











Projetar uma arquitetura de dados robusta exige equilibrar prioridades conflitantes. Integridade, desempenho e manutenibilidade frequentemente puxam em direções diferentes. Quando o sistema muda o foco para operações intensivas de leitura, as regras tradicionais de design de esquema enfrentam estresse significativo. O Diagrama de Relacionamento de Entidades (ERD) torna-se mais do que um plano estático; atua como o contrato entre a lógica da aplicação e o motor de armazenamento. Este guia explora a divergência estratégica entre abordagens normalizadas e denormalizadas, especificamente no contexto de cargas de trabalho com leituras em grande volume.
A decisão de normalizar ou denormalizar não é binária. Envolve compreender o custo da duplicação de dados em relação ao custo da recuperação de dados. Em ambientes onde operações de leitura dominam os logs de transações, minimizar a complexidade das junções frequentemente torna-se o principal objetivo de otimização. No entanto, introduzir redundância cria novos desafios para a consistência dos dados e operações de escrita. Devemos analisar as trade-offs para selecionar a estratégia estrutural apropriada.
🏗️ Compreendendo a Normalização no Design de ERD
A normalização é um processo sistemático usado para reduzir a redundância de dados e melhorar a integridade dos dados. Organiza atributos e tabelas em um banco de dados relacional para minimizar anomalias durante operações de inserção, atualização e exclusão. O objetivo é garantir que cada peça de dados seja armazenada em exatamente um local.
Princípios Fundamentais da Normalização
Ao construir um Diagrama de Relacionamento de Entidades, arquitetos geralmente seguem uma hierarquia de regras conhecidas como Formas Normais. Cada forma aborda tipos específicos de redundância.
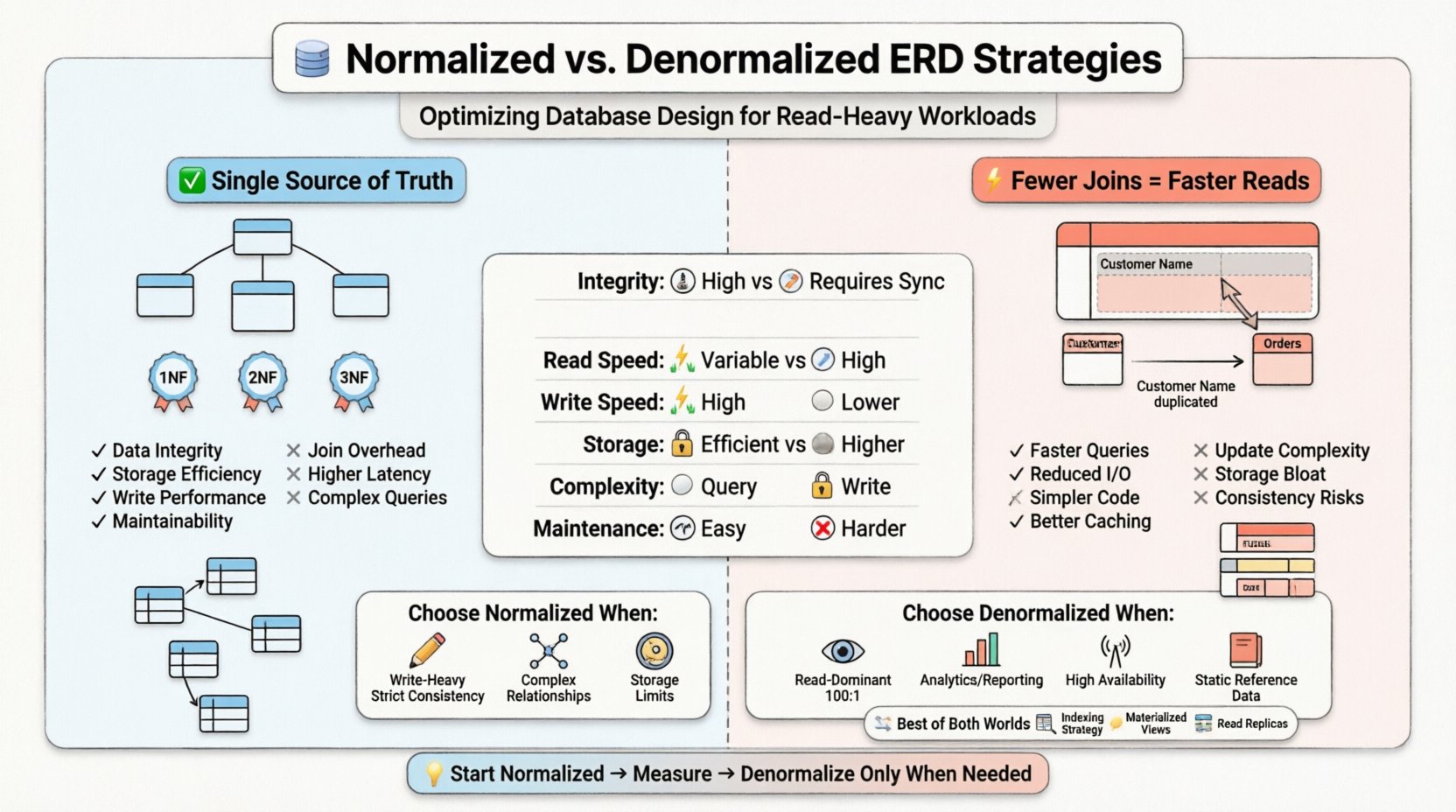
- Primeira Forma Normal (1NF): Garante que cada coluna contenha valores atômicos e que não haja grupos repetidos. Isso estabelece uma estrutura plana para as linhas.
- Segunda Forma Normal (2NF): Constrói sobre o 1NF ao remover dependências parciais. Os atributos devem depender da chave primária inteira, e não apenas de uma parte dela.
- Terceira Forma Normal (3NF): Elimina dependências transitivas. Atributos não-chave devem depender apenas da chave primária, e não de outros atributos não-chave.
Em um ERD altamente normalizado, as tabelas são granulares. Uma tabela de cliente pode existir separadamente da tabela de endereço, que é vinculada por meio de uma chave estrangeira. Uma tabela de pedidos referencia o cliente, e uma tabela de itens de pedido referencia o pedido. Essa estrutura garante que, se um cliente mudar de endereço, a atualização ocorra em um único local e se propague automaticamente.
Vantagens de um Esquema Normalizado
- Integridade dos Dados: Fontes únicas de verdade reduzem o risco de informações conflitantes.
- Eficiência de Armazenamento: Menos dados redundantes significam que a pegada do banco de dados é menor.
- Desempenho de Escrita: Operações de inserção, atualização e exclusão são geralmente mais rápidas porque são necessárias menos linhas para serem alteradas em múltiplas tabelas.
- Manutenibilidade: As alterações nas estruturas de dados são localizadas. Adicionar um novo atributo a uma entidade específica não exige alterações em cascata em tabelas não relacionadas.
Desvantagens para Sistemas com Leituras Intensivas
Embora a normalização se destaque em ambientes com escritas intensivas ou mistos, ela introduz atrito para operações de leitura. Cada junção necessária para montar um registro completo representa uma operação física no disco ou no cache de memória. Em uma carga de trabalho com leituras intensivas, o sistema pode precisar buscar dados de cinco ou seis tabelas diferentes para renderizar uma única visualização no painel.
- Custo de Junção: O processador de consultas deve corresponder chaves entre tabelas. Isso consome ciclos da CPU e largura de banda de memória.
- Operações de E/S: Se as tabelas forem grandes, o motor de armazenamento deve realizar várias buscas para recuperar dados relacionados.
- Latência: O tempo acumulado de várias consultas aumenta o tempo de resposta para o usuário final.
🔗 A Abordagem de Denormalização
A denormalização é a introdução deliberada de redundância em um design de banco de dados. O objetivo é otimizar o sistema para desempenho de leitura, reduzindo o número de junções necessárias. No Diagrama de Relacionamento de Entidades, isso se manifesta como colunas que duplicam dados de outras tabelas ou tabelas mais amplas que consolidam informações relacionadas.
Como Funciona a Denormalização
Em vez de armazenar uma chave estrangeira para procurar o nome do cliente, uma tabela de pedidos denormalizada pode armazenar o nome do cliente diretamente. Se o cliente mudar seu nome, o registro do pedido deve ser atualizado ou sinalizado, ou o sistema aceita que o pedido reflita o nome na data da compra.
Essa estratégia transfere a complexidade da rota de leitura para a rota de gravação. O sistema agora deve lidar com a lógica de atualização das cópias redundantes de dados.
Benefícios para Cargas de Trabalho com Leituras Intensivas
- Execução de Consultas Mais Rápida: Menos junções significam menos sobrecarga computacional.
- I/O Reduzido: Mais dados são recuperados em uma única varredura de tabela em vez de várias consultas.
- Consultas Simplificadas: O código do aplicativo exige menos lógica para montar os resultados.
- Eficiência de Cache: Estruturas mais planas geralmente são mais fáceis de armazenar eficientemente em cache na memória.
Riscos e Desvantagens
O custo principal da denormalização é a consistência dos dados. Se os dados de origem mudarem, todas as cópias redundantes devem ser atualizadas simultaneamente. A falha em fazer isso resulta em dados desatualizados.
- Anomalias de Atualização: Atualizar o nome de um cliente exige encontrar e alterar cada registro de pedido que faz referência a esse cliente.
- Aumento do Armazenamento: Replicar dados aumenta o tamanho total do banco de dados.
- Complexidade nas Gravações: As transações de gravação tornam-se mais complexas, frequentemente exigindo mais bloqueios ou tempos de transação mais longos.
- Rigidez do Esquema: Adicionar um novo campo pode exigir a atualização de várias tabelas, e não apenas uma.
📈 Análise das Características de Cargas de Trabalho com Leituras Intensivas
Para escolher a estratégia correta, é necessário entender a natureza específica da carga de trabalho. Sistemas com leituras intensivas diferem significativamente dos sistemas transacionais, onde gravações são frequentes e críticas.
Padrões de Consulta
O aplicativo realiza consultas analíticas complexas ou pesquisas simples? Consultas complexas que envolvem agregações em muitas tabelas se beneficiam da denormalização. Pesquisas simples por ID podem funcionar adequadamente com normalização, desde que os índices estejam bem ajustados.
- Consultas Pontuais: Recuperando um único registro por ID.
- Consultas em Faixa: Recuperando um conjunto de registros dentro de um intervalo de datas.
- Aggregações: Calculando totais, médias ou contagens em grandes conjuntos de dados.
Requisitos de Latência
Plataformas de negociação de alta frequência ou painéis em tempo real não podem arcar com a latência introduzida por junções complexas. Nesses cenários, a desnormalização é frequentemente uma exigência, e não uma escolha. Por outro lado, se o aplicativo puder tolerar alguns centenas de milissegundos de atraso, a normalização pode ser suficiente com indexação adequada.
Tolerância à Consistência de Dados
A consistência imediata é necessária? Se o sistema puder tolerar consistência eventual, a desnormalização torna-se muito mais segura. Réplicas de leitura ou mecanismos de atualização assíncrona podem lidar com a sincronização de dados redundantes sem bloquear operações de gravação.
📋 Tabela Estratégica de Comparação
A tabela a seguir resume as principais diferenças entre os dois abordagens no contexto do design de banco de dados.
| Funcionalidade | Esquema Normalizado | Esquema Denormalizado |
|---|---|---|
| Integridade de Dados | Alta (Fonte única de verdade) | Menor (Requer lógica de sincronização) |
| Desempenho de Leitura | Variável (Depende das junções) | Alto (Menos junções) |
| Desempenho de Gravação | Alto (Redundância mínima) | Menor (Atualiza múltiplas linhas) |
| Uso de Armazenamento | Eficiente | Maior (Dados redundantes) |
| Complexidade | Alta Complexidade de Consulta | Alta Complexidade de Gravação |
| Manutenibilidade | Fácil para Mudanças no Esquema | Mais Difícil para Mudanças no Esquema |
🧭 Estrutura de Decisão para Arquitetos
Selecionar o caminho certo exige avaliar os requisitos do negócio em contraste com as restrições técnicas. O seguinte framework ajuda a orientar o processo de tomada de decisões.
Quando Escolher a Normalização
- Intensidade de Escrita: Se operações de escrita ocorrem com frequência em relação às leituras, a normalização evita anomalias de atualização.
- Consistência Estrita: Sistemas financeiros ou registros médicos frequentemente exigem conformidade estrita com ACID, onde a redundância é inaceitável.
- Relacionamentos Complexos: Quando entidades possuem relacionamentos muitos para muitos que mudam com frequência, a normalização gerencia o mapeamento de forma limpa.
- Restrições de Armazenamento: Se o espaço em disco é escasso, minimizar a redundância é vantajoso.
Quando Escolher a Denormalização
- Dominância de Leitura: Se as leituras superam as escritas em uma margem significativa (por exemplo, 100:1), os ganhos de desempenho com menos junções superam os custos de escrita.
- Relatórios e Análise: Data warehouses e motores de relatórios frequentemente denormalizam para acelerar consultas de agregação.
- Alta Disponibilidade: Sistemas distribuídos podem denormalizar dados para permitir leituras em nós locais sem saltos de rede para outras partições.
- Dados de Referência Estáticos: Dados que raramente mudam (por exemplo, códigos de país, taxas de câmbio) são candidatos ideais para duplicação.
🛠️ Abordagens Híbridas e Otimização
É raramente necessário escolher um extremo em detrimento do outro. Sistemas modernos frequentemente empregam estratégias híbridas para equilibrar os benefícios de ambos os modelos.
Estratégias de Indexação
Antes de denormalizar, certifique-se de que o esquema normalizado está totalmente indexado. Índices abrangentes permitem que o motor de armazenamento recupere todos os dados necessários diretamente do índice, evitando pesquisas na tabela. Isso pode, às vezes, alcançar velocidades de leitura próximas às de denormalização sem a redundância de dados.
- Índices Compostos: Ordene as colunas pelos campos mais seletivos para acelerar varreduras em faixa.
- Índices Parciais: Indexe apenas subconjuntos específicos de dados para reduzir o tamanho do índice e o custo de manutenção.
Visualizações Materializadas
Uma visualização materializada é um objeto de banco de dados que armazena fisicamente o resultado de uma consulta. Permite ao sistema manter uma visão desnormalizada dos dados sem alterar as tabelas base. Quando os dados subjacentes mudam, a visualização materializada pode ser atualizada.
- Pré-computação:Aggregações complexas são calculadas antecipadamente.
- Ciclos de Atualização:Pode ser configurado para executar em um cronograma ou ser acionado pela mudança de dados.
- Separação de Leitura:As consultas atingem a visualização materializada, enquanto as gravações vão para as tabelas base.
Réplicas de Leitura
Em arquiteturas distribuídas, réplicas de leitura podem ser configuradas para hospedar cópias desnormalizadas de dados. O nó principal lida com gravações e mantém o esquema normalizado. A réplica recebe atualizações de forma assíncrona e atende o tráfego de leitura com o esquema otimizado.
- Escalar Leituras:Distribui a carga entre múltiplos nós.
- Proximidade Geográfica:Coloca os dados mais próximos do usuário.
- Consistência Eventual:Aceita um pequeno atraso na propagação dos dados.
⚠️ Armadilhas Comuns no Design de Esquemas
Mesmo com uma estratégia clara, erros de implementação podem comprometer o desempenho. Arquitetos devem permanecer atentos aos erros comuns.
Sobrenormalização
Criar muitas tabelas para um único conceito pode levar a junções excessivas. Embora a 3FN seja um padrão, segui-la cegamente em sistemas com muitas leituras pode prejudicar o desempenho. Às vezes, uma violação controlada da 3FN é necessária.
Desnormalização Inconsistente
Desnormalizar apenas algumas partes do aplicativo, enquanto outras permanecem normalizadas, cria um sistema fragmentado. A inconsistência torna difícil para os desenvolvedores prever as características de desempenho.
Ignorar o Volume de Dados
Um esquema que funciona para um conjunto de dados pequeno pode falhar quando o volume cresce. A desnormalização aumenta os requisitos de armazenamento linearmente com o número de registros. Se os dados crescerem exponencialmente, o custo de armazenamento e a sobrecarga de manutenção da redundância podem tornar-se inviáveis.
Complexidade da Lógica de Atualização
Implementar a lógica para manter os dados redundantes sincronizados não é trivial. Muitas vezes exige gatilhos, transações em nível de aplicação ou filas de mensagens. Se essa lógica falhar, a corrupção dos dados ocorre silenciosamente.
🔍 Considerações de Implementação
Ao passar do design para a implementação, detalhes técnicos específicos devem ser abordados para garantir o sucesso.
Gerenciamento de Transações
Atualizações desnormalizadas muitas vezes abrangem múltiplas linhas. Elas devem ser envolvidas em uma única transação para garantir atomicidade. Se o sistema falhar no meio do processo, os dados devem ser revertidos para evitar inconsistência.
Camadas de Cache
Mesmo com desnormalização, o cache de dados frequentemente acessados na memória pode reduzir ainda mais a carga do banco de dados. O cache deve ser inválido ou atualizado quando os dados subjacentes forem alterados.
Monitoramento e Métricas
O monitoramento contínuo é essencial. Monitore os tempos de execução de consultas, contenção de bloqueios e crescimento do armazenamento. Se a latência de gravação aumentar abruptamente, pode indicar que a lógica de atualização da desnormalização é muito pesada.
📝 Considerações Finais para Arquitetos
A escolha entre estratégias de ERD normalizadas e desnormalizadas é uma decisão arquitetônica fundamental. Ela determina como os dados fluem pelo sistema e como o motor de armazenamento interage com o aplicativo. Não existe uma única resposta correta que se aplique a todos os cenários.
- Meça Primeiro: Não otimize com base em suposições. Perfille a carga de trabalho atual para identificar gargalos.
- Comece Simples: Comece com um design normalizado. Desnormalize apenas quando métricas de desempenho indicarem necessidade.
- Documente as Decisões: Registre claramente por que a redundância foi introduzida. Mantenedores futuros precisam entender as trade-offs.
- Planeje para a Evolução: Os designs de esquema devem evoluir. Uma estratégia que funciona hoje pode precisar de ajustes conforme os padrões de dados mudarem.
Ao compreender a mecânica das junções, o custo da redundância e as demandas específicas de cargas de trabalho intensivas em leitura, arquitetos podem projetar sistemas que sejam tanto robustos quanto eficientes. O objetivo não é seguir uma regra rígida, mas aplicar a ferramenta mais adequada para o ambiente de dados específico.