











Die Gestaltung der Datenstruktur für eine moderne Anwendung erfordert sorgfältige Überlegungen dazu, wie Informationen miteinander verbunden sind, persistieren und skaliert werden. Im Zentrum dieses Gestaltungsprozesses steht das Entity-Relationship-Diagramm (ERD). Dieses visuelle Modell dient als Bauplan zur Verständnis von Datenentitäten und ihren Wechselwirkungen. Mit wachsender Komplexität der Anwendung wird die Wahl zwischen einem relationalen und einem graphbasierten Ansatz entscheidend. Beide Methoden bieten unterschiedliche Vorteile, abhängig von der Art der Datenbeziehungen und den Leistungsanforderungen des Systems.
Das Verständnis der Feinheiten jeder Modellierungstechnik ermöglicht Architekten, Systeme zu entwickeln, die robust, wartbar und effizient sind. Dieser Leitfaden untersucht die grundlegenden Prinzipien, strukturellen Unterschiede und praktischen Implikationen der Wahl zwischen relationalen und graphbasierten ERDs. Durch eine detaillierte Betrachtung dieser Methoden können Teams fundierte Entscheidungen treffen, die mit ihrer spezifischen Geschäftslogik und technischen Beschränkungen übereinstimmen.
🏛️ Der relationale Ansatz: Struktur und Integrität
Das relationale Modell ist seit Jahrzehnten die Grundlage der Datenverwaltung. Es beruht auf einer strengen Struktur, bei der Daten in Tabellen organisiert werden, die aus Zeilen und Spalten bestehen. In einem relationalen ERD werden Entitäten als Tabellen dargestellt, und Beziehungen werden durch Fremdschlüssel definiert, die Primärschlüssel über verschiedene Tabellen hinweg verknüpfen.
Grundprinzipien der relationalen Modellierung
- Normalisierung:Relationale Datenbanken legen Wert auf Normalisierung, um Redundanz zu reduzieren. Daten werden in mehrere Tabellen aufgeteilt, um sicherzustellen, dass jedes Informationsstück an nur einer Stelle gespeichert wird. Dadurch werden Datenanomalien bei Aktualisierungen oder Löschungen minimiert.
- Referenzielle Integrität:Beschränkungen sorgen dafür, dass Beziehungen gültig bleiben. Wenn ein Datensatz in einer übergeordneten Tabelle gelöscht wird, legen Regeln fest, wie mit den zugehörigen Kinddatensätzen verfahren wird, beispielsweise durch kaskadierendes Löschen oder Verhinderung der Aktion.
- Schema-Definition:Die Struktur wird vor der Dateneinfügung definiert. Jede Spalte muss einen bestimmten Datentyp und Einschränkungen haben, um Konsistenz im gesamten Datensatz zu gewährleisten.
- Abfragesprache:Der Zugriff auf Daten erfolgt typischerweise über die strukturierte Abfragesprache (SQL). Diese Sprache ermöglicht komplexe Joins, um Daten zu erhalten, die über mehrere Tabellen verteilt sind.
Stärken relationaler ERDs
Relationale Diagramme zeichnen sich in Szenarien aus, in denen Datenkonsistenz von höchster Bedeutung ist. Sie eignen sich ideal für Systeme, die Finanztransaktionen, Bestandsverwaltung oder jede Anwendung verarbeiten, bei der strikte Einhaltung von Regeln erforderlich ist.
- Datenintegrität:Das strenge Schema setzt Regeln durch, die verhindern, dass ungültige Daten in das System gelangen. Dies ist entscheidend für Compliance und Audits.
- Reife:Die Technologie ist gut verstanden. Werkzeuge zur Visualisierung, Fehlerbehebung und Wartung sind reichlich vorhanden und standardisiert.
- ACID-Konformität:Relationale Systeme unterstützen typischerweise Atomicität, Konsistenz, Isolation und Dauerhaftigkeit. Dadurch wird sichergestellt, dass Transaktionen zuverlässig verarbeitet werden, selbst bei Systemausfällen.
- Effizienz von Joins:Bei stark normalisierten Daten mit wenigen Beziehungsebenen sind Joins zwischen Tabellen effizient und vorhersehbar.
Zu berücksichtigende Einschränkungen
Trotz ihrer Stärken stoßen relationale Modelle bei der Verarbeitung stark miteinander verbundener Daten auf Herausforderungen. Mit zunehmender Anzahl von Beziehungen wächst die Komplexität der Joins.
- Komplexe Joins:Die Abfrage von Daten, die sich über viele Tabellen erstrecken, kann zu Leistungseinbußen führen. Jeder Join fügt zusätzlichen Rechenaufwand hinzu.
- Schema-Starrheit:Die Änderung der Struktur einer relationalen Datenbank erfordert oft Migrationsskripte. Dies kann in Produktionsumgebungen riskant und zeitaufwendig sein.
- Tiefenmodellierung:Die Darstellung von Many-to-Many-Beziehungen oder rekursiven Strukturen (wie Organisationshierarchien) erfordert Zwischentabellen oder selbstreferenzierende Schlüssel, was die Diagramme und Abfragen komplizierter machen kann.
🕸️ Der graphbasierte Ansatz: Verbindungen als erste Klasse
Die graphbasierte Modellierung verlagert den Fokus von den Daten selbst auf die Verbindungen zwischen Datenpunkten. Bei diesem Ansatz werden Beziehungen als explizit definierte Verknüpfungen gespeichert, anstatt über Fremdschlüssel abgeleitet zu werden. Dadurch eignet sich das Graphmodell besonders gut für Netzwerke, soziale Strukturen und Empfehlungssysteme.
Grundprinzipien der Graphmodellierung
- Knoten und Kanten:Entitäten werden als Knoten dargestellt, und Beziehungen als Kanten. Jeder Knoten und jede Kante kann Eigenschaften enthalten, was reichhaltige Metadaten ohne zusätzliche Tabellen ermöglicht.
- Durchquerung:Abfragen sind darauf ausgelegt, Pfade von einem Knoten zum anderen zu durchqueren. Die Datenbankengine optimiert das Folgen von Verbindungen statt das Durchsuchen von Tabellen.
- Schema-Flexibilität:Obwohl Schemata durchgesetzt werden können, erlauben Graphmodelle oft schemafreie oder schema-on-read-Ansätze. Neue Beziehungstypen können hinzugefügt werden, ohne die gesamte Struktur zu verändern.
- Musterabgleich:Abfragen konzentrieren sich auf das Finden spezifischer Verbindungsstrukturen. Dies ist effizient beim Auffinden von Freunden von Freunden, kürzesten Wegen oder gemeinsamen Merkmalen.
Stärken von Graph-ERDs
Graphische Darstellungen zeichnen sich aus, wenn der Wert des Systems in den Verbindungen zwischen Entitäten liegt. Sie bieten eine natürliche Darstellung für komplexe Netzwerke.
- Navigations-Effizienz:Die Abfrage von Daten über mehrere Verbindungsstufen hinweg ist deutlich schneller. Die Datenbank folgt den Verbindungen direkt, ohne die gesamte Datenmenge zu durchsuchen.
- Dynamische Beziehungen:Das Hinzufügen neuer Verbindungstypen erfordert keine Schema-Migrationen. Dies unterstützt schnelle Iterationen und sich verändernde Geschäftsanforderungen.
- Visuelle Klarheit:Graphische ERDs spiegeln oft das mentale Modell der Daten wider. Stakeholder können leicht erkennen, wie Entitäten miteinander verbunden sind, ohne komplexe Join-Bedingungen verstehen zu müssen.
- Behandlung tiefer Hierarchien:Rekursive Beziehungen, wie Kategorien innerhalb von Kategorien, werden natürlich als Ketten aus Knoten und Kanten dargestellt.
Zu berücksichtigende Einschränkungen
Graphmodelle sind keine universelle Lösung. Sie bringen spezifische Herausforderungen mit sich, die bewältigt werden müssen.
- Schreibleistung:Während Lesevorgänge schnell sind, kann die Pflege von Beziehungen bei hochvolumigen Schreibvorgängen komplexer sein als einfache Einfügungen.
- Transaktionsumfang:Die Verwaltung von Transaktionen über ein verteiltes Graphen kann schwieriger sein als die Aktualisierung einzelner Zeilen in einer Tabelle.
- Abfragekomplexität: Das Schreiben effektiver Durchlaufabfragen erfordert einen anderen Ansatz als das Schreiben von SQL-Joins. Es erfordert das Verständnis von Pfadfindungsalgorithmen.
- Werkzeug-Ökosystem: Während es wächst, ist das Ökosystem für die Verwaltung von Graphendaten kleiner als das relationaler Systeme, was die Besetzung von Stellen und die Verfügbarkeit von Support beeinträchtigen könnte.
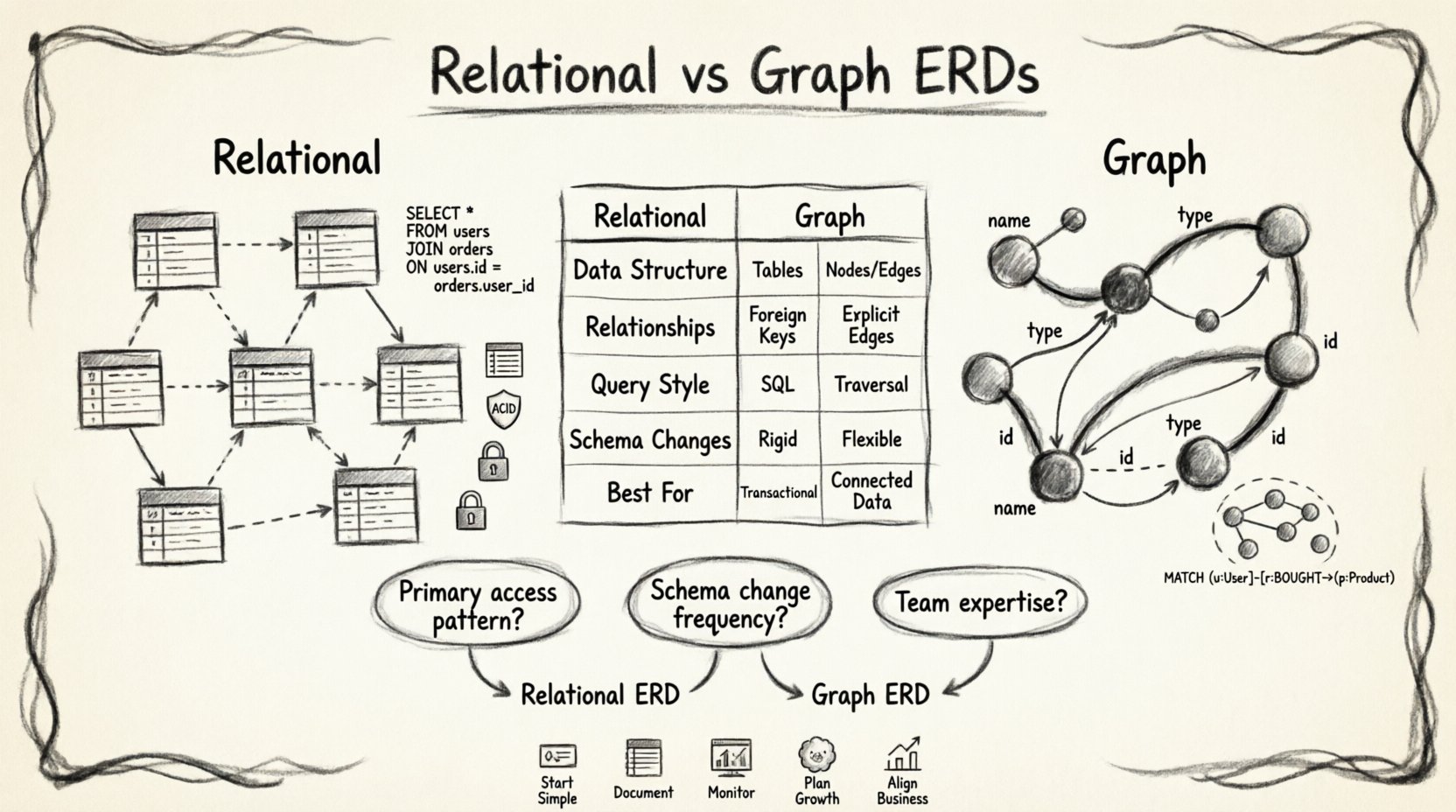
⚖️ Vergleichende Analyse: Wichtige Unterschiede
Um die Kompromisse klar zu verstehen, ist es hilfreich, die beiden Ansätze nebeneinander zu betrachten. Die folgende Tabelle skizziert die wichtigsten Unterschiede über gängige architektonische Dimensionen hinweg.
| Dimension | Relationaler ERD-Ansatz | Graphenbasierter ERD-Ansatz |
|---|---|---|
| Datenstruktur | Tabellen, Zeilen, Spalten | Knoten, Kanten, Eigenschaften |
| Speicherung von Beziehungen | Fremdschlüssel (implizit) | Explizite Kanten (erster Klasse) |
| Abfragemodus | Deklarativ (SQL) | Durchläufe / Musterabgleich |
| Schemaänderungen | Kostenintensiv (Migrationen) | Flexibel (schemafreie Optionen) |
| Beste Anwendungsfälle | Transaktionale, strukturierte Daten | Netzwerkartige, verbundene Daten |
| Integritätsprüfung | Strenge Einschränkungen | Anwendungsebene oder konfigurierbar |
| Skalierbarkeit | Vertikale Skalierung | Horizontale Skalierung |
| Abfragekomplexität | Hohe Verbindungen = Langsamer | Große Tiefe = Effizient |
🛠️ Implementierungsaspekte
Die Wahl zwischen diesen Ansätzen geht über reine technische Vorlieben hinaus. Es erfordert eine Bewertung des Anwendungslebenszyklus, der fachlichen Kompetenz des Teams und der langfristigen Wartungsziele.
Schema-Evolution und -Migration
In einer relationalen Umgebung ist die Evolution des Schemas ein bewusster Prozess. Das Hinzufügen einer Spalte oder die Änderung eines Datentyps erfordert oft das Sperren von Tabellen oder das Ausführen von Migrations-Skripten. Dies kann die Verfügbarkeit beeinträchtigen. Im Gegensatz dazu ermöglichen Graphmodelle die Einführung neuer Beziehungstypen, ohne bestehende Knoten zu beeinflussen. Diese Flexibilität unterstützt agile Entwicklungszyklen, bei denen sich die Anforderungen häufig ändern.
Allerdings bringt diese Flexibilität einen Preis mit sich. Ohne strikte Schema-Enforcement kann die Datenqualität im Laufe der Zeit abnehmen. Teams müssen Governance-Strategien implementieren, um sicherzustellen, dass der Graph weiterhin nutzbar und abfragbar bleibt.
Abfrageleistung und Indizierung
Die Leistungsoptimierung unterscheidet sich erheblich zwischen den beiden Modellen. Relationale Systeme verlassen sich auf Indizes in Spalten, um die Suche zu beschleunigen. Beim Verknüpfen mehrerer Tabellen bestimmt der Optimierer den effizientesten Ausführungsplan.
Graphsysteme verlassen sich auf Indizes für Knoten und Kanten. Der Durchlauf-Engine folgt den Verweisen direkt. Bei Abfragen, die eine tiefe Verschachtelung erfordern, wie beispielsweise „Finde alle Lieferanten, die Teile an Produkte liefern, die an Kunden in Region X versandt werden“, vermeidet ein Graphmodell die exponentiellen Kosten mehrerer Verknüpfungen.
Anforderungen an Datenkonsistenz
Anwendungen, die mit Geld, medizinischen Aufzeichnungen oder rechtlichen Verträgen arbeiten, erfordern starke Konsistenz. Relationale Modelle bieten integrierte Mechanismen, um sicherzustellen, dass jede Transaktion gültig ist, bevor sie festgeschrieben wird. Graphmodelle können Konsistenz unterstützen, erfordern dafür aber oft eine größere Konfiguration, um auf verteilten Knoten dasselbe Maß an Sicherheit zu gewährleisten.
Integration mit bestehenden Systemen
Die meisten Organisationen verfügen bereits über eine relationale Infrastruktur. Die Einführung eines Graphmodells erfordert oft eine Polyglot-Persistence. Das bedeutet, zwei unterschiedliche Datenspeicher zu pflegen und sicherzustellen, dass sie synchron bleiben. Die Integrations-Schicht erhöht die Komplexität der Architektur.
🌐 Hybridstrategien für moderne Anwendungen
Viele moderne Anwendungen passen nicht sauber in eine Kategorie. Ein hybrider Ansatz bietet oft das beste Gleichgewicht. Diese Strategie beinhaltet die Verwendung einer relationalen Datenbank für zentrale transaktionale Daten und eines Graphspeichers für abfragereiche Beziehungsoperationen.
Mikroservices und Datenbesitz
In einer Mikroservices-Architektur können verschiedene Dienste unterschiedliche Datenmodelle besitzen. Der Benutzerdienst könnte ein relationales Modell verwenden, um Konten sicher zu verwalten. Der Empfehlungsdienst könnte ein Graphmodell nutzen, um Benutzerpräferenzen und Verbindungen zu analysieren. Diese Trennung ermöglicht es jedem Dienst, sich auf seine spezifische Arbeitslast zu optimieren.
Synchronisationsmuster
Die Synchronisation der beiden Speicher erfordert eine sorgfältige Gestaltung. Eventgesteuerte Architekturen können verwendet werden, um Änderungen zu verbreiten. Wenn ein Datensatz im relationalen Speicher aktualisiert wird, wird ein Ereignis ausgelöst, um die entsprechenden Knoten im Graphspeicher zu aktualisieren.
- Änderungsdatenerfassung: Überwachung des Transaktionsprotokolls der relationalen Datenbank zur Erkennung von Änderungen.
- Ereignisquellen: Speichern von Zustandsänderungen als Folge von Ereignissen, die wiederholt werden können, um den Graphzustand aufzubauen.
- Stapelverarbeitung: Periodische Aufgaben, die den Graphindex aus der relationalen Quelle neu aufbauen.
📊 Entscheidungsrahmen
Wenn Sie sich der Entscheidung gegenübersehen, welchen ERD-Ansatz Sie übernehmen sollen, überlegen Sie folgende Fragen.
- Was ist der primäre Zugriffsmuster? Wenn die Anwendung Daten über viele Tabellen hinweg aggregieren muss, ist relational oft besser. Wenn die Anwendung Beziehungen durchlaufen muss, ist Graph überlegen.
- Wie oft ändert sich das Schema?Häufige Änderungen deuten auf einen graphen- oder dokumentenbasierten Ansatz hin. Stabile Schemata eignen sich gut für relationale Modelle.
- Wie groß ist die Toleranz für Datenredundanz?Relationale Modelle minimieren Redundanz. Graphenmodelle akzeptieren Redundanz oft, um Lesevorgänge zu beschleunigen.
- Welche Expertise hat das Team?Relationale SQL wird weithin gelehrt. Graphenabfragesprachen erfordern spezifische Schulungen, damit das Team effektiv arbeiten kann.
- Welche Compliance-Anforderungen bestehen?Hoch regulierte Branchen bevorzugen oft die Nachvollziehbarkeit relationaler Systeme.
🔮 Zukünftige Trends in der Datenmodellierung
Das Feld der Datenmodellierung entwickelt sich weiter. Je komplexer die Anwendungen werden, desto mehr könnten die Grenzen zwischen relationalen und graphenbasierten Ansätzen verschwimmen.
Graph-Relationale Hybride
Einige neu entstehende Datenbankplattformen versuchen, die Stärken beider Ansätze zu kombinieren. Sie bieten relationale Tabellen mit nativen graphenbasierten Durchlaufmöglichkeiten. Dadurch können Entwickler eine einzige Engine sowohl für Transaktionsintegrität als auch für Netzwerkanalysen nutzen.
KI-getriebene Schema-Design
Künstliche Intelligenz beginnt, bei der Datenmodellierung zu unterstützen. Werkzeuge können Nutzungsmuster analysieren und optimale Schema-Designs vorschlagen. Sie können empfehlen, wann Daten normalisiert oder Beziehungsinformationen hinzugefügt werden sollten.
Cloud-natives Skalieren
Cloud-Infrastruktur treibt beide Modelle in Richtung horizontaler Skalierung. Verteilte relationale Datenbanken und verteilte Graph-Cluster werden zunehmend zur Norm. Dies verringert die Hürden bei der Skalierung und ermöglicht eine globale Verteilung der Daten.
📝 Zusammenfassung der Best Practices
Unabhängig von der gewählten Herangehensweise gelten bestimmte Prinzipien für alle erfolgreichen Datenmodellierungsansätze.
- Beginne einfach:Übertreibe nicht das erste Modell. Beginne mit den zentralen Entitäten und füge Komplexität hinzu, je nachdem, wie sich die Anforderungen entwickeln.
- Dokumentiere Beziehungen:Dokumentiere klar die Kardinalität und Richtung der Beziehungen. Dies ist entscheidend für die Abstimmung im Team.
- Überwache die Leistung:Überwache kontinuierlich die Abfrageleistung. Ein Modell, das auf Papier gut aussieht, kann in der Produktion schlecht performen.
- Plane für Wachstum:Plane mit Skalierung im Blick. Überlege, wie das Modell 10-mal oder 100-mal das aktuelle Datenvolumen bewältigen wird.
- Koordiniere mit dem Geschäft:Stelle sicher, dass das Datenmodell den Geschäftsbereich widerspiegelt. Das Diagramm sollte die Geschichte der Geschäftslogik erzählen.
Die Wahl zwischen relationalen und graphenbasierten ERDs geht nicht darum, die perfekte Lösung zu finden. Es geht darum, das richtige Werkzeug für das jeweilige Problem zu wählen. Durch das Verständnis der Stärken und Grenzen jedes Ansatzes können Architekten Systeme entwickeln, die widerstandsfähig, leistungsstark und an zukünftige Anforderungen anpassbar sind. Die Entscheidung hängt letztendlich von der Beschaffenheit der Daten und den operativen Anforderungen der Anwendung ab.