











データモデリングは、いかなる堅牢なデータベースアーキテクチャの基盤である。理論はしばしば大学の授業で教えられるが、実際の生産環境における応用は、境界ケース、パフォーマンスのボトルネック、論理的な曖昧さに満ちた状況を明らかにする。エンティティ関係図(ERD)はこれらのシステムの設計図として機能するが、現実世界が箱や線にすっきりと収まらない場合、しばしば議論の的となる。
我々は、主要データベース管理者およびデータアーキテクトのパネルと対談し、設計段階でチームを悩ませるシナリオを詳細に検討した。これらは理論的な演習ではなく、ビジネス要件と物理的ストレージ制約が衝突する際に生じる問題である。ここでの目的は、即効的な解決策を提示することではなく、関与するトレードオフを深く理解することにある。
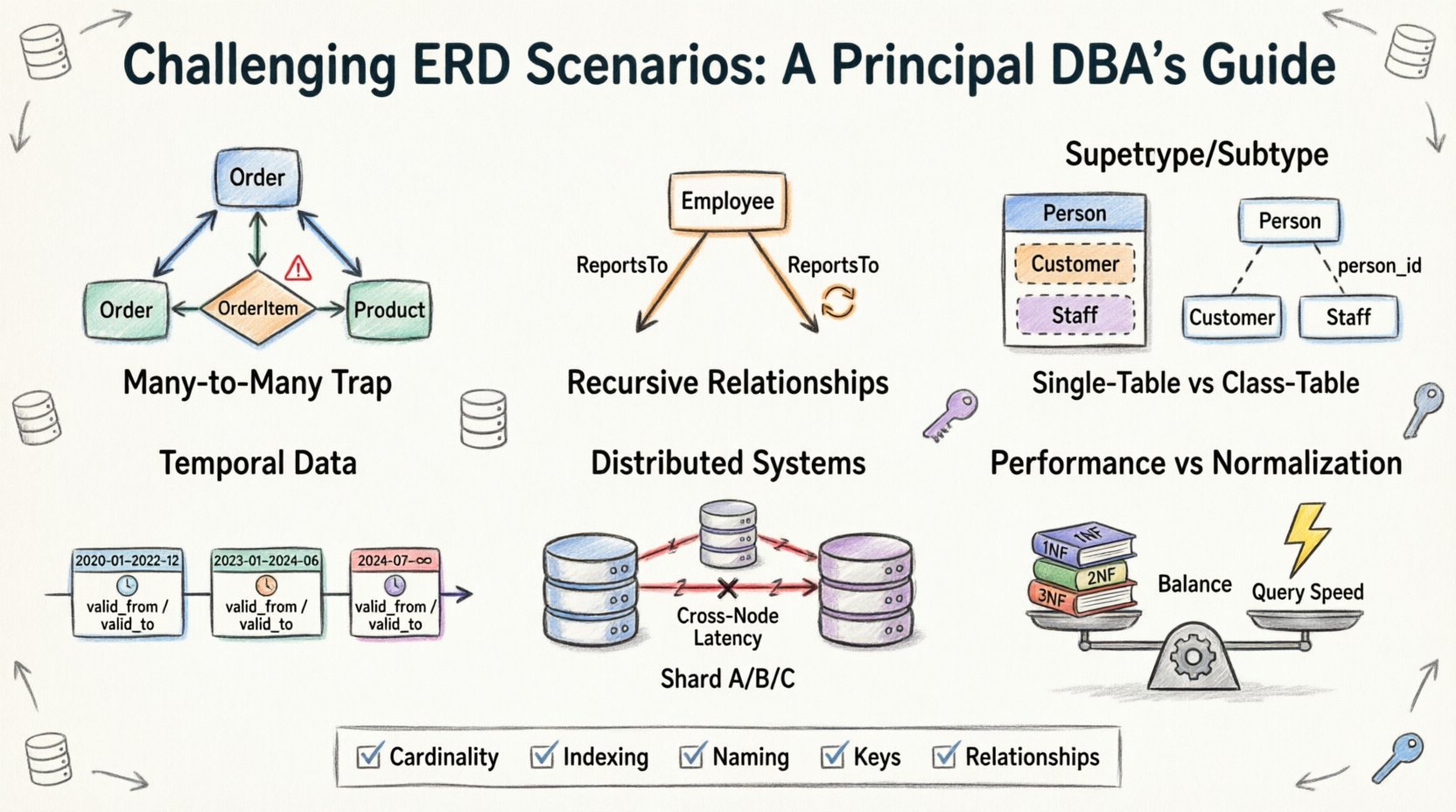
1. 多対多の罠:単純な結合テーブルを超えて 🕸️
ERD設計における最も一般的な出発点は、多対多関係である。直感的に理解できる:生徒は複数の授業に登録可能であり、授業には複数の生徒が所属できる。標準的な解決策は、ブリッジまたは関連テーブルを設けることである。しかし、関係自体に属性が追加されると、複雑さが生じる。
- 問題点:しばしば、チームは登録データ(成績や登録日など)を主となる生徒テーブルまたは授業テーブルに格納しようとするが、これにより極めて大きな重複やnull値が生じる。
- 現実:関係自体がエンティティである。独自の主キーと、親を指す外部キーを持つ必要がある。
- 課題:連鎖削除の処理。授業が削除された場合、登録記録はどうなるか?登録記録が削除された場合、生徒は消えるのか?これらの決定がデータ整合性を規定する。
対談中に、ある主要DBAが、関連テーブルがしばしばパフォーマンスのボトルネックになることに言及した。この接続部をまたいでデータを照会する際、データベースエンジンは結合操作を実行しなければならないが、行数が数百万単位に達するとスケーリングが著しく悪化する。解決策は常にアーキテクチャ的なものではない。場合によっては非正規化が必要だが、これにより更新異常が生じる。
多対多のための重要な考慮点:
- 関係にインデックスが必要な属性があるか?
- 関係は現在有効なものか、過去のものか?(例:現在の登録と過去の登録は異なるか?)
- 親が削除された場合、孤児となったレコードをシステムはどのように処理するか?
2. 再帰的関係:自己参照階層 🌳
階層的データは至る所に存在する。組織図、部品表、フォーラムのコメントスレッドなどを思い浮かべてほしい。これをモデリングするには、テーブルが自分自身を参照する必要がある。概念的には簡単だが、リレーショナルスキーマで実装すると、深さや走査に関する特定の課題が生じる。
構造上の問題:
主キーと、同じテーブルの主キーを指す外部キー列を持つテーブルを作成する。これはしばしば「parent_id」列と呼ばれる。ルートノードは親がnullである。
パフォーマンス上の問題:
標準的なSQLクエリは深い階層に対して苦戦する。マネージャーとその直接・間接の部下全員を取得する必要がある場合、単純なJOINでは不十分である。再帰的な共通テーブル式(CTE)またはレベルをループするストアドプロシージャが必要となる。これは計算コストが非常に高くなることがある。
整合性上の問題:
循環参照は静かなる殺し手である。社員Aが社員Bを管理し、社員Bが社員Aを管理している場合、循環が発生する。データベースがこれを防止するか、アプリケーションロジックが検出しなければならない。大規模システムでは、循環がレポートツールで無限ループを引き起こすことがある。
- 深さの制限:多くのシステムでは、階層の深さを制限(例:32段階)することで、走査中にスタックオーバーフローのエラーを防いでいる。
- パス集計:部分木の合計コストや件数を計算するには再帰的なロジックが必要だが、標準的なクエリプランでは最適化が難しい。
3. スーパータイプとサブタイプのモデリング:継承のジレンマ 🧬
オブジェクト指向プログラミングでは、継承は標準である。リレーショナルデータベースでは、これはストレージと取得に影響を与える設計選択である。問題は、車両を単一のテーブルとしてモデリングするか、Vehicle、Car、Truckに分割するかである。
オプションA:単一テーブル継承
すべてのサブタイプの属性が1つのテーブルに含まれます。使用されていない属性にはNULLが使用されます。
- 長所:シンプルなクエリ、どの車両も検索する際に結合が必要ありません。
- 短所:テーブルの肥大化、サブタイプ固有の制約を適用しにくく、多くのカラムがNULLになる。
オプションB:クラステーブル継承
スーパークラス(Vehicle)用の1つのテーブルと、サブクラス(Car、Truck)用の別々のテーブルがあり、主キーによってリンクされています。
- 長所:明確な分離、NULLが存在しない、各サブタイプごとに厳格な制約が可能。
- 短所:クエリには複数のテーブルの結合が必要となり、読み取りパフォーマンスに影響を与える可能性がある。
当社の主要DBAは、選択はしばしばクエリパターンに依存すると指摘しました。特定のサブタイプを頻繁にクエリする場合は、クラステーブル方式がより適しています。すべてのサブタイプを集計して頻繁にアクセスする場合は、単一テーブル方式が優れています。ERDはこの意思決定を明確に反映する必要があります。これにより、将来の開発者が混乱しないようにします。
4. 時系列データ:時間の経過に伴う変更の追跡 ⏳
ビジネスルールは変化する。顧客が引っ越し、価格が更新され、契約が期限切れになる。現在の状態だけを保存するのは、監査やレポートにおいてしばしば不十分である。これにより、時系列テーブルや徐々に変化する次元(SCD)の設計が生じる。
複雑さ:
行の更新ではなく、有効開始日と終了日を含む新しい行を挿入する。古い行は非アクティブとしてマークされる。これにより、履歴データのストレージ要件が2倍になり、「現在のビュー」を取得するクエリが複雑化する。
クエリの課題:
特定の時点におけるデータを選択するには、日付範囲でのフィルタリングが必要となる。日付範囲のロジックを誤ると、誤ったバージョンのレコードを返す可能性がある。これは金融アプリケーションでデータ整合性の問題が顕在化するよくある場面である。
- スナップショット設計:特定時点での状態を保存する。スナップショットを書き込むために定期的なバッチジョブが必要となる。
- トランザクションログ設計:すべての変更を記録する。書き込み量が非常に多く、取得ロジックが複雑になる。
- 定期的設計:有効期間を保存する。時間のギャップをうまく扱えるが、境界管理に注意が必要である。
5. 分散システム:シャーディングと関係性 🔗
単一のデータベースではデータを保持できない場合、シャーディングが必須となる。ここがERD設計が最も厳しい物理的制約に直面する場所である。シャーディング境界をまたぐ関係性はコストがかかる。
結合の問題:
Table AがUser IDでシャーディングされている場合、Table BがTable Aにリンクされているならば、Table Bも同じUser IDでシャーディングされなければ、分散結合を避けることができない。Table Bが他のものでシャーディングされている場合、クエリを複数のシャードにルーティングし、結果を統合してローカルで結合する必要がある。
参照整合性:
外部キー制約は分散ノード間で強制するのが難しい。多くのシステムは可用性を維持するために、シャーディング環境で外部キーを無効化する。これにより整合性の負担がアプリケーション層に移され、競合状態が発生しやすくなる。
分散ERDの要点:
- 複数のシャードにまたがる多対多の関係を避ける。
- ノード間の結合の必要性を減らすために、データを正規化しない(デノーマライズ)する。
- パーティションキー(シャーディングキー)を、主キーだけでなく最も頻繁に使用されるクエリパターンに基づいて設計する。
6. パフォーマンス vs. 正規化:トレードオフのバランス ⚖️
正規化(1NF、2NF、3NF)はデータ整合性のゴールドスタンダードとして教えられる。しかし、高スループットシステムでは、厳格な正規化がパフォーマンスを著しく低下させる可能性がある。ERDは両者のバランスを取らなければならない。
デノーマライズするタイミング:
- 読み込み中心のワークロード:読み込みが書き込みよりもはるかに多い場合、冗長なカラムを追加することで結合操作を節約できる。
- レポート要件:正規化されたデータ上の集計には複雑な結合が必要となり、ダッシュボードの動作を遅くする。
- 書き込み中心のワークロード:時として、データを別々に保持することで、更新時のロック競合を減らせる。
パネルは、『完璧なスキーマ』は存在しないと強調した。それは妥協の産物である。ERDはデノーマライズがどこで行われ、なぜ行われたのかを文書化すべきであり、将来の保守担当者が冗長性が意図的であることを理解できるようにするべきである。
モデリングパターンの比較 📊
意思決定を支援するために、議論されたモデリングパターンとその典型的な使用ケースの要約を以下に示す。
| パターン | 最適な使用ケース | 主なリスク | 複雑さ |
|---|---|---|---|
| 単一テーブル | 単純な階層構造、種類が少ない | NULLフィールド、スキーマの肥大化 | 低 |
| クラステーブル | 厳密なサブタイプ、明確な属性 | 結合のオーバーヘッド | 中 |
| 再帰的 | 組織図、カテゴリ | 走査の深さ、サイクル | 高 |
| 関連エンティティ | 属性付きの多対多 | 結合のパフォーマンス | 中 |
| 時系列 | 監査、履歴追跡 | クエリの複雑さ | 高 |
| 分散シャーディング | 大規模スケール、水平拡張 | 参照整合性 | 非常に高い |
ERDレビューのチェックリスト ✅
エンティティ関係図を最終確定する前に、このチェックリストを使って一般的な落とし穴を発見してください。設計段階でこれらの問題を発見するほうが、本番環境で発見するよりも良いです。
- 基数:1対1、1対多、多対多の関係を明確に定義しましたか?最小/最大制約(0..1、1..*)は明示されていますか?
- データ型:列のデータ型が想定されるデータサイズに適していますか?(例:IDにIntegerとVarcharのどちらを使用するか)
- Null許容性:外部キーはNullを許容しますか?許容する場合、ロジックは孤立した参照を適切に処理しますか?
- インデックス戦略:ERDはパフォーマンス向上のため、どの列にインデックスを付けるべきかを示していますか?外部キーは結合を高速化するために頻繁にインデックス化されます。
- 命名規則:テーブル名と列名は一貫していますか?後で曖昧になる可能性のある省略語は避けてください。
- ビジネスルール:制約(例:「ユーザーは2つのアクティブなサブスクリプションを持つことはできません」)は論理チェックまたはデータベース制約として表現されていますか?
- 拡張性: スキーマは完全な移行を必要とせずに新しい属性を対応できるでしょうか?(例えば、適切な場面ではEAVパターンやJSONカラムを使用するなど)。
データモデリングに関する最終的な考察 🧠
エンティティ関係図(ERD)を設計することは、箱と線を描くことだけではありません。データの流れやハードウェアの制約、ビジネスのニーズを理解することにあります。ここに述べたシナリオは、理論と実践がぶつかり合う摩擦点を表しています。
これらの課題——再帰的深さ、分散結合、時系列履歴、継承のトレードオフ——を事前に想定することで、耐障害性のあるスキーマを構築できます。適切に設計されたERDは技術的負債を削減し、将来の高コストな再設計を防ぎます。これは、システム全体の安定性への投資です。
最も良いスキーマは、データとともに進化するものであることを思い出してください。ドキュメント化が鍵となります。標準正規化からのすべての逸脱が正当化され、記録されていることを確認してください。この透明性こそが、堅牢なデータベースアーキテクチャと脆弱なアーキテクチャを分けるものです。