











現代のインフラストラクチャのためのデータモデル設計には、根本的な考え方の転換が必要です。従来のエンティティ関係図(ERD)は、単一のデータベースインスタンスがすべてのトランザクションを管理するモノリシックアーキテクチャにおいて適切に機能していました。しかし、システムが分散環境へと進化するにつれて、データ整合性や関係マッピングのルールは大きく変化します。このガイドでは、複雑な分散トランザクションシステムに特化した高度なERDパターンについて探求します。一貫性のモデル化、サービス間での状態管理、特定のソフトウェア製品に依存せずに依存関係を可視化する方法について検討します。
分散環境では、データ所有権の境界が曖昧になります。エンティティが複数の論理的ストアに存在する可能性があり、関係がどのように維持されるかを明確に定義する必要があります。この文書では、これらの複雑さをモデル化するための構造的なアプローチを提供します。
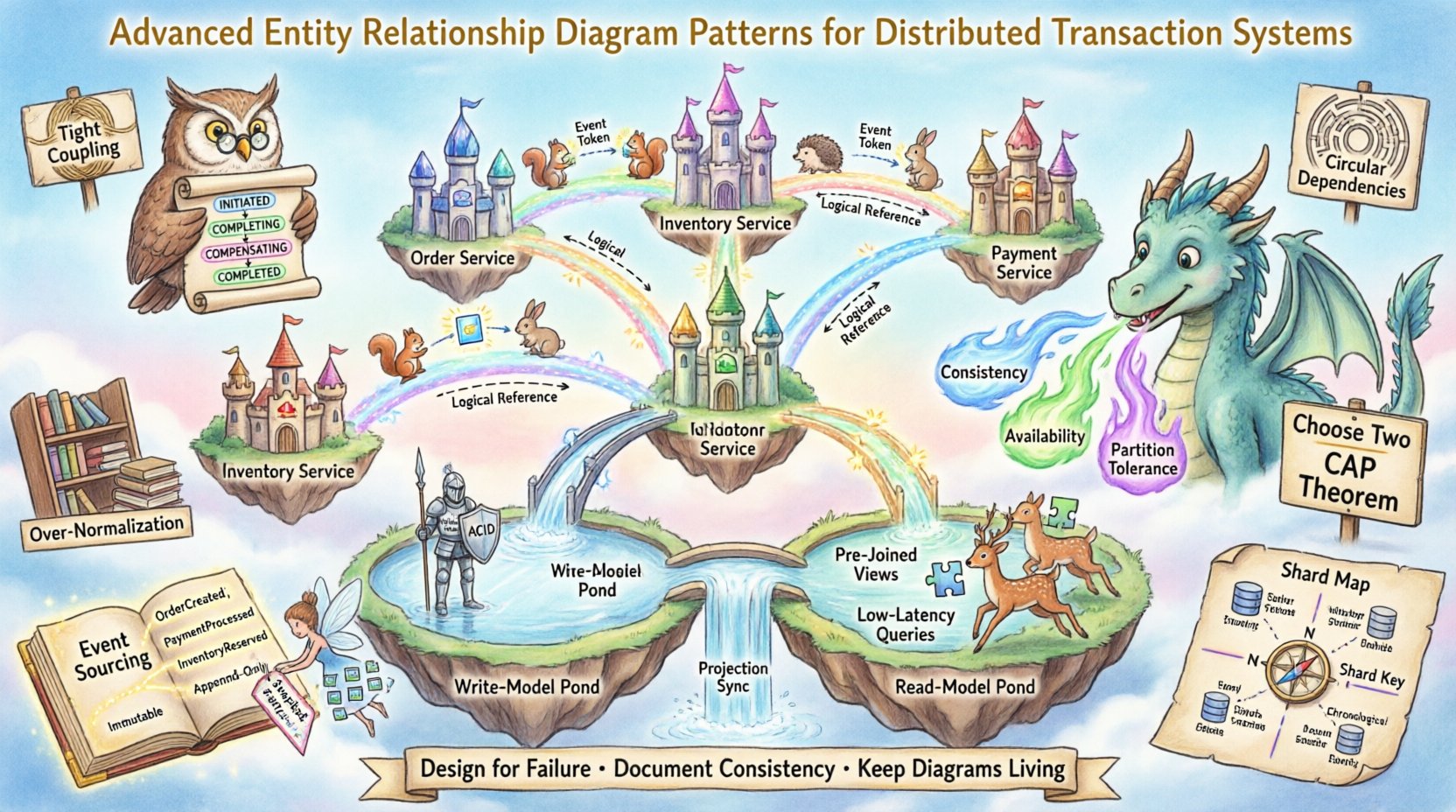
🧠 分散アーキテクチャがデータモデリングに与える影響
特定のパターンに取り組む前に、ネットワーク境界によって課される制約を理解することが不可欠です。モノリシックな構成では、外部キー制約が参照整合性を保証します。しかし分散システムでは、ネットワーク遅延やネットワークパーティションの可能性があるため、即時整合性を確保することはしばしば不可能または極めてコストが高いです。
- ネットワークパーティション: CAP定理は、ネットワークの分裂が発生した場合、一貫性(Consistency)と可用性(Availability)のどちらかを選択しなければならないことを示しています。
- データ所有権:サービスは、密結合を防ぐために自らのデータを所有しなければなりません。これにより、サービス境界を越えた直接的な外部キー関係が制限されます。
- トランザクション境界:複数のデータベースにまたがるグローバルトランザクションは、パフォーマンスおよび信頼性のリスクのため、一般的に推奨されません。
この環境向けにERDを作成する際には、物理的制約だけでなく、論理的な関係を反映しなければなりません。視覚的な表現は、データがどこに存在するか、どのように同期されているかを明確に伝える必要があります。
🔗 外部キーなしで参照整合性を管理する
分散トランザクションシステムでは、物理的な外部キーがしばしば存在しません。代わりに、アプリケーションロジックや非同期イベントによって論理的な関係が強制されます。ERDはこれらの論理的リンクを明確に捉えなければなりません。
1. 論理的識別子参照
物理的なキー制約の代わりに、モデルは一意の識別子を使用します。図を描く際には、関係が論理的リンクであることを明示してください。
- 論理的依存関係を表すには破線を使用してください。
- 関係を「制約」ではなく「参照」でラベル付けしてください。
- IDのデータ型を明確に指定して、スキーマにおける型安全を確保してください。
2. ソフト参照
ハード削除は分散システムではリスクが高くなります。一般的なパターンとして、レコードを削除するのではなく、削除済みとしてマークする方法があります。ERDにはステータスフィールドを含めるべきです。
- 以下のフィールドを含めてください:
is_activeまたはstatus列。 - 図のメモ内にエンティティのライフサイクルを記録してください。
- 削除イベント中に孤立したレコードがどのように処理されるかを明確にしてください。
3. 最終的整合性のモデル化
データがサービス間でレプリケーションされる場合、整合性は即時に得られません。ERDはレプリケーションの遅延を可視化する必要があります。
- 読み取り専用レプリカであるエンティティをマークする。
- 「真実のソース」と「キャッシュされたバージョン」とを区別する。
- 変更を同期するために使用されるメカニズムを示す(例:変更データキャプチャ)。
⚡ サガパターンのモデリング
サガパターンは分散トランザクションの基盤である。トランザクションを一連のローカルトランザクションに分割することで、長時間実行される操作を管理する。各ローカルトランザクションは特定のサービス内のデータを更新し、次のステップをトリガーする。
1. 状態機械の表現
サガは状態に依存するため、ERDはプロセスの状態遷移を明示的にモデル化しなければならない。
- 次の
SagaInstanceエンティティを作成する。 - 以下の状態を定義する:
INITIATED,COMPLETING,COMPENSATING、およびCOMPLETED. - サガインスタンスを、影響を受ける特定のビジネスエンティティにリンクする。
2. 補償トランザクション
ステップが失敗した場合、サガは以前のステップをロールバックしなければならない。図には逆方向の関係を示す必要がある。
- 各ステップに対する補償アクションを文書化する。
- 以下の
SagaLogテーブルがすべてのステップの履歴を記録していることを確認する。 - ロールバックパスを別々の関係線として可視化する。
3. イベントのトリガー
サガはしばしばイベント駆動である。ERDはイベントが状態変更を引き起こす仕組みを示す必要がある。
- 次の
イベントログテーブル。 - イベントを特定のサーガ状態遷移にマッピングする。
- どのサービスがどのイベントを消費するかを示す。
📊 一貫性パターンの比較
異なる一貫性モデル間のトレードオフを理解することは、正確なERD設計にとって不可欠です。以下の表は、一般的なパターンの特徴を概説しています。
| パターン | 一貫性レベル | ERDの複雑さ | 最適な使用ケース |
|---|---|---|---|
| 2段階コミット | 強 | 低 | 内部サービスの調整 |
| サーガオーケストレーション | 最終的 | 高 | 長時間実行されるビジネスプロセス |
| サーガコーディネーション | 最終的 | 中 | 緩く結合されたマイクロサービス |
| CQRSリードモデル | 最終的 | 中 | 高読み取り負荷 |
| イベントソーシング | 強(集約ごと) | 高 | 監査ログと状態の再構築 |
🔄 コマンドクエリ責任分離(CQRS)
CQRSは読み取りモデルと書き込みモデルを分離します。これにより、書き込み側のERDは読み取り側のERDと大きく異なります。
1. 書き込みモデルの設計
書き込みモデルはデータの整合性とビジネスルールに注力します。
- データの冗長性を減らすために正規化を行います。
- 作成時に厳格な検証ルールを適用します。
- スキーマを厳密に保つことで論理エラーを防ぎます。
2. 読み取りモデルの設計
読み取りモデルはパフォーマンスとクエリ速度に注力します。
- 結合を避けるためにデータを非正規化します。
- 一般的なクエリ用に事前に結合されたフィールドを含めます。
- 論理よりもUIの要件に基づいてテーブルを構造化します。
3. 同期メカニズム
ERDは書き込みモデルが読み取りモデルをどのように更新するかを示す必要があります。
- フローをマッピングするためにプロジェクションエンティティを使用します。
- 書き込みと読み取りの可用性の間の遅延を文書化します。
- データのずれに対して再整合プロセスを含めます。
🗂️ シャーディングとパーティションキー
スケーリングには、データを複数のノードにシャーディングする必要があることがよくあります。ERDはデータの分散方法を反映し、効率的なクエリを確保する必要があります。
1. シャードキーの特定
シャードキーはデータを保持するノードを決定します。
- エンティティ定義内でシャードキーを明確にマークします。
- キーがクエリで頻繁に使用されることを確認します。
- データ分布が偏るようなキーを避けてください。
2. シャード間の関係
シャードをまたぐ関係は高コストです。ERDはこれらを強調すべきです。
- シャード間リンクには特定の表記を使用します。
- シャード境界をまたぐ関係の数を最小限に抑えます。
- シャード間結合を避けるために非正規化を検討します。
3. グローバルインデックスとローカルインデックス
インデックス戦略は、シャーディングモデルによって異なります。
- ローカルインデックスは、シングルシャードクエリにおいて効率的です。
- グローバルインデックスはすべてのシャードをスキャンする必要があり、パフォーマンスに影響を与えます。
- どのインデックスがローカルで、どのインデックスがグローバルかをドキュメント化してください。
📜 イベントソーシングと不変状態
イベントソーシングは、エンティティの状態をイベントのシーケンスとして保存します。これにより、ERDがエンティティをどのように表現するかが変わります。
1. イベントストア
主要なエンティティはイベントログになります。
- 作成する:
EventStreamテーブル。 - 次のメタデータを保存する:
event_id,timestamp、およびaggregate_id. - ペイロードが構造化データとして保存されることを確認してください。
2. アグリゲート
アグリゲートは、イベントを発生させるルートエンティティです。
- アグリゲートIDをイベントストリームにリンクしてください。
- 現在の状態をカラムとして保存しないでください。
- ログからイベントを再実行することで、状態を再構築します。
3. スナップショット
パフォーマンスを最適化するために、現在の状態のスナップショットを保存できます。
- 作成する:
Snapshotテーブル。 - スナップショットをアグリゲートIDにリンクしてください。
- スナップショットのバージョン番号をドキュメント化する。
🛡️ 一般的な落とし穴と反パターン
高度なパターンを用いても、ミスは発生する可能性がある。反パターンを認識することは、システムの健全性を維持するのに役立つ。
- 強いつながり:他のサービスのエンティティを直接参照しない。代わりにIDを使用する。
- 循環依存:Entity BがEntity Aに依存している場合、Entity AがEntity Bに依存しないようにする。
- 過剰な正規化:読み込みが重いシステムでは、正規化しすぎるとパフォーマンスが低下する。
- タイムゾーンの無視:分散システムは世界中で動作する。タイムスタンプはUTCで保存する。
- 冪等性の欠如:操作が副作用なしに再試行可能であることを確認する。
🔄 スキーマの進化とバージョン管理
分散システムはモノリスよりも速く進化する。ERDは既存のサービスを破壊せずにスキーマ変更をサポートしなければならない。
1. 後方互換性
スキーマへの変更は、消費者を破壊してはならない。
- フィールドの追加のみを許可し、既存のフィールドを即座に削除または名前変更してはならない。
- フィールドは時間をかけて段階的に非推奨にする。
- スキーマと並行してAPI契約をバージョン管理する。
2. マイグレーション戦略
本番環境でのデータマイグレーションには注意が必要である。
- デプロイには拡張と収縮のパターンを使用する。
- 移行中に古いスキーマが読み取り可能であることを確認する。
- 失敗したマイグレーションに対するロールバック計画をドキュメント化する。
🖼️ サービス間依存関係の可視化
標準的なERDは1つのデータベース内のテーブルを示す。分散ERDはサービスを示さなければならない。
1. サービス境界
テーブルを所有するサービスごとにグループ化する。
- 各サービスに別々のコンテナを使用する。
- コンテナにサービス名をラベル付けしてください。
- 矢印を使用して、コンテナ間のデータフローを示してください。
2. データフロー
サービス間でデータがどのように移動するかを示してください。
- 同期呼び出しには実線を使用してください。
- 非同期イベントには破線を使用してください。
- データフローの方向をラベル付けしてください。
3. 統合ポイント
サービスが相互に作用する場所を特定してください。
- 図の中でAPIゲートウェイを強調してください。
- メッセージブローカーを仲介者としてマークしてください。
- 各統合で使用されるプロトコルを文書化してください。
🏁 システム設計者のための最終的な考慮事項
分散トランザクションを設計することは、複雑さを管理する作業です。ERDは、この複雑さをチームに伝えるためのツールです。テーブルを単に表示するだけでなく、システムの論理を示すべきです。
- 物理的制約よりも論理的な関係に注目してください。
- すべての関係について、整合性の保証を文書化してください。
- データモデルにおいて、障害シナリオを想定して計画してください。
- システムの進化に伴い、図を常に最新の状態に保ってください。
これらのパターンに従うことで、高可用性とデータ整合性をサポートする設計図を作成できます。図は開発と保守をガイドする、生きている文書になります。