











Diseñar modelos de datos para la infraestructura moderna requiere un cambio fundamental en el pensamiento. Los diagramas tradicionales de relaciones de entidades (ERD) servían bien a las arquitecturas monolíticas, donde una única instancia de base de datos gestionaba todas las transacciones. Sin embargo, a medida que los sistemas evolucionan hacia entornos distribuidos, las reglas de integridad de datos y el mapeo de relaciones cambian significativamente. Esta guía explora patrones avanzados de ERD específicamente adaptados para sistemas complejos de transacciones distribuidas. Examinaremos cómo modelar la consistencia, gestionar el estado entre servicios y visualizar dependencias sin depender de productos de software específicos.
En un contexto distribuido, el límite entre la propiedad de datos se vuelve fluido. Una entidad podría existir en múltiples almacenes lógicos, lo que requiere una definición clara de cómo se mantienen las relaciones. Este documento proporciona un enfoque estructurado para modelar estas complejidades.
🧠 El impacto de la arquitectura distribuida en el modelado de datos
Antes de adentrarnos en patrones específicos, es esencial comprender las restricciones impuestas por los límites de red. En una configuración monolítica, una restricción de clave foránea garantiza la integridad referencial. En un sistema distribuido, la latencia de red y las posibles particiones de red significan que la consistencia inmediata a menudo es imposible o prohibitivamente costosa.
- Particiones de red: La teoría CAP establece que en caso de una división de red, debes elegir entre consistencia y disponibilidad.
- Propiedad de datos: Los servicios deben poseer sus propios datos para evitar acoplamiento estrecho. Esto limita las relaciones directas de clave foránea entre los límites de los servicios.
- Límites de transacción: Las transacciones globales que abarcan múltiples bases de datos generalmente se desaconsejan debido a los riesgos de rendimiento y fiabilidad.
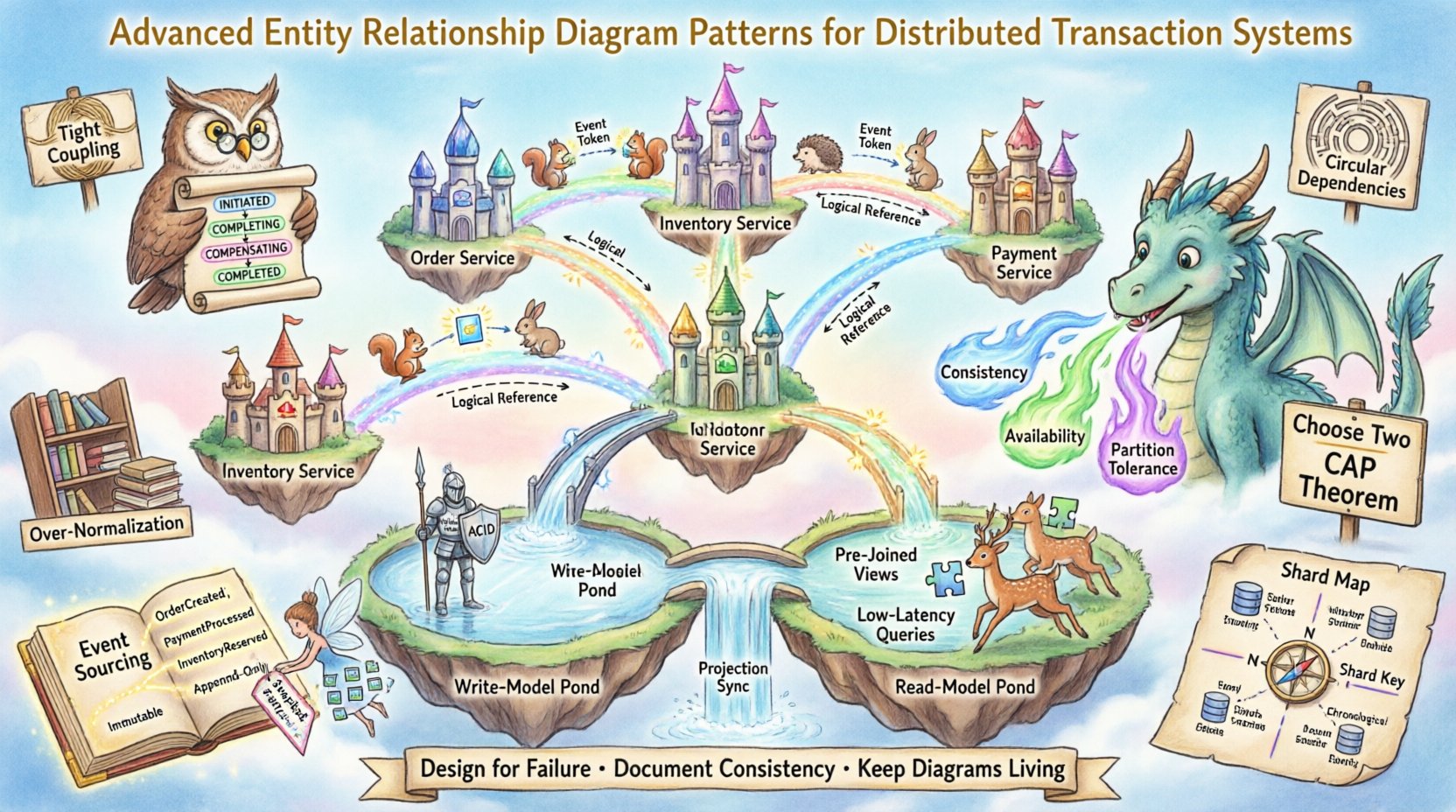
Al crear un ERD para este entorno, el diagrama debe reflejar relaciones lógicas, y no solo restricciones físicas. La representación visual debe comunicar dónde reside los datos y cómo se sincronizan.
🔗 Gestionar la integridad referencial sin claves foráneas
En un sistema de transacciones distribuidas, las claves foráneas físicas suelen estar ausentes. En su lugar, las relaciones lógicas se imponen mediante lógica de aplicación o eventos asíncronos. El ERD debe capturar claramente estas conexiones lógicas.
1. Referencias de identificadores lógicos
En lugar de una restricción de clave física, los modelos utilizan identificadores únicos. Al dibujar el diagrama, indique que una relación es un enlace lógico.
- Utilice líneas punteadas para representar dependencias lógicas.
- Etiquete la relación como “Referencia” en lugar de “Restricción”.
- Especifique el tipo de dato del ID para garantizar la seguridad de tipos en el esquema.
2. Referencia suave
Las eliminaciones permanentes son riesgosas en sistemas distribuidos. Un patrón común consiste en marcar los registros como eliminados en lugar de eliminarlos. El ERD debe incluir un campo de estado.
- Incluya un
is_activeostatuscolumna. - Documente el ciclo de vida de la entidad en las notas del diagrama.
- Aclare cómo se manejan los registros huérfanos durante un evento de eliminación.
3. Modelado de consistencia eventual
Cuando los datos se replican entre servicios, la consistencia no es inmediata. El ERD debe visualizar el retraso de replicación.
- Marque las entidades que son réplicas de solo lectura.
- Distinga entre la “Fuente de la Verdad” y la “Versión en caché”.
- Indique el mecanismo utilizado para sincronizar los cambios (por ejemplo, Captura de Datos de Cambio).
⚡ Modelado del patrón Saga
El patrón Saga es una piedra angular de las transacciones distribuidas. Gestiona operaciones de larga duración dividiendo una transacción en una secuencia de transacciones locales. Cada transacción local actualiza datos dentro de un servicio específico y desencadena el siguiente paso.
1. Representación de máquinas de estado
Dado que las Sagas dependen del estado, el diagrama ER debe modelar explícitamente las transiciones de estado del proceso.
- Cree una
SagaInstanceentidad. - Defina estados como
INICIADO,COMPLETANDO,COMPENSANDO, yCOMPLETADO. - Vincule la instancia de Saga con las entidades empresariales específicas que afecta.
2. Transacciones de compensación
Si un paso falla, la Saga debe deshacer los pasos anteriores. El diagrama debe mostrar las relaciones inversas.
- Documente la acción de compensación para cada paso.
- Asegúrese de que la tabla
SagaLogregistre el historial de todos los pasos. - Visualice la ruta de deshacer como una línea de relación separada.
3. Disparadores de eventos
Las Sagas suelen ser impulsadas por eventos. El diagrama ER debe mostrar cómo los eventos desencadenan cambios de estado.
- Incluya un
Registro de eventostabla. - Asocie eventos con las transiciones específicas de estado de la Saga.
- Indique qué servicios consumen qué eventos.
📊 Comparación de patrones de consistencia
Comprender las compensaciones entre diferentes modelos de consistencia es vital para un diseño preciso del ERD. La tabla a continuación describe las características de los patrones comunes.
| Patrón | Nivel de consistencia | Complejidad del ERD | Mejor caso de uso |
|---|---|---|---|
| Compromiso de dos fases | Fuerte | Baja | Coordinación interna de servicios |
| Orquestación de Saga | Eventual | Alta | Procesos de negocio de larga duración |
| Coreografía de Saga | Eventual | Media | Microservicios débilmente acoplados |
| Modelo de lectura CQRS | Eventual | Media | Cargas de trabajo con alta lectura |
| Origen de eventos | Fuerte (por agregado) | Alta | Rastros de auditoría y reconstrucción de estado |
🔄 Separación de responsabilidades de comandos y consultas (CQRS)
CQRS separa los modelos de lectura y escritura. Esto significa que el diagrama ERD del lado de escritura difiere significativamente del diagrama ERD del lado de lectura.
1. Diseño del modelo de escritura
El modelo de escritura se enfoca en la integridad de los datos y las reglas de negocio.
- Normalice los datos para reducir la redundancia.
- Aplicar reglas estrictas de validación en la creación.
- Mantenga el esquema rígido para prevenir errores lógicos.
2. Diseño del modelo de lectura
El modelo de lectura se enfoca en el rendimiento y la velocidad de consulta.
- Denormalice los datos para evitar uniones.
- Incluya campos previamente unidos para consultas comunes.
- Estructurar las tablas según los requisitos de la interfaz de usuario en lugar de la lógica.
3. Mecanismo de sincronización
El diagrama ERD debe mostrar cómo el modelo de escritura actualiza el modelo de lectura.
- Utilice entidades de proyección para mapear el flujo.
- Documente el retraso entre la disponibilidad de escritura y lectura.
- Incluya un proceso de reconciliación para el desplazamiento de datos.
🗂️ Fragmentación y claves de partición
La escalabilidad a menudo requiere fragmentar los datos en múltiples nodos. El diagrama ERD debe reflejar cómo se distribuyen los datos para garantizar una consulta eficiente.
1. Identificación de la clave de fragmentación
La clave de fragmentación determina qué nodo almacena los datos.
- Marque claramente la clave de fragmentación en la definición de la entidad.
- Asegúrese de que la clave se utilice con frecuencia en las consultas.
- Evite claves que generen una distribución sesgada de datos.
2. Relaciones entre fragmentos
Las relaciones que abarcan fragmentos son costosas. El diagrama ERD debe resaltar estas.
- Utilice una notación específica para los enlaces entre fragmentos.
- Minimice el número de relaciones que cruzan los límites de fragmentos.
- Considere la denormalización para evitar uniones entre fragmentos.
3. Índices globales frente a locales
Las estrategias de indexación difieren según el modelo de particionado.
- Los índices locales son eficientes para consultas en un solo shard.
- Los índices globales requieren escanear todos los shards, afectando el rendimiento.
- Documente cuáles índices son locales y cuáles son globales.
📜 Recuperación de eventos y estado inmutable
La recuperación de eventos almacena el estado de una entidad como una secuencia de eventos. Esto cambia la forma en que el ERD representa a la entidad misma.
1. El Almacén de Eventos
La entidad principal se convierte en el registro de eventos.
- Cree una
EventStreamtabla. - Almacene metadatos como
event_id,timestamp, yaggregate_id. - Asegúrese de que la carga útil se almacene como datos estructurados.
2. Agrupaciones
Las agrupaciones son las entidades raíz que desencadenan eventos.
- Vincule el ID de la agrupación con la secuencia de eventos.
- No almacene el estado actual como una columna.
- Reconstruya el estado reproduciendo eventos desde el registro.
3. Instantáneas
Para optimizar el rendimiento, se pueden almacenar instantáneas del estado actual.
- Cree una
Snapshottabla. - Vincule la instantánea con el ID de la agrupación.
- Documente el número de versión para la instantánea.
🛡️ Errores comunes y patrones incorrectos
Aunque se utilicen patrones avanzados, pueden ocurrir errores. Reconocer los patrones incorrectos ayuda a mantener la salud del sistema.
- Acoplamiento fuerte:Evite referirse a entidades de otros servicios directamente. Use identificadores en su lugar.
- Dependencias circulares:Asegúrese de que la entidad A no dependa de la entidad B si la entidad B depende de la entidad A.
- Sobrenormalización:En sistemas con muchas lecturas, normalice en exceso y el rendimiento sufrirá.
- Ignorar husos horarios:Los sistemas distribuidos operan a nivel global. Almacene las marcas de tiempo en UTC.
- Falta de idempotencia:Asegúrese de que las operaciones puedan repetirse sin efectos secundarios.
🔄 Evolución y versionado de esquemas
Los sistemas distribuidos evolucionan más rápido que los monolíticos. El diagrama ER debe permitir cambios en el esquema sin romper los servicios existentes.
1. Compatibilidad hacia atrás
Los cambios en el esquema no deben romper a los consumidores.
- Agregue campos solo, nunca elimine ni cambie el nombre de los existentes de inmediato.
- Desactive los campos gradualmente con el tiempo.
- Vere la versión de los contratos de API junto con el esquema.
2. Estrategias de migración
Manejar la migración de datos en producción requiere cuidado.
- Use los patrones de expansión y contracción para la implementación.
- Asegúrese de que el esquema antiguo permanezca legible durante la transición.
- Documente el plan de reversión para las migraciones fallidas.
🖼️ Visualización de dependencias entre servicios
Un ERD estándar muestra tablas dentro de una sola base de datos. Un ERD distribuido debe mostrar servicios.
1. Límites del servicio
Agrupe las tablas según el servicio que las posee.
- Use contenedores distintos para cada servicio.
- Etiquete el contenedor con el nombre del servicio.
- Muestre el flujo de datos entre contenedores utilizando flechas.
2. Flujo de datos
Indique cómo se mueve los datos entre servicios.
- Use líneas sólidas para llamadas síncronas.
- Use líneas punteadas para eventos asíncronos.
- Etiquete la dirección del flujo de datos.
3. Puntos de integración
Identifique dónde interactúan los servicios.
- Resalte las pasarelas de API en el diagrama.
- Marque los brokers de mensajes como intermediarios.
- Documente el protocolo utilizado para cada integración.
🏁 Consideraciones finales para los diseñadores de sistemas
Diseñar para transacciones distribuidas es un ejercicio en la gestión de la complejidad. El ERD es una herramienta para comunicar esta complejidad al equipo. No debe mostrar solo tablas; debe mostrar la lógica del sistema.
- Enfóquese en las relaciones lógicas sobre las restricciones físicas.
- Documente las garantías de consistencia para cada relación.
- Planee escenarios de falla en el modelo de datos.
- Mantenga el diagrama actualizado a medida que evoluciona el sistema.
Al seguir estos patrones, crea una plantilla que respalda la alta disponibilidad y la integridad de los datos. El diagrama se convierte en un documento vivo que guía el desarrollo y la mantenimiento.