











Die Gestaltung von Datenmodellen für moderne Infrastrukturen erfordert eine grundlegende Veränderung des Denkens. Traditionelle Entitäts-Beziehungs-Diagramme (ERD) waren für monolithische Architekturen gut geeignet, bei denen eine einzelne Datenbankinstanz alle Transaktionen verwaltete. Doch wenn Systeme in verteilte Umgebungen übergehen, ändern sich die Regeln für Datenintegrität und Beziehungsmapping erheblich. Dieser Leitfaden untersucht erweiterte ERD-Muster, die speziell für komplexe verteilte Transaktionssysteme entwickelt wurden. Wir werden untersuchen, wie Konsistenz modelliert, der Zustand über Dienste hinweg verwaltet und Abhängigkeiten visualisiert wird, ohne sich auf bestimmte Softwareprodukte zu stützen.
In einem verteilten Kontext wird die Grenze zwischen Datenbesitz fließend. Eine Entität könnte in mehreren logischen Speichern existieren, was eine klare Definition erfordert, wie Beziehungen aufrechterhalten werden. Dieses Dokument bietet einen strukturierten Ansatz zur Modellierung dieser Komplexitäten.
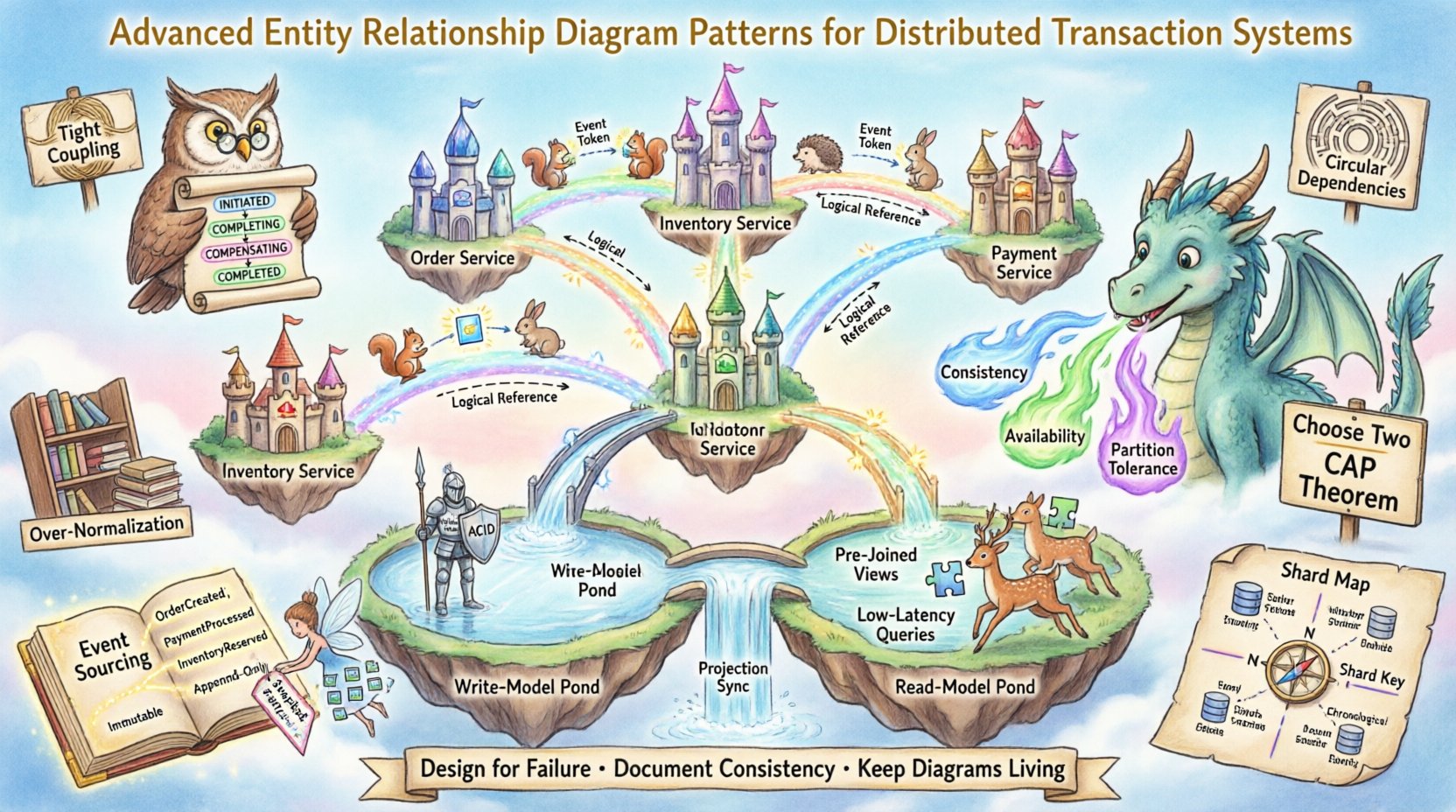
🧠 Der Einfluss verteilter Architekturen auf die Datenmodellierung
Bevor wir uns spezifischen Mustern zuwenden, ist es unerlässlich, die durch Netzwerkgrenzen auferlegten Beschränkungen zu verstehen. In einer monolithischen Umgebung garantiert eine Fremdschlüsselbeschränkung die Referenzintegrität. In einem verteilten System bedeuten Netzwerklatenz und mögliche Partitionen, dass sofortige Konsistenz oft unmöglich oder prohibitiv teuer ist.
- Netzwerkpartitionen: Der CAP-Satz besagt, dass im Falle einer Netzwerkpartition zwischen Konsistenz und Verfügbarkeit gewählt werden muss.
- Datenbesitz: Dienste müssen ihre Daten besitzen, um enge Kopplung zu vermeiden. Dies begrenzt direkte Fremdschlüsselbeziehungen über Dienstgrenzen hinweg.
- Transaktionsgrenzen: Globale Transaktionen, die mehrere Datenbanken umfassen, werden aufgrund von Leistungs- und Zuverlässigkeitsrisiken im Allgemeinen abgeraten.
Beim Erstellen eines ERD für diese Umgebung muss das Diagramm logische Beziehungen widerspiegeln, nicht nur physische Beschränkungen. Die visuelle Darstellung muss kommunizieren, wo die Daten liegen und wie sie synchronisiert werden.
🔗 Verwaltung der Referenzintegrität ohne Fremdschlüssel
In einem verteilten Transaktionssystem fehlen physische Fremdschlüssel oft. Stattdessen werden logische Beziehungen über Anwendungslogik oder asynchrone Ereignisse durchgesetzt. Das ERD muss diese logischen Verbindungen klar darstellen.
1. Logische Identifizierer-Verweise
Anstelle einer physischen Schlüsselbeschränkung verwenden Modelle eindeutige Identifizierer. Beim Zeichnen des Diagramms sollte angezeigt werden, dass eine Beziehung eine logische Verbindung darstellt.
- Verwenden Sie gestrichelte Linien, um logische Abhängigkeiten darzustellen.
- Bezeichnen Sie die Beziehung als „Verweis“ statt „Beschränkung“.
- Geben Sie den Datentyp der ID an, um Typ-Sicherheit im Schema zu gewährleisten.
2. Weiche Verweise
Harte Löschungen sind in verteilten Systemen riskant. Ein verbreitetes Muster besteht darin, Datensätze als gelöscht zu markieren, anstatt sie zu entfernen. Das ERD sollte ein Status-Feld enthalten.
- Enthalten Sie ein
is_activeoderstatusSpalte. - Dokumentieren Sie den Lebenszyklus der Entität in den Diagrammnotizen.
- Klären Sie, wie verwaiste Datensätze bei einem Löschereignis behandelt werden.
3. Modellierung der eventualen Konsistenz
Wenn Daten über Dienste hinweg repliziert werden, ist Konsistenz nicht sofort gegeben. Das ERD sollte die Replikationsverzögerung visualisieren.
- Markieren Sie Entitäten, die schreibgeschützte Replikate sind.
- Unterscheiden Sie zwischen der „Quelle der Wahrheit“ und der „Gecachten Version“.
- Geben Sie die verwendete Methode zur Synchronisierung von Änderungen an (z. B. Change Data Capture).
⚡ Modellierung des Saga-Musters
Das Saga-Muster ist ein Eckpfeiler verteilter Transaktionen. Es verwaltet langlaufende Operationen, indem es eine Transaktion in eine Folge von lokalen Transaktionen aufteilt. Jede lokale Transaktion aktualisiert Daten innerhalb eines bestimmten Dienstes und löst den nächsten Schritt aus.
1. Darstellung von Zustandsmaschinen
Da Sagas auf Zuständen basieren, muss das ERD die Zustandsübergänge des Prozesses explizit modellieren.
- Erstellen Sie eine
SagaInstanceEntität. - Definieren Sie Zustände wie
INITIERT,ABGESCHLOSSEN,KOMPENSIEREND, undABGESCHLOSSEN. - Verknüpfen Sie die Saga-Instanz mit den spezifischen Geschäftsentitäten, die sie beeinflusst.
2. Kompensierende Transaktionen
Wenn ein Schritt fehlschlägt, muss die Saga die vorherigen Schritte rückgängig machen. Das Diagramm sollte die umgekehrten Beziehungen zeigen.
- Dokumentieren Sie die kompensierende Aktion für jeden Schritt.
- Stellen Sie sicher, dass die
SagaLogTabelle die Geschichte aller Schritte erfasst. - Visualisieren Sie den Rückgängigmachungspfad als separate Beziehungsline.
3. Ereignis-Auslöser
Sagas sind oft ereignisgesteuert. Das ERD muss zeigen, wie Ereignisse Zustandsänderungen auslösen.
- Schließen Sie ein
EreignisprotokollTabelle. - Weisen Sie Ereignisse den spezifischen Zustandsübergängen der Saga zu.
- Geben Sie an, welche Dienste welche Ereignisse verarbeiten.
📊 Vergleich von Konsistenzmustern
Das Verständnis der Vor- und Nachteile zwischen verschiedenen Konsistenzmodellen ist entscheidend für eine genaue ERD-Entwicklung. Die folgende Tabelle beschreibt die Eigenschaften gängiger Muster.
| Muster | Konsistenzstufe | ERD-Komplexität | Beste Anwendungsfälle |
|---|---|---|---|
| Zwei-Phasen-Commit | Stark | Niedrig | Interne Dienstkoordination |
| Saga-Orchestrierung | Letztendlich | Hoch | Langlaufende Geschäftsprozesse |
| Saga-Choreografie | Letztendlich | Mittel | Schwach gekoppelte Mikrodienste |
| CQRS-Lese-Modell | Letztendlich | Mittel | Hochleistungs-Leseanforderungen |
| Ereignisquellen | Stark (pro Aggregat) | Hoch | Audit-Protokolle und Zustandsrekonstruktion |
🔄 Befehl-Abfrage-Aufgaben-Trennung (CQRS)
CQRS trennt das Lese- und Schreibmodell. Das bedeutet, dass das ERD für die Schreibseite sich erheblich vom ERD für die Leseseite unterscheiden wird.
1. Gestaltung des Schreibmodells
Das Schreibmodell konzentriert sich auf Datenintegrität und Geschäftsregeln.
- Normalisieren Sie die Daten, um Redundanz zu reduzieren.
- Strenge Validierungsregeln bei der Erstellung durchsetzen.
- Halten Sie das Schema fest, um logische Fehler zu vermeiden.
2. Gestaltung des Lesemodells
Das Lesemodell konzentriert sich auf Leistung und Abfragegeschwindigkeit.
- Dekomprimieren Sie die Daten, um Joins zu vermeiden.
- Schließen Sie vorverknüpfte Felder für häufige Abfragen ein.
- Strukturieren Sie Tabellen basierend auf UI-Anforderungen statt auf Logik.
3. Synchronisationsmechanismus
Das ERD muss zeigen, wie das Schreibmodell das Lesemodell aktualisiert.
- Verwenden Sie Projektionselemente, um den Fluss abzubilden.
- Dokumentieren Sie die Verzögerung zwischen Schreib- und Leseverfügbarkeit.
- Schließen Sie einen Abgleichprozess für Datenabweichungen ein.
🗂️ Sharding und Partitionsschlüssel
Skalierung erfordert oft das Sharding von Daten über mehrere Knoten. Das ERD muss zeigen, wie die Daten verteilt werden, um eine effiziente Abfrage zu gewährleisten.
1. Identifizierung des Shard-Schlüssels
Der Shard-Schlüssel bestimmt, welcher Knoten die Daten enthält.
- Markieren Sie den Shard-Schlüssel eindeutig in der Entitätsdefinition.
- Stellen Sie sicher, dass der Schlüssel häufig in Abfragen verwendet wird.
- Vermeiden Sie Schlüssel, die zu einer verzerrten Datenverteilung führen.
2. Beziehungen über Shard-Grenzen hinweg
Beziehungen, die über Shard-Grenzen hinwegreichen, sind kostspielig. Das ERD sollte diese hervorheben.
- Verwenden Sie eine spezifische Notation für Verbindungen über Shard-Grenzen hinweg.
- Minimieren Sie die Anzahl der Beziehungen, die Shard-Grenzen überschreiten.
- Berücksichtigen Sie die Dekompression, um Joins über Shard-Grenzen hinweg zu vermeiden.
3. Globale vs. lokale Indizes
Indizierungsstrategien unterscheiden sich je nach Sharding-Modell.
- Lokale Indizes sind effizient für Abfragen in einzelnen Shards.
- Globale Indizes erfordern das Scannen aller Shards und beeinträchtigen die Leistung.
- Dokumentieren Sie, welche Indizes lokal und welche global sind.
📜 Event Sourcing und unveränderlicher Zustand
Event Sourcing speichert den Zustand einer Entität als Folge von Ereignissen. Dies verändert, wie das ERD die Entität selbst darstellt.
1. Der Ereignisspeicher
Die primäre Entität wird zum Ereignisprotokoll.
- Erstellen Sie eine
EreignisstromTabelle. - Speichern Sie Metadaten wie
ereignis_id,Zeitstempel, undaggregat_id. - Stellen Sie sicher, dass der Payload als strukturierte Daten gespeichert wird.
2. Aggregatoren
Aggregatoren sind die Stamm-Entitäten, die Ereignisse auslösen.
- Verknüpfen Sie die Aggregat-ID mit dem Ereignisstrom.
- Speichern Sie den aktuellen Zustand nicht als Spalte.
- Stellen Sie den Zustand durch erneutes Abspielen der Ereignisse aus dem Protokoll wieder her.
3. Momentaufnahmen
Um die Leistung zu optimieren, können Momentaufnahmen des aktuellen Zustands gespeichert werden.
- Erstellen Sie eine
MomentaufnahmeTabelle. - Verknüpfen Sie die Momentaufnahme mit der Aggregat-ID.
- Dokumentieren Sie die Versionsnummer für den Snapshot.
🛡️ Häufige Fehler und Anti-Muster
Selbst mit fortgeschrittenen Mustern können Fehler auftreten. Das Erkennen von Anti-Mustern hilft, die Systemgesundheit aufrechtzuerhalten.
- Starke Kopplung:Vermeiden Sie direkte Verweise auf Entitäten aus anderen Diensten. Verwenden Sie stattdessen IDs.
- Zirkuläre Abhängigkeiten:Stellen Sie sicher, dass Entity A nicht von Entity B abhängt, wenn Entity B von Entity A abhängt.
- Über-Normalisierung:Bei lesedichten Systemen führt zu starke Normalisierung zu Leistungseinbußen.
- Ignorieren von Zeitzonen:Verteilte Systeme arbeiten global. Speichern Sie Zeitstempel in UTC.
- Fehlende Idempotenz:Stellen Sie sicher, dass Operationen ohne Nebenwirkungen wiederholt werden können.
🔄 Schema-Evolution und Versionierung
Verteilte Systeme entwickeln sich schneller als Monolithen. Das ERD muss Änderungen am Schema unterstützen, ohne bestehende Dienste zu brechen.
1. Rückwärtskompatibilität
Änderungen am Schema dürfen die Verbraucher nicht brechen.
- Fügen Sie nur Felder hinzu, entfernen oder benennen Sie bestehende Felder niemals sofort um.
- Markieren Sie Felder schrittweise als veraltet.
- Versionieren Sie die API-Verträge zusammen mit dem Schema.
2. Migrationsstrategien
Die Behandlung von Datenmigrationen in der Produktion erfordert Sorgfalt.
- Verwenden Sie Erweiterungs- und Vertragsmuster für die Bereitstellung.
- Stellen Sie sicher, dass das alte Schema während des Übergangs lesbar bleibt.
- Dokumentieren Sie den Rückgängigmachungsplan für fehlgeschlagene Migrationen.
🖼️ Visualisierung von Dienstübergreifenden Abhängigkeiten
Ein standardmäßiges ERD zeigt Tabellen innerhalb einer Datenbank. Ein verteiltes ERD muss Dienste anzeigen.
1. Dienstgrenzen
Gruppieren Sie Tabellen nach dem Dienst, der sie besitzt.
- Verwenden Sie für jeden Dienst separate Container.
- Beschriften Sie den Container mit dem Dienstnamen.
- Zeigen Sie den Datenfluss zwischen Containern mit Pfeilen an.
2. Datenfluss
Geben Sie an, wie Daten zwischen Diensten bewegt werden.
- Verwenden Sie durchgezogene Linien für synchrone Aufrufe.
- Verwenden Sie gestrichelte Linien für asynchrone Ereignisse.
- Beschriften Sie die Richtung des Datenflusses.
3. Integrationspunkte
Identifizieren Sie, wo Dienste interagieren.
- Hervorheben Sie API-Gateways im Diagramm.
- Markieren Sie Nachrichtenbroker als Vermittler.
- Dokumentieren Sie das für jede Integration verwendete Protokoll.
🏁 Endgültige Überlegungen für Systemdesigner
Das Design für verteilte Transaktionen ist eine Übung im Umgang mit Komplexität. Das ERD ist ein Werkzeug, um diese Komplexität dem Team zu vermitteln. Es sollte nicht nur Tabellen zeigen; es sollte die Logik des Systems zeigen.
- Konzentrieren Sie sich auf logische Beziehungen statt auf physische Einschränkungen.
- Dokumentieren Sie die Konsistenzgarantien für jede Beziehung.
- Planen Sie für Fehlerfälle im Datenmodell.
- Halten Sie das Diagramm aktualisiert, während sich das System weiterentwickelt.
Durch die Einhaltung dieser Muster erstellen Sie eine Bauplanung, die hohe Verfügbarkeit und Datenintegrität unterstützt. Das Diagramm wird zu einem lebendigen Dokument, das die Entwicklung und Wartung leitet.