











Моделирование данных — это основа любой надежной архитектуры базы данных. Хотя теория часто преподается в университетских курсах, практическое применение в производственных средах раскрывает сложную картину, полную крайних случаев, узких мест производительности и логической неоднозначности. Диаграммы сущностей и связей (ERD) служат чертежами для этих систем, однако они часто становятся источником споров, когда реальный мир отказывается помещаться в четкие рамки и линии.
Мы провели беседу с группой ведущих специалистов по базам данных и архитекторов данных, чтобы проанализировать сценарии, которые постоянно вызывают затруднения у команд на этапе проектирования. Речь идет не о теоретических упражнениях, а о реальных проблемах, возникающих, когда бизнес-требования сталкиваются с физическими ограничениями хранения данных. Цель состоит не в предоставлении быстрого решения, а в глубоком понимании существующих компромиссов.
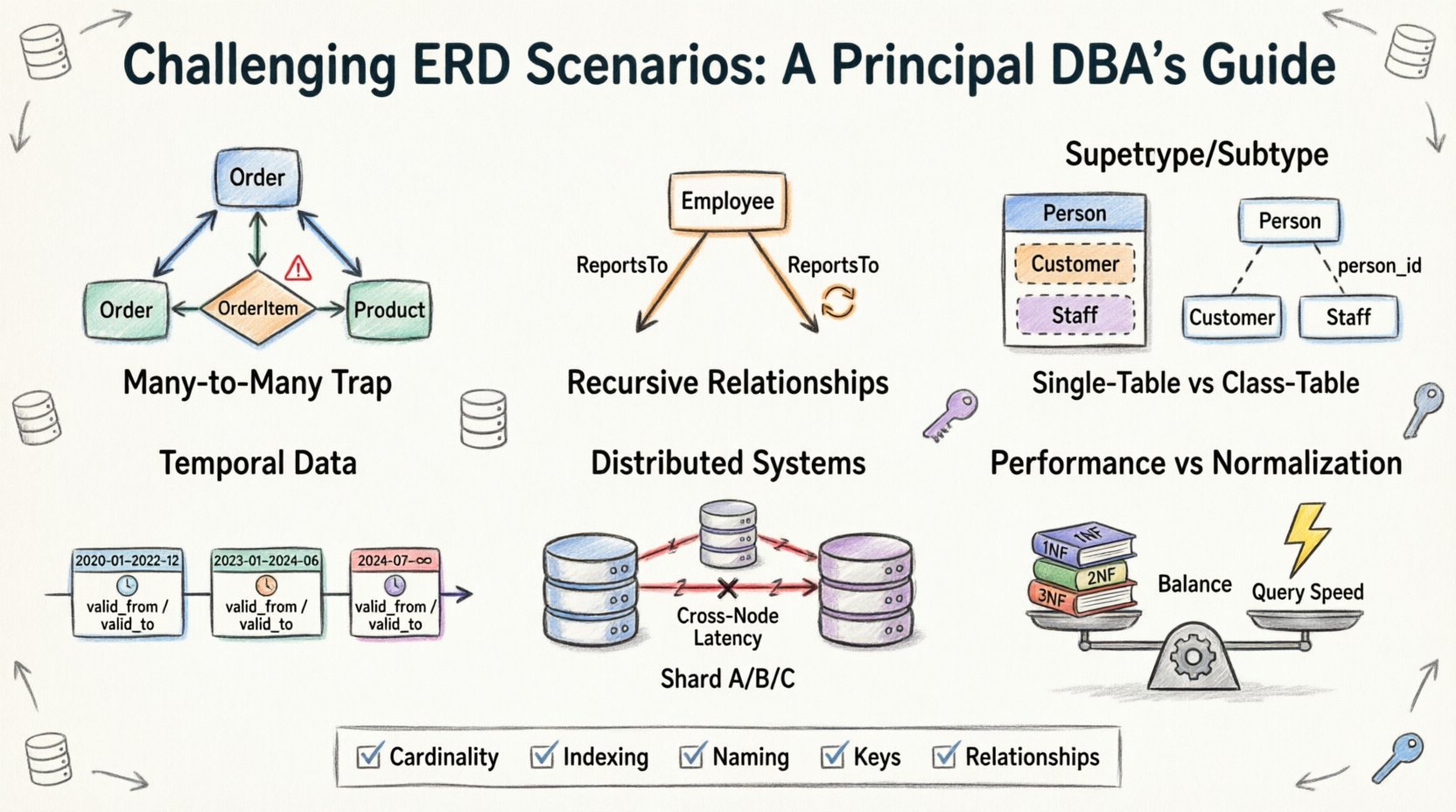
1. Ловушка «многие ко многим»: за пределами простых таблиц соединений 🕸️
Наиболее распространенной отправной точкой при проектировании диаграмм сущностей и связей является отношение «многие ко многим». Это кажется интуитивно понятным: студент может записываться на много курсов, а курс может включать множество студентов. Стандартное решение предполагает использование промежуточной или ассоциативной таблицы. Однако сложность возникает, когда в само отношение добавляются атрибуты.
- Проблема:Часто команды пытаются хранить данные о зачислении (например, оценки или даты регистрации) в основной таблице студентов или курсов, что приводит к огромной избыточности или пустым значениям.
- Реальность:Само отношение является сущностью. Оно должно иметь собственный первичный ключ и внешние ключи, указывающие на родительские сущности.
- Вызов:Обработка каскадного удаления. Если курс удаляется, что происходит с записями о зачислении? Если запись о зачислении удаляется, исчезает ли студент? Эти решения определяют целостность данных.
В ходе нашего обсуждения один ведущий специалист по базам данных отметил, что ассоциативная таблица часто становится узким местом производительности. При запросе данных через эту точку соединения база данных должна выполнять операцию соединения, которая плохо масштабируется при росте количества строк до миллионов. Решение не всегда архитектурное; иногда требуется денормализация, но это вводит аномалии обновления.
Ключевые соображения при работе с отношениями «многие ко многим»:
- Имеет ли отношение атрибуты, требующие индексации?
- Отношение активное или историческое? (например, отличается ли текущее зачисление от прошлого?)
- Как система будет обрабатывать «сиротские» записи, если родительская сущность будет удалена?
2. Рекурсивные отношения: иерархии с самоссылками 🌳
Иерархические данные повсюду. Подумайте об организационной структуре, спецификации материалов или ветке комментариев на форуме. Моделирование таких данных требует, чтобы таблица ссылалась сама на себя. Хотя концептуально это просто, реализация в реляционной схеме порождает конкретные сложности, связанные с глубиной и обходом.
Структурная проблема:
Вы создаете таблицу с первичным ключом и столбцом внешнего ключа, который ссылается на первичный ключ той же таблицы. Такой столбец часто называют «parent_id». У корневого узла родительское значение — null.
Проблема производительности:
Стандартные запросы SQL испытывают трудности с глубокими иерархиями. Если вам нужно получить менеджера и всех его прямых и косвенных подчиненных, простое соединение (JOIN) недостаточно. Вам потребуются рекурсивные выражения общих таблиц (CTE) или хранимые процедуры, которые проходят по уровням. Это может быть вычислительно затратно.
Проблема целостности:
Циклические ссылки — тихий убийца. Если сотрудник А управляет сотрудником Б, а сотрудник Б управляет сотрудником А, у вас возникает цикл. База данных должна предотвращать это, или логика приложения должна его обнаруживать. В крупных системах цикл может вызвать бесконечный цикл в инструментах отчетности.
- Ограничения глубины:Большинство систем ограничивают глубину иерархии (например, 32 уровня), чтобы предотвратить ошибки переполнения стека при обходе.
- Агрегация путей:Вычисление общей стоимости или количества поддерева требует рекурсивной логики, которую трудно оптимизировать в стандартных планах запросов.
3. Моделирование супертипа и подтипа: дилемма наследования 🧬
В объектно-ориентированном программировании наследование — стандарт. В реляционных базах данных это выбор архитектуры, влияющий на хранение и извлечение данных. Вопрос в том, моделировать ли транспортное средство как одну таблицу, или разбить его на таблицы Vehicle, Car и Truck?
Вариант А: наследование в одной таблице
Все атрибуты для всех подтипов находятся в одной таблице. Для неиспользуемых атрибутов используются значения NULL.
- Плюсы:Простые запросы, не требуется выполнение соединений для поиска любого транспортного средства.
- Минусы:Рост размера таблицы, трудно обеспечить ограничения, специфичные для подтипа, много столбцов с возможными значениями NULL.
Вариант Б: наследование в таблицах классов
Одна таблица для супертипа (Транспортное средство), и отдельные таблицы для подтипов (Автомобиль, Грузовик), связанные первичным ключом.
- Плюсы:Чистое разделение, отсутствие значений NULL, строгие ограничения для каждого подтипа.
- Минусы:Запросы требуют соединения нескольких таблиц, что может повлиять на производительность чтения.
Наши ведущие DBA отметили, что выбор часто зависит от шаблонов запросов. Если вы часто запрашиваете конкретные подтипы, подход с таблицами классов будет лучше. Если вы часто агрегируете все подтипы, выигрывает подход с одной таблицей. ERD должен четко отражать это решение, чтобы избежать путаницы для будущих разработчиков.
4. Временные данные: отслеживание изменений во времени ⏳
Правила бизнеса меняются. Клиент переезжает, цена обновляется, договор заканчивается. Хранение только «текущего» состояния часто недостаточно для аудита или отчетности. Это приводит к проектированию временных таблиц или медленно изменяющихся измерений (SCD).
Сложность:
Вместо обновления строки вы вставляете новую строку с датой начала и окончания действия. Старая строка помечается как неактивная. Это удваивает требования к хранению исторических данных и усложняет запрос «текущего состояния».
Проблема с запросами:
Выбор данных «на момент» конкретной даты требует фильтрации по диапазону дат. Если вы упустите логику диапазона дат, вы можете вернуть неверную версию записи. Именно здесь часто возникают проблемы с целостностью данных в финансовых приложениях.
- Проектирование снимков:Хранить состояние на определенный момент времени. Требуются периодические пакетные задания для записи снимков.
- Проектирование журнала транзакций:Фиксировать каждое изменение. Высокий объем записей, сложная логика извлечения.
- Периодическое проектирование:Хранить действительные интервалы. Хорошо справляется с пробелами во времени, но требует тщательного управления границами.
5. Распределенные системы: шардирование и отношения 🔗
Когда одна база данных не может вместить данные, становится необходимым шардирование. Именно здесь проектирование ERD сталкивается с наиболее серьезными физическими ограничениями. Отношения, пересекающие границы шардирования, являются дорогостоящими.
Проблема соединения:
Если таблица A шардируется по идентификатору пользователя, а таблица B связана с таблицей A, таблица B должна шардироваться по тому же идентификатору пользователя, чтобы избежать распределенных соединений. Если таблица B шардируется по чему-то иному, вы должны направить запрос на несколько шардов, объединить результаты и выполнить соединение локально.
Целостность ссылок:
Ограничения внешнего ключа трудно соблюдать на распределенных узлах. Многие системы отключают внешние ключи в средах с шардированием, чтобы обеспечить доступность. Это перекладывает ответственность за целостность данных на уровень приложения, который подвержен гонкам.
Ключевые выводы по распределенным ERD:
- Избегайте отношений «многие ко многим», которые охватывают несколько шардов.
- Денормализуйте данные, чтобы сократить потребность в соединениях между узлами.
- Проектируйте ключ партиционирования (ключ шардирования) на основе наиболее частых шаблонов запросов, а не только первичного ключа.
6. Производительность против нормализации: баланс компромиссов ⚖️
Нормализация (1НФ, 2НФ, 3НФ) преподается как золотой стандарт целостности данных. Однако в системах с высокой пропускной способностью строгая нормализация может убить производительность. ERD должен находить баланс между ними.
Когда нужно денормализовать:
- Работа с преобладанием чтения: Если вы читаете данные намного чаще, чем записываете, добавление избыточных столбцов экономит операции соединения.
- Требования к отчетности: Агрегации на нормализованных данных требуют сложных соединений, которые замедляют панели мониторинга.
- Работа с преобладанием записи: Иногда хранение данных отдельно снижает конкуренцию блокировок во время обновлений.
Наша группа подчеркнула, что нет «идеальной» схемы. Это компромисс. ERD должен документировать, где происходит денормализация и почему, чтобы будущие сопровождающие понимали, что избыточность — это осознанный выбор, а не ошибка.
Сравнение паттернов моделирования 📊
Для облегчения принятия решений, вот краткое резюме паттернов моделирования, обсуждавшихся, и их типичных сценариев использования.
| Паттерн | Лучший сценарий использования | Основной риск | Сложность |
|---|---|---|---|
| Одна таблица | Простые иерархии, низкое разнообразие | Поля с null, раздувание схемы | Низкая |
| Таблица классов | Строгие подтипы, отличительные атрибуты | Накладные расходы на соединение | Средняя |
| Рекурсивный | Диаграммы организаций, категории | Глубина обхода, циклы | Высокий |
| Ассоциативный объект | Многие ко многим с атрибутами | Производительность соединений | Средний |
| Временной | Аудит, отслеживание истории | Сложность запросов | Высокий |
| Распределённое шардирование | Масштабирование на больших объемах, горизонтальное расширение | Целостность ссылок | Очень высокий |
Чек-лист для проверки ERD ✅
Перед окончательным утверждением диаграммы сущностей и отношений используйте этот чек-лист, чтобы выявить распространённые ошибки. Лучше обнаружить эти проблемы на этапе проектирования, чем в производственной среде.
- Мощность:Чётко определены ли отношения один к одному, один ко многим и многие ко многим? Явно ли указаны минимальные и максимальные ограничения (0..1, 1..*)?
- Типы данных:Типы столбцов соответствуют ожидаемому размеру данных? (например, использование Integer вместо Varchar для идентификаторов).
- Допустимость NULL:Могут ли внешние ключи быть NULL? Если да, то логика корректно обрабатывает несвязанные ссылки?
- Стратегия индексации:На ERD указаны ли столбцы, которые требуют индексации для повышения производительности? Внешние ключи часто индексируются для ускорения соединений.
- Соглашения об именовании:Имена таблиц и столбцов единообразны? Избегайте сокращений, которые могут быть неоднозначными в будущем.
- Бизнес-правила:Ограничения (например, «Пользователь не может иметь две активные подписки») представлены как логические проверки или ограничения базы данных?
- Масштабируемость: Может ли схема вместить новые атрибуты без необходимости полной миграции? (например, с использованием шаблона EAV или столбцов JSON при необходимости).
Заключительные мысли о моделировании данных 🧠
Создание диаграммы сущность-связь — это не просто рисование прямоугольников и линий. Это понимание потока данных, ограничений аппаратного обеспечения и потребностей бизнеса. Сценарии, обсуждаемые здесь, представляют собой точки соприкосновения теории и практики.
Предвидя эти вызовы — рекурсивную глубину, распределённые соединения, временные истории и компромиссы наследования — вы сможете создавать устойчивые схемы. Хорошо продуманная ERD снижает технический долг и предотвращает необходимость дорогостоящей рефакторинга в будущем. Это вложение в стабильность всей системы.
Помните, что лучшая схема — это та, которая развивается вместе с данными. Ключевым является документирование. Убедитесь, что каждый отклонение от стандартной нормализации обоснован и зафиксирован. Прозрачность — это то, что отличает надёжную архитектуру базы данных от хрупкой.