











Ein Datenflussdiagramm (DFD) dient als grundlegende visuelle Darstellung in der Systemanalyse und -gestaltung. Es zeigt den Fluss von Informationen durch ein System und hebt hervor, wie Daten von der Eingabe zur Ausgabe fließen. Im Gegensatz zu Flussdiagrammen, die sich auf die Steuerlogik konzentrieren, legen DFDs den Fokus auf die Datenbewegung. Diese Anleitung beschreibt die Methodik zur Erstellung genauer Diagramme, ohne auf spezifische proprietäre Werkzeuge angewiesen zu sein. Der Prozess erfordert klare Gedankenführung und die Einhaltung etablierter Notationsstandards.
🧐 Verständnis des Kernzwecks
Bevor Linien und Formen gezeichnet werden, muss das Ziel verstanden werden. Ein DFD modelliert die funktionalen Anforderungen eines Systems. Er zeigt, was das System tut, nicht unbedingt, wie es physisch implementiert ist. Diese Unterscheidung ist für Analysten entscheidend. Sie ermöglicht es den Stakeholdern, die Logik der Geschäftsprozesse zu überprüfen, ohne sich in technische Implementierungsdetails zu verstricken.
Das Diagramm hilft dabei, folgendes zu identifizieren:
- Wo die Daten innerhalb der Systemgrenzen entstehen.
- Wie Daten in nützliche Informationen umgewandelt werden.
- Wo Daten für die spätere Abrufbarkeit gespeichert werden.
- Wo Daten das System verlassen, um an externe Parteien weitergeleitet zu werden.
Durch die Visualisierung dieser Elemente können Teams Engpässe, Redundanzen oder fehlende Datenpfade bereits in einem frühen Stadium des Entwicklungszyklus erkennen. Es fungiert als Kommunikationsbrücke zwischen technischen Teams und Geschäftsanwendern.
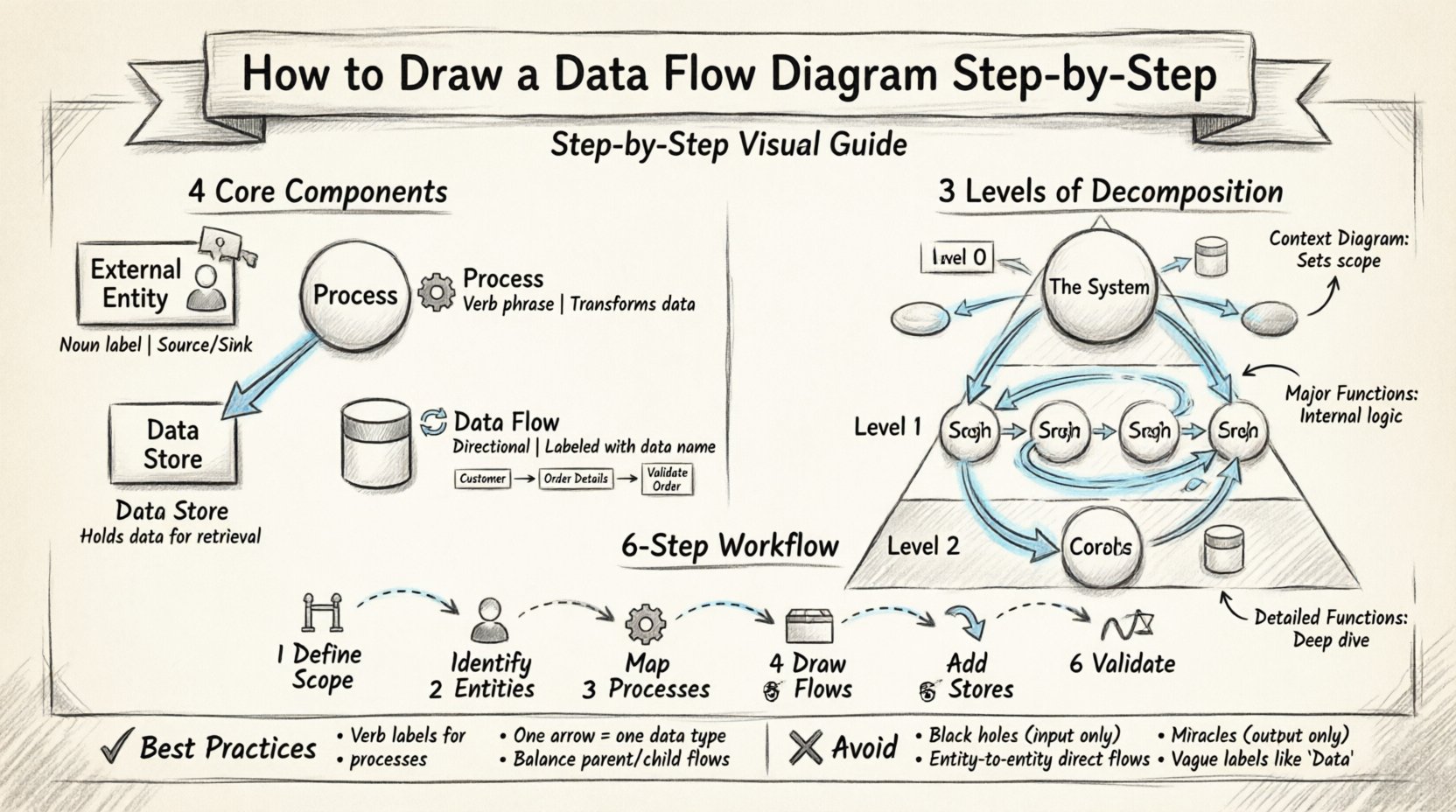
🛠️ Die vier grundlegenden Komponenten
Ein vollständiges DFD beruht auf vier primären Symbolen. Jedes gezeichnete Element muss einer dieser Kategorien zugeordnet werden. Die Verwendung einer anderen Form führt zu Unklarheiten. Die Standardnotation folgt in der Regel entweder der Yourdon & DeMarco-Methode oder der Gane & Sarson-Methode. Obwohl die Symbole zwischen diesen Stilen leicht variieren können, bleibt die zugrundeliegende Logik identisch.
1. Externe Entitäten 👤
Externe Entitäten stellen Quellen oder Ziele von Daten außerhalb der Systemgrenzen dar. Sie sind die Akteure, die mit dem System interagieren. Dazu können Personen, Organisationen oder andere Systeme gehören.
- Quelle: Die Entität liefert Eingabedaten an das System (z. B. ein Kunde, der eine Bestellung aufgibt).
- Senke: Die Entität empfängt Ausgabedaten vom System (z. B. eine Steuerbehörde, die Berichte erhält).
In einem Diagramm werden sie typischerweise durch Rechtecke oder Quadrate dargestellt. Sie werden mit einem Substantivphrasenlabel versehen, das ihre Rolle angibt.
2. Prozesse ⚙️
Prozesse stellen Aktionen dar, die Eingabedaten in Ausgabedaten umwandeln. Sie sind das Herzstück des Diagramms. Ein Prozess muss immer mindestens eine Eingabe und eine Ausgabe haben.
- Transformation: Sie wandelt Daten von einer Form in eine andere um (z. B. die Umwandlung von Rohverkaufszahlen in einen Zusammenfassungsbericht).
- Beschriftung: Prozesse werden gewöhnlich mit einer Verbalphrase beschriftet (z. B. „Steuern berechnen“, „Benutzer validieren“).
Sie werden je nach Notationsstandard oft als Kreise, abgerundete Rechtecke oder Blasen dargestellt.
3. Datenbanken 📂
Datenbanken stellen dar, wo Informationen für die spätere Verwendung gespeichert werden. Es handelt sich dabei nicht um eine physische Datenbankdatei, sondern um ein logisches Repository. Daten fließen in eine Datenbank zur Speicherung und fließen heraus zur Abrufung.
- Geöffnet vs. Geschlossen: Daten können sowohl aus der Datenbank gelesen als auch in sie geschrieben werden.
- Persistenz: Daten bleiben verfügbar, auch wenn der Prozess, der sie erstellt hat, beendet ist.
Häufig verwendete Symbole sind offene Rechtecke oder Zylinder, die Dateien und Datenbanken darstellen.
4. Datenflüsse 🔄
Datenflüsse zeigen die Bewegung von Daten zwischen Entitäten, Prozessen und Speichern. Sie sind gerichtete Pfeile.
- Richtung: Der Pfeil zeigt in die Richtung, in die die Daten fließen.
- Inhalt: Jeder Fluss muss mit dem spezifischen Dateninhalt gekennzeichnet sein, der übertragen wird (z. B. „Bestelldetails“, „Zahlungsbestätigung“).
- Konsistenz: Daten können nicht zwischen zwei externen Entitäten fließen, ohne dass ein Prozess dazwischen liegt.
| Komponente | Symbolform | Beschriftungstyp | Funktion |
|---|---|---|---|
| Externe Entität | Rechteck / Quadrat | Substantiv | Quelle oder Ziel |
| Prozess | Kreis / Abgerundetes Feld | Verben-Phrase | Daten transformieren |
| Datenbank | Offenes Rechteck / Zylinder | Substantiv | Daten speichern |
| Datenfluss | Pfeil | Datenname | Daten verschieben |
📈 Stufen der Zerlegung
Komplexe Systeme können nicht in einer einzigen Ansicht verstanden werden. DFDs sind hierarchisch aufgebaut. Sie beginnen mit einer Übersicht auf hoher Ebene und zerlegen die Prozesse schrittweise in detailliertere Bestandteile. Dies wird als Zerlegung bezeichnet.
Ebene 0: Kontextdiagramm 🌍
Das Kontextdiagramm ist die höchste Ebene. Es zeigt das gesamte System als eine einzelne Prozessblase. Es veranschaulicht, wie das System mit der Außenwelt interagiert.
- Es ist nur ein Prozess in der Mitte dargestellt.
- Externe Entitäten umgeben den Prozess.
- Datenflüsse verbinden die Entitäten mit dem einzelnen Prozess.
- Auf dieser Ebene werden keine Datenbestände angezeigt.
Dieses Diagramm legt den Umfang fest. Es definiert die Grenzen des Projekts.
Ebene 1: Hauptprozesse 🔍
Ebene 1 erweitert den einzelnen Prozess aus dem Kontextdiagramm zu Hauptunterprozessen. Hier beginnt die interne Logik sichtbar zu werden.
- Der einzelne Prozess wird zu einer Gruppe von 3 bis 7 Hauptprozessen.
- Datenbestände werden hier eingeführt.
- Externe Entitäten bleiben wie in Ebene 0.
- Die Flüsse müssen mit den Eingängen und Ausgängen von Ebene 0 abgestimmt sein.
Ebene 2: Detaillierte Funktionen 🔬
Ebene 2 zerlegt spezifische Prozesse aus Ebene 1. Dies wird für komplexe Operationen verwendet, die einer weiteren Erklärung bedürfen.
- Fokussiert sich auf einen einzelnen Prozess aus der vorherigen Ebene.
- Zeigt detaillierte Logik und Unterschritte an.
- Wird verwendet, wenn ein Prozess der Ebene 1 zu komplex ist, um ihn in einer einzigen Ansicht zu verwalten.
| Ebene | Fokus | Prozesse | Datenbestände |
|---|---|---|---|
| Ebene 0 | Systemumfang | 1 (Das System) | Keine |
| Ebene 1 | Hauptfunktionen | 3 bis 7 | Ja |
| Ebene 2 | Spezifische Details | Abhängig von Ebene 1 | Ja |
✍️ Schritt-für-Schritt-Methode zur Zeichnung
Die Erstellung eines DFD erfordert einen strukturierten Ansatz. Die Einhaltung dieser Schritte gewährleistet Konsistenz und Klarheit in der gesamten Dokumentation.
Schritt 1: Umfang und Grenze definieren 🚧
Beginnen Sie damit, das zu identifizieren, was sich innerhalb des Systems befindet und was sich außerhalb befindet. Diese Entscheidung bestimmt die Positionierung der externen Entitäten. Alles außerhalb der Grenze ist eine externe Entität. Alles innerhalb ist ein Prozess, Speicher oder Fluss. Fügen Sie hier keine Implementierungsdetails wie Hardware oder Code hinzu.
Schritt 2: Externe Entitäten identifizieren 👥
Listen Sie alle Parteien auf, die mit dem System interagieren. Stellen Sie Fragen wie:
- Wer sendet Informationen an das System?
- Wer erhält Berichte oder Ausgaben aus dem System?
- Gibt es andere Systeme, die Daten mit diesem austauschen?
Zeichnen Sie diese Entitäten um den Umfang Ihres Arbeitsplatzes herum. Verwenden Sie klare, beschreibende Namen.
Schritt 3: Hauptprozesse bestimmen ⚙️
Identifizieren Sie die Hauptfunktionen, die das System erfüllen muss, um Eingaben in Ausgaben zu verwandeln. Gruppieren Sie verwandte Aktivitäten. Zum Beispiel könnte „Auftragsverwaltung“ ein Hauptprozess sein, der „Auftrag validieren“ und „Bestand aktualisieren“ als Unterverfahren enthält.
- Halten Sie die Anzahl der Prozesse überschaubar (idealerweise unter 7 für Ebene 1).
- Stellen Sie sicher, dass jeder Prozess einen klaren Zweck hat.
- Beschriften Sie Prozesse mit Verben (z. B. „Zahlung verarbeiten“).
Schritt 4: Datenflüsse abbilden 🔄
Zeichnen Sie Pfeile, die Entitäten mit Prozessen und Prozesse mit Prozessen verbinden. Jeder Pfeil muss eine Beschriftung haben, die die Daten beschreibt.
- Stellen Sie sicher, dass die Daten logisch fließen.
- Stellen Sie sicher, dass kein Fluss die Systemgrenze überschreitet, ohne durch einen Prozess zu gehen.
- Beschriften Sie Flüsse mit dem spezifischen Datenpaket (z. B. „Kunden-ID“, nicht nur „Daten“).
Schritt 5: Datenbanken hinzufügen 📂
Identifizieren Sie, wo Informationen gespeichert werden müssen. Wenn Daten später benötigt werden, müssen sie in einen Speicher gelangen.
- Verbinden Sie Speicher mit den Prozessen, die darauf lesen oder schreiben.
- Stellen Sie sicher, dass Daten in einen Speicher fließen, um sie zu speichern.
- Stellen Sie sicher, dass Daten aus einem Speicher fließen, um sie zu verwenden.
Schritt 6: Überprüfen und Ausbalancieren ⚖️
Dies ist der kritischste technische Schritt. Die Abstimmung stellt sicher, dass die Eingaben und Ausgaben eines übergeordneten Prozesses mit den Eingaben und Ausgaben seines Kinddiagramms (der nächsten Ebene darunter) übereinstimmen.
- Wenn Ebene 0 eine Eingabe „Auftrag“ hat, muss Ebene 1 ebenfalls „Auftrag“ zeigen, der in den Hauptprozess eintritt.
- Wenn Ebene 1 einen Prozess aufteilt, müssen die Unterverarbeitungen die gleichen Daten-Eingaben und -Ausgaben wie der übergeordnete Prozess verarbeiten.
- Überprüfen Sie auf verwaiste Prozesse (Prozesse ohne Datenfluss).
- Überprüfen Sie auf verwaiste Datenspeicher (Speicher ohne Datenfluss hinein oder heraus).
🧠 Best Practices und Regeln
Die Einhaltung strenger Regeln verhindert Verwirrung. Abweichungen können zu einer falschen Interpretation der Systemlogik führen.
1. Namenskonventionen 🏷️
Konsistenz ist entscheidend. Verwenden Sie eine standardisierte Namenskonvention für alle Elemente.
- Entitäten: Plural-Nomen (z. B. „Kunden“, „Lieferanten“).
- Prozesse: Verbphrasen (z. B. „Inventar aktualisieren“).
- Speicher: Nomen (z. B. „Inventar-Datei“).
- Flüsse: Datenbezeichnungen (z. B. „Bestandaktualisierung“).
2. Vermeiden Sie Steuerlogik 🚫
DFDs sind keine Ablaufdiagramme. Fügen Sie keine Entscheidungsdiamanten oder Schleifen hinzu, die die Steuerlogik darstellen. Wenn eine Entscheidung den Datenfluss beeinflusst, stellen Sie sie dar, indem Sie den Fluss in verschiedene Pfade aufteilen, die auf dem Dateninhalt basieren, nicht auf der logischen Bedingung selbst.
3. Ein Pfeil, ein Datenpaket
Kombinieren Sie keine mehreren Datentypen in einem einzigen Pfeil. Wenn ein Prozess sowohl „Auftragsdaten“ als auch „Zahlungsdaten“ sendet, zeichnen Sie zwei separate Pfeile.
4. Keine direkten Entität-zu-Entität-Flüsse
Daten können nicht direkt von einer externen Entität zur anderen bewegt werden, ohne durch das System zu gehen. Wenn dies geschieht, bedeutet es, dass das System umgangen wird, oder der Diagrammbereich ist falsch definiert.
5. Vermeiden Sie Schwarze Löcher und Wunder
- Schwarzes Loch: Ein Prozess, der Eingaben hat, aber keine Ausgaben. Daten verschwinden. Das ist unmöglich.
- Wunder: Ein Prozess, der Ausgaben hat, aber keine Eingaben. Daten erscheinen aus dem Nichts. Das ist unmöglich.
⚠️ Häufige Fehler, die vermieden werden sollten
Sogar erfahrene Analysten begehen Fehler. Die Kenntnis häufiger Fallstricke spart Zeit bei Überprüfungen.
Fehler 1: Vermischung von Ebenen
Die Kombination von Level-0- und Level-1-Details auf einer Seite führt zu Überladung. Halten Sie jedes Level getrennt, um Klarheit zu bewahren.
Fehler 2: Inkonsistente Flussrichtung
Stellen Sie sicher, dass Pfeile in die richtige Richtung zeigen. Ein häufiger Fehler ist das Zeichnen eines Pfeils von der Speicherstelle zum Prozess, wenn der Prozess tatsächlich Daten in die Speicherstelle schreibt.
Fehler 3: Mehrdeutige Beschriftungen
Vermeiden Sie Beschriftungen wie „Info“, „Daten“ oder „Details“. Seien Sie präzise. „Kundendaten“ ist besser. „Daten“ ist für die Analyse nutzlos.
Fehler 4: Ignorieren von Datenspeichern
Das Überspringen von Datenspeichern führt zu einem unvollständigen Modell. Wenn Daten später verwendet werden, müssen sie gespeichert werden. Die Nichtberücksichtigung von Speichern impliziert ein zustandsloses System, was für komplexe Anwendungen selten zutreffend ist.
🔍 Fortgeschrittene Überlegungen
Je größer die Systeme werden, desto strengere Pflege erfordern DFDs. Berücksichtigen Sie Folgendes bei größeren Projekten.
Physische vs. logische DFDs
- Logische DFD: Konzentriert sich auf die geschäftlichen Anforderungen. Sie ignoriert technische Implementierungsdetails wie Papierdateien gegenüber Datenbanken.
- Physische DFD: Spiegelt die tatsächliche Implementierung wider. Sie legt Hardware, Software und Dateitypen fest.
Es ist Best Practice, zuerst die logische DFD zu erstellen, um die Anforderungen abzustimmen, und daraus die physische DFD für die Entwicklung abzuleiten.
Konkurrenz und Zeitverhalten
Standard-DFDs zeigen keine Zeit oder Konkurrenz. Sie zeigen, was geschieht, nicht wann. Für Systeme, bei denen das Zeitverhalten entscheidend ist, können neben DFDs andere Modellierungstechniken wie Zustandsübergangsdiagramme erforderlich sein.
Sicherheit und Zugriffssteuerung
Obwohl DFDs keine Sicherheitsprotokolle explizit zeigen, sollten Datenflüsse sensible Informationen anzeigen. Flüsse, die „Passwort“ oder „Kreditkartennummer“ enthalten, sollten markiert werden. Dies hilft Sicherheitsarchitekten dabei, zu erkennen, wo Verschlüsselung erforderlich ist.
📝 Zusammenfassung des Arbeitsablaufs
Die Erstellung eines Datenflussdiagramms ist eine disziplinierte Übung im systemischen Denken. Es erfordert die Aufteilung eines komplexen Systems in handhabbare Teile, während die Integrität des Datenflusses gewahrt bleibt. Der Prozess geht von der Makroperspektive des Kontextdiagramms zur Mikroperspektive detaillierter Prozesse über.
Erfolg hängt ab von:
- Klare Abgrenzung der Grenzen.
- Konsistente Beschriftung der Komponenten.
- Strenge Einhaltung der Abstimmungsregeln.
- Validierung mit Stakeholdern.
Durch die Einhaltung dieser Schritte und die Vermeidung häufiger Fehler erstellen Sie eine zuverlässige Grundlage für die Systementwicklung. Dieses Dokument dient als Fundament für die Datenbankgestaltung, die Softwarearchitektur und Verbesserungsinitiativen im Prozess. Es bleibt ein zeitloses Werkzeug, um zu verstehen, wie Informationen durch jedes organisierte System fließen.