











Die Modernisierung eines veralteten Systems in eine Microservices-Architektur ist eine Reise voller technischer und organisatorischer Herausforderungen. Während viele Teams sich stark auf Code-Refactoring und Containerisierung konzentrieren, liegt oft ein wesentlicher Hindernis in der Datenebene. Insbesondere kann das traditionelle Entitäts-Beziehungs-Diagramm (ERD)-Modell bei der Umstellung auf verteilte Systeme zu einer erheblichen Einschränkung werden. 📉
Wenn Sie eine monolithische Anwendung entwerfen, ist Ihr Datenmodell zentralisiert. Ein ERD stellt die einzige Quelle der Wahrheit dar, wobei normalisierte Tabellen über Fremdschlüssel verknüpft sind. Dieser Ansatz funktioniert gut für eine einzelne Datenbankinstanz. Allerdings erfordern Microservices Autonomie. Wenn Sie eine monolithische ERD-Struktur auf eine verteilte Architektur aufzwingen, entsteht eine enge Kopplung, die die Vorteile der Aufspaltung Ihres Systems zunichte macht. 🚧
Dieser Leitfaden untersucht, warum die klassische ERD-Mentalität die Einführung von Microservices behindert, und bietet einen praktischen Wegweiser, um Ihre Datenmodellierungsstrategien zu verändern. Wir behandeln verteilte Datenverwaltung, Konsistenzmodelle und Visualisierungstechniken, die mit den Prinzipien des domain-driven Design übereinstimmen. 🗺️
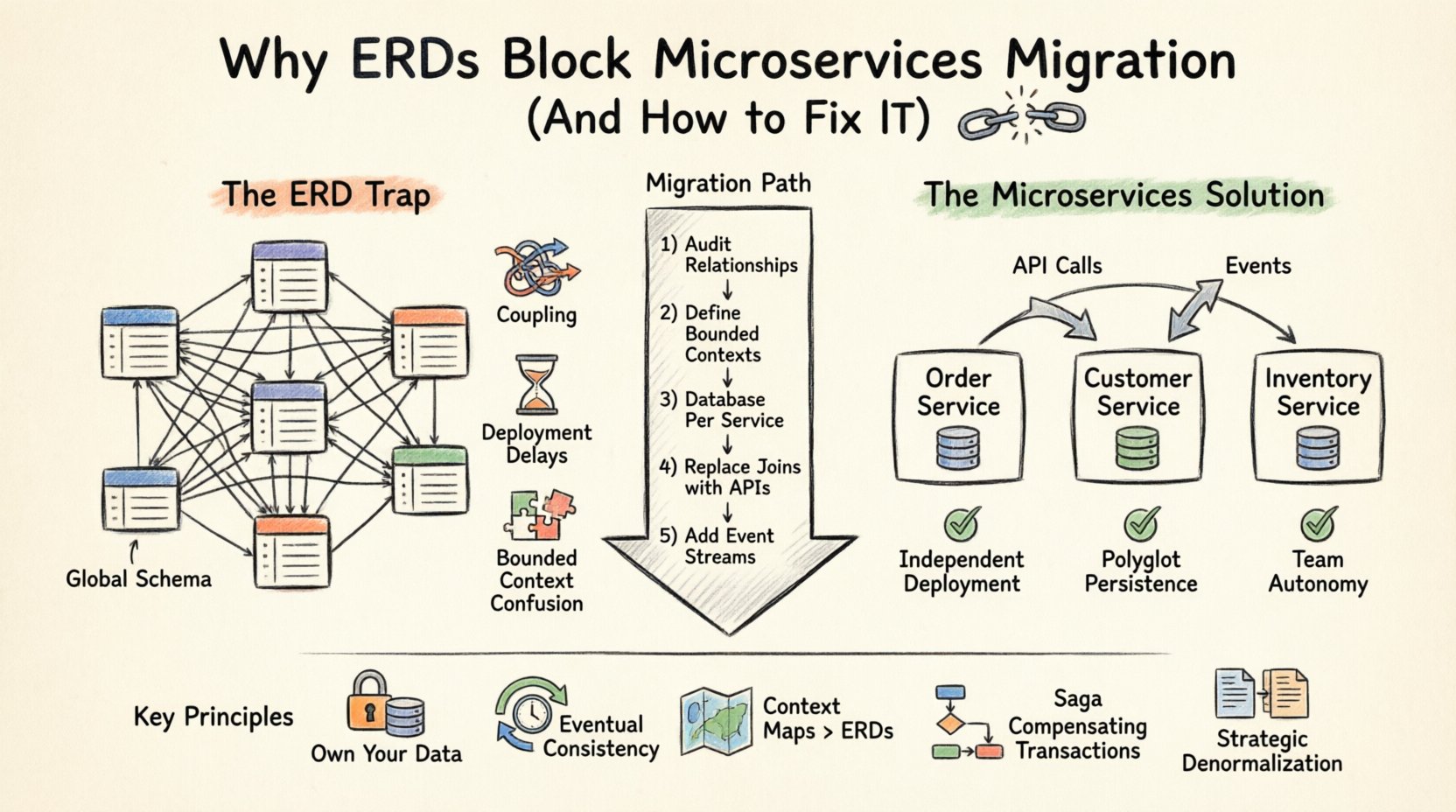
Das ERD-Problem in verteilten Systemen verstehen 🧩
Ein Entitäts-Beziehungs-Diagramm ist eine visuelle Darstellung der logischen Struktur einer Datenbank. Es definiert Entitäten (Tabellen), Attribute (Spalten) und Beziehungen (Fremdschlüssel). In einer monolithischen Umgebung ist diese Zentralisierung ein Vorteil. Sie gewährleistet die Datenintegrität durch ACID-Transaktionen und vereinfacht die Abfrage über die gesamte Anwendung hinweg.
Allerdings basiert die Microservices-Architektur auf dem Prinzip derService-Unabhängigkeit. Jeder Dienst sollte seine Daten besitzen und sie ausschließlich über eine API verfügbar machen. Wenn Sie ein gemeinsames ERD aufrechterhalten, das mehrere Dienste umfasst, verletzen Sie die Grenze der Eigentumsverantwortung. Dies führt zu folgenden Problemen:
- Globale Schema-Abhängigkeiten: Wenn Service A Daten aus Service B direkt auf Datenbankebene verknüpfen muss, sind sie nicht länger unabhängig. Eine Änderung im Schema von Service B bricht Service A.
- Transaktionsgrenzen: ACID-Transaktionen über mehrere Datenbanken sind komplex und leistungsintensiv. Verteilte Transaktionen führen oft zu Sperrkonflikten und Latenzspitzen.
- Bereitstellungskopplung: Wenn Ihr Datenmodell geteilt wird, können Sie Dienste nicht unabhängig bereitstellen. Sie müssen die Schemaänderungen über Teams hinweg koordinieren, was die Freigabzyklen verlangsamt.
- Verwirrung im begrenzten Kontext: Verschiedene Dienste können dieselbe Entität unterschiedlich interpretieren. Ein ERD zwingt zu einer einzigen Definition und ignoriert domänenspezifische Nuancen.
Das Kopplungsproblem: Fremdschlüssel und Joins 🔗
Ein der häufigsten Fehler bei der Migration besteht darin, das bestehende Datenbankschema beizubehalten, während der Anwendungscode aufgeteilt wird. Dies führt zu einemgemeinsames Datenbank-Antipattern. In diesem Szenario verbinden mehrere Dienste sich mit derselben Datenbankinstanz und verlassen sich auf Fremdschlüssel, um Beziehungen aufrechtzuerhalten.
Obwohl dies wie eine gültige ERD-Struktur aussieht, ist es ein versteckter Monolith. Hier ist, warum dieser Ansatz im Kontext von Microservices scheitert:
- Netzwerklatenz: Selbst wenn die Datenbank lokal im Netzwerk ist, führen Abfragen zwischen Diensten zu Netzwerk-Hops, die die Leistung im Vergleich zu lokalen Abfragen verschlechtern.
- Einzelner Ausfallpunkt: Wenn die Datenbank ausfällt, fällt jeder Dienst aus. Microservices zielen auf Resilienz durch Isolation ab.
- Sicherheitsrisiken: Ein Dienst, der keinen direkten Zugriff auf andere Daten haben sollte, kann sie dennoch über die Datenbankverbindungszeichenfolge erreichen. APIs bieten eine kontrollierte Schnittstelle; direkter DB-Zugriff nicht.
- Technologie-Verriegelung: Alle Dienste müssen die gleiche Datenbanktechnologie verwenden. Microservices ermöglichen polyglotte Persistenz, bei der verschiedene Dienste die für ihre spezifischen Anforderungen am besten geeignete Datenspeicher verwenden.
Um dies zu beheben, müssen Sie von SQL-Joins über Dienstgrenzen hinweg abrücken. Stattdessen sollten Sie die API-Zusammensetzung oder ereignisgesteuerte Daten-Synchronisation verwenden. 🔄
Datenbank pro Dienst: Die Goldene Regel 🏦
Das grundlegende Muster für die Datenarchitektur von Microservices istDatenbank pro Dienst. Jeder Dienst besitzt seine eigene Datenbank-Schema. Kein anderer Dienst darf diese Datenbank direkt zugreifen. Die Kommunikation erfolgt strikt über die öffentliche API des Dienstes.
Dieser Wandel erfordert eine grundlegende Änderung, wie Sie Ihre Daten visualisieren. Sie können nun nicht mehr ein einziges großes ERD für das gesamte System zeichnen. Stattdessen erstellen Sie mehrere kleinere ERDs, einen für jeden Dienst. 📄
| Aspekt | Monolithisches ERD | Microservices-Modell |
|---|---|---|
| Schema-Bereich | Global / Einheitlich | Lokal / Dienstspezifisch |
| Beziehungen | Fremdschlüssel | API-Aufrufe / Ereignisse |
| Konsistenz | Stark (ACID) | Letztendlich (BASE) |
| Bereitstellung | Abhängig | Unabhängig |
Verwaltung der Konsistenz ohne gemeinsame Transaktionen 🤝
Wenn Sie Datenbanken trennen, verlieren Sie die Fähigkeit, eine einzelne Transaktion auszuführen, die sowohl Service A als auch Service B gleichzeitig aktualisiert. In einem Monolithen könnten Sie eine Datenbanktransaktion verwenden, um Geld von Konto A auf Konto B zu überweisen. In Microservices könnten diese Konten zu unterschiedlichen Diensten gehören.
Da Sie keine sofortige Konsistenz über verteilte Systeme hinweg garantieren können, müssen SieLetztendliche Konsistenz. Das bedeutet, dass das System im Laufe der Zeit einen konsistenten Zustand erreichen wird, aber nicht unbedingt im exakten Moment, wenn der Benutzer auf eine Schaltfläche klickt.
Implementierung von Sagas
Um komplexe Workflows zu handhaben, die mehrere Dienste umfassen, verwenden Sie dasSaga-Muster. Eine Saga ist eine Folge lokaler Transaktionen, bei der jede Transaktion die Datenbank innerhalb eines einzelnen Dienstes aktualisiert. Wenn ein Schritt fehlschlägt, führt die Saga kompensierende Transaktionen aus, um die Änderungen der vorherigen Schritte rückgängig zu machen.
- Choreografie:Dienste senden Ereignisse aus, die Aktionen in anderen Diensten auslösen. Es gibt keinen zentralen Koordinator.
- Orchestrierung:Ein zentraler Koordinationsdienst verwaltet den Arbeitsablauf und gibt anderen Diensten vor, was sie tun sollen.
Dieser Ansatz gewährleistet die Datenintegrität, ohne gemeinsame Sperren oder verteilte Transaktionen zu erfordern. Er erhöht die Komplexität der Implementierung, ist jedoch notwendig, um die Systemgesundheit aufrechtzuerhalten. 🛡️
Datenvisualisierung ohne ERDs: Kontextkarten 🗺️
Wenn Sie das traditionelle ERD aufgeben, was verwenden Sie, um Ihre Datenarchitektur zu visualisieren? Die Antwort liegt inKontextkarten nach Domain-Driven Design (DDD). Während ein ERD sich auf Tabellen und Spalten konzentriert, richtet sich eine Kontextkarte auf begrenzte Kontexte und Beziehungen.
Anstatt Linien zwischen Tabellen zu zeichnen, zeichnen Sie Linien zwischen Diensten. Sie definieren, wie Daten zwischen ihnen fließen:
- Kunde-Lieferant:Ein Dienst stellt Daten für einen anderen bereit. Der Anbieter definiert den Vertrag.
- Konformer:Der verbrauchende Dienst muss sich an das Modell des Anbieters anpassen.
- Offener Hostdienst:Ein Dienst macht seine Daten über ein offenes Protokoll zugänglich.
- Getrennte Wege:Beide Dienste entwickeln ihre eigenen Modelle unabhängig voneinander.
Diese Verschiebung in der Visualisierung hilft Teams zu verstehenwarumDaten dupliziert werden. In einer Monolith-Architektur ist Duplizierung schlecht. In Mikrodiensten ist Duplizierung oft eine Funktion, um Dienste zu entkoppeln. Zum Beispiel speichert derBestellungs-Dienstkönnte eine Momentaufnahme desKundennameum bei jeder Ansicht einer Bestellung einen Netzwerkaufruf zu vermeiden. Dieser Kompromiss ist für die Leistung akzeptabel.
Migrations-Schritte: Von ERD zu verteilten Daten 🚀
Der Übergang von einem zentralen ERD zu einem verteilten Datenmodell ist kein einmaliger Vorgang. Es ist ein schrittweiser Prozess. Hier ist ein empfohlener Ansatz, um die Migration zu managen.
Schritt 1: Prüfung bestehender Datenbeziehungen
Bevor Sie etwas aufteilen, dokumentieren Sie jede Beziehung in Ihrem aktuellen ERD. Identifizieren Sie, welche Tabellen leseschwer sind, welche schreibschwer sind und welche häufig zusammengefügt werden. Diese Analyse hilft Ihnen, Entitäten in logische Dienstgrenzen zu gruppieren. 📊
Schritt 2: Definieren begrenzter Kontexte
Gruppieren Sie die Entitäten basierend auf Geschäftsbereichen statt auf technischen Abhängigkeiten. Zum Beispiel ist ein Produktkatalog unterscheidet sich von einem Bestandsverwaltung -System, auch wenn beide das Feld ProductID verwenden. Stellen Sie sicher, dass die Grenzen mit den Teamstrukturen übereinstimmen (Gesetz von Conway).
Schritt 3: Datenbank pro Dienst implementieren
Erstellen Sie für jeden Dienst eine neue Datenbankinstanz. Migrieren Sie die relevanten Daten aus der monolithischen Datenbank. Sie müssen nicht sofort alles verschieben. Beginnen Sie mit den Kerndaten, die für die Funktionsfähigkeit des Dienstes erforderlich sind. 🏗️
Schritt 4: JOINs durch API-Aufrufe ersetzen
Refaktorisieren Sie Ihre Abfragen. Anstatt JOIN Orders, Customers, sollte Ihr Code die Kunden-API aufrufen, um Details abzurufen. Dies könnte Latenz verursachen, daher sollten Sie Caching-Strategien oder Denormalisierung gegebenenfalls berücksichtigen.
Schritt 5: Ereignisströme einführen
Für Echtzeit-Updates implementieren Sie einen Ereignisbus. Wenn eine Entität in einem Dienst geändert wird, veröffentlichen Sie ein Ereignis. Andere Dienste können sich für diese Ereignisse anmelden, um ihre lokalen Datenkopien zu aktualisieren. Dadurch wird eine letztendliche Konsistenz ohne direkte Kopplung gewährleistet.
Häufige Fehler während der Migration ⚠️
Auch mit einem Plan stolpern Teams oft während der Umstellung. Seien Sie sich dieser häufigen Probleme bewusst.
- vorzeitiges Aufteilen: Teilen Sie Dienste nicht, bevor Sie den Datenfluss verstehen. Zu frühes Aufteilen kann zu verteilter Komplexität führen, bevor Sie dafür bereit sind.
- Ignorieren der Datenverantwortung: Wenn mehrere Teams die Verantwortung für dieselbe Datenentität übernehmen, werden Konflikte entstehen. Weisen Sie jeder Dienst eine klare Verantwortung zu.
- Über-Normalisierung: In einem verteilten System wird Denormalisierung oft bevorzugt, um die Anzahl der API-Aufrufe zu reduzieren, die zum Rendern einer Seite erforderlich sind.
- Netzwerkabhängigkeit: Nehmen Sie niemals an, dass das Netzwerk perfekt ist. Implementieren Sie Zeitüberschreitungen, Wiederholungen und Schaltkreisunterbrecher für die Kommunikation zwischen Diensten.
Organisatorische Ausrichtung 🤝
Die Datenarchitektur ist nicht nur technisch, sondern auch organisatorisch. Ein verteiltes Datenmodell erfordert, dass Teams anders kommunizieren. In einem Monolithen sprechen Entwickler über ein gemeinsames Whiteboard (die Datenbank). In Microservices sprechen sie über den API-Vertrag.
Stellen Sie sicher, dass Ihre Teams befähigt sind, ihre Datenbankschemata zu ändern, ohne einen zentralen Governance-Ausschuss zu konsultieren. Diese Autonomie ist die einzige Möglichkeit, die Geschwindigkeit der unabhängigen Bereitstellung aufrechtzuerhalten. Wenn Sie einen zentralen Team einführen, das alle Schemänderungen genehmigt, bringen Sie den Engpass erneut zurück, den Sie zu vermeiden versucht haben. 👥
Endgültige Überlegungen zur Datenstrategie 🧭
Sich von einem traditionellen Entity-Relationship-Diagramm zu entfernen, ist ein bedeutender Schritt. Es erfordert eine Veränderung des Denkens vonDatenintegrität durch EinschränkungenzuDatenintegrität durch Anwendungslogik und Ereignisse. Das ERD ist ein Werkzeug für relationale Datenbanken, kein Bauplan für verteilte Systeme.
Durch die Einführung des Musters ‘Datenbank pro Dienst’, die Nutzung einer ereignisgesteuerten Architektur und die Fokussierung auf begrenzte Kontexte können Sie die Kopplung vermeiden, die Ihre Migration verlangsamt. Das Ziel besteht nicht darin, Ihr bestehendes Datenmodell zu zerstören, sondern es in eine Struktur zu entwickeln, die unabhängiges Skalieren und Resilienz unterstützt.
Denken Sie daran, dass Konsistenz ein Spektrum ist. Sie benötigen überall keine starke Konsistenz. Identifizieren Sie die Teile Ihres Systems, die strenge Genauigkeit erfordern, und diejenigen, die eine ereignisgesteuerte Konsistenz tolerieren können. Diese Pragmatik wird Sie vor einer Überkonstruktion Ihrer Lösung bewahren.
Beginnen Sie mit der Überprüfung Ihrer aktuellen Diagramme. Identifizieren Sie die Verknüpfungen, die Dienstgrenzen überschreiten. Planen Sie die Migration dieser spezifischen Entitäten. Machen Sie kleine Schritte. Überprüfen Sie die Ergebnisse. Und halten Sie stets den Geschäftsdomain im Zentrum Ihrer Datenarchitektur. 🎯
Wichtige Erkenntnisse 📝
- Vermeiden Sie gemeinsame Datenbanken zwischen Diensten, um Kopplung zu vermeiden.
- Verwenden Sie die API-Zusammensetzung statt SQL-Joins für Datenübertragungen zwischen Diensten.
- Akzeptieren Sie die ereignisgesteuerte Konsistenz, um Verfügbarkeit und Partitionstoleranz zu erreichen.
- Visualisieren Sie Daten mithilfe von Kontextkarten statt globaler ERDs.
- Weisen Sie klare Datenverantwortung einzelnen Dienstteams zu.
- Planen Sie Daten-Duplikation als Leistungs-Optimierung.
Indem Sie diese Prinzipien befolgen, können Sie die Komplexität der Datenmigration meistern, ohne dass Ihr ERD die Grenzen Ihrer neuen Architektur bestimmt. Der Weg vorwärts ist verteilt, dezentralisiert und auf Skalierbarkeit ausgelegt. 🚀