











Data modeling is the backbone of any robust database architecture. While the theory is often taught in university courses, the practical application in production environments reveals a landscape fraught with edge cases, performance bottlenecks, and logical ambiguities. Entity Relationship Diagrams (ERDs) serve as the blueprint for these systems, yet they often become sources of contention when the real world refuses to fit neatly into boxes and lines.
We sat down with a panel of Principal Database Administrators and Data Architects to dissect the scenarios that consistently stump teams during the design phase. These are not theoretical exercises; they are problems that arise when business requirements collide with physical storage constraints. The goal here is not to offer a quick fix, but to provide a deep understanding of the trade-offs involved.
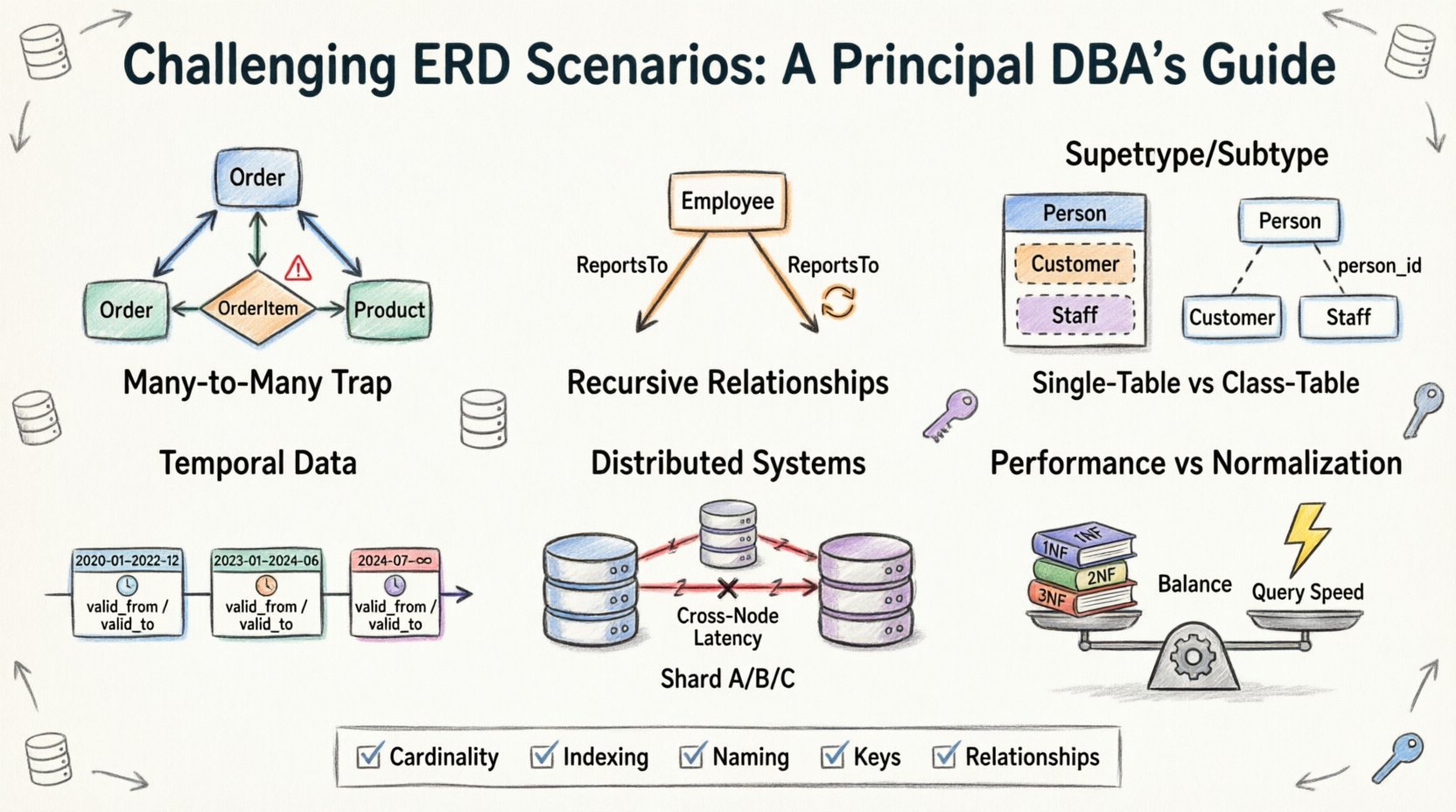
1. The Many-to-Many Trap: Beyond Simple Join Tables 🕸️
The most common starting point in ERD design is the Many-to-Many relationship. It seems intuitive: a Student can enroll in many Courses, and a Course can have many Students. The standard solution involves a bridge or associative table. However, the complexity arises when attributes are introduced into the relationship itself.
- The Problem: Often, teams try to store enrollment data (like grades or registration dates) in the main Student or Course table, leading to massive redundancy or null values.
- The Reality: The relationship itself is an entity. It must have its own primary key and foreign keys pointing back to the parents.
- The Challenge: Handling cascading deletes. If a Course is removed, what happens to the Enrollment records? If an Enrollment is deleted, does the Student disappear? These decisions define data integrity.
During our discussion, one Principal DBA noted that the associative table often becomes a performance bottleneck. When querying data across this junction, the database engine must perform a join operation that can scale poorly as the row count grows into the millions. The solution isn’t always architectural; sometimes it requires denormalization, but that introduces update anomalies.
Key Considerations for Many-to-Many:
- Does the relationship have attributes that require indexing?
- Is the relationship active or historical? (e.g., Is a current enrollment different from a past one?)
- How will the system handle orphaned records if a parent is deleted?
2. Recursive Relationships: Self-Referencing Hierarchies 🌳
Hierarchical data is everywhere. Think of an organizational chart, a bill of materials, or a comment thread on a forum. Modeling this requires a table to reference itself. While conceptually simple, implementing this in a relational schema introduces specific challenges regarding depth and traversal.
The Structural Issue:
You create a table with a primary key and a foreign key column that points back to the same table’s primary key. This is often called a “parent_id” column. The root node has a null parent.
The Performance Issue:
Standard SQL queries struggle with deep hierarchies. If you need to fetch a manager and all their direct and indirect subordinates, a simple JOIN is insufficient. You need recursive Common Table Expressions (CTEs) or stored procedures that loop through levels. This can be computationally expensive.
The Integrity Issue:
Circular references are a silent killer. If Employee A manages Employee B, and Employee B manages Employee A, you have a cycle. The database must prevent this, or the application logic must detect it. In large systems, a cycle can cause an infinite loop in reporting tools.
- Depth Limits: Most systems cap the hierarchy depth (e.g., 32 levels) to prevent stack overflow errors during traversal.
- Path Aggregation: Calculating the total cost or count of a subtree requires recursive logic that is hard to optimize in standard query plans.
3. Supertype and Subtype Modeling: The Inheritance Dilemma 🧬
In object-oriented programming, inheritance is standard. In relational databases, it is a design choice that impacts storage and retrieval. The question is: do you model a Vehicle as a single table, or do you split it into Vehicle, Car, and Truck?
Option A: Single Table Inheritance
All attributes for all subtypes are in one table. Nulls are used for unused attributes.
- Pros: Simple queries, no joins needed to find any vehicle.
- Cons: Table bloat, hard to enforce subtype-specific constraints, many nullable columns.
Option B: Class Table Inheritance
One table for the supertype (Vehicle), and separate tables for subtypes (Car, Truck) linked by the primary key.
- Pros: Clean separation, no nulls, strict constraints per subtype.
- Cons: Querying requires joining multiple tables, which can impact read performance.
Our Principal DBAs highlighted that the choice often depends on the query patterns. If you frequently query specific subtypes, the Class Table approach is better. If you frequently aggregate all subtypes, the Single Table approach wins. The ERD must reflect this decision clearly to avoid confusion for future developers.
4. Temporal Data: Tracking Changes Over Time ⏳
Business rules change. A customer moves, a price updates, a contract expires. Storing only the “current” state is often insufficient for auditing or reporting. This leads to the design of temporal tables or Slowly Changing Dimensions (SCD).
The Complexity:
Instead of updating a row, you insert a new row with an effective start and end date. The old row is marked as inactive. This doubles the storage requirement for historical data and complicates the “current view” query.
The Query Challenge:
Selecting data “as of” a specific point in time requires filtering on the date range. If you miss the date range logic, you might return the wrong version of a record. This is often where data integrity issues surface in financial applications.
- Snapshot Design: Store the state at a point in time. Requires periodic batch jobs to write snapshots.
- Transaction Log Design: Capture every change. High write volume, complex retrieval logic.
- Periodic Design: Store valid intervals. Handles gaps in time well but requires careful boundary management.
5. Distributed Systems: Sharding and Relationships 🔗
When a single database cannot hold the data, sharding becomes necessary. This is where ERD design faces its most severe physical constraints. Relationships that cross sharding boundaries are costly.
The Join Problem:
If Table A is sharded by User ID, and Table B is linked to Table A, Table B must be sharded by the same User ID to avoid distributed joins. If Table B is sharded by something else, you must route the query to multiple shards, aggregate the results, and join locally.
Referential Integrity:
Foreign key constraints are hard to enforce across distributed nodes. Many systems disable foreign keys in sharded environments to maintain availability. This shifts the burden of integrity to the application layer, which is prone to race conditions.
Key Takeaways for Distributed ERDs:
- Avoid many-to-many relationships that span multiple shards.
- Denormalize data to reduce the need for cross-node joins.
- Design the partition key (sharding key) based on the most frequent query patterns, not just the primary key.
6. Performance vs. Normalization: The Trade-Off Balance ⚖️
Normalization (1NF, 2NF, 3NF) is taught as the gold standard for data integrity. However, in high-throughput systems, strict normalization can kill performance. The ERD must balance the two.
When to Denormalize:
- Read-Heavy Workloads: If you read data much more than you write, adding redundant columns saves join operations.
- Reporting Requirements: Aggregations on normalized data require complex joins that slow down dashboards.
- Write-Heavy Workloads: Sometimes, keeping data separate reduces locking contention during updates.
Our panel emphasized that there is no “perfect” schema. It is a compromise. An ERD should document where denormalization occurs and why, so future maintainers understand that redundancy is intentional, not an error.
Comparison of Modeling Patterns 📊
To assist in decision-making, here is a summary of the modeling patterns discussed and their typical use cases.
| Pattern | Best Use Case | Primary Risk | Complexity |
|---|---|---|---|
| Single Table | Simple hierarchies, low variety | Null fields, schema bloat | Low |
| Class Table | Strict subtypes, distinct attributes | Join overhead | Medium |
| Recursive | Org charts, categories | Traversal depth, cycles | High |
| Associative Entity | Many-to-Many with attributes | Join performance | Medium |
| Temporal | Auditing, history tracking | Query complexity | High |
| Distributed Sharding | Massive scale, horizontal growth | Referential integrity | Very High |
Checklist for ERD Review ✅
Before finalizing an Entity Relationship Diagram, use this checklist to catch common pitfalls. It is better to catch these issues during the design phase than in production.
- Cardinality: Have you clearly defined One-to-One, One-to-Many, and Many-to-Many relationships? Are the min/max constraints (0..1, 1..*) explicit?
- Data Types: Are the column types appropriate for the expected data size? (e.g., using Integer vs. Varchar for IDs).
- Nullability: Are foreign keys nullable? If yes, does the logic handle orphaned references gracefully?
- Indexing Strategy: Does the ERD indicate which columns need indexing for performance? Foreign keys are often indexed to speed up joins.
- Naming Conventions: Are table and column names consistent? Avoid abbreviations that might be ambiguous later.
- Business Rules: Are constraints (e.g., “A user cannot have two active subscriptions”) represented as logical checks or database constraints?
- Extensibility: Can the schema accommodate new attributes without requiring a full migration? (e.g., using an EAV pattern or JSON columns where appropriate).
Final Thoughts on Data Modeling 🧠
Designing an Entity Relationship Diagram is not just about drawing boxes and lines. It is about understanding the flow of data, the constraints of the hardware, and the needs of the business. The scenarios discussed here represent the friction points where theory meets practice.
By anticipating these challenges—recursive depth, distributed joins, temporal history, and inheritance trade-offs—you can build schemas that are resilient. A well-crafted ERD reduces technical debt and prevents the need for costly refactoring later. It is an investment in the stability of the entire system.
Remember that the best schema is the one that evolves with the data. Documentation is key. Ensure that every deviation from standard normalization is justified and recorded. This transparency is what separates a robust database architecture from a fragile one.