











O modelamento de dados é a base de qualquer arquitetura de banco de dados robusta. Embora a teoria seja frequentemente ensinada em cursos universitários, a aplicação prática em ambientes de produção revela um cenário repleto de casos extremos, gargalos de desempenho e ambiguidades lógicas. Diagramas de Relacionamento de Entidades (ERDs) servem como planta baixa para esses sistemas, mas muitas vezes tornam-se fontes de controvérsia quando o mundo real se recusa a se encaixar facilmente em caixas e linhas.
Sentamos com um painel de DBAs Principais e Arquitetos de Dados para analisar os cenários que constantemente confundem equipes na fase de design. Estes não são exercícios teóricos; são problemas que surgem quando os requisitos de negócios colidem com as restrições físicas de armazenamento. O objetivo aqui não é oferecer uma solução rápida, mas sim proporcionar uma compreensão profunda das trade-offs envolvidas.
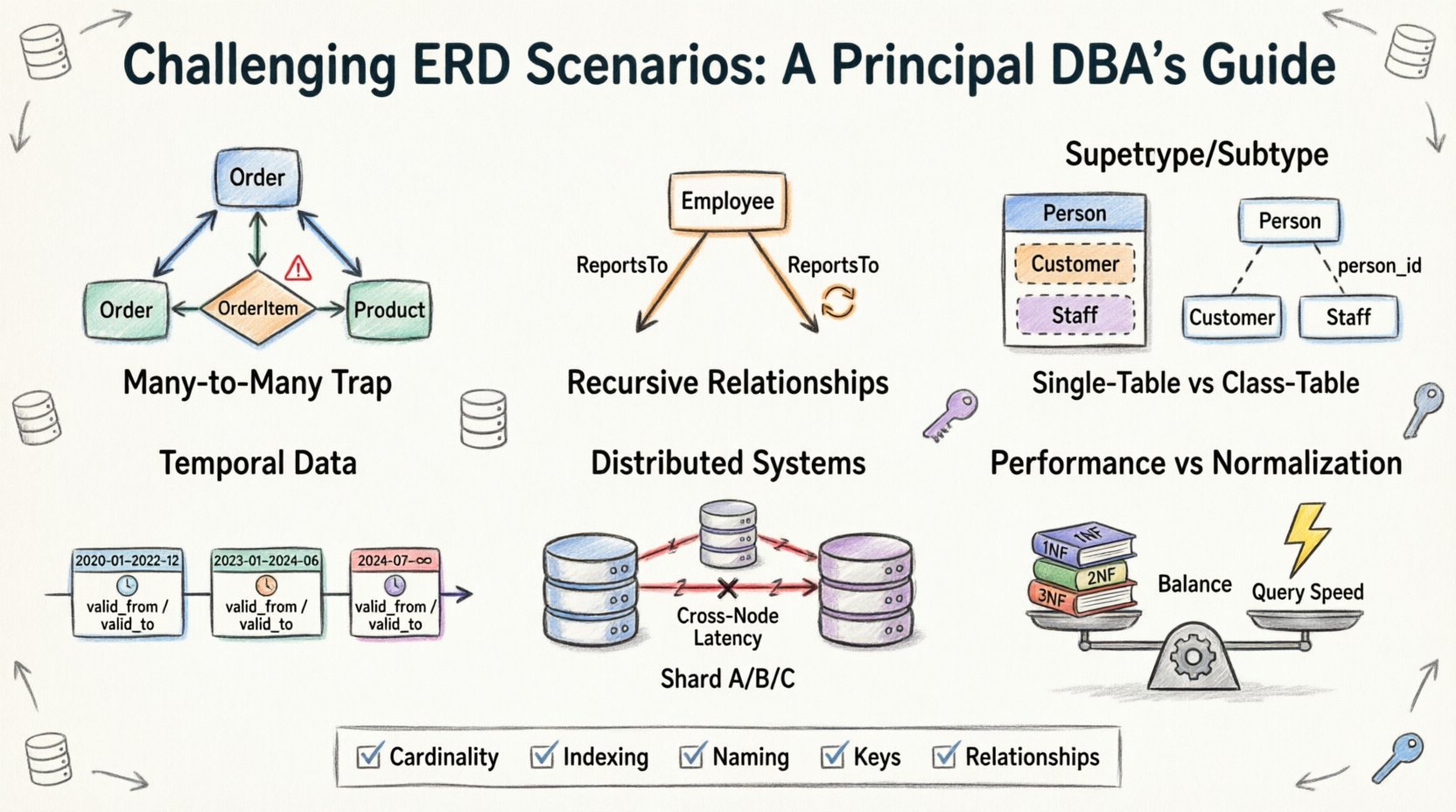
1. A Armadilha de Muitos para Muitos: Além das Tabelas de Junção Simples 🕸️
O ponto de partida mais comum no design de ERDs é a relação Muitos para Muitos. Parece intuitivo: um Aluno pode se inscrever em muitos Cursos, e um Curso pode ter muitos Alunos. A solução padrão envolve uma tabela de ligação ou associativa. No entanto, a complexidade surge quando atributos são introduzidos diretamente na própria relação.
- O Problema:Muitas vezes, as equipes tentam armazenar dados de matrícula (como notas ou datas de inscrição) na tabela principal de Aluno ou Curso, resultando em redundância massiva ou valores nulos.
- A Realidade:A própria relação é uma entidade. Deve ter sua própria chave primária e chaves estrangeiras apontando de volta para os pais.
- O Desafio:Gerenciar exclusões em cascata. Se um Curso for removido, o que acontece com os registros de Matrícula? Se uma Matrícula for excluída, o Aluno desaparece? Essas decisões definem a integridade dos dados.
Durante nossa discussão, um DBA Principal observou que a tabela associativa muitas vezes se torna um gargalo de desempenho. Ao consultar dados através dessa junção, o motor do banco de dados deve realizar uma operação de junção que pode escalar mal à medida que o número de linhas cresce para milhões. A solução nem sempre é arquitetônica; às vezes exige desnormalização, mas isso introduz anomalias de atualização.
Principais Considerações para Muitos para Muitos:
- A relação possui atributos que exigem indexação?
- A relação é ativa ou histórica? (por exemplo, uma matrícula atual é diferente de uma anterior?)
- Como o sistema lidará com registros órfãos se um pai for excluído?
2. Relações Recursivas: Hierarquias de Referência Automática 🌳
Dados hierárquicos estão em toda parte. Pense em uma estrutura organizacional, uma lista de materiais ou um tópico de comentários em um fórum. Modelar isso exige que uma tabela se refira a si mesma. Embora conceitualmente simples, implementar isso em um esquema relacional introduz desafios específicos em relação à profundidade e à navegação.
O Problema Estrutural:
Você cria uma tabela com uma chave primária e uma coluna de chave estrangeira que aponta de volta para a própria chave primária da tabela. Isso é frequentemente chamado de coluna ‘parent_id’. O nó raiz possui um pai nulo.
O Problema de Desempenho:
Consultas SQL padrão têm dificuldade com hierarquias profundas. Se você precisar buscar um gerente e todos os seus subordinados diretos e indiretos, uma simples junção não é suficiente. Você precisa de Expressões de Tabela Comum (CTEs) recursivas ou procedimentos armazenados que percorram os níveis. Isso pode ser computacionalmente custoso.
O Problema de Integridade:
Referências circulares são um assassino silencioso. Se o Funcionário A gerencia o Funcionário B, e o Funcionário B gerencia o Funcionário A, você tem um ciclo. O banco de dados deve impedir isso, ou a lógica da aplicação deve detectá-lo. Em sistemas grandes, um ciclo pode causar um loop infinito em ferramentas de relatórios.
- Limites de Profundidade:A maioria dos sistemas limita a profundidade da hierarquia (por exemplo, 32 níveis) para evitar erros de estouro de pilha durante a navegação.
- Agregação de Caminho:Calcular o custo total ou a contagem de uma subárvore exige lógica recursiva que é difícil de otimizar em planos de consulta padrão.
3. Modelagem de Super Tipo e Sub Tipo: O Dilema da Herança 🧬
Na programação orientada a objetos, a herança é padrão. Nos bancos de dados relacionais, é uma escolha de design que afeta armazenamento e recuperação. A pergunta é: você modela um Veículo como uma única tabela, ou divide em Veículo, Carro e Caminhão?
Opção A: Herança de Tabela Única
Todos os atributos para todos os subtipos estão em uma única tabela. Valores nulos são usados para atributos não utilizados.
- Vantagens:Consultas simples, sem necessidade de junções para encontrar qualquer veículo.
- Desvantagens:Aumento excessivo da tabela, difícil de impor restrições específicas por subtipo, muitas colunas nulas.
Opção B: Herança de Tabela de Classe
Uma tabela para o tipo superior (Veículo), e tabelas separadas para os subtipos (Carro, Caminhão), ligadas pela chave primária.
- Vantagens:Separação clara, sem valores nulos, restrições rígidas por subtipo.
- Desvantagens:Consultas exigem junções em múltiplas tabelas, o que pode afetar o desempenho de leitura.
Nossos principais DBAs destacaram que a escolha depende frequentemente dos padrões de consulta. Se você consulta com frequência subtipos específicos, a abordagem de Tabela de Classe é melhor. Se você frequentemente agrupa todos os subtipos, a abordagem de Tabela Única prevalece. O ERD deve refletir claramente essa decisão para evitar confusão para desenvolvedores futuros.
4. Dados Temporais: Rastreamento de Mudanças ao Longo do Tempo ⏳
Regras de negócios mudam. Um cliente se muda, um preço é atualizado, um contrato expira. Armazenar apenas o estado atual geralmente é insuficiente para auditoria ou relatórios. Isso leva ao design de tabelas temporais ou Dimensões de Mudança Lenta (SCD).
A Complexidade:
Em vez de atualizar uma linha, você insere uma nova linha com uma data de início e fim efetivas. A linha antiga é marcada como inativa. Isso duplica a necessidade de armazenamento para dados históricos e complica a consulta da “visão atual”.
O Desafio da Consulta:
Selecionar dados “na data de” um ponto específico exige filtragem pela faixa de datas. Se você esquecer a lógica da faixa de datas, pode retornar a versão incorreta de um registro. É frequentemente aqui que surgem problemas de integridade de dados em aplicações financeiras.
- Design de Instantâneo:Armazene o estado em um ponto no tempo. Exige trabalhos em lote periódicos para gravar instantâneos.
- Design de Registro de Transações:Capture todas as mudanças. Alto volume de escrita, lógica de recuperação complexa.
- Design Periódico:Armazene intervalos válidos. Lidam bem com lacunas no tempo, mas exigem gerenciamento cuidadoso dos limites.
5. Sistemas Distribuídos: Shard e Relacionamentos 🔗
Quando um único banco de dados não consegue armazenar os dados, o shard torna-se necessário. É aqui que o design do ERD enfrenta suas mais severas restrições físicas. Relacionamentos que cruzam os limites do shard são custosos.
O Problema da Junção:
Se a Tabela A é shard por ID de Usuário, e a Tabela B está ligada à Tabela A, a Tabela B deve ser shard pela mesma ID de Usuário para evitar junções distribuídas. Se a Tabela B for shard por outra coisa, você deve encaminhar a consulta para múltiplos shards, agrupar os resultados e fazer a junção localmente.
Integridade Referencial:
As restrições de chave estrangeira são difíceis de aplicar entre nós distribuídos. Muitos sistemas desativam chaves estrangeiras em ambientes particionados para manter a disponibilidade. Isso transfere a responsabilidade pela integridade para a camada de aplicativo, que é propensa a condições de corrida.
Principais aprendizados para ERDs distribuídos:
- Evite relacionamentos muitos para muitos que abrangem múltiplas partições.
- Denormalize os dados para reduzir a necessidade de junções entre nós.
- Projete a chave de partição (chave de particionamento) com base nos padrões de consulta mais frequentes, e não apenas na chave primária.
6. Desempenho vs. Normalização: O equilíbrio entre compromissos ⚖️
A normalização (1FN, 2FN, 3FN) é ensinada como o padrão ouro para integridade de dados. No entanto, em sistemas de alta taxa de transferência, a normalização rígida pode prejudicar o desempenho. O ERD deve equilibrar os dois aspectos.
Quando denormalizar:
- Cargas de trabalho com leitura intensiva: Se você ler dados muito mais do que gravar, adicionar colunas redundantes economiza operações de junção.
- Requisitos de relatórios: Agregações em dados normalizados exigem junções complexas que retardam os painéis.
- Cargas de trabalho com escrita intensiva: Às vezes, manter os dados separados reduz a contenção de bloqueios durante atualizações.
Nosso painel enfatizou que não existe um esquema ‘perfeito’. É um compromisso. Um ERD deve documentar onde ocorre a denormalização e por quê, para que futuros mantenedores entendam que a redundância é intencional, e não um erro.
Comparação de padrões de modelagem 📊
Para auxiliar na tomada de decisões, aqui está um resumo dos padrões de modelagem discutidos e seus casos de uso típicos.
| Padrão | Melhor caso de uso | Risco principal | Complexidade |
|---|---|---|---|
| Tabela única | Hierarquias simples, baixa variedade | Campos nulos, aumento do esquema | Baixa |
| Tabela de classe | Subtipos rígidos, atributos distintos | Custo de junção | Média |
| Recursivo | Organogramas, categorias | Profundidade de percurso, ciclos | Alto |
| Entidade associativa | Muitos para muitos com atributos | Desempenho de junção | Médio |
| Temporal | Auditoria, rastreamento de histórico | Complexidade da consulta | Alto |
| Sharding distribuído | Escala massiva, crescimento horizontal | Integridade referencial | Muito alto |
Checklist para revisão de ERD ✅
Antes de finalizar um Diagrama de Relacionamento de Entidades, use esta checklist para identificar armadilhas comuns. É melhor detectar esses problemas na fase de design do que na produção.
- Cardinalidade:Você definiu claramente as relações Um para Um, Um para Muitos e Muitos para Muitos? As restrições mínimas/máximas (0..1, 1..*) estão explícitas?
- Tipos de dados:Os tipos de coluna são adequados para o tamanho esperado dos dados? (por exemplo, usar Integer em vez de Varchar para IDs).
- Nulidade:As chaves estrangeiras são nulas? Se sim, a lógica lida com referências órfãs de forma adequada?
- Estratégia de indexação:O ERD indica quais colunas precisam de indexação para desempenho? As chaves estrangeiras geralmente são indexadas para acelerar as junções.
- Convenções de nomeação:Os nomes das tabelas e colunas são consistentes? Evite abreviações que possam ser ambíguas posteriormente.
- Regras de negócios:As restrições (por exemplo, “Um usuário não pode ter duas assinaturas ativas”) são representadas como verificações lógicas ou restrições do banco de dados?
- Extensibilidade: O esquema pode acomodar novos atributos sem exigir uma migração completa? (por exemplo, usando um padrão EAV ou colunas JSON quando apropriado).
Pensamentos Finais sobre Modelagem de Dados 🧠
Projetar um Diagrama de Relacionamento de Entidades não é apenas sobre desenhar caixas e linhas. É sobre compreender o fluxo de dados, as restrições do hardware e as necessidades do negócio. Os cenários discutidos aqui representam os pontos de atrito onde a teoria encontra a prática.
Antecipando esses desafios — profundidade recursiva, junções distribuídas, histórico temporal e trade-offs de herança — você pode construir esquemas resilientes. Um ERD bem elaborado reduz a dívida técnica e evita a necessidade de refatoração cara no futuro. É um investimento na estabilidade de todo o sistema.
Lembre-se de que o melhor esquema é aquele que evolui com os dados. A documentação é fundamental. Certifique-se de que toda desvio da normalização padrão seja justificado e registrado. Essa transparência é o que diferencia uma arquitetura de banco de dados robusta de uma frágil.