











Modernizacja systemu dziedziczonego do architektury mikroserwisów to podróż pełna wyzwań technicznych i organizacyjnych. Choć wiele zespołów skupia się intensywnie na refaktoryzacji kodu i konteneryzacji, istotnym przeszkodą często jest warstwa danych. Dokładnie model tradycyjnego diagramu relacji encji (ERD) może stać się poważnym ograniczeniem podczas przejścia do systemów rozproszonych. 📉
Kiedy projektujesz aplikację monolityczną, model danych jest centralizowany. Diagram ERD reprezentuje jedyną prawdę, z normalizowanymi tabelami połączonymi kluczami obcymi. Ten podejście działa dobrze dla pojedynczego wystąpienia bazy danych. Jednak mikroserwisy wymagają niezależności. Gdy siłą narzucasz strukturę ERD monolitycznej architektury na architekturę rozproszoną, tworzysz silne powiązania, które anulują korzyści z rozdzielenia systemu. 🚧
Ten przewodnik bada, dlaczego klasyczny sposób myślenia wokół ERD utrudnia przyjęcie architektury mikroserwisów i zapewnia praktyczny plan przejścia do nowych strategii modelowania danych. Omówimy zarządzanie rozproszonymi danymi, modele spójności oraz techniki wizualizacji zgodne z zasadami projektowania opartego na domenie. 🗺️
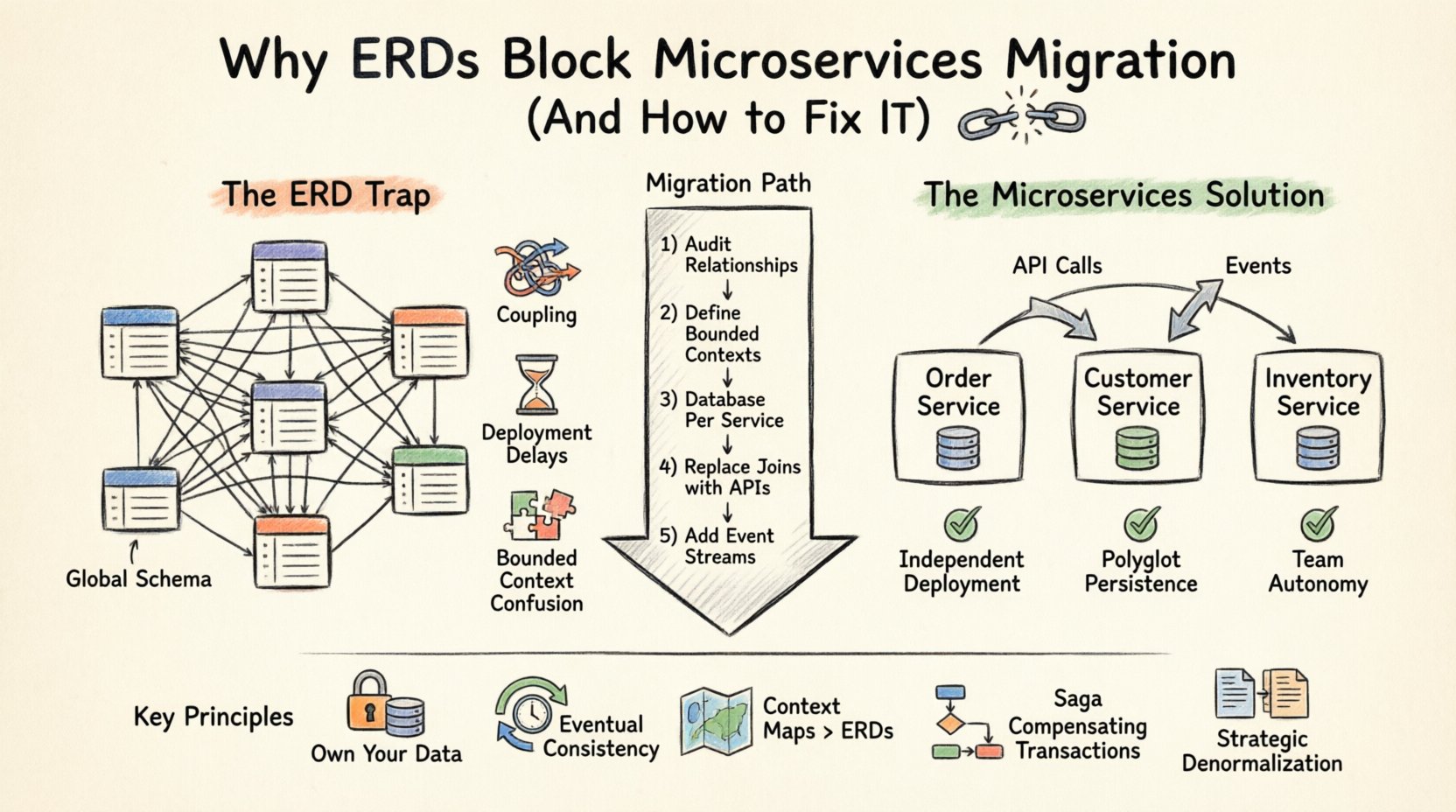
Zrozumienie pułapki ERD w systemach rozproszonych 🧩
Diagram relacji encji to wizualna reprezentacja struktury logicznej bazy danych. Definiuje encje (tabelki), atrybuty (kolumny) oraz relacje (klucze obce). W środowisku monolitycznym ta centralizacja jest mocą. Zapewnia integralność danych poprzez transakcje ACID i upraszcza zapytania na całym zastosowaniu.
Jednak architektura mikroserwisów opiera się na zasadzieniezależności usług. Każda usługa powinna posiadać własne dane i udostępniać je wyłącznie poprzez interfejs API. Gdy utrzymujesz wspólny diagram ERD obejmujący wiele usług, naruszasz granicę własności. Powoduje to następujące problemy:
- Zależności globalnego schematu: Jeśli usługa A potrzebuje połączyć dane z usługi B bezpośrednio na poziomie bazy danych, nie są już niezależne. Zmiana schematu usługi B powoduje awarię usługi A.
- Granice transakcji: Transakcje ACID między wieloma bazami danych są skomplikowane i obciążające pod względem wydajności. Transakcje rozproszone często prowadzą do zawieszeń i wzrostu opóźnień.
- Zależność wdrażania: Jeśli model danych jest współdzielony, nie możesz wdrażać usług niezależnie. Musisz koordynować zmiany schematu między zespołami, co spowalnia cykle wdrażania.
- Zmieszanie kontekstów ograniczonych: Różne usługi mogą inaczej rozumieć tę samą encję. Diagram ERD wymusza jednoznaczną definicję, ignorując szczegóły specyficzne dla domeny.
Problem powiązań: klucze obce i połączenia 🔗
Jednym z najczęściej popełnianych błędów podczas migracji jest próba zachowania istniejącego schematu bazy danych podczas dzielenia kodu aplikacji. Powoduje toantypatrón współdzielonej bazy danych. W tym scenariuszu wiele usług łączy się z tym samym wystąpieniem bazy danych, polegając na kluczach obcych w celu utrzymania relacji.
Choć wygląda to jak poprawna struktura ERD, to ukryty monolit. Oto dlaczego ten podejście zawodzi w kontekście mikroserwisów:
- Opóźnienia sieciowe: Nawet jeśli baza danych jest lokalna w sieci, zapytania między usługami wprowadzają przejścia sieciowe, które pogarszają wydajność w porównaniu do zapytań lokalnych.
- Jedno miejsce awarii: Jeśli baza danych się zawiesi, każda usługa się zawiesi. Mikroserwisy dążą do odporności poprzez izolację.
- Ryzyka bezpieczeństwa: Usługa, która nie powinna mieć bezpośredniego dostępu do innych danych, może nadal do nich uzyskać dostęp poprzez ciąg połączenia z bazą danych. Interfejsy API zapewniają kontrolowany dostęp; bezpośredni dostęp do bazy danych nie.
- Zależność technologiczna: Wszystkie usługi muszą używać tej samej technologii bazy danych. Mikroserwisy pozwalają na wielojęzyczne przechowywanie danych, gdzie różne usługi używają najodpowiedniejszego magazynu danych dla swoich konkretnych potrzeb.
Aby to naprawić, musisz odstąpić od złączeń SQL przez granice usług. Zamiast tego powinieneś używać kompozycji interfejsów API lub synchronizacji danych opartej na zdarzeniach. 🔄
Baza danych na usługę: Złote prawo 🏦
Podstawowym wzorcem architektury danych mikroserwisów jestBaza danych na usługę. Każda usługa posiada własny schemat bazy danych. Żadna inna usługa nie może uzyskać dostępu do tej bazy danych bezpośrednio. Komunikacja odbywa się wyłącznie poprzez publiczny interfejs API usługi.
Ten przeskok wymaga podstawowej zmiany sposobu wizualizacji danych. Nie możesz już rysować jednego ogromnego diagramu ERD dla całego systemu. Zamiast tego tworzysz wiele mniejszych diagramów ERD, jeden dla każdej usługi. 📄
| Aspekt | Monolityczny diagram ERD | Model mikroserwisów |
|---|---|---|
| Zakres schematu | Globalny / Zjednoczony | Lokalny / specyficzny dla usługi |
| Związki | Klucze obce | Wywołania interfejsów API / Zdarzenia |
| Spójność | Silna (ACID) | Ostateczna (BASE) |
| Wdrożenie | Związane | Niezależne |
Zarządzanie spójnością bez współdzielonych transakcji 🤝
Gdy rozdzielisz bazy danych, tracisz możliwość uruchomienia pojedynczej transakcji, która aktualizowałaby jednocześnie usługę A i usługę B. W monolicie możesz użyć transakcji bazy danych do przeniesienia środków z konta A na konto B. W mikroserwisach te konta mogą należeć do różnych usług.
Ponieważ nie możesz zagwarantować natychmiastowej spójności w systemach rozproszonych, musisz przyjąćSpójność ostateczna. Oznacza to, że system osiągnie spójny stan z czasem, ale niekoniecznie w dokładnie tym momencie, gdy użytkownik kliknie przycisk.
Wdrażanie sag
Aby obsłużyć złożone przepływy pracy obejmujące wiele usług, użyjwzorca sag. Saga to ciąg lokalnych transakcji, gdzie każda transakcja aktualizuje bazę danych w jednej usłudze. Jeśli krok zawiedzie, saga wykonuje transakcje kompensacyjne w celu cofnięcia zmian dokonanych przez poprzednie kroki.
- Choreografia: Usługi emitują zdarzenia, które wywołują działania w innych usługach. Nie ma centralnego koordynatora.
- Orkiestracja: Usługa centralnego koordynatora zarządza przepływem pracy i informuje inne usługi, co mają robić.
Ten podejście zapewnia integralność danych bez potrzeby współdzielonych blokad lub transakcji rozproszonych. Dodaje złożoność implementacji, ale jest konieczne do utrzymania zdrowia systemu. 🛡️
Wizualizacja danych bez ERD: Mapy kontekstów 🗺️
Jeśli porzucisz tradycyjny ERD, czym możesz wizualizować architekturę danych? Odpowiedź tkwi wMapy kontekstów DDD (Domain-Driven Design). Podczas gdy ERD skupia się na tabelach i kolumnach, mapa kontekstów skupia się na ograniczonych kontekstach i relacjach.
Zamiast rysować linie między tabelami, rysujesz linie między usługami. Określasz, jak dane przepływają między nimi:
- Klient-Dostawca: Jedna usługa dostarcza dane drugiej. Dostawca definiuje kontrakt.
- Zgodnik: Usługa korzystająca musi dostosować się do modelu dostawcy.
- Otwarta usługa hosta: Usługa udostępnia swoje dane za pomocą otwartego protokołu.
- Oddzielne drogi: Obie usługi niezależnie rozwijają własne modele.
Taka zmiana wizualizacji pomaga zespołom zrozumiećdlaczego dane są duplikowane. W monolitach duplikacja jest zła. W mikroserwisach duplikacja często jest cechą, która odseparowuje usługi. Na przykład usługaUsługa Zamówień może przechowywać zrzutImię i nazwisko klienta aby uniknąć wywołania sieciowego za każdym razem, gdy przegląda się zamówienie. Ta kompromis jest akceptowalny pod kątem wydajności.
Kroki migracji: Przejście od ERD do rozproszonej architektury danych 🚀
Przejście od zcentralizowanego ERD do modelu rozproszonej architektury danych nie jest jednorazowym wydarzeniem. Jest to proces etapowy. Oto zalecane podejście do zarządzania migracją.
Krok 1: Audyt istniejących relacji danych
Zanim podzielisz cokolwiek, zapisz każdą relację w obecnym ERD. Zidentyfikuj, które tabele są intensywnie odczytywane, które są intensywnie zapisywane, a które często łączone ze sobą. Ta analiza pomaga Ci grupować encje w logiczne granice usług. 📊
Krok 2: Zdefiniuj ograniczone konteksty
Grupuj encje na podstawie domen biznesowych, a nie zależności technicznych. Na przykład, Katalog produktów różni się od Zarządzanie zapasami systemu, nawet jeśli oba wykorzystują pole ProductID pole. Upewnij się, że granice są zgodne z strukturami zespołów (Prawo Conwaya).
Krok 3: Wprowadź bazę danych na usługę
Utwórz nową instancję bazy danych dla każdej usługi. Przenieś odpowiednie dane z monolitycznej bazy danych. Nie musisz przenosić wszystkiego od razu. Zacznij od kluczowych danych wymaganych do działania usługi. 🏗️
Krok 4: Zastąp połączenia (JOIN) wywołaniami interfejsów API
Przepisz swoje zapytania. Zamiast JOIN Orders, Customers, Twój kod powinien wywoływać interfejs API klienta aby pobrać szczegóły. Może to wprowadzić opóźnienie, dlatego rozważ strategie buforowania lub denormalizację tam, gdzie jest to odpowiednie.
Krok 5: Wprowadź strumienie zdarzeń
W celu aktualizacji w czasie rzeczywistym zaimplementuj szynę zdarzeń. Gdy encja zmienia się w jednej usłudze, opublikuj zdarzenie. Inne usługi mogą subskrybować te zdarzenia, aby zaktualizować swoje lokalne kopie danych. Zapewnia to spójność ostateczną bez bezpośredniego sprzężenia.
Typowe pułapki podczas migracji ⚠️
Nawet z planem zespoły często napotykają trudności podczas przejścia. Bądź świadom tych typowych problemów.
- zbyt wczesne podział: Nie dziel usług, zanim nie zrozumiesz przepływu danych. Zbyt wczesny podział może prowadzić do złożoności rozproszonej, zanim będzie to możliwe.
- Ignorowanie własności danych: Jeśli wiele zespołów domaga się własności tej samej encji danych, pojawią się konflikty. Przypisz jasną własność każdej usłudze.
- Nadmierna normalizacja: W systemie rozproszonym często preferuje się denormalizację, aby zmniejszyć liczbę wywołań interfejsów API wymaganych do wyświetlenia strony.
- Zależność od sieci: Nigdy nie zakładaj, że sieć jest doskonała. Zaimplementuj limit czasu, ponowne próby i przerywacze obwodów dla komunikacji między usługami.
Zgodność organizacyjna 🤝
Architektura danych nie jest tylko techniczna; jest organizacyjna. Model danych rozproszony wymaga od zespołów innej formy komunikacji. W monolicie programiści rozmawiają nad wspólną tablicą (bazą danych). W mikroserwisach rozmawiają nad kontraktem interfejsu API.
Upewnij się, że Twoje zespoły mają możliwość zmiany schematu bazy danych bez konsultacji z centralnym zespołem zarządzania. Ta autonomia to jedyna droga do utrzymania szybkości niezależnego wdrażania. Jeśli wprowadzisz centralny zespół, który zatwierdza wszystkie zmiany schematu, ponownie wprowadzisz węzeł zatyczki, którego próbowałeś uniknąć. 👥
Ostateczne rozważania dotyczące strategii danych 🧭
Odstąpienie od tradycyjnego diagramu relacji encji to istotny krok. Wymaga on zmiany nastawienia odintegralności danych poprzez ograniczeniadointegralności danych poprzez logikę aplikacji i zdarzenia. Diagram ERD to narzędzie dla baz danych relacyjnych, a nie projekt dla systemów rozproszonych.
Przyjmując wzorzec bazy danych na usługę, wykorzystując architekturę opartą na zdarzeniach i skupiając się na ograniczonych kontekstach, możesz uniknąć sprzężenia, które spowalnia Twoją migrację. Celem nie jest zniszczenie istniejącego modelu danych, ale jego ewolucja w strukturę wspierającą niezależne skalowanie i odporność.
Pamiętaj, że spójność to spektrum. Nie potrzebujesz silnej spójności wszędzie. Zidentyfikuj, które części Twojego systemu wymagają ścisłej dokładności, a które mogą tolerować spójność ostateczną. Ta praktyczność pomoże Ci uniknąć nadmiernego skomplikowania rozwiązania.
Zacznij od audytu obecnych diagramów. Zidentyfikuj połączenia przekraczające granice usług. Zaprojektuj migrację tych konkretnych encji. Robiąc małe kroki, sprawdzaj wyniki. I zawsze trzymaj domenę biznesową w centrum projektowania danych. 🎯
Kluczowe wnioski 📝
- Unikaj współdzielonych baz danych między usługami, aby zapobiec sprzężeniu.
- Używaj kompozycji interfejsów API zamiast złączeń SQL do danych między usługami.
- Przyjmij spójność ostateczną, aby uzyskać dostępność i odporność na podziały.
- Wizualizuj dane za pomocą map kontekstów zamiast globalnych diagramów ERD.
- Przypisz jasne zarządzanie danymi do poszczególnych zespołów usług.
- Zaplanuj duplikację danych jako optymalizację wydajności.
Śledząc te zasady, możesz poruszać się po złożonościach migracji danych, nie pozwalając diagramowi ERD określać ograniczeń Twojej nowej architektury. Przyszłość to systemy rozproszone, rozdecentralizowane i zaprojektowane do skalowania. 🚀