











現代のソフトウェア工学では、システムがモノリシックなエントリティとして存在することはめったにありません。複数のサービス、プロセス、ストレージユニットがネットワーク境界を越えて相互に作用しています。これらの異なるユニット間を情報がどのように移動するかを理解することは、システムの整合性を維持し、障害を診断し、スケーラビリティを計画するために不可欠です。このガイドでは、分散アーキテクチャ内のデータフローをマッピングおよび可視化するプロセスについて解説し、特にC4モデルを構造的フレームワークとして活用する方法を扱います。
明確なドキュメントがなければ、分散システムはすぐにブラックボックス化します。エンジニアはリクエストの追跡やボトルネックの特定、変更の影響の理解に苦労します。データの動きを可視化することで、明確な理解が得られます。抽象的な論理を、ステークホルダーが解釈できる具体的な図に変換するのです。この文書では、境界の定義、接続のマッピング、そしてこれらの図を時間とともに維持するための手法を概説します。
1. アーキテクチャの地図 🌍
分散システムは、モノリシックなアプリケーションが直面しない複雑性をもたらします。単一のプロセスがすべてのロジックを処理する場合、データフローは内部的で線形です。複数のコンテナやサービスが関与する場合、データはネットワークを横断し、ファイアウォールを通過し、信頼境界を越えます。各ホップは遅延を引き起こし、障害の潜在的ポイントを追加します。
この地図を可視化するには、標準化されたアプローチが必要です。臨時の図はしばしば一貫性を欠きます。あるエンジニアはデータベースを円筒として描く一方、別のエンジニアは箱を使います。標準化により、図が見られたときにその意味が即座に理解できるようになります。C4モデルは、特定の抽象化レベルを定義することで、この標準化を提供します。
分散可視化における主な課題には以下が含まれます:
- ネットワーク遅延:データがキューまたはネットワークで待機している場所を可視化すること。
- データ整合性:ノード間で状態がどのように同期されているかを示すこと。
- 障害領域:コンテナの1つが応答を停止した場合に何が起こるかを特定すること。
- セキュリティ境界:データ暗号化または認証が必要な場所をマークすること。
2. C4モデルの説明 📐
C4モデルは、ソフトウェアアーキテクチャを記述するために使用される図の階層です。4つのレベルから構成されており、それぞれが異なる対象者と目的に応じています。コンテナ間のデータフロー可視化においては、コンテナレベルとコンポーネントレベルが最も関連性が高いです。
レベル1:システムコンテキスト
この高レベルのビューでは、システムを単一のブロックとして表示し、外部のユーザーおよびシステムとの相互作用を示します。質問「このシステムはどのような機能を果たし、誰が使用しているのか?」に答えるものです。コンテキストを把握するには有用ですが、コンテナ間の内部データフローは表示されません。
レベル2:コンテナ
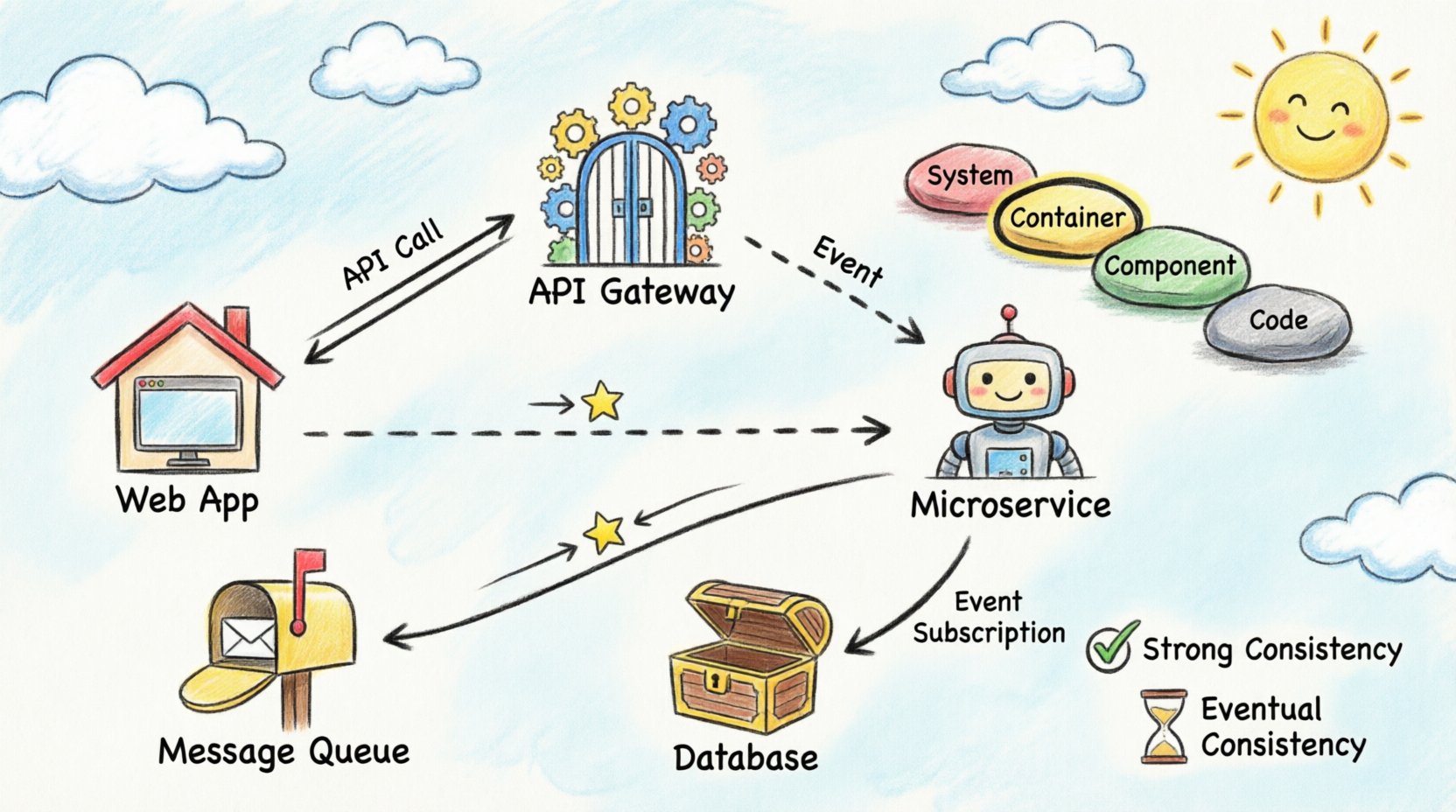
これは分散可視化の核です。コンテナはデプロイ可能な独立した単位を表します。ウェブアプリケーション、モバイルアプリ、マイクロサービス、データストアなどが例です。このレベルでは、これらのユニット間をデータがどのように流れているかを示します。APIコール、メッセージキュー、直接のデータベース接続をマッピングするのに最適な場所です。
レベル3:コンポーネント
コンテナ内では、コンポーネントはソフトウェアの異なる部分を表します。このレベルでは、ロジックの詳細に踏み込み、内部クラス間の相互作用やモジュールの依存関係を示します。重要ではありますが、高レベルのデータフロー分析にはしばしば詳細が過ぎます。
レベル4:コード
このレベルは特定のクラスやメソッドに対応します。アーキテクチャフローのドキュメント作成には一般的に不要であり、開発者向けの参照資料に適しています。
3. コンテナ境界の特定 🚧
データフローの線を描く前に、コンテナとは何かを定義する必要があります。コンテナはデプロイ可能な単位です。他のコンテナとは独立したライフサイクルを持ちます。同じ物理サーバー上で実行される場合もあれば、異なる地域に分散して実行される場合もあります。
一般的なコンテナタイプには以下が含まれます:
- ウェブアプリケーション:ブラウザ経由でアクセスされるフロントエンドインターフェース。
- マイクロサービス:特定のビジネスロジックを処理するバックエンドサービス。
- APIゲートウェイ:内部サービスにトラフィックをルーティングするエントリポイント。
- データストア:データベース、キャッシュ、またはファイルシステム。
- バッチ処理:非同期にデータを処理するスケジュールされたジョブ。
境界を定義する際には、デプロイ戦略を検討してください。2つのサービスが常に一緒にデプロイされ、メモリを共有する場合、それらは単一のコンテナに属している可能性があります。一方、独立してスケーリングできる場合は、別々のコンテナにするべきです。この決定は、データフローの可視化に影響を与えます。
4. データフローのパターンをマッピングする 📡
データフローは、2つのボックスを結ぶ単なる線ではありません。特定の相互作用のパターンを表しています。パターンを理解することは、正確な可視化にとって不可欠です。以下の表は、一般的なパターンとそれらをどのように表現すべきかを示しています。
| パターン | 方向 | 可視性 | 使用例 |
|---|---|---|---|
| 同期型リクエスト/レスポンス | 双方向(クライアント → サーバー → クライアント) | 即時 | API呼び出し、フォーム送信 |
| 非同期の発射後放棄 | 単方向(クライアント → サーバー) | 遅延 | ログ記録、分析イベント |
| プルベースの処理 | 単方向(ワーカー ← キュー) | オンデマンド | バックグラウンドジョブ、データインジェスト |
| イベント購読 | 単方向(発信者 → 受信者) | イベントによってトリガーされる | 通知、状態の変更 |
同期通信
同期フローでは、送信者が応答を待つ。これはAPIの相互作用で一般的である。これを可視化する際は、リクエストと応答を示す矢印付きの実線を使用する。使用されたプロトコル(例:HTTPやgRPC)をラベルで示す。これによりエンジニアは、この相互作用のブロッキング性を理解できる。
非同期通信
非同期フローは送信者と受信者を分離する。送信者はメッセージをキューに配置して処理を継続する。受信者は後にメッセージを処理する。メッセージブローカーを表すために破線または明確なアイコンを使用して可視化する。異なるデータストリームを区別するためにキュー名を明示することが重要である。
5. 同期と整合性の扱い ⚖️
分散型データフローにおける最も難しい点の一つは、状態管理である。データが一つのコンテナに書き込まれたとき、それが他のコンテナに即座に反映されるか?可視化はこれらの整合性要件を捉えなければならない。
強整合性
一部のシステムでは、すべてのノードが同じ時刻に同じデータを参照する必要がある。これは、単一の真実のソースまたは同期レプリケーションを意味することが多い。図では、これらの接続に「強整合性」または「ACID」というラベルを付ける。これにより、システムの一部でダウンタイムが発生した場合、他の部分にも影響する可能性があることをステークホルダーに警告する。
最終整合性
多くの分散システムでは、即時整合性よりも可用性を優先する。データが伝播するまで数秒または数分かかることがある。時間の指標や遅延を示す「Sync」ラベルを追加することでこれを可視化する。これにより、ユーザーが更新された情報をいつ見られるかという期待を適切に管理できる。
ステートレス vs. ステートフルコンテナ
ステートレスコンテナはローカルにデータを保存しない。外部のデータベースやキャッシュに依存する。ステートフルコンテナは自らのストレージ内にデータを保持する。フローをマッピングする際は、外部ストレージがコンテナから明確に分離されていることを確認する。コンテナがデータを保存する場合は、フローラインがそのコンテナ内またはそれに接続されたストレージアイコンを指すようにする。
6. ドキュメントのメンテナンス 📝
図は正確でなければ意味がない。時間とともにコードが変更され、新しいサービスが追加され、非推奨のサービスが削除される。静的な図はすぐに陳腐化する。メンテナンスの戦略が必要である。
ドキュメントを最新の状態に保つためのベストプラクティスには以下が含まれる:
- 自動生成:可能な限り、コードのアノテーションや構成ファイルから図を生成する。これにより手作業の負担が減り、コードとドキュメントのずれを防ぐことができる。
- レビュー周期:プルリクエストの「完了定義」に図の更新を含める。サービスインターフェースが変更された場合、図も変更されなければならない。
- バージョン管理:アーキテクチャ図をコードとして扱う。バージョン管理システムに保存して履歴を追跡し、変更が誤っていた場合にロールバックできるようにする。
- ツール標準:一貫したツールスタックを使用する。異なるチーム間で異なる図作成プラットフォームを切り替えることを避ける。
7. 避けるべき一般的な落とし穴 🛑
構造化されたアプローチを採用しても、可視化プロセス中にエラーが発生する可能性がある。一般的なミスに気づいておくことで、高品質なドキュメントを維持できる。
過剰な抽象化
図をあまり簡略化したくなるのは当然だが、10のサービスを「Backend」という1つのボックスにまとめると、特定のデータパスを追跡できなくなる。コンテナレベルの粒度を維持する。ライフサイクルが完全に同じでない限り、異なるデプロイ単位をマージしてはならない。
失敗経路を無視する
ほとんどの図はすべてが正常に動作する「ハッピーパス」を示す。信頼性の高い可視化では、失敗モードも示す必要がある。サービスがタイムアウトした場合、フローはどこへ向かうか?フォールバックサービスはあるか?デッドレターキューはあるか?これらの経路を追加することで、図はレジリエンス計画のツールとなる。
命名の不整合
図のサービスに使用する用語はコードベースと同一のものを使うこと。コードで「Order-Service」と呼ばれるサービスを、図では「Orders API」とラベル付けしないでください。これによりデバッグセッション中に混乱が生じる。
データ型の欠落
2つのコンテナの間の線はデータが移動していることを示すが、何のデータが移動しているかは教えてくれない。データペイロードの種類を線に注釈を付けると役立つ。たとえば「JSONペイロード」、「バイナリ画像」、または「CSVバッチ」など。これにより、受信側で必要な処理の複雑さについてエンジニアに情報を提供する。
8. メンテナンスと成長のためのベストプラクティス 📈
システムが成長するにつれて、図はごちゃごちゃになる可能性がある。複雑さの管理は継続的な作業である。視覚化を明確かつ有用な状態に保つための戦略を以下に示す。
- レイヤリング:異なる関心事に異なるレイヤーを使用する。セキュリティ用のレイヤー、データフロー用のレイヤー、デプロイメントトポロジー用のレイヤーをそれぞれ別々に設ける。これらをすべて1ページに描き込まないよう注意する。
- 詳細へのリンク:コンテナが複雑な場合は、別途サブ図を用意する。概要ページにすべてのコンポーネントを描くのではなく、メイン図を詳細ビューにリンクする。
- 色分け:色を使ってステータスや重要度を示す。重要なパスには赤、標準的なフローには青、非推奨の接続には灰色を使用する。これにより、システムの健全性を素早く視覚的に把握できる。
- メタデータ:図のバージョンと最終レビュー日を文書のフッターに含める。これにより、情報の最新性に関する文脈が提供される。
9. 監視性との統合 🔍
静的な図は静的である。実際のシステムは動的である。現代のアーキテクチャでは、図と監視プラットフォームが統合される。つまり、図は単なる画像ではなく、ライブインターフェースとなる。
データフローを可視化する際には、図が監視データとどのように関連しているかを検討する必要がある。監視ツールで特定の接続に高い遅延が見られる場合、図はその接続を明確に示すべきである。このリンクは根本原因分析を支援する。エンジニアは図上の線をクリックすることで、そのリンクの現在のメトリクスを確認できる。
この統合には、図形式が外部データソースへの埋め込みまたはリンクをサポートしている必要がある。メトリクスが変更されるたびに手動で更新しなくてもよい柔軟性を、選択した図作成手法が提供していることを確認する。
10. 主なポイントの要約 ✅
分散システムにおけるデータフローの可視化は、技術的正確性と可読性のバランスを取る分野である。C4モデルに従うことで、アーキテクチャに関する一貫した言語をチームが構築できる。コンテナレベルは、複雑さに圧倒されずサービス間の相互作用を理解するのに必要な詳細を提供する。
覚えておくべきポイント:
- 境界を明確に定義する:コンテナがデプロイメント単位と一致していることを確認する。
- パターンを明示的にマッピングする:同期的フローと非同期的フローを区別する。
- 整合性モデルを文書化する:境界を越えて状態がどのように管理されているかを示す。
- 厳密に維持する:図をコードとともに進化する生きている文書として扱う。
- 過度な期待を避ける: アーキテクチャを売り込むのではなく、明確さと正確さに注力してください。
これらの原則に従うことで、エンジニアリングチームは認知負荷を軽減し、新メンバーのオンボーディングを加速させ、分散型インフラの全体的な信頼性を向上させることができます。目的は単に線を引くことではなく、システムの仕組みについて共有された理解を構築することです。