











Dans l’ingénierie logicielle moderne, les systèmes existent rarement sous forme d’entités monolithiques. Ils sont composés de multiples services, processus et unités de stockage qui interagissent au-delà des frontières réseau. Comprendre comment les informations circulent entre ces unités distinctes est essentiel pour maintenir l’intégrité du système, diagnostiquer les défaillances et prévoir l’évolutivité. Ce guide explore le processus de cartographie et de visualisation du flux de données au sein des architectures distribuées, en utilisant spécifiquement le modèle C4 comme cadre structurel.
Sans documentation claire, les systèmes distribués deviennent rapidement des boîtes noires. Les ingénieurs peinent à suivre les requêtes, à identifier les goulets d’étranglement ou à comprendre l’impact des modifications. Visualiser le déplacement des données apporte de la clarté. Elle transforme la logique abstraite en diagrammes concrets que les parties prenantes peuvent interpréter. Ce document décrit les méthodologies pour définir des frontières, cartographier les connexions et maintenir ces diagrammes au fil du temps.
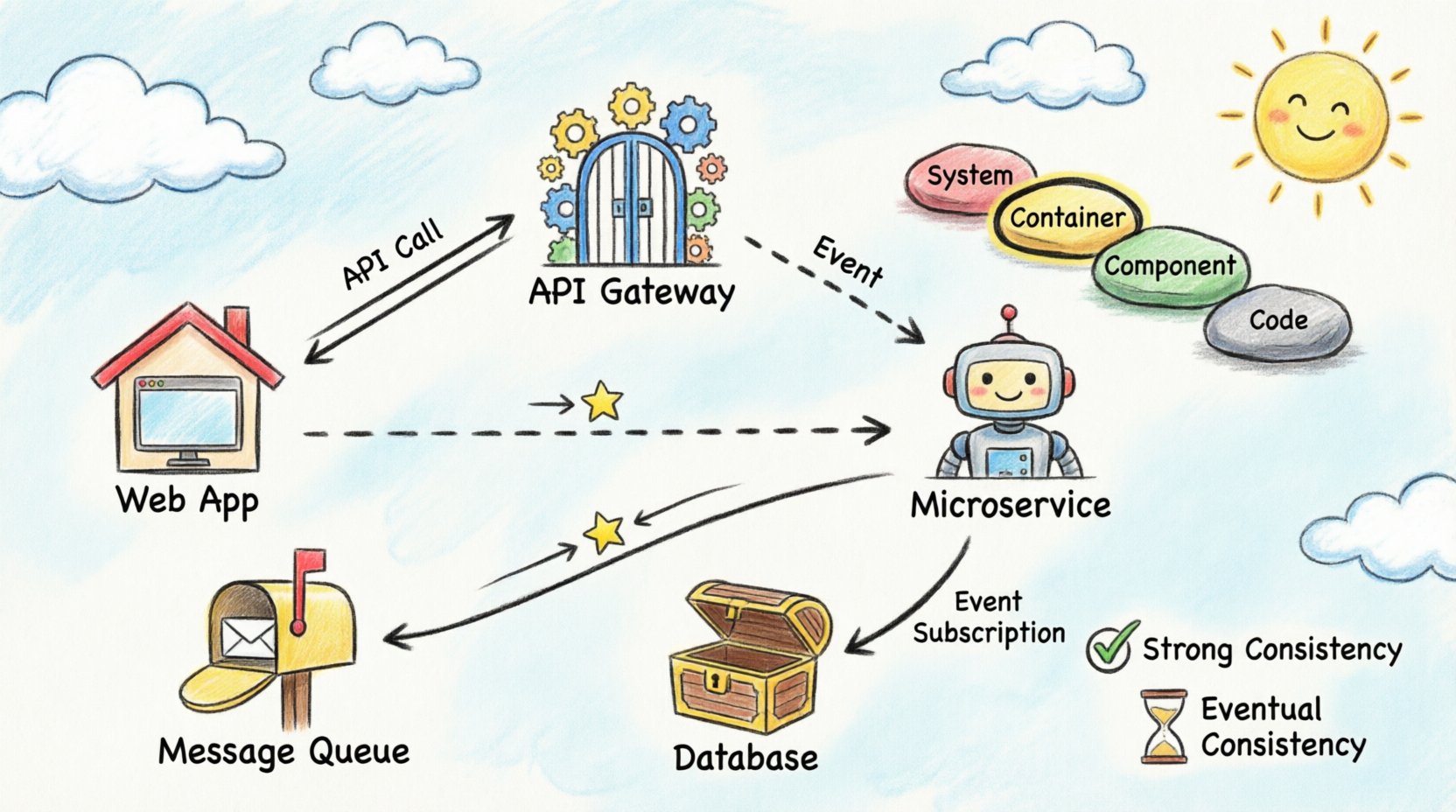
1. Le paysage architectural 🌍
Les systèmes distribués introduisent une complexité que les applications monolithiques n’ont pas à affronter. Lorsqu’un seul processus gère toute la logique, le flux de données est interne et linéaire. Lorsqu’il est question de plusieurs conteneurs ou services, les données traversent des réseaux, passent à travers des pare-feu et franchissent des frontières de confiance. Chaque saut introduit une latence et des points potentiels de défaillance.
Visualiser ce paysage nécessite une approche standardisée. Les diagrammes improvisés entraînent souvent une incohérence. Un ingénieur pourrait représenter une base de données sous forme de cylindre, tandis qu’un autre utilise une boîte. La standardisation garantit que, lorsqu’un diagramme est consulté, son sens est immédiatement compris. Le modèle C4 assure cette standardisation en définissant des niveaux spécifiques d’abstraction.
Les défis clés de la visualisation distribuée incluent :
- Latence réseau : Visualiser les endroits où les données attendent dans des files d’attente ou sur les réseaux.
- Consistance des données : Montrer comment l’état est synchronisé entre les nœuds.
- Domaines de défaillance : Identifier ce qui se produit si un conteneur cesse de répondre.
- Frontières de sécurité : Indiquer les endroits où le chiffrement des données ou l’authentification est requis.
2. Explication du modèle C4 📐
Le modèle C4 est une hiérarchie de diagrammes utilisée pour décrire l’architecture logicielle. Il se compose de quatre niveaux, chacun servant un public et un objectif différents. Pour la visualisation du flux de données à travers les conteneurs, les niveaux Conteneur et Composant sont les plus pertinents.
Niveau 1 : Contexte du système
Cette vue de haut niveau montre le système sous forme d’un bloc unique et ses interactions avec les utilisateurs et systèmes externes. Elle répond à la question : « Que fait ce système, et qui l’utilise ? » Bien qu’utile pour le contexte, elle ne montre pas le flux de données interne entre les conteneurs.
Niveau 2 : Conteneurs
C’est le cœur de la visualisation distribuée. Un conteneur représente une unité de déploiement distincte. Les exemples incluent les applications web, les applications mobiles, les microservices et les magasins de données. Ce niveau illustre comment les données circulent entre ces unités. C’est l’endroit idéal pour cartographier les appels d’API, les files de messages et les connexions directes à la base de données.
Niveau 3 : Composants
Dans un conteneur, les composants représentent des parties distinctes du logiciel. Ce niveau approfondit la logique, en montrant les interactions entre classes internes ou les dépendances entre modules. Bien qu’important, il est souvent trop détaillé pour une analyse de haut niveau du flux de données.
Niveau 4 : Code
Ce niveau correspond à des classes et méthodes spécifiques. Il est généralement inutile pour la documentation du flux architectural et convient mieux aux documents de référence spécifiques aux développeurs.
3. Identification des frontières des conteneurs 🚧
Avant de dessiner les lignes de flux de données, vous devez définir ce qui constitue un conteneur. Un conteneur est une unité déployable. Il possède un cycle de vie indépendant des autres conteneurs. Il peut fonctionner sur le même serveur physique ou être réparti sur différentes régions.
Les types courants de conteneurs incluent :
- Applications web :Interfaces frontend accessibles via les navigateurs.
- Microservices :Services backend gérant une logique métier spécifique.
- Passerelles API :Points d’entrée qui acheminent le trafic vers les services internes.
- Magasins de données :Bases de données, caches ou systèmes de fichiers.
- Traitements par lots :Travaux planifiés qui traitent les données de manière asynchrone.
Lors de la définition des limites, prenez en compte la stratégie de déploiement. Si deux services sont toujours déployés ensemble et partagent la mémoire, ils peuvent faire partie d’un seul conteneur. Si elles peuvent être mises à l’échelle indépendamment, elles doivent être des conteneurs séparés. Cette décision influence la manière dont le flux de données est visualisé.
4. Mappage des modèles de flux de données 📡
Le flux de données n’est pas simplement une ligne reliant deux boîtes. Il représente un modèle d’interaction spécifique. Comprendre ce modèle est crucial pour une visualisation précise. Le tableau suivant décrit les modèles courants et la manière dont ils doivent être représentés.
| Modèle | Direction | Visibilité | Cas d’utilisation |
|---|---|---|---|
| Demande/Réponse synchrone | Bidirectionnel (Client → Serveur → Client) | Immédiat | Appels d’API, soumissions de formulaires |
| Feu et oublie asynchrone | Unidirectionnel (Client → Serveur) | Différé | Journalisation, événements d’analyse |
| Traitement basé sur le pull | Unidirectionnel (Worker ← File d’attente) | À la demande | Travaux en arrière-plan, ingestion de données |
| Abonnement à un événement | Unidirectionnel (Émetteur → Abonné) | Déclenché par un événement | Notifications, modifications d’état |
Communication synchrone
Dans les flux synchrones, l’expéditeur attend une réponse. C’est courant dans les interactions API. Lors de la visualisation, utilisez des lignes pleines avec des flèches indiquant la requête et la réponse. Indiquez le protocole utilisé, tel que HTTP ou gRPC. Cela aide les ingénieurs à comprendre la nature bloquante de l’interaction.
Communication asynchrone
Les flux asynchrones déconnectent l’expéditeur du destinataire. L’expéditeur place un message dans une file d’attente et continue. Le destinataire traite le message ultérieurement. Visualisez cela à l’aide de lignes pointillées ou d’icônes distinctes pour représenter le broker de messages. Il est essentiel d’indiquer le nom de la file d’attente pour distinguer les différents flux de données.
5. Gestion de la synchronisation et de la cohérence ⚖️
L’un des aspects les plus difficiles du flux de données distribué est la gestion de l’état. Lorsqu’un données sont écrites dans un conteneur, celle-ci se reflète-elle immédiatement dans un autre ? La visualisation doit capturer ces exigences de cohérence.
Cohérence forte
Certains systèmes exigent que tous les nœuds voient les mêmes données au même moment. Cela implique souvent une seule source de vérité ou une réplication synchrone. Dans les diagrammes, marquez ces connexions avec des étiquettes indiquant « Cohérence forte » ou « ACID ». Cela alerte les parties prenantes que la panne dans une partie du système peut affecter les autres.
Cohérence éventuelle
De nombreux systèmes distribués privilégient la disponibilité plutôt que la cohérence immédiate. Les données peuvent prendre plusieurs secondes ou minutes pour se propager. Visualisez cela en ajoutant un indicateur de temps ou une étiquette « Sync » avec une notation de délai. Cela permet de gérer les attentes concernant le moment où les utilisateurs verront les informations mises à jour.
Conteneurs sans état vs. conteneurs avec état
Les conteneurs sans état ne stockent pas de données localement. Ils dépendent de bases de données externes ou de caches. Les conteneurs avec état conservent les données dans leur propre stockage. Lors du tracé du flux, assurez-vous que le stockage externe est clairement séparé du conteneur. Si un conteneur stocke des données, la ligne de flux doit pointer vers une icône de stockage située à l’intérieur ou attachée à ce conteneur.
6. Maintenance de la documentation 📝
Un diagramme n’est utile que s’il est précis. Au fil du temps, le code évolue, de nouveaux services sont ajoutés et des services obsolètes sont supprimés. Les diagrammes statiques deviennent rapidement obsolètes. Une stratégie de maintenance est nécessaire.
Les meilleures pratiques pour maintenir la documentation à jour incluent :
- Génération automatisée :Lorsque c’est possible, générez les diagrammes à partir des annotations de code ou des fichiers de configuration. Cela réduit les efforts manuels et évite le décalage entre le code et la documentation.
- Cycles de revue :Incluez les mises à jour des diagrammes dans la définition de « terminé » pour les demandes de fusion. Si l’interface d’un service change, le diagramme doit être mis à jour.
- Gestion de versions :Traitez les diagrammes d’architecture comme du code. Stockez-les dans des systèmes de gestion de versions pour suivre l’historique et permettre un retour en arrière si une modification est incorrecte.
- Normes d’outils :Utilisez une pile d’outils cohérente. Évitez de passer d’une plateforme de diagrammation à une autre selon les équipes.
7. Pièges courants à éviter 🛑
Même avec une approche structurée, des erreurs peuvent survenir au cours du processus de visualisation. Être conscient des erreurs courantes aide à maintenir une documentation de haute qualité.
Sur-abstraction
Il est tentant de simplifier les diagrammes trop. Si vous regroupez dix services dans une seule boîte étiquetée « Backend », vous perdez la capacité de suivre des chemins de données spécifiques. Maintenez le niveau de granularité du conteneur. Ne fusionnez pas des unités de déploiement distinctes sauf si elles partagent exactement le même cycle de vie.
Ignorer les chemins d’échec
La plupart des diagrammes montrent le chemin idéal où tout fonctionne. Une visualisation robuste indique également les modes d’échec. Où le flux va-t-il si un service expiré ? Y a-t-il un service de secours ? Y a-t-il une file de lettres mortes ? Ajouter ces chemins transforme le diagramme en outil de planification de résilience.
Nomenclature incohérente
Utilisez la même terminologie pour les services dans le diagramme que dans la base de code. Si un service est appelé « Order-Service » dans le code, ne le nommez pas « Orders API » dans le diagramme. Cela crée de la confusion lors des sessions de débogage.
Types de données manquants
Une ligne entre deux conteneurs vous indique *qu*’un déplacement de données a lieu, mais pas *quoi* exactement est déplacé. Il est utile d’annoter les lignes avec le type de charge utile des données. Par exemple, « Charge utile JSON », « Image binaire » ou « Lot CSV ». Cela informe les ingénieurs sur la complexité du traitement requis au niveau de la réception.
8. Meilleures pratiques pour la maintenance et la croissance 📈
Au fur et à mesure que le système grandit, le diagramme peut devenir encombré. Gérer la complexité est une tâche continue. Voici des stratégies pour garder la visualisation propre et utile.
- Empilement :Utilisez des couches différentes pour des préoccupations distinctes. Une couche pour la sécurité, une autre pour le flux de données, et une troisième pour la topologie de déploiement. Évitez de représenter tout cela sur une seule page.
- Liens vers les détails :Si un conteneur est complexe, créez un sous-diagramme distinct pour lui. Liez le diagramme principal à la vue détaillée plutôt que de dessiner chaque composant sur la page de vue d’ensemble.
- Codage par couleur :Utilisez la couleur pour indiquer l’état ou la criticité. Rouge pour les chemins critiques, bleu pour les flux standards, et gris pour les connexions obsolètes. Cela permet un balayage visuel rapide de l’état du système.
- Métadonnées :Incluez la version du diagramme et la date de la dernière révision dans le pied de page du document. Cela fournit un contexte sur la mise à jour de l’information.
9. Intégration avec l’observabilité 🔍
Les diagrammes statiques sont statiques. Les systèmes réels sont dynamiques. Les architectures modernes intègrent les diagrammes avec des plateformes d’observabilité. Cela signifie que le diagramme n’est pas seulement une image, mais une interface en temps réel.
Lors de la visualisation du flux de données, considérez comment le diagramme est lié aux données de surveillance. Si vous observez une latence élevée sur une connexion spécifique dans l’outil de surveillance, le diagramme doit clairement afficher cette connexion. Ce lien aide à l’analyse des causes racines. Les ingénieurs peuvent cliquer sur une ligne du diagramme pour voir les métriques actuelles de ce lien.
Cette intégration nécessite que le format du diagramme permette l’incorporation ou le lien avec des sources de données externes. Assurez-vous que la méthode choisie pour la création de diagrammes permet cette flexibilité sans nécessiter de mises à jour manuelles à chaque changement de métrique.
10. Résumé des points clés à retenir ✅
Visualiser le flux de données dans les systèmes distribués est une discipline qui équilibre la précision technique et la lisibilité. En suivant le modèle C4, les équipes peuvent créer un langage cohérent pour l’architecture. Le niveau des conteneurs fournit les détails nécessaires pour comprendre les interactions entre services sans surcharger la complexité.
Points clés à retenir :
- Définissez clairement les frontières :Assurez-vous que les conteneurs s’alignent avec les unités de déploiement.
- Mettez en évidence les modèles :Différenciez les flux synchrones et asynchrones.
- Documentez les modèles de cohérence :Indiquez comment l’état est géré à travers les frontières.
- Maintenez rigoureusement :Traitez les diagrammes comme des documents vivants qui évoluent avec le code.
- Évitez la surenchère : Concentrez-vous sur la clarté et l’exactitude plutôt que sur la vente de l’architecture.
En suivant ces principes, les équipes d’ingénierie peuvent réduire la charge cognitive, accélérer l’intégration des nouveaux membres et améliorer la fiabilité globale de leur infrastructure distribuée. L’objectif n’est pas seulement de tracer des lignes, mais de construire une compréhension partagée de la manière dont le système fonctionne.