











В современной инженерии программного обеспечения системы редко существуют как монолитные единицы. Они состоят из нескольких служб, процессов и единиц хранения данных, взаимодействующих через границы сетей. Понимание того, как информация перемещается между этими различными единицами, критически важно для поддержания целостности системы, диагностики сбоев и планирования масштабируемости. Данное руководство рассматривает процесс картографирования и визуализации потока данных в распределённых архитектурах, используя модель C4 в качестве структурной основы.
Без чёткой документации распределённые системы быстро превращаются в чёрные ящики. Инженеры сталкиваются с трудностями при отслеживании запросов, выявлении узких мест или понимании последствий изменений. Визуализация перемещения данных обеспечивает ясность. Она превращает абстрактную логику в конкретные диаграммы, которые могут интерпретировать заинтересованные стороны. В этом документе описываются методологии определения границ, картографирования соединений и поддержания этих диаграмм на протяжении времени.
1. Ландшафт архитектуры 🌍
Распределённые системы вводят сложность, с которой не сталкиваются монолитные приложения. Когда один процесс обрабатывает всю логику, поток данных внутренний и линейный. Когда задействованы несколько контейнеров или служб, данные проходят через сети, проходят через брандмауэры и пересекают границы доверия. Каждый переход вносит задержку и потенциальные точки отказа.
Визуализация этой среды требует стандартизированного подхода. Случайные диаграммы часто приводят к несогласованности. Один инженер может изобразить базу данных в виде цилиндра, другой — в виде прямоугольника. Стандартизация обеспечивает, что при просмотре диаграммы её смысл становится сразу понятным. Модель C4 обеспечивает стандартизацию, определяя конкретные уровни абстракции.
Ключевые вызовы при визуализации распределённых систем включают:
- Задержки в сети:Визуализация мест, где данные ожидают в очередях или сетях.
- Согласованность данных:Показывает, как состояние синхронизируется между узлами.
- Области отказов:Определение того, что происходит, если один контейнер перестаёт отвечать.
- Границы безопасности:Отметка мест, где требуется шифрование данных или аутентификация.
2. Объяснение модели C4 📐
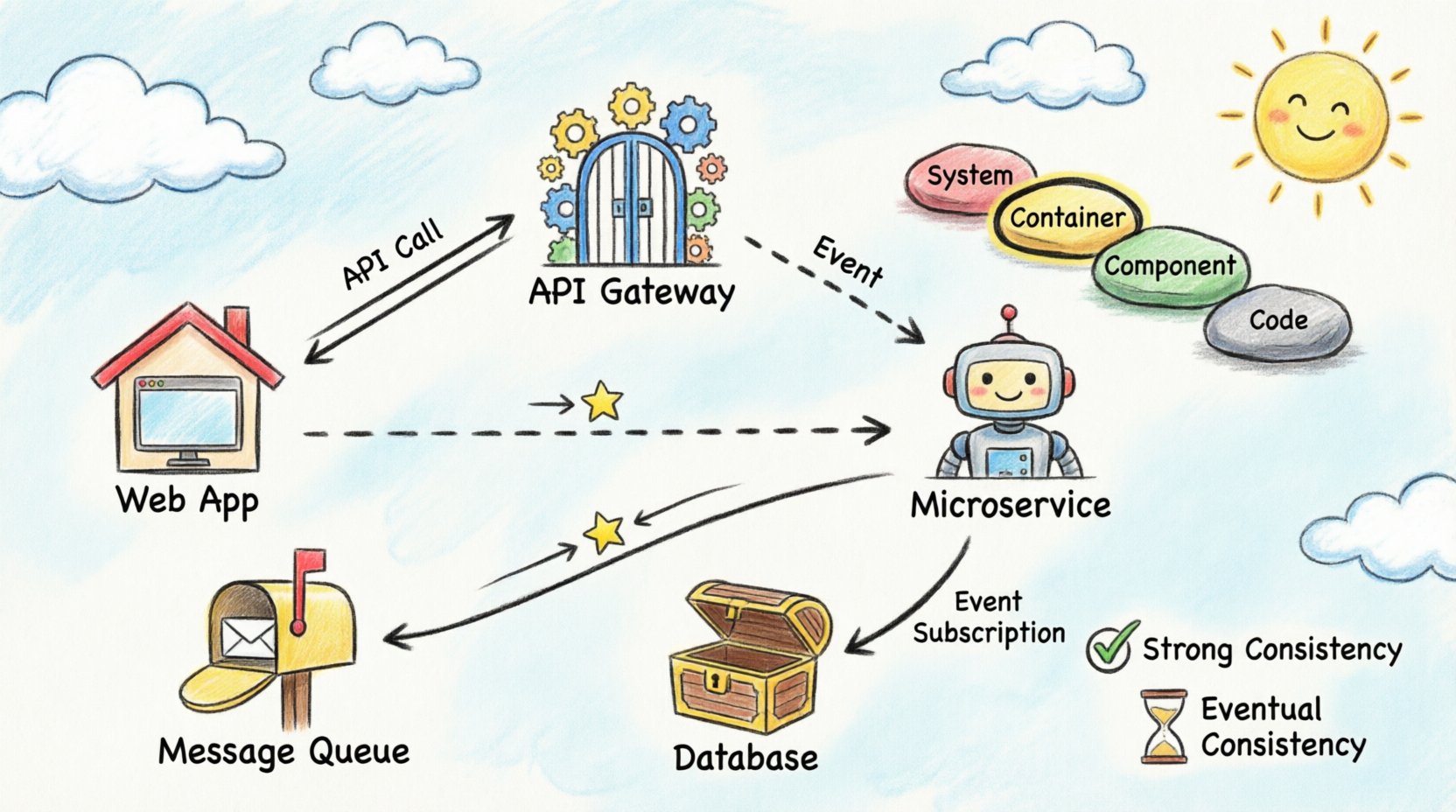
Модель C4 — это иерархия диаграмм, используемых для описания архитектуры программного обеспечения. Она состоит из четырёх уровней, каждый из которых предназначен для разных аудиторий и целей. Для визуализации потока данных между контейнерами наиболее релевантны уровни «Контейнеры» и «Компоненты».
Уровень 1: Контекст системы
На этом высоком уровне показывается система как единый блок и её взаимодействие с внешними пользователями и системами. Отвечает на вопрос: «Что делает эта система и кто её использует?» Хотя это полезно для контекста, на этом уровне не показывается внутренний поток данных между контейнерами.
Уровень 2: Контейнеры
Это основа визуализации распределённых систем. Контейнер представляет собой отдельную единицу развертывания. Примеры включают веб-приложения, мобильные приложения, микросервисы и хранилища данных. На этом уровне показывается, как данные перемещаются между этими единицами. Это идеальное место для отображения вызовов API, очередей сообщений и прямых соединений с базами данных.
Уровень 3: Компоненты
Внутри контейнера компоненты представляют собой отдельные части программного обеспечения. На этом уровне углубляются в логику, показывая взаимодействие внутренних классов или зависимости модулей. Хотя это важно, на этом уровне часто слишком много деталей для анализа потока данных на высоком уровне.
Уровень 4: Код
На этом уровне отображаются конкретные классы и методы. Обычно это не требуется для документирования архитектурного потока и лучше подходит для материалов, ориентированных на разработчиков.
3. Определение границ контейнеров 🚧
Прежде чем рисовать линии потока данных, необходимо определить, что составляет контейнер. Контейнер — это развертываемая единица. У него есть независимый жизненный цикл по отношению к другим контейнерам. Он может работать на одном физическом сервере или распределяться по разным регионам.
Распространённые типы контейнеров включают:
- Веб-приложения:Интерфейсы фронтенда, доступные через браузеры.
- Микросервисы: Сервисы бэкенда, обрабатывающие конкретную бизнес-логику.
- Шлюзы API: Точки входа, перенаправляющие трафик на внутренние сервисы.
- Хранилища данных: Базы данных, кэши или файловые системы.
- Пакетные процессы: Планируемые задания, обрабатывающие данные асинхронно.
При определении границ учитывайте стратегию развертывания. Если два сервиса всегда развертываются вместе и используют общую память, они могут быть частью одного контейнера. Если они могут масштабироваться независимо, они должны быть отдельными контейнерами. Это решение влияет на то, как визуализируется поток данных.
4. Отображение паттернов потока данных 📡
Поток данных — это не просто линия, соединяющая два блока. Он представляет собой конкретный паттерн взаимодействия. Понимание паттерна критически важно для точной визуализации. В следующей таблице перечислены распространённые паттерны и способы их отображения.
| Паттерн | Направление | Видимость | Сценарий использования |
|---|---|---|---|
| Синхронный запрос/ответ | Двусторонний (Клиент → Сервер → Клиент) | Немедленная | Вызовы API, отправка форм |
| Асинхронный режим «отправить и забыть» | Односторонний (Клиент → Сервер) | Отложенная | Журналирование, события аналитики |
| Обработка по запросу | Односторонний (Рабочий ← Очередь) | По требованию | Фоновые задания, приём данных |
| Подписка на события | Односторонний (Опубликовавший → Подписчик) | Событийный триггер | Уведомления, изменения состояния |
Синхронная коммуникация
В синхронных потоках отправитель ожидает ответа. Это распространено при взаимодействии с API. При визуализации используйте сплошные линии со стрелками, указывающими на запрос и ответ. Укажите используемый протокол, например HTTP или gRPC. Это помогает инженерам понять блокирующий характер взаимодействия.
Асинхронная коммуникация
Асинхронные потоки разделяют отправителя и получателя. Отправитель помещает сообщение в очередь и продолжает работу. Получатель обрабатывает сообщение позже. Визуализируйте это с помощью штриховых линий или отдельных иконок, представляющих брокер сообщений. Крайне важно указать имя очереди, чтобы различать разные потоки данных.
5. Обработка синхронизации и согласованности ⚖️
Одной из самых сложных задач при распределённом потоке данных является управление состоянием. Когда данные записываются в один контейнер, немедленно ли они отражаются в другом? Визуализация должна отражать эти требования к согласованности.
Сильная согласованность
Некоторые системы требуют, чтобы все узлы видели одни и те же данные в одно и то же время. Это часто означает наличие единого источника истины или синхронной репликации. На диаграммах помечайте такие соединения метками «Сильная согласованность» или «ACID». Это информирует заинтересованные стороны о том, что простои в одной части системы могут повлиять на другие.
Потенциальная согласованность
Многие распределённые системы ставят доступность выше немедленной согласованности. Данные могут занять несколько секунд или минут для распространения. Визуализируйте это, добавив индикатор времени или метку «Синхронизация» с обозначением задержки. Это помогает управлять ожиданиями пользователей относительно того, когда они увидят обновлённую информацию.
Безсостоятельные и состоятельные контейнеры
Безсостоятельные контейнеры не хранят данные локально. Они полагаются на внешние базы данных или кэши. Состоятельные контейнеры хранят данные в собственном хранилище. При построении потока убедитесь, что внешнее хранилище чётко отделено от контейнера. Если контейнер хранит данные, линия потока должна указывать на иконку хранилища внутри или прикреплённую к этому контейнеру.
6. Поддержка документации 📝
Диаграмма полезна только в том случае, если она точна. Со временем код изменяется, добавляются новые службы, а устаревшие удаляются. Статические диаграммы быстро устаревают. Необходима стратегия поддержки.
Наилучшие практики поддержания актуальности документации включают:
- Автоматическая генерация:Там, где это возможно, генерируйте диаграммы из аннотаций кода или файлов конфигурации. Это снижает ручные усилия и предотвращает расхождение между кодом и документацией.
- Циклы обзора:Включайте обновления диаграмм в определение «готово» для запросов на слияние. Если изменяется интерфейс службы, диаграмма также должна быть изменена.
- Версионирование:Рассматривайте архитектурные диаграммы как код. Храните их в системах контроля версий для отслеживания истории и возможности отката, если изменение оказалось неверным.
- Стандарты инструментов:Используйте единый набор инструментов. Избегайте смены различных платформ для создания диаграмм между разными командами.
7. Распространённые ошибки, которые следует избегать 🛑
Даже при структурированном подходе ошибки могут возникать в процессе визуализации. Осознание распространённых ошибок помогает поддерживать высокое качество документации.
Чрезмерная абстракция
Очень соблазнительно чрезмерно упрощать диаграммы. Если вы объедините десять служб в одну коробку с надписью «Бэкенд», вы потеряете возможность отслеживать конкретные пути передачи данных. Сохраняйте детализацию на уровне контейнера. Не объединяйте отдельные единицы развертывания, если они не имеют идентичного жизненного цикла.
Пренебрежение путями отказа
Большинство диаграмм показывают путь «счастливого» сценария, когда всё работает. Надёжная визуализация также указывает на режимы отказа. Куда направляется поток, если служба превышает время ожидания? Есть ли резервная служба? Есть ли очередь для необработанных сообщений? Добавление этих путей превращает диаграмму в инструмент планирования отказоустойчивости.
Несогласованное наименование
Используйте одинаковую терминологию для сервисов на диаграмме, как в кодовой базе. Если сервис называется «Order-Service» в коде, не называйте его «Orders API» на диаграмме. Это вызывает путаницу во время сеансов отладки.
Отсутствующие типы данных
Линия между двумя контейнерами говорит вам *о том, что* данные перемещаются, но не *о том, какие* данные перемещаются. Полезно аннотировать линии типом передаваемых данных. Например, «JSON-данные», «Бинарное изображение» или «Пакет CSV». Это информирует инженеров о сложности обработки, необходимой на принимающем конце.
8. Лучшие практики для поддержки и роста 📈
По мере роста системы диаграмма может стать перегруженной. Управление сложностью — это постоянная задача. Вот стратегии, которые помогут сохранить визуализацию чистой и полезной.
- Слоистость: Используйте разные слои для разных аспектов. Один слой для безопасности, другой — для потока данных, третий — для развертывания. Избегайте отображения всего этого на одной странице.
- Ссылки на детали: Если контейнер сложный, создайте отдельную поддиаграмму для него. Ссылайтесь на подробный вид из основной диаграммы, а не рисуйте каждый компонент на странице обзора.
- Цветовая кодировка: Используйте цвет для обозначения статуса или критичности. Красный — для критических путей, синий — для стандартных потоков, серый — для устаревших соединений. Это позволяет быстро визуально оценить состояние системы.
- Метаданные: Включите версию диаграммы и дату последнего обзора в подвал документа. Это дает контекст относительно актуальности информации.
9. Интеграция с системами наблюдения 🔍
Статические диаграммы — статичны. Реальные системы динамичны. Современные архитектуры интегрируют диаграммы с платформами наблюдения. Это означает, что диаграмма — не просто изображение, а живой интерфейс.
При визуализации потока данных учитывайте, как диаграмма связана с данными мониторинга. Если в инструменте мониторинга вы видите высокую задержку на конкретном соединении, диаграмма должна четко показывать это соединение. Такая связь помогает в анализе причин. Инженеры могут нажать на линию на диаграмме и увидеть текущие метрики для этого соединения.
Такая интеграция требует, чтобы формат диаграммы поддерживал встраивание или ссылки на внешние источники данных. Убедитесь, что выбранный метод создания диаграмм обеспечивает такую гибкость без необходимости ручного обновления при каждом изменении метрики.
10. Краткое резюме ключевых выводов ✅
Визуализация потока данных в распределенных системах — это дисциплина, которая балансирует техническую точность и читаемость. Следуя модели C4, команды могут создать единый язык архитектуры. Уровень контейнеров предоставляет необходимую детализацию для понимания взаимодействия сервисов без излишней сложности.
Ключевые моменты, которые следует помнить:
- Четко определяйте границы: Убедитесь, что контейнеры соответствуют единицам развертывания.
- Явно отображайте паттерны: Различайте синхронные и асинхронные потоки.
- Документируйте модели согласованности: Укажите, как состояние управляется через границы.
- Строго поддерживайте: Рассматривайте диаграммы как живые документы, которые развиваются вместе с кодом.
- Избегайте излишнего энтузиазма: Сосредоточьтесь на ясности и точности, а не на продаже архитектуры.
Следуя этим принципам, инженерные команды могут снизить когнитивную нагрузку, ускорить адаптацию новых членов команды и улучшить общую надежность своей распределенной инфраструктуры. Цель заключается не просто в проведении линий, а в формировании общего понимания того, как работает система.