











堅牢なデータアーキテクチャを設計するには、対立する優先事項のバランスを取る必要がある。整合性、パフォーマンス、保守性はしばしば異なる方向に引っ張られる。システムの焦点が読み込みが重い操作に移行すると、従来のスキーマ設計のルールは大きなストレスにさらされる。エンティティ関係図(ERD)は単なる静的な設計図を超えて、アプリケーションロジックとストレージエンジン間の契約として機能する。このガイドでは、高頻度の読み込みワークロードという文脈において、正規化と非正規化のアプローチの戦略的差異を検討する。
正規化するか非正規化するかという決定は二値ではない。データの重複のコストとデータ取得のコストを理解することが必要である。読み込み操作がトランザクションログの主な構成を占める環境では、結合の複雑さを最小限に抑えることがしばしば最優先の最適化目標となる。しかし、冗長性を導入すると、データの一貫性と書き込み操作に対する新たな課題が生じる。適切な構造戦略を選択するためには、こうしたトレードオフを分析しなければならない。
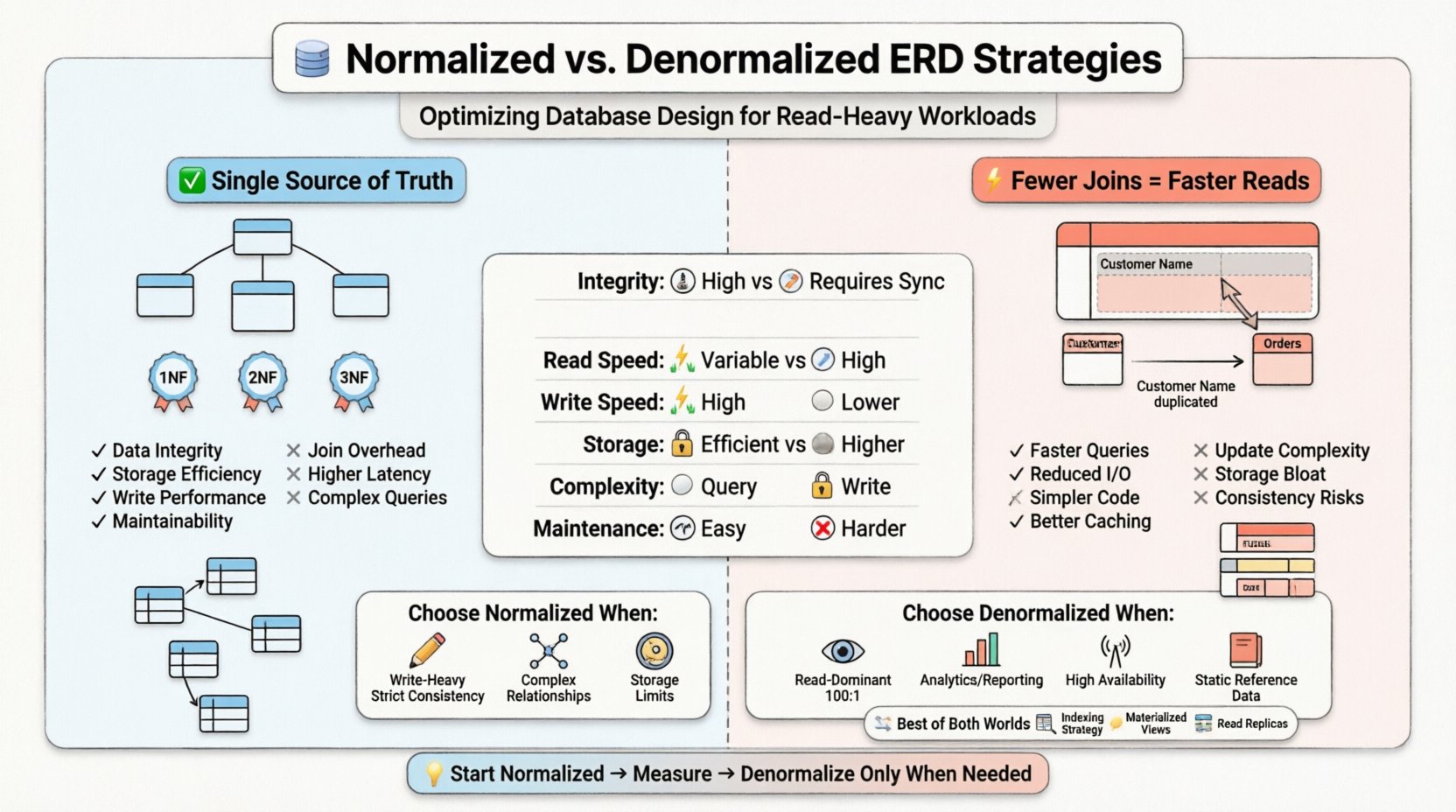
🏗️ ERD設計における正規化の理解
正規化は、データの重複を減らし、データの整合性を向上させるために用いられる体系的なプロセスである。関係データベース内の属性とテーブルを整理することで、挿入、更新、削除操作中の異常を最小限に抑える。目的は、各データが正確に1か所にのみ格納されることを保証することである。
正規化の基本原則
エンティティ関係図を構築する際、アーキテクトたちは通常、正規形と呼ばれるルールの階層に従う。各正規形は特定の種類の重複に対処する。
- 第一正規形(1NF):各列が原子値を含み、繰り返しグループが存在しないことを保証する。これにより、行にフラットな構造が確立される。
- 第二正規形(2NF):1NFを基盤として、部分的依存を排除する。属性は、主キーの一部ではなく、全体に依存しなければならない。
- 第三正規形(3NF):推移的依存を排除する。非キー属性は、他の非キー属性ではなく、主キーにのみ依存しなければならない。
非常に正規化されたERDでは、テーブルは細分化される。顧客テーブルは住所テーブルとは別に存在し、外部キーによってリンクされる。注文テーブルは顧客を参照し、注文アイテムテーブルは注文を参照する。この構造により、顧客が引っ越しをした場合、更新が1か所で行われ、自動的に伝播されることが保証される。
正規化スキーマの利点
- データ整合性:単一の真実の情報源により、矛盾する情報のリスクが低下する。
- ストレージ効率:冗長データが少ないことで、データベースのサイズが小さくなる。
- 書き込みパフォーマンス:挿入、更新、削除操作は、複数のテーブルにまたがる行を触る必要が少ないため、一般的に高速になる。
- 保守性:データ構造への変更は局所的になる。特定のエンティティに新しい属性を追加しても、関係のないテーブルに連鎖的な変更を加える必要がない。
読み込みが重いシステムにおける欠点
正規化は書き込みが重い環境や混合環境では優れた性能を発揮するが、読み込み操作には摩擦をもたらす。完全なレコードを構成するために必要な各結合は、ディスクまたはメモリキャッシュ上の物理的操作を意味する。読み込みが重いワークロードでは、1つのダッシュボードビューをレンダリングするために、システムが5つまたは6つの異なるテーブルからデータを取得する必要がある場合がある。
- 結合のオーバーヘッド:クエリプロセッサはテーブル間でキーを一致させる必要がある。これによりCPUサイクルとメモリ帯域幅が消費される。
- I/O操作:テーブルが大きい場合、ストレージエンジンは関連データを取得するために複数回のシークを実行しなければならない。
- 遅延: 複数の参照処理の累積時間が、エンドユーザーの応答時間を長くする。
🔗 デノーマライゼーションのアプローチ
デノーマライゼーションとは、データベース設計に意図的に冗長性を導入する手法である。その目的は、必要な結合の数を減らすことによって、読み取り性能を最適化することである。エンティティ関係図では、他のテーブルからのデータを複製するカラム、または関連情報を統合した広いテーブルとして現れる。
デノーマライゼーションの仕組み
顧客名を参照するために外部キーを保存する代わりに、デノーマライズされた注文テーブルは顧客名を直接保存する場合がある。顧客の名前が変更された場合、注文記録を更新またはフラグを立てる必要がある、あるいはシステムは注文が購入時時点の名前を反映していることを受け入れる。
この戦略は、複雑性を読み取りパスから書き込みパスに移す。システムは今後、冗長なデータコピーの更新ロジックを処理しなければならない。
読み取りが主なワークロードにおける利点
- クエリ実行の高速化: 結合の数が減るため、計算オーバーヘッドが少なくなる。
- I/Oの削減: 複数の参照ではなく、単一のテーブルスキャンでより多くのデータを取得できる。
- クエリの簡素化: アプリケーションコードが結果を組み立てるために必要なロジックが少なくなる。
- キャッシュ効率: より平坦な構造は、メモリ上で効果的にキャッシュしやすいことが多い。
リスクと欠点
デノーマライゼーションの主なコストはデータの一貫性である。元データが変更された場合、すべての冗長コピーを同時に更新しなければならない。これを怠ると、古くなったデータ(スタレートデータ)が発生する。
- 更新異常: 顧客名の更新には、その顧客を参照するすべての注文記録を検索し、変更する必要がある。
- ストレージの肥大化: データの複製により、データベース全体のサイズが増加する。
- 書き込みの複雑さ: 書き込みトランザクションがより複雑になり、多くのロックや長時間のトランザクションを要する場合がある。
- スキーマの硬直性: 新しいフィールドを追加するには、1つのテーブルではなく複数のテーブルを更新する必要がある場合がある。
📈 読み取りが主なワークロードの特徴を分析する
適切な戦略を選ぶためには、ワークロードの具体的な性質を理解する必要がある。読み取りが主なシステムは、書き込みが頻繁で重要なトランザクション系システムと大きく異なる。
クエリパターン
アプリケーションは複雑な分析クエリを実行するか、単純な参照を行うか?多数のテーブルにわたる集計を含む複雑なクエリは、デノーマライゼーションによって恩恵を受ける。IDによる単純な参照は、インデックスが適切にチューニングされていれば、正規化でも十分な性能を発揮できる。
- ポイントクエリ: ID による単一レコードの取得。
- 範囲クエリ: 日付範囲内のレコードのセットを取得する。
- 集計: 大規模なデータセット全体での合計、平均、またはカウントの計算。
ラテントシ要求
高頻度取引プラットフォームやリアルタイムダッシュボードは、複雑な結合によって引き起こされる遅延を負担できない。これらの状況では、正規化の解除は選択ではなく、しばしば必須となる。逆に、アプリケーションが数百ミリ秒の遅延を許容できる場合、適切なインデックスを使用すれば正規化で十分になる可能性がある。
データ一貫性の許容度
即時一貫性が必要か? システムが最終的一貫性を許容できる場合、正規化の解除ははるかに安全になる。読み取りレプリカや非同期更新メカニズムは、書き込み操作をブロックせずに冗長データの同期を処理できる。
📋 戦略的比較表
以下の表は、データベース設計の文脈における2つのアプローチの主な違いを要約している。
| 機能 | 正規化スキーマ | 非正規化スキーマ |
|---|---|---|
| データ整合性 | 高い(唯一の真実のソース) | 低い(同期ロジックが必要) |
| 読み取りパフォーマンス | 変動する(結合に依存) | 高い(結合が少ない) |
| 書き込みパフォーマンス | 高い(冗長性が最小限) | 低い(複数行の更新) |
| ストレージ使用量 | 効率的 | 高い(冗長データ) |
| 複雑さ | 高いクエリの複雑さ | 高い書き込みの複雑さ |
| 保守性 | スキーマの変更が容易 | スキーマの変更が難しい |
🧭 アーキテクト向け意思決定フレームワーク
適切な道を選ぶには、ビジネス要件を技術的制約と照らし合わせて評価する必要があります。以下のフレームワークが意思決定プロセスをガイドするのに役立ちます。
正規化を選択するタイミング
- 書き込みの頻度: 読み込みに対して書き込み操作が頻繁に発生する場合、正規化により更新異常を防ぐことができます。
- 厳格な整合性: 金融システムや医療記録は、冗長性が許されないため、厳格なACID準拠を要求することが多いです。
- 複雑な関係性: エンティティ間に頻繁に変化する多対多の関係がある場合、正規化はマッピングを明確に処理できます。
- ストレージ制約: ディスク容量が貴重な場合、冗長性を最小限に抑えることは有益です。
非正規化を選択するタイミング
- 読み込み優位: 読み込みが書き込みよりも大幅に多い場合(例:100:1)、結合の回数を減らすことで得られるパフォーマンス向上は、書き込みコストを上回ります。
- レポート作成および分析: データウェアハウスやレポートエンジンは、集計クエリの高速化のためにしばしば非正規化を行います。
- 高可用性: 分散システムは、他のパーティションへのネットワーク遷移なしにローカルノードで読み取りを可能にするためにデータを非正規化することがあります。
- 静的参照データ: 経時的にほとんど変化しないデータ(例:国コード、為替レート)は、コピーの対象として非常に適しています。
🛠️ ハイブリッドアプローチと最適化
一方の極端を他方よりも選ぶ必要はほとんどありません。現代のシステムは、両モデルの利点をバランスさせるためにハイブリッド戦略を採用することが多いです。
インデックス戦略
非正規化を行う前に、正規化されたスキーマが完全にインデックス化されていることを確認してください。カバーインデックスを使用すると、ストレージエンジンがインデックス自体から必要なすべてのデータを取得でき、テーブル参照を回避できます。これにより、データの冗長性を伴わずに、ほぼ非正規化された読み取り速度を達成できる場合があります。
- 複合インデックス: 範囲スキャンを高速化するために、最も選択性の高いフィールド順に列を並べてください。
- 部分インデックス: 特定のデータサブセットのみにインデックスを構築することで、インデックスのサイズとメンテナンスコストを削減できます。
マテリアライズドビュー
マテリアライズドビューは、クエリの結果を物理的に格納するデータベースオブジェクトです。基底テーブルを変更せずに、データの非正規化されたビューを維持できるようにします。基になるデータが変更された場合、マテリアライズドビューは更新(リフレッシュ)できます。
- 事前計算:複雑な集計処理は事前に計算される。
- 更新サイクル:スケジュールに基づいて実行するか、データの変更をトリガーとして実行できる。
- 読み取り分離:クエリはマテリアライズドビューにアクセスする一方、書き込みは基底テーブルに送られる。
読み取りレプリカ
分散アーキテクチャでは、読み取りレプリカを非正規化されたデータのコピーをホストするように設定できる。プライマリーノードは書き込みを処理し、正規化されたスキーマを維持する。レプリカは非同期で更新を受け取り、最適化されたスキーマで読み取りトラフィックを処理する。
- 読み取りのスケーリング:複数のノードに負荷を分散する。
- 地理的近接:データをユーザーに近い場所に配置する。
- 最終的整合性:データの伝播にわずかな遅延を受け入れる。
⚠️ スキーマ設計における一般的な落とし穴
明確な戦略があっても、実装上の誤りがパフォーマンスを損なうことがある。アーキテクトは一般的なミスに対して常に注意を払わなければならない。
過剰な正規化
単一の概念に対してあまりにも多くのテーブルを作成すると、結合が過剰になる。3NFは標準であるが、読み取りが重いシステムでこれを盲目的に守るとパフォーマンスが低下する。場合によっては、3NFの制御された違反が必要になる。
不整合な非正規化
アプリケーションの一部だけを非正規化し、他の部分は正規化したままにすると、断片化されたシステムが生じる。不整合性により、開発者がパフォーマンス特性を予測しにくくなる。
データ量を無視する
小さなデータセットで動作するスキーマでも、データ量が増大すると失敗する可能性がある。非正規化はレコード数に比例してストレージ要件を増加させる。データが指数関数的に増加する場合、冗長性のストレージコストと保守負荷は管理不能になる。
更新ロジックの複雑さ
冗長なデータを同期させるロジックを実装することは容易ではない。通常、トリガー、アプリケーションレベルのトランザクション、またはメッセージキューが必要となる。このロジックが失敗すると、データの破損が静かに発生する。
🔍 実装上の考慮事項
設計から実装へ移行する際には、成功を確保するために特定の技術的詳細を検討しなければならない。
トランザクション管理
非正規化された更新はしばしば複数の行にわたる。これを原子性を保つために1つのトランザクションでラップしなければならない。システムが途中でクラッシュした場合、データはロールバックされ、整合性の損なわれた状態を避ける必要がある。
キャッシュレイヤー
正規化されていなくても、メモリに頻繁にアクセスされるデータをキャッシュすることで、データベースの負荷をさらに軽減できます。基盤となるデータが変更された場合は、キャッシュを無効化または更新する必要があります。
モニタリングとメトリクス
継続的なモニタリングは不可欠です。クエリ実行時間、ロック競合、ストレージの増加を追跡してください。書き込み遅延が急上昇した場合は、正規化解除の更新ロジックが重すぎることを示している可能性があります。
📝 アーキテクトのための最終的な考慮事項
正規化されたERD戦略と非正規化されたERD戦略の選択は、根本的なアーキテクチャ上の意思決定です。これはデータがシステム内をどのように流れ、ストレージエンジンがアプリケーションとどのように相互作用するかを規定します。すべてのシナリオに適用できる唯一の正解は存在しません。
- まずは測定を:仮定に基づいて最適化しないでください。現在のワークロードをプロファイリングして、ボトルネックを特定してください。
- シンプルから始める:正規化された設計から始めましょう。パフォーマンスメトリクスがニーズを示す場合にのみ、非正規化を行います。
- 意思決定を文書化する:冗長性が導入された理由を明確に記録してください。将来の保守担当者がトレードオフを理解できるようにする必要があります。
- 進化を計画する:スキーマ設計は進化しなければなりません。今日機能する戦略も、データパターンの変化に伴って調整が必要になる可能性があります。
結合のメカニズム、冗長性のコスト、読み込み中心のワークロードの特定の要求を理解することで、アーキテクトは堅牢かつパフォーマンスの高いシステムを設計できます。目的は厳格なルールに従うことではなく、特定のデータ環境に最も適したツールを適用することです。