











La modelización de datos es la columna vertebral de cualquier arquitectura de bases de datos sólida. Aunque la teoría se enseña con frecuencia en cursos universitarios, su aplicación práctica en entornos de producción revela un panorama plagado de casos extremos, cuellos de botella de rendimiento y ambigüedades lógicas. Los diagramas de relaciones de entidades (ERD) sirven como planos para estos sistemas, pero a menudo se convierten en fuentes de controversia cuando el mundo real se niega a encajar convenientemente en cuadros y líneas.
Nos reunimos con un panel de administradores principales de bases de datos y arquitectos de datos para analizar los escenarios que constantemente confunden a los equipos durante la fase de diseño. Estos no son ejercicios teóricos; son problemas que surgen cuando los requisitos del negocio entran en conflicto con las limitaciones físicas de almacenamiento. El objetivo aquí no es ofrecer una solución rápida, sino proporcionar una comprensión profunda de los compromisos involucrados.
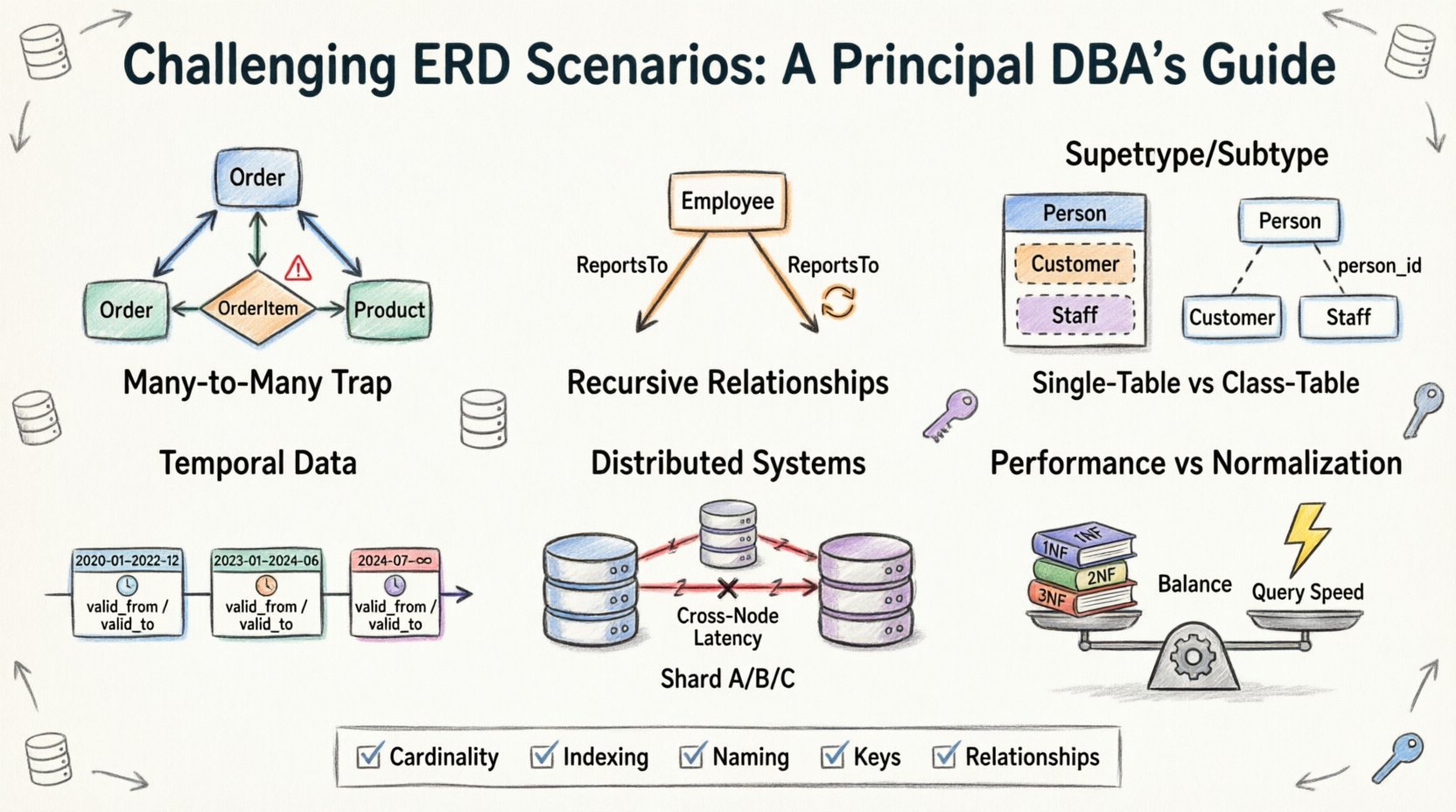
1. La trampa de muchos a muchos: más allá de las tablas de unión simples 🕸️
El punto de partida más común en el diseño de ERD es la relación muchos a muchos. Parece intuitivo: un estudiante puede inscribirse en muchos cursos, y un curso puede tener muchos estudiantes. La solución estándar implica una tabla puente o asociativa. Sin embargo, la complejidad surge cuando se introducen atributos dentro de la propia relación.
- El problema:Con frecuencia, los equipos intentan almacenar datos de inscripción (como calificaciones o fechas de registro) en la tabla principal de Estudiantes o Cursos, lo que genera una redundancia masiva o valores nulos.
- La realidad:La propia relación es una entidad. Debe tener su propia clave primaria y claves foráneas que apunten de vuelta a sus padres.
- El desafío:Gestión de eliminaciones en cascada. Si se elimina un curso, ¿qué sucede con los registros de inscripción? Si se elimina una inscripción, ¿desaparece el estudiante? Estas decisiones definen la integridad de los datos.
Durante nuestra discusión, uno de los DBAs principales señaló que la tabla asociativa a menudo se convierte en un cuello de botella de rendimiento. Al consultar datos a través de esta unión, el motor de la base de datos debe realizar una operación de unión que puede escalar mal a medida que el número de filas crece hasta los millones. La solución no siempre es arquitectónica; a veces requiere desnormalización, pero esto introduce anomalías de actualización.
Consideraciones clave para muchos a muchos:
- ¿Tiene la relación atributos que requieren indexación?
- ¿Es la relación activa o histórica? (por ejemplo, ¿es una inscripción actual diferente de una anterior?)
- ¿Cómo manejará el sistema los registros huérfanos si se elimina un padre?
2. Relaciones recursivas: jerarquías de referencia a sí mismas 🌳
Los datos jerárquicos están en todas partes. Piense en un organigrama, una lista de materiales o un hilo de comentarios en un foro. Modelar esto requiere que una tabla se refiera a sí misma. Aunque conceptualmente sencillo, implementarlo en un esquema relacional introduce desafíos específicos relacionados con la profundidad y el recorrido.
El problema estructural:
Crea una tabla con una clave primaria y una columna de clave foránea que apunta de nuevo a la clave primaria de la misma tabla. A menudo se denomina columna “parent_id”. El nodo raíz tiene un padre nulo.
El problema de rendimiento:
Las consultas SQL estándar tienen dificultades con jerarquías profundas. Si necesita obtener un gerente y todos sus subordinados directos e indirectos, una simple unión no es suficiente. Necesita expresiones de tabla común recursivas (CTEs) o procedimientos almacenados que recorran los niveles. Esto puede ser computacionalmente costoso.
El problema de integridad:
Las referencias circulares son un asesino silencioso. Si el empleado A gestiona al empleado B, y el empleado B gestiona al empleado A, tienes un ciclo. La base de datos debe prevenirlo, o la lógica de la aplicación debe detectarlo. En sistemas grandes, un ciclo puede provocar un bucle infinito en herramientas de informes.
- Límites de profundidad:La mayoría de los sistemas limitan la profundidad de la jerarquía (por ejemplo, 32 niveles) para evitar errores de desbordamiento de pila durante el recorrido.
- Agregación de rutas:Calcular el costo total o el recuento de un subárbol requiere lógica recursiva que es difícil de optimizar en planes de consulta estándar.
3. Modelado de supertipo y subtipo: el dilema de la herencia 🧬
En programación orientada a objetos, la herencia es estándar. En bases de datos relacionales, es una elección de diseño que afecta el almacenamiento y la recuperación. La pregunta es: ¿modelas un vehículo como una sola tabla, o lo divides en Vehículo, Coche y Camión?
Opción A: Herencia de tabla única
Todos los atributos para todos los subtipos están en una sola tabla. Se utilizan valores nulos para los atributos no utilizados.
- Ventajas:Consultas simples, no se necesitan uniones para encontrar ningún vehículo.
- Desventajas:Aumento excesivo de tamaño de tabla, difícil de aplicar restricciones específicas por subtipo, muchas columnas que aceptan valores nulos.
Opción B: Herencia de tabla de clase
Una tabla para el tipo superior (Vehículo), y tablas separadas para los subtipos (Coche, Camión) vinculadas mediante la clave primaria.
- Ventajas:Separación clara, sin valores nulos, restricciones estrictas por subtipo.
- Desventajas:Las consultas requieren unir múltiples tablas, lo que puede afectar el rendimiento de lectura.
Nuestros principales DBAs destacaron que la elección depende a menudo de los patrones de consulta. Si consulta con frecuencia subtipos específicos, el enfoque de tabla de clase es mejor. Si con frecuencia agrega todos los subtipos, la opción de tabla única gana. El diagrama ERD debe reflejar claramente esta decisión para evitar confusiones para los desarrolladores futuros.
4. Datos temporales: Seguimiento de cambios a lo largo del tiempo ⏳
Las reglas de negocio cambian. Un cliente se muda, un precio se actualiza, un contrato expira. Almacenar únicamente el estado «actual» a menudo es insuficiente para auditorías o informes. Esto lleva al diseño de tablas temporales o dimensiones que cambian lentamente (SCD).
La complejidad:
En lugar de actualizar una fila, inserta una nueva fila con una fecha de inicio y fin efectivas. La fila antigua se marca como inactiva. Esto duplica el requisito de almacenamiento para los datos históricos y complica la consulta de la vista «actual».
El desafío de consulta:
Seleccionar datos «tal como estaban» en un punto específico del tiempo requiere filtrar por el rango de fechas. Si omites la lógica del rango de fechas, podrías devolver la versión incorrecta de un registro. Es común que surjan problemas de integridad de datos en aplicaciones financieras.
- Diseño de instantánea:Almacena el estado en un punto en el tiempo. Requiere trabajos por lotes periódicos para escribir instantáneas.
- Diseño de registro de transacciones:Captura cada cambio. Alto volumen de escritura, lógica de recuperación compleja.
- Diseño periódico:Almacena intervalos válidos. Maneja bien los huecos en el tiempo, pero requiere una gestión cuidadosa de los límites.
5. Sistemas distribuidos: Fragmentación y relaciones 🔗
Cuando una sola base de datos no puede contener los datos, la fragmentación se vuelve necesaria. Es aquí donde el diseño de ERD enfrenta sus restricciones físicas más severas. Las relaciones que cruzan los límites de fragmentación son costosas.
El problema de unión:
Si la tabla A está fragmentada por ID de usuario, y la tabla B está vinculada a la tabla A, la tabla B debe estar fragmentada por el mismo ID de usuario para evitar uniones distribuidas. Si la tabla B está fragmentada por otra cosa, debe enrutar la consulta a múltiples fragmentos, agrupar los resultados y unirlos localmente.
Integridad referencial:
Las restricciones de clave externa son difíciles de aplicar entre nodos distribuidos. Muchos sistemas deshabilitan las claves externas en entornos fragmentados para mantener la disponibilidad. Esto traslada la responsabilidad de la integridad a la capa de aplicación, que es propensa a condiciones de carrera.
Puntos clave para ERDs distribuidos:
- Evite las relaciones muchos a muchos que abarcan múltiples fragmentos.
- Denormalice los datos para reducir la necesidad de uniones entre nodos.
- Diseñe la clave de partición (clave de fragmentación) según los patrones de consulta más frecuentes, no solo según la clave primaria.
6. Rendimiento frente a normalización: El equilibrio de compromiso ⚖️
La normalización (1FN, 2FN, 3FN) se enseña como la norma de oro para la integridad de los datos. Sin embargo, en sistemas de alto rendimiento, la normalización estricta puede destruir el rendimiento. El ERD debe equilibrar ambos aspectos.
Cuándo denormalizar:
- Cargas de trabajo con muchas lecturas: Si lee datos mucho más que escribe, agregar columnas redundantes ahorra operaciones de unión.
- Requisitos de informes: Las agregaciones sobre datos normalizados requieren uniones complejas que ralentizan los paneles.
- Cargas de trabajo con muchas escrituras: A veces, mantener los datos separados reduce la contención de bloqueos durante las actualizaciones.
Nuestro panel destacó que no existe un esquema «perfecto». Es un compromiso. Un ERD debe documentar dónde ocurre la denormalización y por qué, para que los futuros mantenimientos entiendan que la redundancia es intencional, no un error.
Comparación de patrones de modelado 📊
Para ayudar en la toma de decisiones, aquí tiene un resumen de los patrones de modelado discutidos y sus casos de uso típicos.
| Patrón | Mejor caso de uso | Riesgo principal | Complejidad |
|---|---|---|---|
| Tabla única | Jerarquías simples, baja variedad | Campos nulos, aumento del esquema | Baja |
| Tabla de clases | Subtipos estrictos, atributos distintos | Sobrecarga de unión | Media |
| Recursivo | Diagramas organizacionales, categorías | Profundidad de recorrido, ciclos | Alto |
| Entidad asociativa | Muchos a muchos con atributos | Rendimiento de unión | Medio |
| Temporal | Auditoría, seguimiento de historial | Complejidad de consulta | Alto |
| Fragmentación distribuida | Gran escala, crecimiento horizontal | Integridad referencial | Muy alto |
Lista de verificación para revisión de diagramas ER ✅
Antes de finalizar un diagrama de relaciones de entidades, utilice esta lista de verificación para detectar errores comunes. Es mejor detectar estos problemas durante la fase de diseño que en producción.
- Cardinalidad:¿Ha definido claramente las relaciones uno a uno, uno a muchos y muchos a muchos? ¿Las restricciones mínimas/máximas (0..1, 1..*) son explícitas?
- Tipos de datos:¿Los tipos de columna son adecuados para el tamaño esperado de los datos? (por ejemplo, usar Integer frente a Varchar para identificadores).
- Posibilidad de nulidad:¿Pueden ser nulos los identificadores foráneos? Si es así, ¿la lógica maneja adecuadamente las referencias huérfanas?
- Estrategia de indexación:¿El diagrama ER indica qué columnas necesitan indexación para el rendimiento? Los identificadores foráneos a menudo se indexan para acelerar las uniones.
- Convenciones de nomenclatura:¿Los nombres de tablas y columnas son coherentes? Evite abreviaturas que puedan resultar ambiguas más adelante.
- Reglas de negocio:¿Las restricciones (por ejemplo, “Un usuario no puede tener dos suscripciones activas”) se representan como comprobaciones lógicas o restricciones de base de datos?
- Extensibilidad:¿Puede el esquema acomodar nuevos atributos sin requerir una migración completa? (por ejemplo, utilizando un patrón EAV o columnas JSON cuando sea apropiado).
Reflexiones finales sobre el modelado de datos 🧠
Diseñar un diagrama de entidades y relaciones no se trata solo de dibujar cajas y líneas. Se trata de comprender el flujo de datos, las limitaciones del hardware y las necesidades del negocio. Los escenarios discutidos aquí representan los puntos de fricción donde la teoría se encuentra con la práctica.
Al anticipar estos desafíos—profundidad recursiva, combinaciones distribuidas, historial temporal y compromisos de herencia—puedes construir esquemas resilientes. Un ERD bien elaborado reduce la deuda técnica y evita la necesidad de reestructuraciones costosas más adelante. Es una inversión en la estabilidad de todo el sistema.
Recuerda que el mejor esquema es aquel que evoluciona con los datos. La documentación es clave. Asegúrate de que cada desviación de la normalización estándar esté justificada y registrada. Esta transparencia es lo que diferencia una arquitectura de base de datos robusta de una frágil.