











Die Gestaltung einer robusten Datenstruktur ist die Grundlage jedes zuverlässigen Informationssystems. Im Zentrum dieses Entwurfs steht das Entity-Relationship-Diagramm (ERD), eine visuelle Bauplanung, die definiert, wie Datenentitäten miteinander interagieren. Ein Diagramm allein garantiert jedoch keine Effizienz. Die wahre Stärke eines ERD entfaltet sich erst, wenn er mit strengen Normalisierungsstrategien kombiniert wird. Das Ziel ist eindeutig: die Erreichung einer Speicherung ohne Redundanz. Das bedeutet, doppelte Daten zu beseitigen, um Integrität zu gewährleisten, Speicherkosten zu senken und die Wartung zu vereinfachen.
Redundanz ist nicht nur ein Speicherproblem; es ist ein logischer Fehler, der Inkonsistenzen verursachen kann. Wenn Daten ohne strenge Beziehung über mehrere Zeilen oder Tabellen hinweg wiederholt werden, sind Aktualisierungsanomalien unvermeidbar. Eine Änderung eines einzelnen Attributs könnte Updates an Dutzenden von Stellen erfordern. Wenn eine davon ausgelassen wird, wird die Datenbank beschädigt. Dieser Leitfaden untersucht die Mechanismen der Normalisierung im Kontext der ERD-Entwicklung, wobei der Fokus auf praktische Anwendung und strukturelle Reinheit liegt.
🧱 Das Verständnis der Grundlagen der Datenmodellierung
Bevor Normalisierungsregeln angewendet werden, muss man die Bestandteile des Entity-Relationship-Diagramms verstehen. Ein ERD besteht aus Entitäten, Attributen und Beziehungen. Entitäten stellen Objekte oder Konzepte dar, wie ein Kunde oder ein Produkt. Attribute sind die Eigenschaften, die diese Entitäten beschreiben, wie Name oder Preis. Beziehungen definieren, wie Entitäten miteinander verbunden sind, oft über Fremdschlüssel.
Die Normalisierung ist der Prozess der Organisation dieser Attribute, um Redundanz und Abhängigkeiten zu minimieren. Dabei werden große Tabellen in kleinere, logisch verbundene aufgeteilt, und Beziehungen zwischen ihnen werden definiert. Ziel ist es, Daten zu isolieren, sodass jeder Sachverhalt nur an einer einzigen Stelle gespeichert wird.
Betrachten Sie den Unterschied zwischen einem denormalisierten und einem normalisierten Ansatz. Bei einem denormalisierten Ansatz könnte eine einzelne Tabelle alle Informationen zu einer Bestellung enthalten, einschließlich der Adresse und der Telefonnummer des Kunden bei jeder Bestellungsanlage. Wenn der Kunde umzieht, müssen Sie jede einzelne Bestellungsdatei aktualisieren. Bei einem normalisierten Ansatz befindet sich die Kundenadresse in einer separaten Kunden-Tabelle. Die Bestell-Tabelle enthält lediglich einen Verweis auf die Kunden-ID. Diese Trennung ist das Wesen der Speicherung ohne Redundanz.
📉 Die Risiken unnormalisierter Daten
Warum ist die Speicherung ohne Redundanz so entscheidend? Die Antwort liegt in den Arten von Anomalien, die auftreten, wenn die Normalisierung ignoriert wird. Diese Anomalien gefährden die Zuverlässigkeit des gesamten Systems.
- Einfügeanomalien:Sie können Daten für eine Entität nicht hinzufügen, ohne Daten für eine andere hinzuzufügen. Zum Beispiel könnten Sie die Existenz eines neuen Mitarbeiters nicht erfassen, wenn der Mitarbeiter noch kein Projekt zugewiesen bekommen hat, und die Tabelle eine Projekt-ID erfordert.
- Löschanomalien:Das Löschen von Daten für eine Entität könnte unbeabsichtigt Daten für eine andere entfernen. Wenn Sie die letzte Bestellung eines Kunden löschen, könnten Sie dessen Kontaktdaten vollständig verlieren.
- Aktualisierungsanomalien:Dies ist das häufigste Problem. Wenn die Adresse eines Kunden in mehreren Bestell-Records gespeichert ist, erfordert die Aktualisierung der Adresse das Finden und Ändern jedes einzelnen Datensatzes. Das Auslassen führt zu widersprüchlichen Daten.
Die Erreichung einer Speicherung ohne Redundanz mindert diese Risiken direkt. Indem sichergestellt wird, dass jeder Datenbestand an einer einzigen Stelle gespeichert wird, wird das System selbstkorrigierend. Aktualisierungen erfolgen nur einmal, und die Änderung verbreitet sich logisch über die Beziehungen hinweg.
🪜 Der Weg zu Normalformen
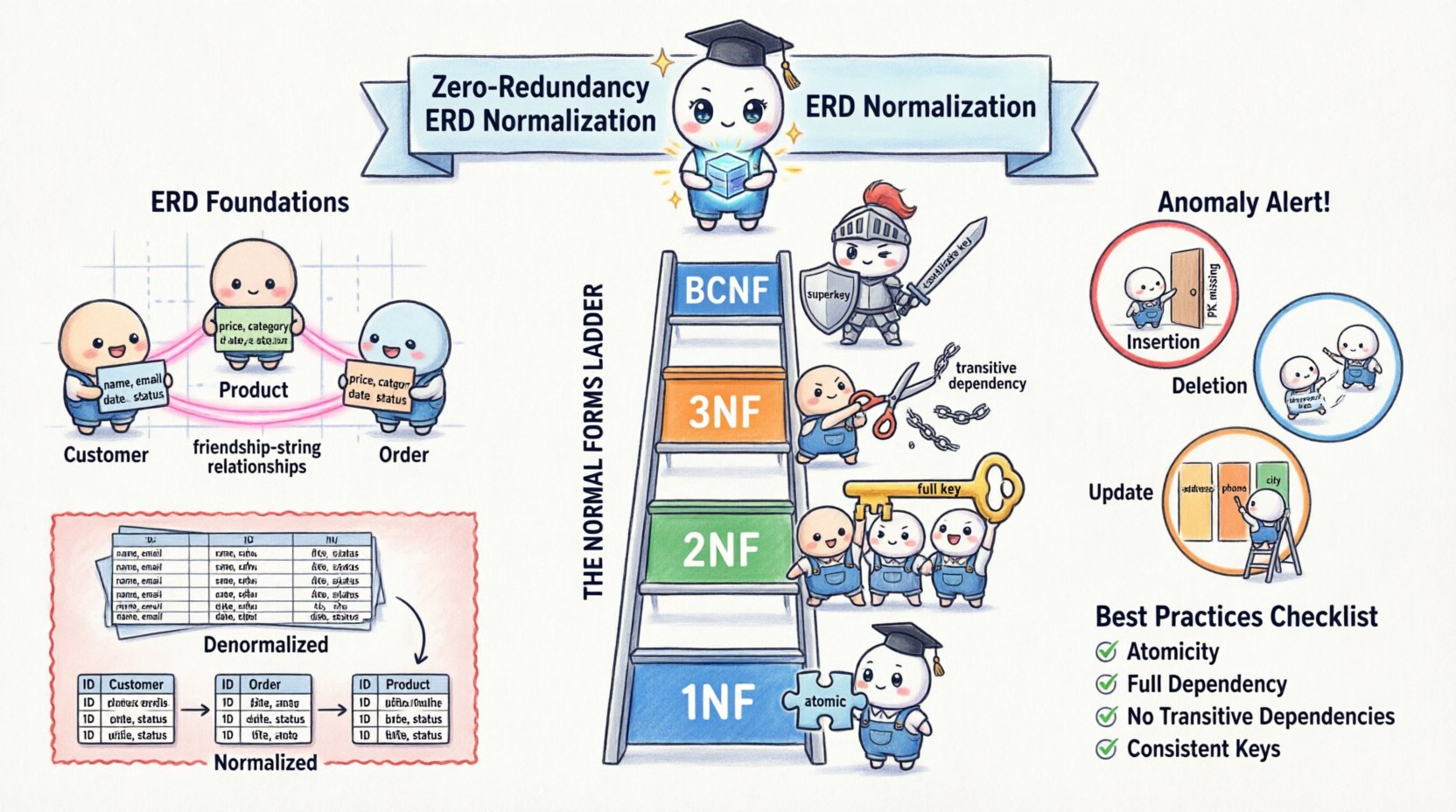
Die Normalisierung ist kein einziger Schritt, sondern eine Fortschreitung durch verschiedene Stufen, die als Normalformen bezeichnet werden. Jede Form befasst sich mit spezifischen Arten von Redundanz. Während die theoretischen Modelle bis zur fünften Normalform (5NF) reichen, konzentriert sich die praktische Datenbankgestaltung typischerweise auf die ersten drei Formen sowie die Boyce-Codd-Normalform (BCNF).
1️⃣ Erste Normalform (1NF)
Die erste Regel der Normalisierung ist die Sicherstellung der Atomsicherheit. Eine Tabelle befindet sich in 1NF, wenn sie keine sich wiederholenden Gruppen oder Arrays enthält. Jede Spalte muss einen einzelnen Wert enthalten, und jede Zeile muss eindeutig sein.
- Atomare Werte:Ein Feld kann keine Liste von Werten enthalten. Anstatt einer Spalte namens „Fähigkeiten“, die „Java, SQL, Python“ enthält, sollten Sie separate Zeilen für jede Fähigkeit oder eine separate Tabelle für Fähigkeiten erstellen.
- Eindeutige Zeilen:Jede Zeile muss von jeder anderen Zeile unterscheidbar sein. Dies erfordert in der Regel einen Primärschlüssel.
Im Kontext eines ERD bedeutet dies, jedes Attribut zu überprüfen. Wenn ein Attribut eine mehrwertige Eigenschaft beschreibt, muss es extrahiert werden. Dies ist der grundlegende Schritt. Ohne 1NF können höhere Formen nicht wirksam angewendet werden.
2️⃣ Zweite Normalform (2NF)
Sobald eine Tabelle in 1NF ist, muss sie die Kriterien für 2NF erfüllen. Eine Tabelle befindet sich in 2NF, wenn sie in 1NF ist und alle Nicht-Schlüssel-Attribute vollständig vom gesamten Primärschlüssel abhängen.
Diese Regel befasst sich hauptsächlich mit Tabellen mit zusammengesetzten Schlüsseln (Schlüsseln aus mehreren Spalten). Wenn eine Tabelle einen zusammengesetzten Schlüssel hat, muss jedes Attribut vom gesamten Schlüssel abhängen, nicht nur von einem Teil davon.
- Vollständige Abhängigkeit:Wenn eine Spalte sich nur auf einen Teil eines zusammengesetzten Schlüssels stützt, gehört sie in eine separate Tabelle.
- Partielle Abhängigkeit: Dies ist die spezifische Redundanz, die 2NF beseitigt. Zum Beispiel, in einer Tabelle, die Studenten mit Kursen verknüpft, hängt der „Studentenname“ nur von der Studenten-ID ab, nicht von der Kurs-ID. Dies erzeugt Redundanz.
Die Lösung besteht darin, die Tabelle zu teilen. Sie erstellen eine Studententabelle und eine Kursentabelle, verbunden durch eine Verknüpfungstabelle. Dadurch wird sichergestellt, dass Studentendaten nicht für jeden Kurs, den sie besuchen, wiederholt werden.
3️⃣ Dritte Normalform (3NF)
Die dritte Normalform befasst sich mit transitiven Abhängigkeiten. Eine Tabelle befindet sich in 3NF, wenn sie in 2NF ist und kein Nicht-Schlüssel-Attribut von einem anderen Nicht-Schlüssel-Attribut abhängt.
In einfachen Worten sollten Attribute nicht von anderen Attributen abhängen, die nicht Teil des Primärschlüssels sind. Dies geschieht oft, wenn eine Spalte eine andere Spalte beschreibt, anstatt die Zeile selbst zu beschreiben.
- Transitive Abhängigkeit: Wenn A B bestimmt und B C bestimmt, dann bestimmt A C. Wenn B kein Schlüssel ist, wird C redundant gespeichert.
- Beispiel: In einer Mitarbeiter-Tabelle, wenn Sie „Abteilungsname“ und „Abteilungsleiter“ speichern, hängt der Leiter vom Abteilungsnamen ab. Wenn sich der Abteilungsname ändert, könnte die Spalte für den Leiter inkonsistent werden, wenn dies nicht sorgfältig verwaltet wird.
Um dies zu beheben, verschieben Sie die Abteilungsinformationen in eine separate Abteilungstabelle. Die Mitarbeiter-Tabelle enthält dann nur eine Abteilungs-ID. Dadurch wird die Abteilungsdaten isoliert, sodass bei einer Umbenennung einer Abteilung diese nur an einer Stelle aktualisiert werden muss.
4️⃣ Boyce-Codd-Normalform (BCNF)
BCNF ist eine strengere Version von 3NF. Sie gilt, wenn es mehrere Kandidatenschlüssel gibt oder wenn ein Nicht-Schlüssel-Attribut auf eine bestimmte Weise ein anderes Nicht-Schlüssel-Attribut bestimmt. Eine Tabelle befindet sich in BCNF, wenn für jede funktionale Abhängigkeit X → Y gilt, dass X ein Superkey ist.
Diese Form behandelt komplexe Szenarien, bei denen 3NF immer noch Anomalien zulassen könnte. Sie stellt sicher, dass jeder Determinant ein Kandidatenschlüssel ist. Obwohl sie nicht für jedes Schema unbedingt erforderlich ist, bietet das Streben nach BCNF das höchste Maß an struktureller Integrität bei null Redundanz.
🛠️ Umgang mit Anomalien: Ein vergleichender Überblick
Das Verständnis der Auswirkungen der Normalisierung erfordert einen klaren Blick darauf, wie Anomalien auftreten. Die folgende Tabelle zeigt die Unterschiede zwischen normalisierten und nicht-normalisierten Zuständen hinsichtlich häufiger Datenprobleme.
| Anomalietyp | Nicht-normalisierter Zustand | Normalisierter Zustand (null Redundanz) |
|---|---|---|
| Aktualisierung | Erfordert die Änderung von Daten in mehreren Zeilen. Hohe Gefahr von Inkonsistenzen. | Erfordert die Änderung von Daten in einer einzigen Zeile. Die Konsistenz ist automatisch gewährleistet. |
| Einfügen | Kann Dummy-Daten erfordern, um Fremdschlüssel-Beschränkungen zu erfüllen. | Neue Entitäten können unabhängig hinzugefügt werden, ohne dass unzusammenhängende Daten erforderlich sind. |
| Löschen | Das Löschen einer Aufzeichnung kann wesentliche Daten über eine andere Entität entfernen. | Das Löschen einer Aufzeichnung betrifft nur die spezifische Entität und bewahrt die anderen. |
| Speicherung | Hoher Speicherverbrauch aufgrund wiederholter Zeichenketten und Werte. | Minimale Speicherverwendung; Werte werden über IDs referenziert. |
Wie gezeigt, reduziert der normalisierte Ansatz die betriebliche Belastung der Datenverwaltung erheblich. Der Preis ist etwas komplexere Abfragen, da Joins erforderlich sind, um vollständige Informationen abzurufen. Doch das Kompromiss ist zugunsten von Integrität und langfristiger Wartbarkeit.
🛠️ Strategien zur Umsetzung
Die Umsetzung dieser Strategien in der Phase der ERD-Entwicklung ist entscheidend. Es ist viel einfacher, Redundanz zu verhindern, als sie nach der Dateneingabe zu beheben. Hier sind handlungsorientierte Schritte für Designer.
1. Funktionale Abhängigkeiten früh identifizieren
Bevor Sie Linien zwischen Entitäten ziehen, listen Sie die Attribute auf und bestimmen Sie, was was bestimmt. Wenn Sie wissen, dass Attribut A Attribut B bestimmt, wissen Sie, dass sie wahrscheinlich in derselben Entität verbleiben sollten, es sei denn, A ist kein Schlüssel.
- Zeichnen Sie alle Beziehungen auf.
- Fragen Sie: „Hängt dieses Attribut vom gesamten Schlüssel ab?“
- Fragen Sie: „Hängt dieses Attribut von einem anderen nicht-schlüsselbasierten Attribut ab?“
2. Entitäten basierend auf ihrem Lebenszyklus trennen
Entitäten mit unterschiedlichen Aktualisierungshäufigkeiten sollten oft getrennt werden. Wenn eine statische Referenztabelle (wie eine Liste von Ländern) mit einer transaktionalen Tabelle (wie Aufträge) vermischt wird, erzeugt die statische Daten unnötige Redundanz in der transaktionalen Tabelle.
3. Surrogatschlüssel verwenden
Verwenden Sie statt natürlicher Daten als Primärschlüssel einen Surrogatschlüssel (eine eindeutige Kennung, die vom System generiert wird). Dadurch werden Probleme vermieden, bei denen der Schlüssel selbst im Laufe der Zeit ändert, was Beziehungen in einem normalisierten System zerstören würde.
4. Mit Testdaten validieren
Bevor Sie die ERD endgültig festlegen, versuchen Sie, sie mit Beispiel-Daten zu füllen. Versuchen Sie, die zuvor beschriebenen Anomalien zu erzeugen. Wenn Sie einen Kunden erfolgreich ohne Auftrag einfügen können und einen Auftrag löschen können, ohne den Kunden zu verlieren, ist Ihr Entwurf wahrscheinlich solide.
⚖️ Ausbalancieren von Leistung und Reinheit
Null-Redundanz zu erreichen bedeutet nicht, die Anzahl der Tabellen zu maximieren. Übermäßige Normalisierung kann zu Leistungseinbußen führen. Wenn eine Abfrage Daten aus zehn verschiedenen Tabellen erfordert, muss das System zehn Joins durchführen. Dies kann Leseoperationen erheblich verlangsamen.
Wann man de-normalisiert
Es gibt gültige Gründe, bewusst Redundanz wieder einzuführen. Dies wird oft De-Normalisierung genannt.
- Leseeingabe-orientierte Systeme: In Data-Warehouses oder Berichtswerkzeugen wird die Lese-Geschwindigkeit gegenüber der Schreib-Konsistenz priorisiert. Vorab berechnete Spalten können die Komplexität von Joins reduzieren.
- Historische Schnappschüsse: Wenn Sie wissen müssen, welcher Adresswert eines Kunden zum Zeitpunkt einer Bestellung galt, können Sie sich nicht auf die aktuelle Adresse in der Kunden-Tabelle verlassen. Sie müssen die Adresse in der Bestell-Tabelle speichern.
- Leistungs-Optimierung: Wenn Abfragen aufgrund von Joins konstant langsam sind, könnte es notwendig sein, eine redundanten Spalte hinzuzufügen, die über Trigger oder Anwendungslogik aktualisiert wird.
Der Schlüssel liegt in der Intentionalität. Akzeptieren Sie Redundanz nicht als Standard. Akzeptieren Sie sie nur, wenn ein messbarer Leistungsvorteil die Wartungskosten überwiegt.
🔄 Überprüfen und Pflegen Ihrer Schema
Normalisierung ist keine einmalige Aufgabe. Geschäftsanforderungen ändern sich, und Daten wachsen. Ein Schema, das vor fünf Jahren normalisiert wurde, könnte heute Anpassungen benötigen.
Regelmäßige Audits
Planen Sie regelmäßige Überprüfungen Ihrer ERD. Suchen Sie nach Mustern wiederholter Daten. Wenn Sie denselben Textstring in mehreren Tabellen finden, untersuchen Sie, warum dies der Fall ist. Es könnte ein Hinweis auf einen Designfehler oder eine bewusste Entscheidung zur De-Normalisierung sein, die dokumentiert werden muss.
Versionskontrolle für Datenmodelle
Behandle dein ERD wie Code. Verwende Versionskontrollsysteme, um Änderungen zu verfolgen. Dadurch kannst du rückgängig machen, wenn eine Änderung Redundanz einführt oder Beziehungen zerstört. Dokumentiere die Begründung für jede größere strukturelle Änderung.
Schulung des Teams
Stelle sicher, dass jeder, der an der Dateneingabe oder der Anwendungsentwicklung beteiligt ist, die Normalisierungsregeln versteht. Wenn Entwickler das Schema umgehen, um Daten direkt einzufügen, können sie Redundanz durch Anwendungslogik wieder einführen. Klare Dokumentation, warum das Schema auf diese Weise strukturiert ist, ist unerlässlich.
📝 Zusammenfassung der Best Practices
Um ein hohes Maß an Datenqualität und Speichereffizienz zu gewährleisten, halte dich während deines Gestaltungsprozesses an die folgende Prüfliste.
- Atomarität: Stelle sicher, dass jede Spalte einen einzigen Wert enthält (1. Normalform).
- Vollständige Abhängigkeit: Stelle sicher, dass nicht-schlüsselbasierte Attribute von dem gesamten Primärschlüssel abhängen (2. Normalform).
- Keine transitiven Abhängigkeiten: Stelle sicher, dass nicht-schlüsselbasierte Attribute nicht von anderen nicht-schlüsselbasierten Attributen abhängen (3. Normalform).
- Konsistente Schlüssel: Stelle sicher, dass jeder Determinant ein Kandidatenschlüssel ist (Boyce-Codd-Normalform).
- Dokumentiere Entscheidungen: Dokumentiere, warum bestimmte Redundanzen eingeführt wurden.
- Überwache das Wachstum: Achte auf Muster wiederholter Daten, wenn die Datenbank skaliert.
Durch Einhaltung dieser Prinzipien schaffst du ein System, das widerstandsfähig gegenüber Veränderungen ist. Die Daten bleiben sauber, und die Logik bleibt konsistent. Null-Redundanz geht nicht nur darum, Speicherplatz zu sparen; es geht darum, eine Grundlage zu schaffen, auf der die Datenwahrheit erhalten bleibt.
🚀 Letzte Gedanken zur strukturellen Integrität
Die Reise hin zu einer Speicherung ohne Redundanz ist eine Investition in die Langlebigkeit deiner Datenarchitektur. Obwohl sie Disziplin während der Entwurfsphase erfordert, werden die Vorteile in Form von weniger Fehlern, geringeren Wartungskosten und höherem Vertrauen in das Informationssystem erzielt.
Wenn du dir ein Entity-Relationship-Diagramm ansiehst, betrachte es nicht nur als Sammlung von Feldern und Linien, sondern als Karte der Wahrheit. Jede Linie repräsentiert eine notwendige Beziehung. Jedes Feld steht für eine eindeutige Tatsache. Durch effektives Normalisieren stellst du sicher, dass diese Karte auch dann genau bleibt, wenn sich das Terrain deines Geschäfts verändert.
Konzentriere dich auf die Logik, nicht nur auf die Speicherung. Lass die Struktur dem Datenbedarf dienen, nicht umgekehrt. Mit einem klaren Verständnis von Normalisierungsstrategien bist du in der Lage, Systeme zu entwickeln, die der Zeit und der Datenmenge standhalten.