











Designing a robust data structure is the backbone of any reliable information system. At the heart of this design lies the Entity Relationship Diagram (ERD), a visual blueprint that defines how data entities interact. However, a diagram alone does not guarantee efficiency. The true power of an ERD emerges when paired with rigorous normalization strategies. The objective is clear: achieve zero-redundancy storage. This means eliminating duplicate data to ensure integrity, reduce storage costs, and simplify maintenance.
Redundancy is not merely a storage issue; it is a logic flaw waiting to cause inconsistencies. When data is repeated across multiple rows or tables without a strict relationship, update anomalies become inevitable. A change in a single attribute might require updates in dozens of places. If one is missed, the database becomes corrupted. This guide explores the mechanics of normalization within the context of ERD design, focusing on practical application and structural purity.
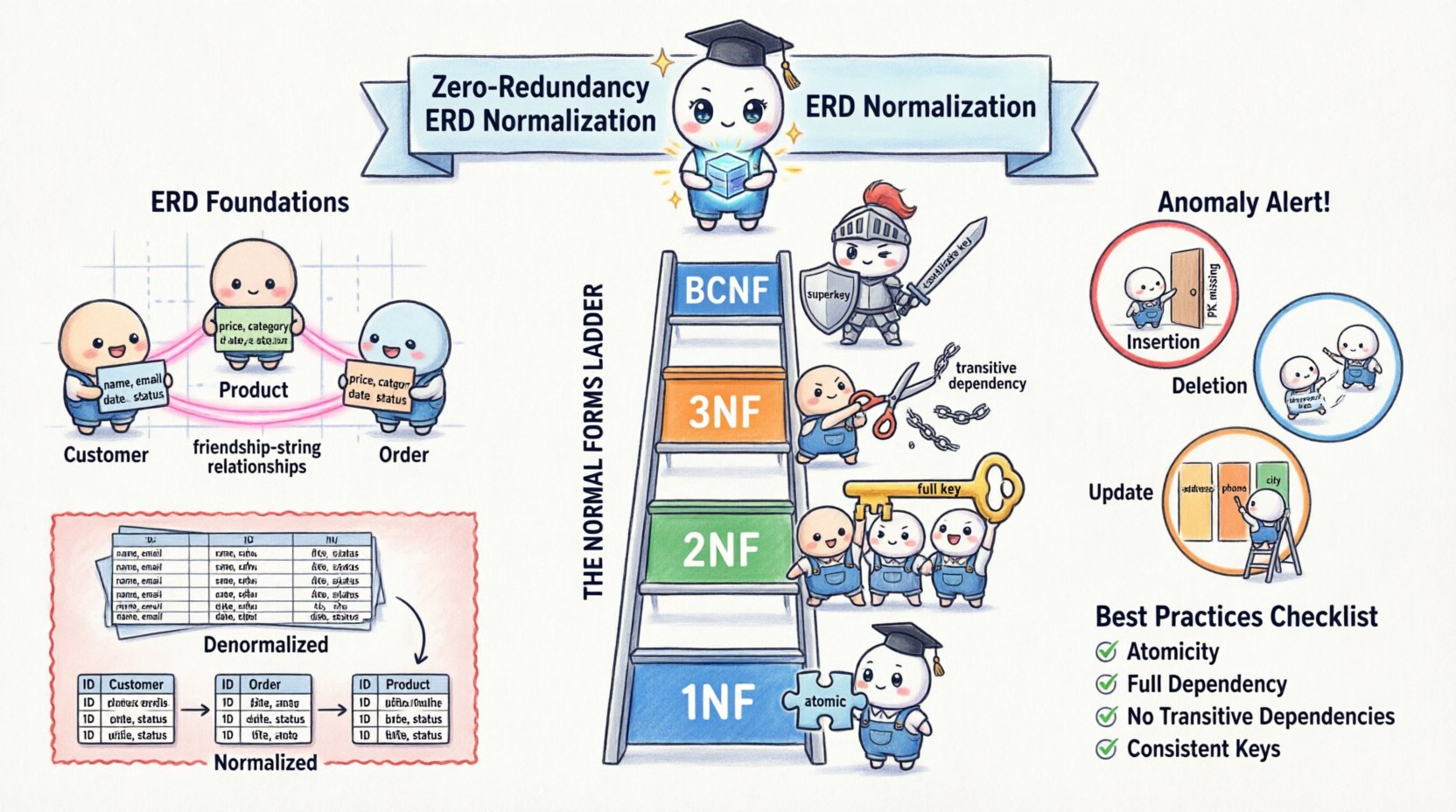
🧱 Understanding the Foundations of Data Modeling
Before applying normalization rules, one must understand the components of the Entity Relationship Diagram. An ERD consists of entities, attributes, and relationships. Entities represent objects or concepts, such as a Customer or a Product. Attributes are the properties describing these entities, like a Name or a Price. Relationships define how entities connect, often through foreign keys.
Normalization is the process of organizing these attributes to minimize redundancy and dependency. It involves dividing large tables into smaller, logically connected ones and defining relationships between them. The goal is to isolate data so that each fact is stored in only one place.
Consider the difference between a denormalized approach and a normalized one. In a denormalized view, a single table might hold all information about an order, including the customer’s address and phone number every time an order is placed. If the customer moves, you must update every single order record. In a normalized view, the customer address exists in a separate Customer table. The Order table simply holds a reference to the Customer ID. This separation is the essence of zero-redundancy.
📉 The Risks of Unnormalized Data
Why is zero-redundancy so critical? The answer lies in the types of anomalies that occur when normalization is ignored. These anomalies threaten the reliability of the entire system.
- Insertion Anomalies: You cannot add data for one entity without adding data for another. For example, if a new employee has not yet been assigned to a project, you might not be able to record their existence if the table requires a project ID.
- Deletion Anomalies: Deleting data for one entity might unintentionally remove data for another. If you delete the last order for a customer, you might lose the customer’s contact information entirely.
- Update Anomalies: This is the most common issue. If a customer’s address is stored in multiple order records, updating the address requires finding and changing every single record. Failure to do so results in conflicting data.
Achieving zero-redundancy directly mitigates these risks. By ensuring that each piece of information has a single home, the system becomes self-correcting. Updates happen once, and the change propagates logically through relationships.
🪜 The Path to Normal Forms
Normalization is not a single step but a progression through distinct stages called Normal Forms. Each form addresses specific types of redundancy. While the theoretical models go up to Fifth Normal Form (5NF), practical database design typically focuses on the first three forms and Boyce-Codd Normal Form (BCNF).
1️⃣ First Normal Form (1NF)
The first rule of normalization is to ensure atomicity. A table is in 1NF if it contains no repeating groups or arrays. Every column must hold a single value, and every row must be unique.
- Atomic Values: A field cannot contain a list of values. Instead of a column named “Skills” containing “Java, SQL, Python”, you should create separate rows for each skill or a separate table for skills.
- Unique Rows: Every row must be distinguishable from every other row. This usually requires a Primary Key.
In the context of an ERD, this means checking every attribute. If an attribute describes a multi-valued property, it must be extracted. This is the foundational step. Without 1NF, higher forms cannot be applied effectively.
2️⃣ Second Normal Form (2NF)
Once a table is in 1NF, it must meet the criteria for 2NF. A table is in 2NF if it is in 1NF and all non-key attributes are fully dependent on the entire primary key.
This rule primarily addresses tables with composite keys (keys made of multiple columns). If a table has a composite key, every attribute must depend on the whole key, not just part of it.
- Full Dependency: If a column relies only on one part of a composite key, it belongs in a separate table.
- Partial Dependency: This is the specific redundancy 2NF eliminates. For instance, in a table linking Students to Courses, if the “Student Name” is stored, it depends only on the Student ID, not the Course ID. This creates redundancy.
Resolving this involves splitting the table. You create a Student table and a Course table, with a junction table linking them. This ensures that student details are not repeated for every course they take.
3️⃣ Third Normal Form (3NF)
The third normal form deals with transitive dependencies. A table is in 3NF if it is in 2NF and no non-key attribute depends on another non-key attribute.
In simpler terms, attributes should not depend on other attributes that are not part of the primary key. This often happens when a column describes another column rather than the row itself.
- Transitive Dependency: If A determines B, and B determines C, then A determines C. If B is not a key, C is redundantly stored.
- Example: In an Employee table, if you store “Department Name” and “Department Manager”, the Manager depends on the Department Name. If the Department Name changes, the Manager column might become inconsistent if not managed carefully.
To fix this, move the Department information to a separate Department table. The Employee table then only holds a Department ID. This isolates the department data, ensuring that if a department is renamed, you update it in one place.
4️⃣ Boyce-Codd Normal Form (BCNF)
BCNF is a stricter version of 3NF. It applies when there are multiple candidate keys or when a non-key attribute determines another non-key attribute in a specific way. A table is in BCNF if, for every functional dependency X → Y, X is a superkey.
This form handles complex scenarios where 3NF might still allow anomalies. It ensures that every determinant is a candidate key. While not always necessary for every schema, aiming for BCNF provides the highest level of structural integrity for zero-redundancy.
🛠️ Handling Anomalies: A Comparative View
Understanding the impact of normalization requires a clear view of how anomalies manifest. The table below outlines the differences between normalized and denormalized states regarding common data issues.
| Anomaly Type | Denormalized State | Normalized State (Zero-Redundancy) |
|---|---|---|
| Update | Requires changing data in multiple rows. High risk of inconsistency. | Requires changing data in a single row. Consistency is automatic. |
| Insert | May require dummy data to satisfy foreign key constraints. | New entities can be added independently without unrelated data. |
| Delete | Deleting a record may remove essential data about another entity. | Deleting a record affects only the specific entity, preserving others. |
| Storage | High storage usage due to repeated strings and values. | Minimal storage usage; values are referenced via IDs. |
As shown, the normalized approach significantly reduces the operational overhead of data management. The cost is slightly more complex querying, as joins are required to retrieve full information. However, the trade-off favors integrity and long-term maintainability.
🛠️ Strategies for Implementation
Implementing these strategies during the ERD design phase is crucial. It is much easier to prevent redundancy than to fix it after data has been populated. Here are actionable steps for designers.
1. Identify Functional Dependencies Early
Before drawing lines between entities, list the attributes and determine what determines what. If you know that Attribute A determines Attribute B, you know they should likely reside in the same entity unless A is not a key.
- Map out all relationships.
- Ask: “Does this attribute depend on the whole key?”
- Ask: “Does this attribute depend on another non-key attribute?”
2. Separate Entities Based on Lifecycle
Entities with different update frequencies should often be separated. If a static reference table (like a list of countries) is mixed with a transactional table (like orders), the static data creates unnecessary redundancy in the transactional table.
3. Use Surrogate Keys
Instead of using natural data as a primary key, consider using a surrogate key (a unique identifier generated by the system). This prevents issues where the key itself changes over time, which would break relationships in a normalized system.
4. Validate with Test Data
Before finalizing the ERD, attempt to populate it with sample data. Try to create the anomalies described earlier. If you can successfully insert a customer without an order, and delete an order without losing the customer, your design is likely sound.
⚖️ Balancing Performance and Purity
Achieving zero-redundancy does not mean maximizing the number of tables. Excessive normalization can lead to performance degradation. When a query requires data from ten different tables, the system must perform ten joins. This can slow down read operations significantly.
When to Denormalize
There are valid reasons to intentionally reintroduce redundancy. This is often called denormalization.
- Read-Heavy Systems: In data warehouses or reporting tools, read speed is prioritized over write consistency. Pre-calculated columns can reduce join complexity.
- Historical Snapshots: If you need to know what a customer’s address was at the time of an order, you cannot rely on the current address in the Customer table. You must store the address in the Order table.
- Performance Tuning: If queries are consistently slow due to joins, adding a redundant column that is updated via triggers or application logic might be necessary.
The key is intentionality. Do not accept redundancy as a default. Accept it only when there is a measured performance benefit that outweighs the maintenance cost.
🔄 Reviewing and Maintaining Your Schema
Normalization is not a one-time task. Business requirements change, and data grows. A schema that was normalized five years ago might need adjustment today.
Regular Audits
Schedule periodic reviews of your ERD. Look for patterns of repeated data. If you find the same text string appearing in multiple tables, investigate why. It might be a sign of a design flaw or a deliberate denormalization choice that needs documentation.
Version Control for Data Models
Treat your ERD as code. Use version control systems to track changes. This allows you to revert if a change introduces redundancy or breaks relationships. Document the reasoning for every major structural change.
Training the Team
Ensure that everyone involved in data entry or application development understands the normalization rules. If developers bypass the schema to insert data directly, they can reintroduce redundancy through application logic. Clear documentation on why the schema is structured this way is essential.
📝 Summary of Best Practices
To maintain a high standard of data quality and storage efficiency, adhere to the following checklist during your design process.
- Atomicity: Ensure every column holds a single value (1NF).
- Full Dependency: Ensure non-key attributes depend on the entire primary key (2NF).
- No Transitive Dependencies: Ensure non-key attributes do not depend on other non-key attributes (3NF).
- Consistent Keys: Ensure every determinant is a candidate key (BCNF).
- Document Decisions: Record why specific redundancies were introduced.
- Monitor Growth: Watch for patterns of repeated data as the database scales.
By following these principles, you create a system that is resilient to change. The data remains clean, and the logic remains sound. Zero-redundancy is not just about saving disk space; it is about building a foundation where data truth is preserved.
🚀 Final Thoughts on Structural Integrity
The journey toward zero-redundancy storage is an investment in the longevity of your data architecture. While it requires discipline during the design phase, the dividends are paid in reduced errors, lower maintenance costs, and higher trust in the information system.
When you look at an Entity Relationship Diagram, see it not just as a collection of boxes and lines, but as a map of truth. Every line represents a relationship of necessity. Every box represents a distinct fact. By normalizing effectively, you ensure that this map remains accurate, even as the terrain of your business evolves.
Focus on the logic, not just the storage. Let the structure serve the data, not the other way around. With a clear understanding of normalization strategies, you are equipped to build systems that stand the test of time and data volume.