











Modernizing a legacy system into a microservices architecture is a journey fraught with technical and organizational challenges. While many teams focus heavily on code refactoring and containerization, a significant stumbling block often lies in the data layer. Specifically, the traditional Entity Relationship Diagram (ERD) model can become a severe constraint when transitioning to distributed systems. 📉
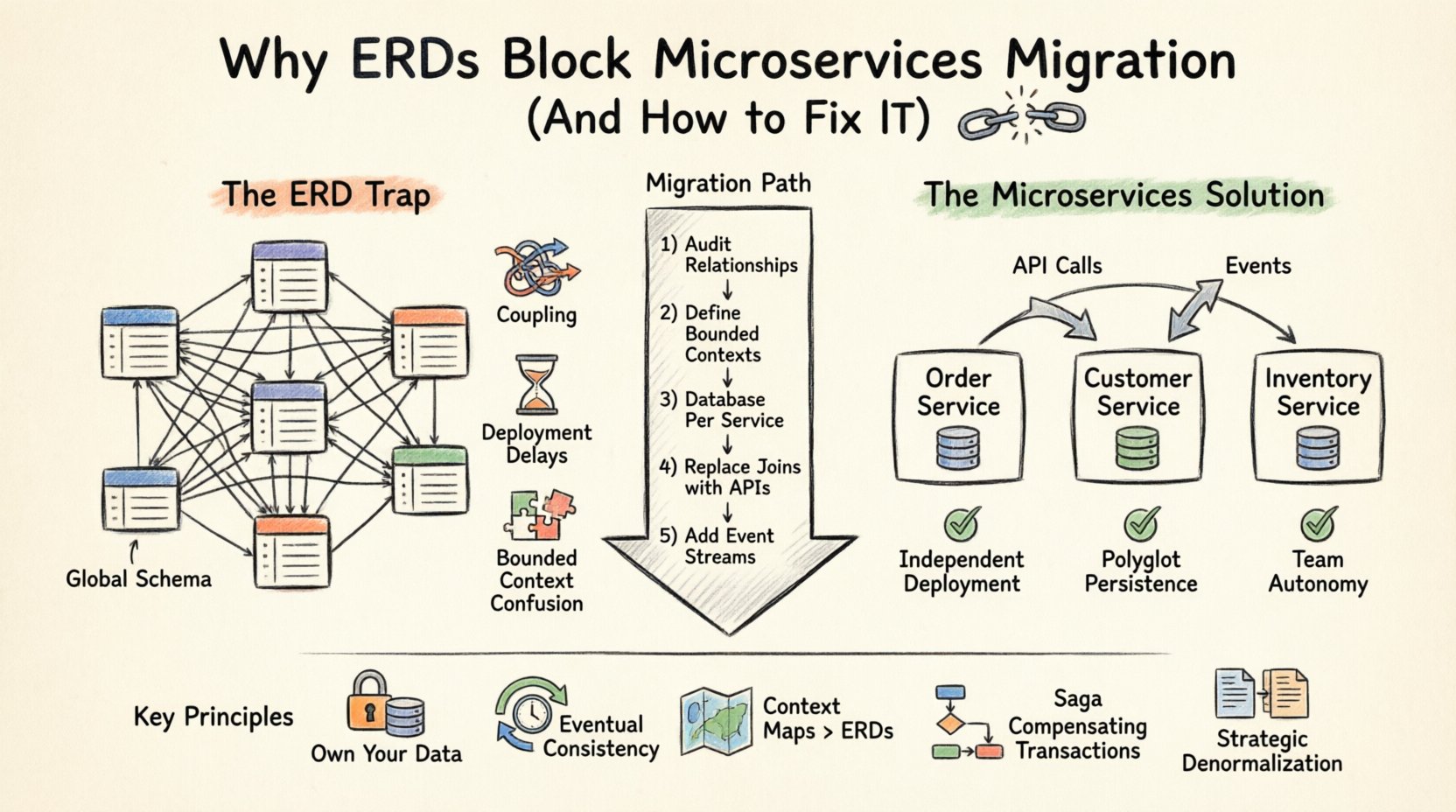
When you design a monolithic application, your data model is centralized. An ERD represents the single source of truth, with normalized tables linked by foreign keys. This approach works well for a single database instance. However, microservices require autonomy. When you force a monolithic ERD structure onto a distributed architecture, you create tight coupling that negates the benefits of breaking apart your system. 🚧
This guide explores why the classic ERD mindset hinders microservices adoption and provides a practical roadmap to transition your data modeling strategies. We will cover distributed data management, consistency models, and visualization techniques that align with domain-driven design principles. 🗺️
Understanding the ERD Trap in Distributed Systems 🧩
An Entity Relationship Diagram is a visual representation of the logical structure of a database. It defines entities (tables), attributes (columns), and relationships (foreign keys). In a monolithic environment, this centralization is a strength. It ensures data integrity through ACID transactions and simplifies querying across the entire application.
However, microservices architecture is built on the principle of service independence. Each service should own its data and expose it only through an API. When you maintain a shared ERD that spans multiple services, you violate the boundary of ownership. This leads to the following issues:
- Global Schema Dependencies: If Service A needs to join data from Service B directly at the database level, they are no longer independent. A change in the schema of Service B breaks Service A.
- Transaction Boundaries: ACID transactions across multiple databases are complex and performance-heavy. Distributed transactions often lead to lock contention and latency spikes.
- Deployment Coupling: If your data model is shared, you cannot deploy services independently. You must coordinate schema changes across teams, slowing down release cycles.
- Bounded Context Confusion: Different services may interpret the same entity differently. An ERD forces a single definition, ignoring domain-specific nuances.
The Coupling Problem: Foreign Keys and Joins 🔗
One of the most common mistakes during migration is attempting to keep the existing database schema intact while splitting the application code. This results in a shared database anti-pattern. In this scenario, multiple services connect to the same database instance, relying on foreign keys to maintain relationships.
While this looks like a valid ERD structure, it is a hidden monolith. Here is why this approach fails in a microservices context:
- Network Latency: Even if the database is local to the network, cross-service queries introduce network hops that degrade performance compared to local queries.
- Single Point of Failure: If the database goes down, every service goes down. Microservices aim for resilience through isolation.
- Security Risks: A service that should not have direct access to other data can still access it via the database connection string. APIs provide a controlled interface; direct DB access does not.
- Technology Lock-in: All services must use the same database technology. Microservices allow polyglot persistence, where different services use the most appropriate data store for their specific needs.
To fix this, you must move away from SQL joins across service boundaries. Instead, you should use API composition or event-driven data synchronization. 🔄
Database Per Service: The Golden Rule 🏦
The foundational pattern for microservices data architecture is Database Per Service. Each service owns its own database schema. No other service is allowed to access this database directly. Communication happens strictly through the service’s public API.
This shift requires a fundamental change in how you visualize your data. You can no longer draw one giant ERD for the entire system. Instead, you create multiple smaller ERDs, one for each service. 📄
| Aspect | Monolithic ERD | Microservices Model |
|---|---|---|
| Schema Scope | Global / Unified | Local / Service-specific |
| Relationships | Foreign Keys | API Calls / Events |
| Consistency | Strong (ACID) | Eventual (BASE) |
| Deployment | Coupled | Independent |
Managing Consistency Without Shared Transactions 🤝
When you separate databases, you lose the ability to run a single transaction that updates both Service A and Service B simultaneously. In a monolith, you might use a database transaction to move money from Account A to Account B. In microservices, these accounts might belong to different services.
Since you cannot guarantee immediate consistency across distributed systems, you must adopt Eventual Consistency. This means the system will reach a consistent state over time, but not necessarily at the exact moment the user clicks a button.
Implementing Sagas
To handle complex workflows that span multiple services, use the Saga pattern. A saga is a sequence of local transactions where each transaction updates the database within a single service. If a step fails, the saga executes compensating transactions to undo the changes made by previous steps.
- Choreography: Services emit events that trigger actions in other services. There is no central coordinator.
- Orchestration: A central coordinator service manages the workflow and tells other services what to do.
This approach ensures data integrity without requiring shared locks or distributed transactions. It adds complexity to the implementation but is necessary for maintaining system health. 🛡️
Visualizing Data Without ERDs: Context Maps 🗺️
If you abandon the traditional ERD, what do you use to visualize your data architecture? The answer lies in Domain-Driven Design (DDD) Context Maps. While an ERD focuses on tables and columns, a Context Map focuses on bounded contexts and relationships.
Instead of drawing lines between tables, you draw lines between services. You define how data flows between them:
- Customer-Supplier: One service provides data to another. The provider defines the contract.
- Conformist: The consuming service must adapt to the provider’s model.
- Open Host Service: A service exposes its data via an open protocol.
- Separate Ways: Both services evolve their own models independently.
This shift in visualization helps teams understand why data is duplicated. In a monolith, duplication is bad. In microservices, duplication is often a feature to decouple services. For example, the Order Service might store a snapshot of the Customer Name to avoid a network call every time an order is viewed. This trade-off is acceptable for performance.
Migration Steps: Moving from ERD to Distributed Data 🚀
Transitioning from a centralized ERD to a distributed data model is not a one-time event. It is a phased process. Here is a recommended approach to manage the migration.
Step 1: Audit Existing Data Relationships
Before splitting anything, document every relationship in your current ERD. Identify which tables are read-heavy, which are write-heavy, and which are frequently joined together. This analysis helps you group entities into logical service boundaries. 📊
Step 2: Define Bounded Contexts
Group the entities based on business domains rather than technical dependencies. For example, a Product Catalog is different from a Inventory Management system, even if they both use the ProductID field. Ensure that the boundaries align with team structures (Conway’s Law).
Step 3: Implement Database Per Service
Create a new database instance for each service. Migrate the relevant data from the monolithic database. You do not need to move everything immediately. Start with the core data required for the service to function. 🏗️
Step 4: Replace Joins with API Calls
Refactor your queries. Instead of JOIN Orders, Customers, your code should call the Customer API to fetch details. This might introduce latency, so consider caching strategies or denormalization where appropriate.
Step 5: Introduce Event Streams
For real-time updates, implement an event bus. When an entity changes in one service, publish an event. Other services can subscribe to these events to update their local copies of the data. This ensures eventual consistency without direct coupling.
Common Pitfalls During Migration ⚠️
Even with a plan, teams often stumble during the transition. Be aware of these common issues.
- premature splitting: Do not split services before you understand the data flow. Splitting too early can lead to distributed complexity before you are ready.
- Ignoring Data Ownership: If multiple teams claim ownership of the same data entity, conflicts will arise. Assign clear ownership to each service.
- Over-normalization: In a distributed system, denormalization is often preferred to reduce the number of API calls required to render a page.
- Network Reliance: Never assume the network is perfect. Implement timeouts, retries, and circuit breakers for service-to-service communication.
Organizational Alignment 🤝
Data architecture is not just technical; it is organizational. A distributed data model requires teams to communicate differently. In a monolith, developers talk over a shared whiteboard (the database). In microservices, they talk over the API contract.
Ensure that your teams are empowered to change their database schema without consulting a central governance board. This autonomy is the only way to maintain the speed of independent deployment. If you introduce a central team that approves all schema changes, you reintroduce the bottleneck you tried to remove. 👥
Final Considerations for Data Strategy 🧭
Moving away from a traditional Entity Relationship Diagram is a significant step. It requires a shift in mindset from data integrity through constraints to data integrity through application logic and events. The ERD is a tool for relational databases, not a blueprint for distributed systems.
By adopting the Database Per Service pattern, utilizing event-driven architecture, and focusing on bounded contexts, you can avoid the coupling that slows down your migration. The goal is not to destroy your existing data model, but to evolve it into a structure that supports independent scaling and resilience.
Remember that consistency is a spectrum. You do not need strong consistency everywhere. Identify which parts of your system require strict accuracy and which can tolerate eventual consistency. This pragmatism will save you from over-engineering your solution.
Start by auditing your current diagrams. Identify the joins that cross service boundaries. Plan the migration of those specific entities. Take small steps. Verify the results. And always keep the business domain at the center of your data design. 🎯
Key Takeaways 📝
- Avoid shared databases between services to prevent coupling.
- Use API composition instead of SQL joins for cross-service data.
- Accept eventual consistency to gain availability and partition tolerance.
- Visualize data using Context Maps rather than global ERDs.
- Assign clear data ownership to individual service teams.
- Plan for data duplication as a performance optimization.
By following these principles, you can navigate the complexities of data migration without letting your ERD dictate the limitations of your new architecture. The path forward is distributed, decentralized, and designed for scale. 🚀