











As systems grow in complexity, the stability of the underlying data structures becomes the bedrock of operational reliability. One of the most persistent challenges faced by engineering teams is schema drift. This phenomenon occurs when the database schema diverges from the expected design, leading to inconsistencies, broken queries, and unpredictable application behavior. While often treated as a database administration issue, the root cause frequently lies in how the Entity Relationship Diagram (ERD) is architected and governed from the start.
A well-structured ERD does more than visualize relationships; it acts as a contract between the application logic and the data storage layer. In scalable environments where multiple services interact with shared data, this contract must be rigid yet flexible enough to accommodate growth. This guide explores the architectural patterns and methodologies that stabilize data models and prevent schema drift before it impacts production.
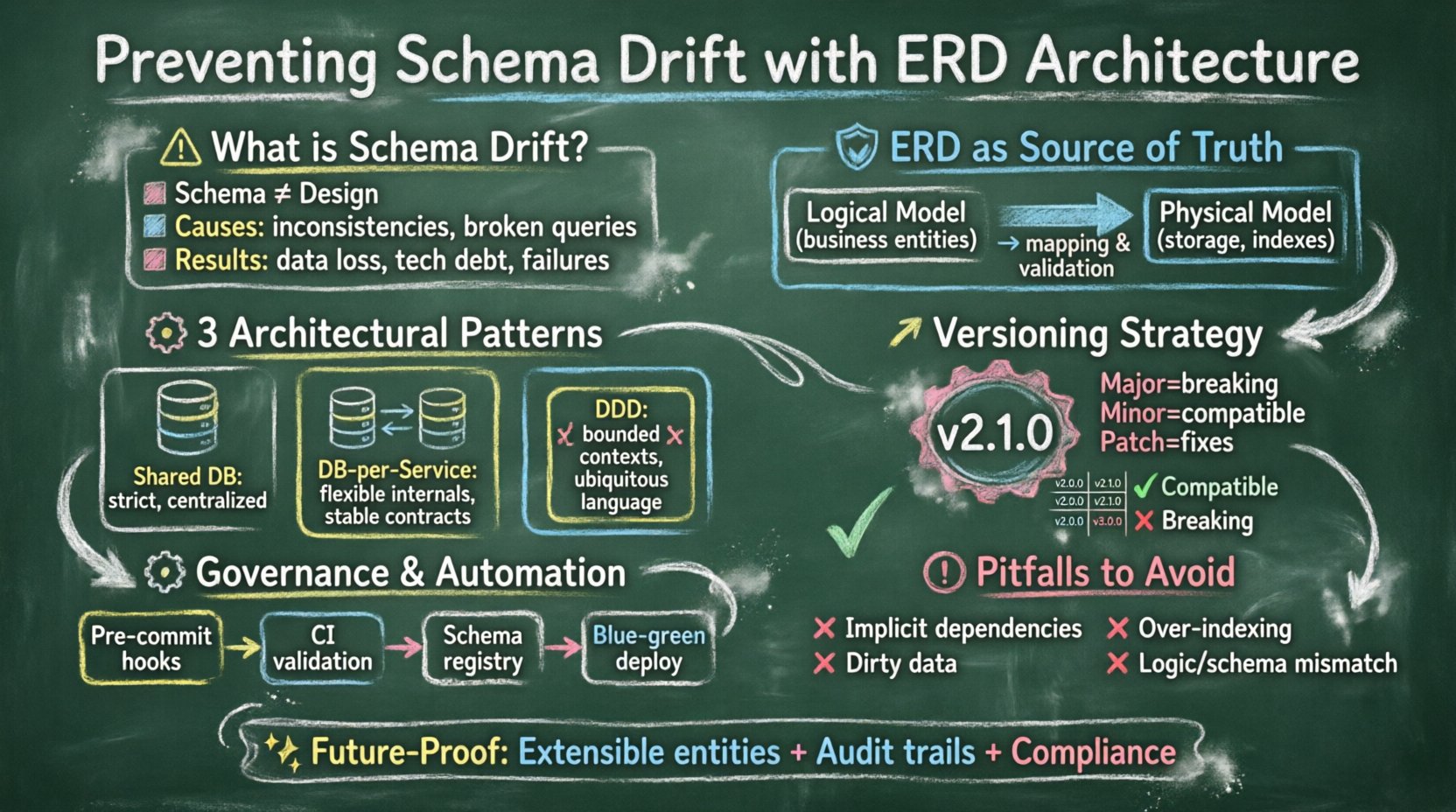
📉 Understanding Schema Drift in Distributed Environments
Schema drift is not merely a matter of forgetting to update a table. It is a systemic issue where the physical implementation of the data model diverges from its logical definition over time. In monolithic systems, this might manifest as a few forgotten columns. In distributed, microservices architectures, it can lead to race conditions where Service A writes data in a format Service B cannot read.
The consequences of unchecked drift include:
- Data Integrity Loss: Constraints are bypassed, allowing invalid states.
- Increased Technical Debt: Developers spend more time debugging data issues than building features.
- Service Breakdowns: APIs fail when expecting specific field types or existence.
- Migration Complexity: Catching up becomes harder as the gap widens.
Preventing this requires an architectural approach to the ERD that enforces consistency without stifling agility. It involves defining rules for change, versioning the data model, and establishing governance around the diagram itself.
🛡️ The Foundation: ERD as a Source of Truth
The first step in preventing drift is elevating the Entity Relationship Diagram from a static drawing to a living document that drives implementation. When the ERD is treated as a secondary artifact, drift becomes inevitable. When it is treated as the primary source of truth, the architecture supports stability.
1. Logical vs. Physical Separation
To maintain flexibility while ensuring stability, separate the logical data model from the physical implementation. The logical ERD should describe business entities and their relationships without technical constraints. The physical ERD handles indexing, partitioning, and specific storage types.
This separation allows the business logic to evolve without forcing immediate physical changes. It creates a buffer zone where changes can be validated against business requirements before impacting the storage layer.
2. Canonical Data Models
In scalable systems, multiple services often need to understand the same data. Establishing a canonical data model ensures that all services reference the same definitions. The ERD defines these canonical entities.
- Single Source of Truth: The ERD defines the exact schema for critical entities like User, Order, or Inventory.
- Service Contracts: Services consume data based on the ERD definition, not ad-hoc queries.
- Standardized Naming: Naming conventions defined in the ERD prevent ambiguity across different database instances.
🧩 Architectural Patterns for ERD Stability
Different system architectures require different ERD strategies. The following patterns help maintain consistency as the system scales.
1. The Shared Database Pattern
In some monolithic or tightly coupled systems, a shared database is used. Here, the ERD must be extremely strict. Changes to the ERD require coordination across all modules accessing that database.
- Centralized Schema Management: A single team owns the ERD updates.
- Strict Access Control: Only authorized scripts can alter the schema.
- Dependency Tracking: The ERD must map dependencies between tables clearly to identify impact before changes.
2. The Database Per Service Pattern
In microservices architectures, each service owns its data. This reduces direct coupling but introduces the risk of inconsistent data definitions across services. The ERD architecture here focuses on the interface between services rather than the internal storage of each.
- Internal Flexibility: Each service can evolve its internal schema as long as the external interface remains stable.
- External Contracts: The ERD defines the shared contracts. If Service A needs data from Service B, the ERD defines the expected structure.
- Event Sourcing: The ERD can define the events that carry data, ensuring immutability and traceability.
3. The Domain-Driven Design (DDD) Approach
Domain-Driven Design aligns the database schema with business domains. The ERD is broken down by bounded contexts. This prevents the “God Table” problem where unrelated entities are forced into one schema.
- Context Mapping: The ERD maps relationships between bounded contexts.
- Ubiquitous Language: Entity names in the ERD match the business terminology.
- Encapsulation: Internal entities are hidden; only the domain boundary is exposed.
🔄 Versioning Strategies for Schema Evolution
Change is inevitable. The goal is to manage it without breaking existing consumers. Versioning the schema within the ERD architecture is critical.
1. Semantic Versioning for Schemas
Just as software code uses semantic versioning, data schemas should too. A schema version can be denoted as Major.Minor.Patch.
- Major: Breaking changes (e.g., removing a column, changing a type).
- Minor: Backward-compatible additions (e.g., adding a nullable column).
- Patch: Internal fixes or optimizations that do not affect the API.
2. Backward Compatibility Rules
To prevent drift, adhere to strict rules regarding how the schema evolves. The following table outlines safe vs. unsafe changes.
| Action | Compatibility | Requirement |
|---|---|---|
| Add New Column | Backward Compatible | Must allow NULLs initially |
| Add New Table | Backward Compatible | Ensure no foreign key dependencies initially |
| Drop Column | Breaking Change | Deprecate first, then remove later |
| Change Data Type | Breaking Change | Requires full migration plan |
| Add Foreign Key | Conditional | Ensure existing data meets constraint |
3. Dual Write Patterns
When a schema change is required, avoid immediate cutover. Implement a dual write strategy where data is written to both the old and new structures. Over time, traffic is shifted to the new structure. The ERD should document both versions during this transition.
- Read Path: Continue reading from the stable schema.
- Write Path: Write to both schemas simultaneously.
- Validation: Monitor data consistency between the two schemas.
- Cutover: Once verified, stop writing to the old schema.
⚙️ Migration Management and Governance
Even with versioning, migrations are necessary. The architecture must support safe, reversible, and automated migrations.
1. Migration Scripts as Code
Migrations should be versioned alongside application code. The ERD serves as the target state for these scripts. Each migration file should reference the specific ERD version it implements.
- Idempotency: Scripts should be safe to run multiple times.
- Rollback Capability: Every upgrade must have a corresponding downgrade script.
- Atomicity: Changes should be transactional where possible to prevent partial updates.
2. Schema Registry
Implement a schema registry to track the state of the ERD across environments. This ensures that the development, staging, and production environments are aligned.
- Environment Parity: Prevents drift between dev and prod.
- Approval Workflows: Schema changes require review before promotion.
- Validation: Automated checks ensure the deployed schema matches the registered ERD.
3. Documentation as Code
Documentation should be generated from the ERD itself. This ensures that diagrams and text descriptions remain synchronized. Manual documentation often becomes outdated quickly.
- Automated Generation: Tools can generate documentation from the ERD file.
- Living Documents: Documentation updates are part of the code review process.
- Contextual Notes: Include business logic notes directly in the ERD metadata.
📝 Automation and CI/CD Integration
Human error is a primary cause of schema drift. Automation reduces this risk by enforcing rules during the deployment pipeline.
1. Pre-Commit Hooks
Implement hooks that validate schema changes before they are committed to the repository. These hooks check for breaking changes against the current ERD definition.
- Linting: Enforce naming conventions and structure rules.
- Validation: Ensure new constraints do not conflict with existing data.
- Review: Require manual approval for high-risk changes.
2. Continuous Integration Checks
During the CI process, run schema validation against a test database. This catches issues before deployment.
- Sandbox Environments: Deploy to a temporary environment to test migrations.
- Integration Tests: Run queries that rely on the schema to ensure functionality.
- Performance Checks: Ensure new indexes do not degrade write performance.
3. Blue-Green Deployments for Data
Similar to application deployments, use blue-green strategies for data. Maintain two versions of the schema in parallel until the new version is stable.
- Zero Downtime: Users are not affected by schema changes.
- Instant Rollback: If issues arise, switch back to the previous schema version.
- Data Synchronization: Ensure data is consistent between both versions during the transition.
🚨 Common Pitfalls to Avoid
Even with a solid architecture, teams often fall into traps that reintroduce drift. Awareness of these pitfalls is essential for long-term stability.
1. Implicit Dependencies
Code often relies on data structures that are not explicitly defined in the ERD. Hardcoded column names or assumptions about data presence lead to silent failures.
- Explicit Typing: Use strong typing in all data access layers.
- Interface Contracts: Define clear interfaces for data access.
- Refactoring: Regularly audit code for implicit assumptions.
2. Ignoring Data Quality
A schema can be perfect, but if the data entering it is dirty, the system fails. The ERD should include constraints that enforce data quality.
- Check Constraints: Validate values at the database level.
- Unique Constraints: Prevent duplicate entries.
- Not Null Constraints: Ensure required fields are always populated.
3. Over-Indexing
Adding indexes to solve read performance often slows down writes. This can lead to schema changes that disrupt the write path.
- Measure First: Monitor query performance before adding indexes.
- Review Regularly: Remove unused indexes to reduce overhead.
- Balance: Find the right balance between read and write performance.
4. Decoupling Logic from Schema
Applying business logic in the application layer that should be in the database leads to inconsistency. The ERD should guide where logic resides.
- Database Constraints: Move logic to triggers or stored procedures where appropriate.
- Validation: Ensure application logic does not bypass database rules.
- Clarity: Document where logic resides in the ERD notes.
🔮 Future-Proofing the Data Model
Scalable systems must be ready for the future. The ERD architecture should anticipate growth and change.
1. Extensibility
Design entities to be extensible. Use flexible data types or JSON columns for attributes that may vary, while keeping core structure rigid.
- Attribute Sets: Store variable attributes in a structured map.
- Tags and Labels: Use key-value pairs for dynamic metadata.
- Version Fields: Include version numbers in entities to track changes.
2. Audit Trails
Every change to the data should be traceable. The ERD should include audit tables to log who changed what and when.
- History Tables: Maintain a history of record changes.
- Change Logs: Log schema changes separately from data changes.
- Access Logs: Track who queries sensitive data.
3. Compliance and Security
Data models must adhere to regulatory requirements. The ERD should define where sensitive data is stored and how it is protected.
- Encryption: Mark fields that require encryption.
- Retention Policies: Define how long data is kept in the schema.
- Access Control: Define roles that can access specific entities.
🏁 Final Thoughts on Architectural Integrity
Preventing schema drift is not about restricting change; it is about managing it with discipline. By treating the Entity Relationship Diagram as a central architectural artifact, teams can build systems that are both robust and adaptable. The key lies in the separation of concerns, strict versioning, and automated governance.
When the ERD is respected, the data model becomes a stable foundation upon which scalable applications can be built. This reduces the cognitive load on developers, minimizes operational risks, and ensures that the system remains maintainable as it grows. The architecture of the diagram dictates the stability of the data, and in turn, the stability of the business.
Adopting these patterns requires an initial investment in process and tooling. However, the long-term return is a system that evolves gracefully without the constant burden of fixing broken data contracts. Prioritize the integrity of the data model, and the system will follow.