











Проектирование моделей данных для современной инфраструктуры требует фундаментального изменения мышления. Традиционные диаграммы отношений сущностей (ERD) хорошо подходили для монолитных архитектур, где единственный экземпляр базы данных управлял всеми транзакциями. Однако по мере того, как системы эволюционируют в распределённые среды, правила целостности данных и сопоставления отношений значительно меняются. В этом руководстве рассматриваются продвинутые шаблоны ERD, специально адаптированные для сложных распределённых систем транзакций. Мы изучим, как моделировать согласованность, управлять состоянием между сервисами и визуализировать зависимости без привязки к конкретным программным продуктам.
В распределённой среде граница между владением данными становится нечёткой. Сущность может существовать в нескольких логических хранилищах, что требует чёткого определения способа поддержания отношений. В этом документе предлагается структурированный подход к моделированию этих сложностей.
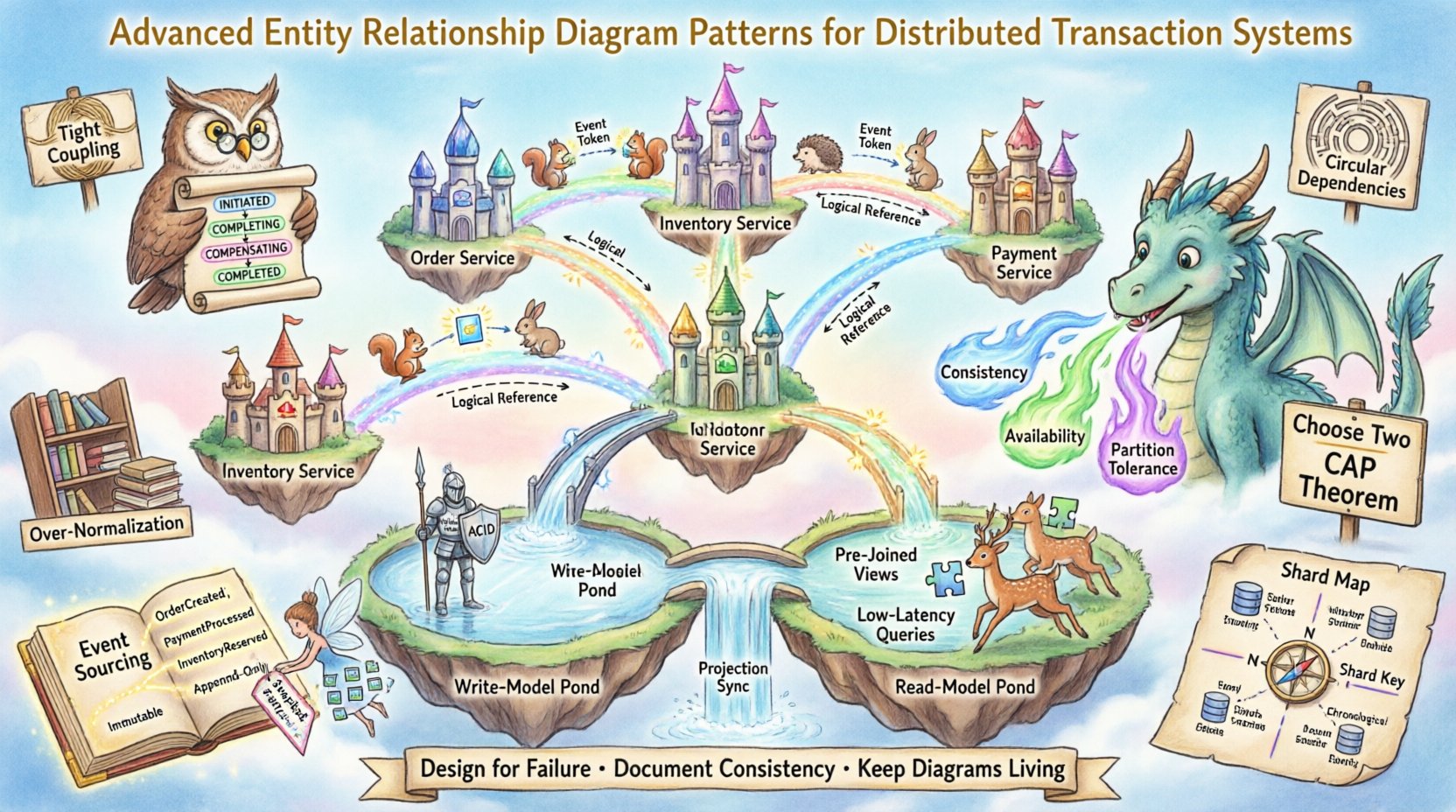
🧠 Влияние распределённой архитектуры на моделирование данных
Прежде чем приступать к изучению конкретных шаблонов, необходимо понимать ограничения, накладываемые сетевыми границами. В монолитной системе ограничение внешнего ключа гарантирует целостность ссылок. В распределённой системе сетевая задержка и возможные разделения сети делают немедленную согласованность часто невозможной или чрезвычайно дорогой.
- Сетевые разделения: Теорема CAP утверждает, что при сетевом разделении необходимо выбирать между согласованностью и доступностью.
- Владение данными: Сервисы должны владеть своими данными, чтобы избежать тесной связанности. Это ограничивает прямые отношения внешнего ключа через границы сервисов.
- Границы транзакций: Глобальные транзакции, охватывающие несколько баз данных, в целом не рекомендуются из-за рисков производительности и надёжности.
При создании ERD для этой среды диаграмма должна отражать логические отношения, а не только физические ограничения. Визуальное представление должно сообщать, где хранятся данные и как они синхронизируются.
🔗 Управление целостностью ссылок без внешних ключей
В распределённой системе транзакций физические внешние ключи часто отсутствуют. Вместо этого логические отношения обеспечиваются с помощью логики приложения или асинхронных событий. ERD должна чётко отображать эти логические связи.
1. Логические ссылки на идентификаторы
Вместо физического ограничения ключа модели используют уникальные идентификаторы. При построении диаграммы следует указать, что отношение является логической ссылкой.
- Используйте штриховые линии для представления логических зависимостей.
- Обозначьте отношение как «Ссылка», а не «Ограничение».
- Укажите тип данных идентификатора, чтобы обеспечить безопасность типов в схеме.
2. Мягкая ссылка
Жёсткое удаление опасно в распределённых системах. Распространённый паттерн предполагает помечать записи как удалённые, а не удалять их. ERD должна включать поле состояния.
- Включите поле
is_activeилиstatusстолбец. - Документируйте жизненный цикл сущности в примечаниях к диаграмме.
- Уточните, как обрабатываются орфанные записи при событии удаления.
3. Моделирование постепенной согласованности
Когда данные реплицируются между сервисами, согласованность не наступает мгновенно. ERD должна визуализировать задержку репликации.
- Отметьте сущности, которые являются репликами только для чтения.
- Различайте «Источник истины» и «Кэшированную версию».
- Укажите механизм, используемый для синхронизации изменений (например, захват изменений данных).
⚡ Моделирование паттерна Сага
Паттерн Сага является фундаментом распределённых транзакций. Он управляет длительными операциями, разбивая транзакцию на последовательность локальных транзакций. Каждая локальная транзакция обновляет данные в конкретном сервисе и запускает следующий шаг.
1. Представление машин состояний
Поскольку Саги зависят от состояния, ERD должен явно моделировать переходы состояний процесса.
- Создайте сущность
SagaInstanceсущность. - Определите состояния, такие как
ИНИЦИИРОВАНО,ЗАВЕРШАЕТСЯ,КОМПЕНСИРУЕТСЯ, иЗАВЕРШЕНО. - Свяжите экземпляр Саги с конкретными бизнес-сущностями, которые он затрагивает.
2. Компенсирующие транзакции
Если шаг завершается неудачно, Сага должна откатить предыдущие шаги. Диаграмма должна показывать обратные связи.
- Документируйте компенсирующее действие для каждого шага.
- Убедитесь, что таблица
SagaLogтаблица фиксирует историю всех шагов. - Визуализируйте путь отката как отдельную линию связи.
3. Событийные триггеры
Саги часто управляются событиями. ERD должен показывать, как события запускают изменения состояния.
- Включите
Журнал событийтаблица. - Сопоставьте события с конкретными переходами состояний Саги.
- Укажите, какие службы потребляют какие события.
📊 Сравнение моделей согласованности
Понимание компромиссов между различными моделями согласованности крайне важно для точного проектирования ERD. В таблице ниже перечислены характеристики распространённых паттернов.
| Паттерн | Уровень согласованности | Сложность ERD | Лучшее применение |
|---|---|---|---|
| Двухфазный коммит | Сильная | Низкая | Внутренняя координация служб |
| Оркестрация Саги | Потенциальная | Высокая | Долгосрочные бизнес-процессы |
| Хореография Саги | Потенциальная | Средняя | Слабосвязанные микросервисы |
| Модель чтения CQRS | Потенциальная | Средняя | Высокая нагрузка на чтение |
| Источник событий | Сильная (на уровне агрегата) | Высокая | Журналы аудита и восстановление состояния |
🔄 Разделение ответственности команд и запросов (CQRS)
CQRS разделяет модели чтения и записи. Это означает, что ERD для стороны записи будет значительно отличаться от ERD для стороны чтения.
1. Проектирование модели записи
Модель записи ориентирована на целостность данных и бизнес-правила.
- Нормализуйте данные, чтобы сократить избыточность.
- Применяйте строгие правила проверки при создании.
- Сохраняйте схему жесткой, чтобы предотвратить логические ошибки.
2. Проектирование модели чтения
Модель чтения ориентирована на производительность и скорость запросов.
- Денормализуйте данные, чтобы избежать соединений.
- Включите предварительно объединённые поля для часто используемых запросов.
- Структурируйте таблицы на основе требований интерфейса, а не логики.
3. Механизм синхронизации
ERD должен показывать, как модель записи обновляет модель чтения.
- Используйте сущности-проекции для отображения потока.
- Документируйте задержку между записью и доступностью чтения.
- Включите процесс согласования для компенсации рассогласования данных.
🗂️ Шардинг и ключи партиционирования
Масштабирование часто требует шардинга данных по нескольким узлам. ERD должен отражать, как данные распределяются, чтобы обеспечить эффективный запрос.
1. Определение ключа шардинга
Ключ шардинга определяет, на каком узле хранятся данные.
- Чётко отметьте ключ шардинга в определении сущности.
- Убедитесь, что ключ часто используется в запросах.
- Избегайте ключей, приводящих к неравномерному распределению данных.
2. Связи между шардами
Связи, охватывающие несколько шардов, являются дорогостоящими. ERD должен выделять такие связи.
- Используйте специальную нотацию для связей между шардами.
- Минимизируйте количество связей, пересекающих границы шардов.
- Рассмотрите денормализацию, чтобы избежать соединений между шардами.
3. Глобальные и локальные индексы
Стратегии индексации различаются в зависимости от модели шардирования.
- Локальные индексы эффективны для запросов к одному шарду.
- Глобальные индексы требуют сканирования всех шардов, что влияет на производительность.
- Документируйте, какие индексы локальные, а какие глобальные.
📜 Источник событий и неизменяемое состояние
Источник событий хранит состояние сущности в виде последовательности событий. Это меняет способ представления сущности в ERD.
1. Хранилище событий
Основная сущность становится журналом событий.
- Создайте
EventStreamтаблицу. - Храните метаданные, такие как
event_id,timestamp, иaggregate_id. - Убедитесь, что нагрузка хранится в виде структурированных данных.
2. Агрегаты
Агрегаты — это корневые сущности, которые инициируют события.
- Свяжите идентификатор агрегата с потоком событий.
- Не храните текущее состояние в виде столбца.
- Восстанавливайте состояние путем повторного воспроизведения событий из журнала.
3. Снимки
Для оптимизации производительности можно хранить снимки текущего состояния.
- Создайте
Snapshotтаблицу. - Свяжите снимок с идентификатором агрегата.
- Зафиксируйте номер версии для снимка.
🛡️ Распространённые ошибки и антипаттерны
Даже при использовании продвинутых паттернов ошибки могут возникать. Распознавание антипаттернов помогает поддерживать здоровье системы.
- Сильная связанность: Избегайте прямой ссылки на сущности из других сервисов. Используйте идентификаторы вместо этого.
- Циклические зависимости: Убедитесь, что сущность A не зависит от сущности B, если сущность B зависит от сущности A.
- Чрезмерная нормализация: В системах с высокой нагрузкой на чтение чрезмерная нормализация приводит к снижению производительности.
- Пренебрежение часовыми поясами: Распределённые системы работают по всему миру. Храните временные метки в формате UTC.
- Отсутствие идемпотентности: Убедитесь, что операции можно повторить без побочных эффектов.
🔄 Эволюция схемы и версионирование
Распределённые системы развиваются быстрее, чем монолиты. ERD должен поддерживать изменения схемы без нарушения существующих сервисов.
1. Обратная совместимость
Изменения в схеме не должны нарушать работу потребителей.
- Добавляйте только новые поля, никогда не удаляйте и не переименовывайте существующие сразу.
- Постепенно устаревайте поля с течением времени.
- Версионируйте контракты API вместе со схемой.
2. Стратегии миграции
Обработка миграции данных в продакшене требует внимания.
- Используйте паттерны расширения и сжатия при развертывании.
- Убедитесь, что старая схема остаётся читаемой во время перехода.
- Документируйте план отката при неудачной миграции.
🖼️ Визуализация межсервисных зависимостей
Стандартная ERD показывает таблицы в одной базе данных. Распределённая ERD должна показывать сервисы.
1. Границы сервисов
Группируйте таблицы по сервису, который их владеет.
- Используйте отдельные контейнеры для каждого сервиса.
- Обозначьте контейнер именем службы.
- Покажите поток данных между контейнерами с помощью стрелок.
2. Поток данных
Укажите, как данные перемещаются между службами.
- Используйте сплошные линии для синхронных вызовов.
- Используйте пунктирные линии для асинхронных событий.
- Обозначьте направление потока данных.
3. Точки интеграции
Определите, где службы взаимодействуют.
- Выделите шлюзы API на диаграмме.
- Обозначьте брокеры сообщений как посредников.
- Документируйте протокол, используемый для каждой интеграции.
🏁 Окончательные соображения для проектировщиков систем
Проектирование распределённых транзакций — это упражнение по управлению сложностью. ERD — это инструмент для передачи этой сложности команде. Он должен не просто показывать таблицы, а отображать логику системы.
- Сосредоточьтесь на логических связях, а не на физических ограничениях.
- Документируйте гарантии согласованности для каждой связи.
- Планируйте сценарии сбоев в модели данных.
- Поддерживайте диаграмму в актуальном состоянии по мере развития системы.
Следуя этим паттернам, вы создадите чертёж, поддерживающий высокую доступность и целостность данных. Диаграмма превращается в живой документ, который руководит разработкой и сопровождением.