











Na engenharia de software moderna, os sistemas raramente existem como entidades monolíticas. Eles são compostos por múltiplos serviços, processos e unidades de armazenamento que interagem além de fronteiras de rede. Compreender como as informações se movem entre essas unidades distintas é essencial para manter a integridade do sistema, diagnosticar falhas e planejar escalabilidade. Este guia explora o processo de mapeamento e visualização do fluxo de dados em arquiteturas distribuídas, utilizando especificamente o modelo C4 como estrutura estrutural.
Sem documentação clara, os sistemas distribuídos rapidamente se tornam caixas pretas. Engenheiros têm dificuldade para rastrear solicitações, identificar gargalos ou entender o impacto das mudanças. Visualizar o movimento dos dados traz clareza. Transforma lógicas abstratas em diagramas concretos que os interessados podem interpretar. Este documento descreve as metodologias para definir limites, mapear conexões e manter esses diagramas ao longo do tempo.
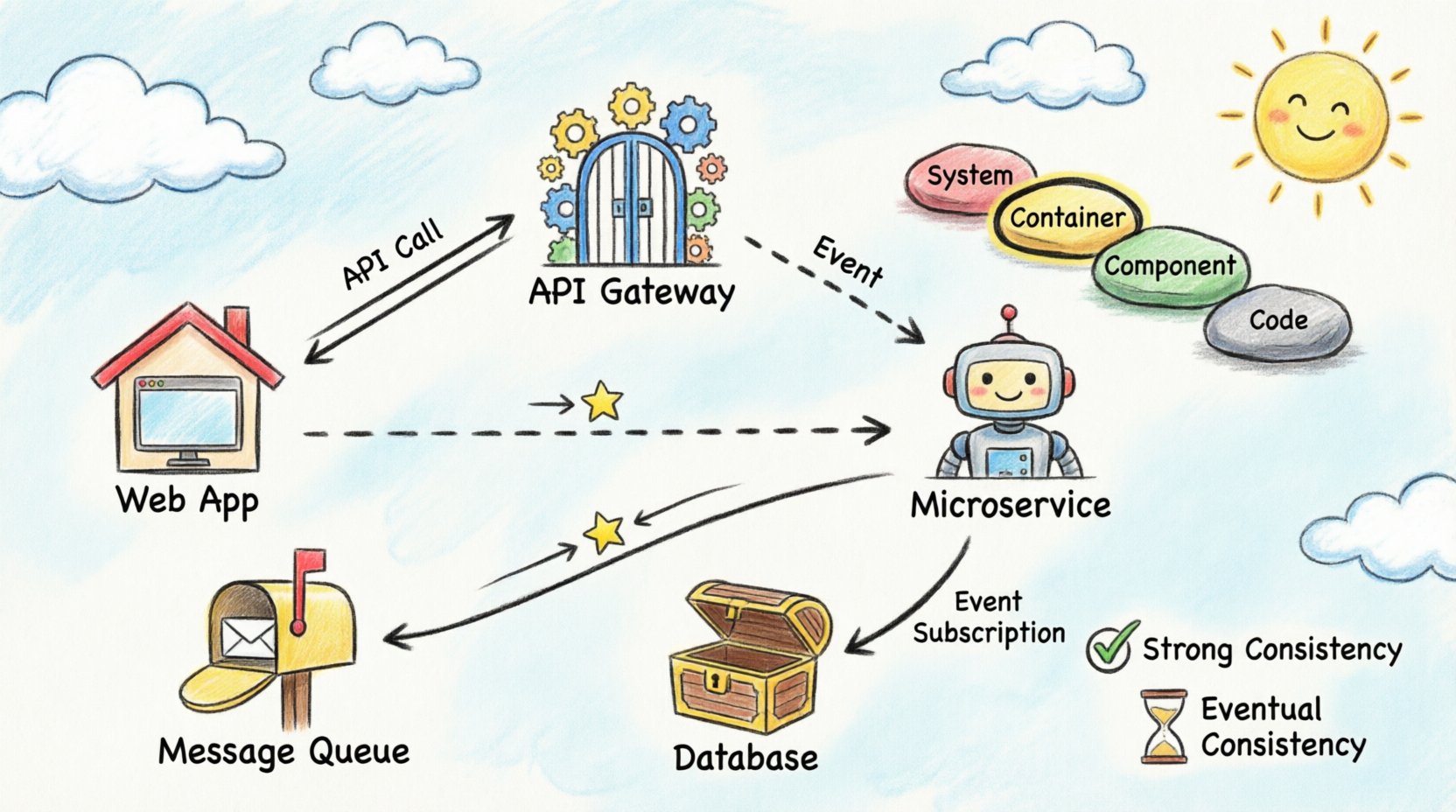
1. O Panorama da Arquitetura 🌍
Sistemas distribuídos introduzem complexidade que as aplicações monolíticas não enfrentam. Quando um único processo manipula toda a lógica, o fluxo de dados é interno e linear. Quando estão envolvidos múltiplos contêineres ou serviços, os dados percorrem redes, passam por firewalls e cruzam fronteiras de confiança. Cada salto introduz latência e pontos potenciais de falha.
Visualizar esse panorama exige uma abordagem padronizada. Diagramas improvisados frequentemente levam à inconsistência. Um engenheiro pode desenhar um banco de dados como um cilindro, enquanto outro usa um retângulo. A padronização garante que, ao visualizar um diagrama, seu significado seja imediatamente compreendido. O modelo C4 fornece essa padronização ao definir níveis específicos de abstração.
Desafios principais na visualização distribuída incluem:
- Latência de Rede:Visualizar onde os dados aguardam em filas ou redes.
- Consistência de Dados:Mostrar como o estado é sincronizado entre nós.
- Domínios de Falha:Identificar o que acontece se um contêiner deixar de responder.
- Fronteiras de Segurança:Indicar onde é necessário criptografia de dados ou autenticação.
2. Explicação do Modelo C4 📐
O modelo C4 é uma hierarquia de diagramas usada para descrever arquitetura de software. Ele consiste em quatro níveis, cada um atendendo a um público e propósito diferentes. Para a visualização do fluxo de dados entre contêineres, os níveis de Contêiner e Componente são os mais relevantes.
Nível 1: Contexto do Sistema
Esta visão de alto nível mostra o sistema como um único bloco e suas interações com usuários e sistemas externos. Responde à pergunta: “O que este sistema faz e quem o utiliza?” Embora útil para contexto, não mostra o fluxo interno de dados entre contêineres.
Nível 2: Contêineres
Este é o núcleo da visualização distribuída. Um contêiner representa uma unidade distinta de implantação. Exemplos incluem aplicações web, aplicativos móveis, microserviços e bancos de dados. Este nível ilustra como os dados fluem entre essas unidades. É o local ideal para mapear chamadas de API, filas de mensagens e conexões diretas com bancos de dados.
Nível 3: Componentes
Dentro de um contêiner, os componentes representam partes distintas do software. Este nível aprofunda a lógica, mostrando interações entre classes internas ou dependências de módulos. Embora importante, geralmente é muito detalhado para análises de fluxo de dados de alto nível.
Nível 4: Código
Este nível se refere a classes e métodos específicos. Geralmente é desnecessário para documentação de fluxo arquitetônico e é mais adequado para materiais de referência específicos para desenvolvedores.
3. Identificando Fronteiras de Contêineres 🚧
Antes de desenhar linhas de fluxo de dados, você deve definir o que constitui um contêiner. Um contêiner é uma unidade implantável. Ele possui um ciclo de vida independente dos outros contêineres. Pode rodar no mesmo servidor físico ou ser distribuído em diferentes regiões.
Tipos comuns de contêineres incluem:
- Aplicações Web:Interfaces de frontend acessadas por navegadores.
- Microserviços:Serviços de back-end que lidam com lógica de negócios específica.
- Gateways de API:Pontos de entrada que roteiam o tráfego para serviços internos.
- Armazenamentos de dados:Bancos de dados, caches ou sistemas de arquivos.
- Processos em lote:Tarefas agendadas que processam dados de forma assíncrona.
Ao definir limites, considere a estratégia de implantação. Se dois serviços forem sempre implantados juntos e compartilharem memória, podem fazer parte de um único contêiner. Se puderem ser dimensionados independentemente, devem ser contêineres separados. Essa decisão afeta como o fluxo de dados é visualizado.
4. Mapeamento de Padrões de Fluxo de Dados 📡
O fluxo de dados não é meramente uma linha que conecta duas caixas. Ele representa um padrão específico de interação. Compreender o padrão é crucial para uma visualização precisa. A tabela a seguir descreve padrões comuns e como eles devem ser representados.
| Padrão | Direção | Visibilidade | Caso de uso |
|---|---|---|---|
| Solicitação/Resposta Síncrona | Bidirecional (Cliente → Servidor → Cliente) | Imediata | Chamadas de API, envios de formulários |
| Disparo e esquecimento assíncrono | Unidirecional (Cliente → Servidor) | Diferida | Registro de logs, eventos de análise |
| Processamento baseado em busca | Unidirecional (Trabalhador ← Fila) | Sob demanda | Tarefas em segundo plano, ingestão de dados |
| Assinatura de evento | Unidirecional (Publicador → Assinante) | Disparado por evento | Notificações, mudanças de estado |
Comunicação Síncrona
Em fluxos síncronos, o remetente aguarda uma resposta. Isso é comum em interações de API. Ao visualizar isso, use linhas sólidas com pontas de seta indicando a solicitação e a resposta. Rotule o protocolo usado, como HTTP ou gRPC. Isso ajuda os engenheiros a entenderem a natureza bloqueante da interação.
Comunicação Assíncrona
Fluxos assíncronos desacoplam o remetente do receptor. O remetente coloca uma mensagem em uma fila e continua. O receptor processa a mensagem posteriormente. Visualize isso usando linhas tracejadas ou ícones distintos para representar o broker de mensagens. É fundamental indicar o nome da fila para distinguir entre diferentes fluxos de dados.
5. Tratamento de Sincronização e Consistência ⚖️
Uma das partes mais difíceis do fluxo de dados distribuído é o gerenciamento de estado. Quando os dados são gravados em um contêiner, eles se refletem imediatamente em outro? A visualização deve capturar esses requisitos de consistência.
Consistência Forte
Algumas sistemas exigem que todos os nós vejam os mesmos dados ao mesmo tempo. Isso frequentemente implica uma única fonte de verdade ou replicação síncrona. Nos diagramas, marque essas conexões com rótulos indicando “Consistência Forte” ou “ACID”. Isso alerta os interessados de que uma falha em uma parte do sistema pode afetar outras.
Consistência Eventual
Muitos sistemas distribuídos priorizam a disponibilidade em vez da consistência imediata. Os dados podem levar segundos ou minutos para se propagar. Visualize isso adicionando um indicador de tempo ou uma etiqueta “Sync” com uma notação de atraso. Isso gerencia as expectativas sobre quando os usuários verão informações atualizadas.
Contêineres Sem Estado vs. Com Estado
Contêineres sem estado não armazenam dados localmente. Eles dependem de bancos de dados externos ou caches. Contêineres com estado mantêm dados em seu próprio armazenamento. Ao mapear o fluxo, certifique-se de que o armazenamento externo esteja claramente separado do contêiner. Se um contêiner armazena dados, a linha de fluxo deve apontar para um ícone de armazenamento dentro ou conectado a esse contêiner.
6. Manutenção da Documentação 📝
Um diagrama só é útil se for preciso. Com o tempo, o código muda, novos serviços são adicionados e serviços obsoletos são removidos. Diagramas estáticos tornam-se obsoletos rapidamente. É necessário um plano de manutenção.
Melhores práticas para manter a documentação atual incluem:
- Geração Automatizada:Onde possível, gere diagramas a partir de anotações no código ou arquivos de configuração. Isso reduz o esforço manual e evita o desalinhamento entre código e documentação.
- Ciclos de Revisão:Inclua atualizações de diagramas na definição de conclusão para solicitações de pull. Se a interface de um serviço mudar, o diagrama também deve mudar.
- Versionamento:Trate diagramas de arquitetura como código. Armazene-os em sistemas de controle de versão para rastrear o histórico e permitir o retorno a uma versão anterior se uma alteração estiver incorreta.
- Padrões de Ferramentas:Use uma pilha de ferramentas consistente. Evite alternar entre diferentes plataformas de diagramação para diferentes equipes.
7. Armadilhas Comuns a Evitar 🛑
Mesmo com uma abordagem estruturada, erros podem ocorrer durante o processo de visualização. Estar ciente dos erros comuns ajuda a manter uma documentação de alta qualidade.
Superabstração
É tentador simplificar demais os diagramas. Se você agrupar dez serviços em uma única caixa rotulada como “Backend”, perde-se a capacidade de rastrear caminhos específicos de dados. Mantenha o nível de granularidade dos contêineres. Não funde unidades de implantação distintas, a menos que compartilhem exatamente o mesmo ciclo de vida.
Ignorar Caminhos de Falha
A maioria dos diagramas mostra o caminho feliz, onde tudo funciona. Uma visualização robusta também indica modos de falha. Para onde o fluxo vai se um serviço expirar? Existe um serviço de fallback? Existe uma fila de mensagens mortas? Adicionar esses caminhos torna o diagrama uma ferramenta para planejamento de resiliência.
Nomenclatura Inconsistente
Use a mesma terminologia para os serviços no diagrama que no código-fonte. Se um serviço é chamado de “Order-Service” no código, não o rotule como “Orders API” no diagrama. Isso gera confusão durante sessões de depuração.
Tipos de Dados Ausentes
Uma linha entre dois contêineres informa *que* os dados se movem, mas não *o que* está sendo movido. É útil anotar as linhas com o tipo de carga de dados. Por exemplo, “Carga JSON”, “Imagem Binária” ou “Lote CSV”. Isso informa aos engenheiros sobre a complexidade do processamento necessário na extremidade receptora.
8. Melhores Práticas para Manutenção e Crescimento 📈
À medida que o sistema cresce, o diagrama pode ficar cheio de elementos. Gerenciar a complexidade é uma tarefa contínua. Aqui estão estratégias para manter a visualização limpa e útil.
- Camadas:Use camadas diferentes para diferentes preocupações. Uma camada para segurança, outra para fluxo de dados e uma terceira para topologia de implantação. Evite desenhar todas essas camadas em uma única página.
- Links para Detalhes:Se um contêiner for complexo, crie um subdiagrama separado para ele. Link o diagrama principal à visualização detalhada em vez de desenhar todos os componentes na página de visão geral.
- Codificação por Cor:Use cores para indicar status ou criticidade. Vermelho para caminhos críticos, azul para fluxos padrão e cinza para conexões obsoletas. Isso permite uma verificação visual rápida da saúde do sistema.
- Metadados:Inclua a versão do diagrama e a data da última revisão no rodapé do documento. Isso fornece contexto sobre o quão atual a informação está.
9. Integração com Observabilidade 🔍
Diagramas estáticos são estáticos. Sistemas reais são dinâmicos. Arquiteturas modernas integram diagramas com plataformas de observabilidade. Isso significa que o diagrama não é apenas uma imagem, mas uma interface ativa.
Ao visualizar o fluxo de dados, considere como o diagrama se relaciona com os dados de monitoramento. Se você observar alta latência em uma conexão específica na ferramenta de monitoramento, o diagrama deve mostrar claramente essa conexão. Essa ligação ajuda na análise de causa raiz. Os engenheiros podem clicar em uma linha no diagrama e ver as métricas atuais para essa conexão.
Essa integração exige que o formato do diagrama suporte incorporação ou vinculação a fontes de dados externas. Certifique-se de que o método escolhido para diagramação permita essa flexibilidade sem exigir atualizações manuais toda vez que uma métrica mudar.
10. Resumo dos Pontos Principais ✅
Visualizar o fluxo de dados em sistemas distribuídos é uma disciplina que equilibra precisão técnica com legibilidade. Ao seguir o modelo C4, as equipes podem criar uma linguagem consistente para arquitetura. O nível de Contêiner fornece os detalhes necessários para entender as interações entre serviços sem sobrecarregar com complexidade.
Pontos-chave para lembrar:
- Defina Fronteiras Claramente:Garanta que os contêineres estejam alinhados com unidades de implantação.
- Mapeie Padrões Explicitamente:Distinga entre fluxos síncronos e assíncronos.
- Documente Modelos de Consistência:Indique como o estado é gerenciado entre fronteiras.
- Mantenha Rigorosamente:Trate os diagramas como documentos vivos que evoluem com o código.
- Evite Modas: Foque na clareza e na precisão, em vez de vender a arquitetura.
Ao seguir esses princípios, equipes de engenharia podem reduzir a carga cognitiva, acelerar a integração de novos membros e melhorar a confiabilidade geral de sua infraestrutura distribuída. O objetivo não é apenas traçar linhas, mas construir uma compreensão compartilhada sobre como o sistema funciona.