











複雑なソフトウェアシステムのアーキテクチャにおいて、明確さこそが成功のカギとなる。論理の1行も書かれる前に、情報の流れを理解しておく必要がある。ここがデータフローダイアグラム(DFD)が不可欠となるポイントである。DFDは、データがシステムにどのように入力され、どのように変換され、どこに保存され、どのように出力されるかを可視化する。これは、「何を」するかと「どのように」するかを分離する構造的な設計図である。コードが特定の実装細節を規定するのに対し、DFDは、全体のエコシステムにわたる情報の論理的流れに焦点を当てる。
多くのチームは、データの流れを明確に可視化せずにコーディングに急ぐ。その結果、スパゲッティコードになり、重複するデータベースクエリが発生し、ビジネスプロセスと整合しないインターフェースが生まれる。DFDの構築と解釈を習得することで、アーキテクトはシステムの基盤が意図された目的を支えることを確実にする。このガイドでは、抽象的な要件と具体的な実装の間のギャップを埋める効果的な図を描くためのメカニズム、ルール、ベストプラクティスを詳述する。
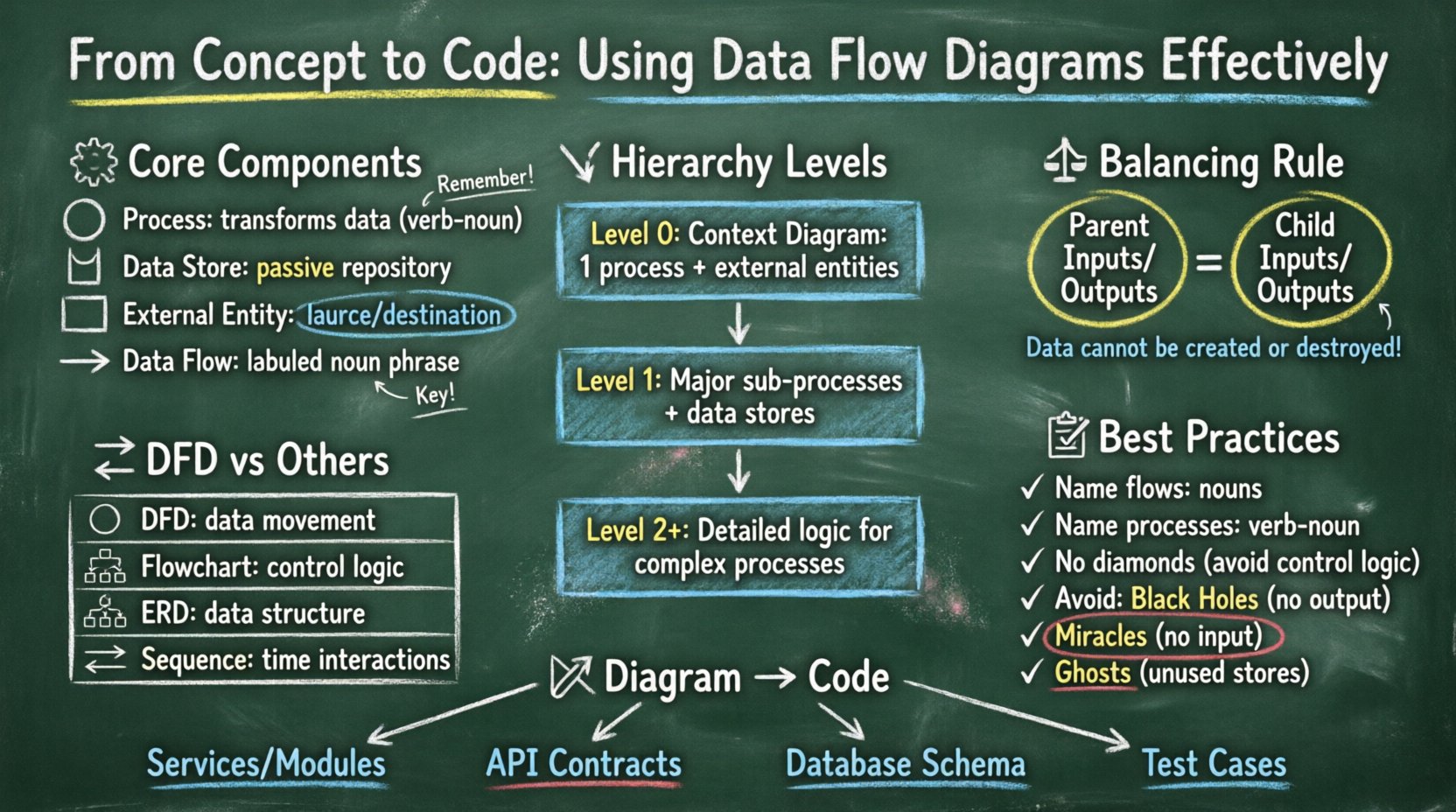
🧩 DFDの核心的な構成要素を理解する
データフローダイアグラムは、情報システム内を流れるデータの流れを図式化したものである。ループや判断分岐といった制御フローは示さず、むしろデータそのものに焦点を当てる。妥当な図を構築するためには、標準表記で用いられる4つの基本的な記号を理解する必要がある。
- プロセス:円またはラウンドされた長方形で表され、プロセスは入力データフローを出力データフローに変換する。これは変更、計算、集計を表す。プロセスは孤立して存在できない。少なくとも1つの入力と1つの出力を持つ必要がある。
- データストア:開口した長方形または平行線で表され、この記号はデータのリポジトリを表す。プロセスの間でデータが一時的に保管される受動的なストレージである。データベーステーブル、フラットファイル、またはメモリ内キャッシュなどが例である。
- 外部エンティティ:ターミネータとも呼ばれる。システムの境界外にあるデータの発生源または目的地を表す長方形である。ユーザー、別のシステム、または物理的なデバイスが該当する。
- データフロー:矢印付きの線で図示され、コンポーネント間のデータの移動を示す。これは物理的な信号ではなく、データそのものを表す。各フローには、内容を説明する意味のあるラベルを付ける必要がある。
これらの構成要素の違いを理解することは極めて重要である。たとえば、よくある誤りは、外部エンティティ同士を直接結ぶデータフローを描くことである。これにより、システムがデータを処理していないことになるが、これは分析の範囲を逸脱している。同様に、プロセスを経ずにデータストアを外部エンティティに直接接続すると、不正アクセスや制御の欠如を意味する。
📉 DFDのレベル階層
データフローダイアグラムは静的ではない。階層的である。これにより、システムを高レベルの概要から細部まで説明できる。この分解により、システムを扱いやすい部分に分割することで、複雑さを管理できる。分解には主に3つのレベルがある。
1. コンテキスト図(レベル0)
コンテキスト図は、最も高いレベルの抽象化を提供する。システム全体を1つのプロセスとして描き、外部エンティティとの相互作用を示す。この図は「システムとは何か?」という問いに答える。内部の詳細に巻き込まれず、すばやく概要を把握したいステークホルダーにとって有用である。
- 範囲:システム全体を表す1つの中心プロセス。
- エンティティ:すべての外部の発生源および目的地。
- フロー:主要なデータ入力および出力。
2. レベル1図
レベル1図は、コンテキスト図の単一プロセスを主要なサブプロセスに分解する。システム設計文書作成で最も一般的に使用されるレベルである。システムの主要な機能領域を明らかにする。ここで特定された各主要機能は、別個のプロセスノードとなる。
- 範囲:主要な機能モジュール。
- 相互作用:データがこれらのモジュールと外部エンティティの間を移動する。
- ストレージ:プライマリデータベースまたはファイルシステムが導入される。
3. レベル2以下
レベル2の図は、レベル1の図から特定のプロセスをさらに詳細に分解したものである。これは、重要な論理処理やデータ処理を伴う複雑なプロセスに限定される。このレベルでの過剰な分解は、読むことのできないほど大きな図を生じる可能性があるため、注意が必要である。通常、最も複雑な関数だけがこの深さを必要とする。
⚖️ バランスの原則
DFD構築における最も重要なルールの一つがバランスである。バランスは、親プロセスの入力と出力が、その子プロセスの入力と出力と一致することを保証する。親プロセスに「注文要求」という入力フローがある場合、子プロセスも「注文要求」を受け入れる(または論理的に合計して同じものになるサブセット)必要がある。
このルールに違反すると一貫性の欠如が生じる。子図を読んでいる開発者は、親図では決して発生しないとされている入力を見てしまう可能性がある。これにより実装エラーが発生する。プロセスを分解する際には、以下の点を確実に確認する必要がある。
- 親プロセスに入力されるすべてのデータフローは、子プロセスにも入力される。
- 子プロセスから出力されるすべてのデータフローは、親プロセスからも出力される。
- 親プロセスの範囲内で正当な理由がない限り、新しいデータフローを導入してはならない。
- 分解の過程で既存のフローが失われてはならない。
バランスをデータの保存則と考えてほしい。システムの境界内では、データは作成されもせず、破壊されもしない。あくまで変換されるだけである。この原則は、システムに入出力するすべてのデータについて、その理由を明確にしなければならないことをアーキテクトに求めている。
🔄 DFDと他の図示技術の比較
DFD、フローチャート、エンティティ関係図(ERD)の間に混乱が生じることが多い。これらはすべてシステムをモデル化するが、それぞれ目的が異なる。特定のタスクに適切でない図を用いると、設計意図が不明瞭になる。
| 図の種類 | 主な焦点 | 最も適している用途 |
|---|---|---|
| データフローダイアグラム(DFD) | データの論理的移動 | システム分析、システム境界の定義、データ変換 |
| フローチャート | 制御フローと論理 | アルゴリズム設計、意思決定経路、特定のプロセス論理 |
| エンティティ関係図(ERD) | データ構造と関係性 | データベーススキーマ設計、データモデリング、ストレージの正規化 |
| シーケンス図 | 時間経過に伴う相互作用 | API呼び出し、ユーザーのセッションフロー、時間的依存関係 |
例えば、ユーザー認証トークンの検証方法を定義する必要がある場合、フローチャートはパス/フェイルの論理を示すのに適している。そのトークンがどこに保存され、どこから取得されるかを定義する必要がある場合は、DFDがストアへのフローを示し、ERDがストレージテーブルのスキーマを示す。DFDは機能的なマップを提供するのに対し、他の図は構造的および論理的な詳細を提供する。
🛠 デザイン原則とベストプラクティス
図を描くことは、ボックスと矢印を描くことだけではありません。図が時間の経過とともに読みやすく正確な状態を保つためには、ルールに従う必要があります。これらの原則を守ることで、図がコードと一致しなくなるドキュメントのずれを防ぐことができます。
1. 名前付けのルール
ラベルは意味を伝えるテキストです。明確なラベルのないDFDは無意味です。すべてのデータフローには名詞句(例:「ユーザーID」、「トランザクションログ」)が必要です。すべてのプロセスには動詞句(例:「パスワードを検証する」、「請求書を生成する」)が必要です。この文法的な違いは、動作と内容の区別を明確にするのに役立ちます。
- プロセス名: 動詞+名詞の構造を使用する。単語だけの「プロセス」や「ロジック」のような表現は避ける。
- データフロー名: 情報パケットを説明する名詞句。
- データストア名: 複数形または単数形の名詞句で、コレクションを示す(例:「顧客記録」)。
2. コントロールロジックの回避
よくある落とし穴は、DFDにコントロールロジックを混入することです。DFDはデータの移動を記述するものであり、意思決定を記述するものではありません。「はい/いいえ」の分岐を示すダイアモンド型の図を描いてはいけません。意思決定が存在する場合は、データをフィルタリングするプロセスです。フローは、データがプロセスに入力され、特定のデータ型が出力される様子を示すべきです。たとえば、分岐ではなく、「承認済み注文」と「却下された注文」の2つのフローを「注文処理」ノードから出力するように表示します。
3. ブラックホールとミラクルの管理
システム分析では、特定の異常を避ける必要があります:
- ブラックホール: 入力はあるが、出力がないプロセス。データが消費され、結果が何も残らないことを意味します。
- ミラクル: 出力はあるが、入力がないプロセス。データが何からも生成されていることを意味します。
- ゴースト: データフローが接続されていないデータストア。使用されないストレージ場所があることを示します。
設計段階でこれらの異常を特定することで、後でのデバッグ時間の大幅な節約が可能になります。プロセスに出力がない場合、その入力に対してシステムは価値を提供していません。ストアに入力がない場合、それは空であり、無関係です。
🔗 図からコードへ:実装戦略
DFDが最終化されると、開発チームの契約書として機能します。この視覚的モデルを実行可能なコードに変換するには、体系的なアプローチが必要です。図はアーキテクチャ、データベーススキーマ、APIエンドポイントを決定する手がかりになります。
1. サービスとモジュールの特定
レベル1の図における各プロセスは、しばしばマイクロサービス、モジュール、またはクラスに対応します。たとえば、「税金を計算する」というプロセスは、請求モジュール内の専用関数になる可能性があります。「ユーザー情報の管理」というプロセスは、ユーザー・サービスに対応する可能性があります。このマッピングにより、コード構造がビジネスロジックを反映するようになります。
2. API契約の定義
外部エンティティとプロセスの間のデータフローは、しばしばAPIリクエストとレスポンスに変換されます。エンティティが「登録データ」をプロセスに送信する場合、対応するAPIエンドポイントはそのデータ構造に一致するペイロードを受け入れる必要があります。DFDがこれらのエンドポイントの入力および出力スキーマを決定します。これにより、フロントエンドとバックエンドチーム間での反復的な交渉の必要性が減少します。
3. データベーススキーマ設計
DFD内のデータストアは永続層を表します。DFDはフィールドやキーを示しませんが、どのデータを保存する必要があるかを特定します。「注文履歴」は注文用のテーブルまたはコレクションを意味します。「アクティブなセッション」はユーザー状態の保存場所を意味します。開発者はDFDを使って、どのテーブルが重要かを優先順位付けし、データストア間の関係が情報の流れと一致していることを確認できます。
4. 検証とテスト
テストケースはデータフローから直接導出できる。すべての矢印は潜在的なテストパスを表す。「注文を送信した場合、システムは請求書を返すか?」このトレーサビリティにより、コードのすべての行が初期設計で定義された目的を果たしていることが保証される。データフローに存在しないコードの追加を防ぐ「機能の拡大」を回避できる。
🛡 メンテナンスとドキュメントのライフサイクル
図は、その最新性に応じてしか価値を持たない。現在のシステムを反映していないDFDは技術的負債となる。新規開発者を誤導し、実際の論理を隠蔽する。したがって、メンテナンスは開発ライフサイクルの一部である。
- バージョン管理:DFDをコードのように扱う。システムに変更が加わったら、図も更新しなければならない。ソフトウェアリリースと一致するようにバージョンをタグ付けする。
- レビューのサイクル:コードレビューのプロセスにDFDの更新を含める。開発者が新しいデータフローを追加したら、図も更新しなければならない。
- アクセス性:図をコードと同じリポジトリまたはドキュメントシステムに保管する。これにより、チームがツールを切り替えた際に図が失われることを防げる。
- 簡略化:図が複雑になりすぎたら、分割を検討する。1ページに50のプロセスを含む図は読みにくい。モジュール化された図はメンテナンスが容易である。
図をコードベースと定期的に照合することで、不一致が明らかになる。コードに存在するが図にないデータストアは存在するか? 図に存在するがリファクタリングで削除されたプロセスは存在するか? これらのギャップを修正することで、システムドキュメントの整合性が保たれる。
🌟 メリットの要約
データフロー図に対して厳格なアプローチを実施すると、実質的な成果が得られる。チームが論理よりもデータについて考えるよう強制する。コードは理解できなくても、ビジネスプロセスを理解するステークホルダーにとって共通の言語を提供する。分析者、アーキテクト、開発者間のコミュニケーションの橋渡しとなる。
バランスの取り方、制御論理の回避、レベルの階層の維持といったルールに従うことで、正確かつ有用な図をチームは作成できる。概念からコードへの移行がスムーズになるのは、目的地が明確にマッピングされているからである。データフローは検証され、ストレージの必要性が正当化され、外部とのインタラクションが定義される。これにより再作業が減り、曖昧さが最小限に抑えられ、設計段階から堅牢なシステムが構築される。
コンテキスト図から始める。分解には注意を払う。フローをバランスさせる。ラベルは正確に保つ。そして、図は一度きりの成果物ではなく、常に更新される実体であることを忘れないでください。これらの実践を守ることで、現代のシステムの複雑さは管理可能になり、アイデアから実装への道筋は明確なまま保たれる。