











Pemodelan data adalah tulang punggung dari arsitektur basis data yang kuat. Meskipun teori ini sering diajarkan dalam mata kuliah di perguruan tinggi, penerapan praktisnya dalam lingkungan produksi mengungkapkan suatu kondisi yang penuh dengan kasus-kasus ekstrem, hambatan kinerja, dan ambiguitas logis. Diagram Hubungan Entitas (ERD) berfungsi sebagai gambaran rancangan sistem ini, namun sering kali menjadi sumber perdebatan ketika dunia nyata menolak untuk masuk dengan rapi ke dalam kotak dan garis.
Kami duduk bersama sekelompok Kepala Administrasi Basis Data dan Arsitek Data untuk menganalisis adegan-adegan yang terus-menerus membingungkan tim selama tahap perancangan. Ini bukan latihan teoritis; ini adalah masalah yang muncul ketika kebutuhan bisnis bertabrakan dengan keterbatasan penyimpanan fisik. Tujuan di sini bukan memberikan solusi cepat, tetapi memberikan pemahaman mendalam mengenai pertimbangan-pertimbangan yang terlibat.
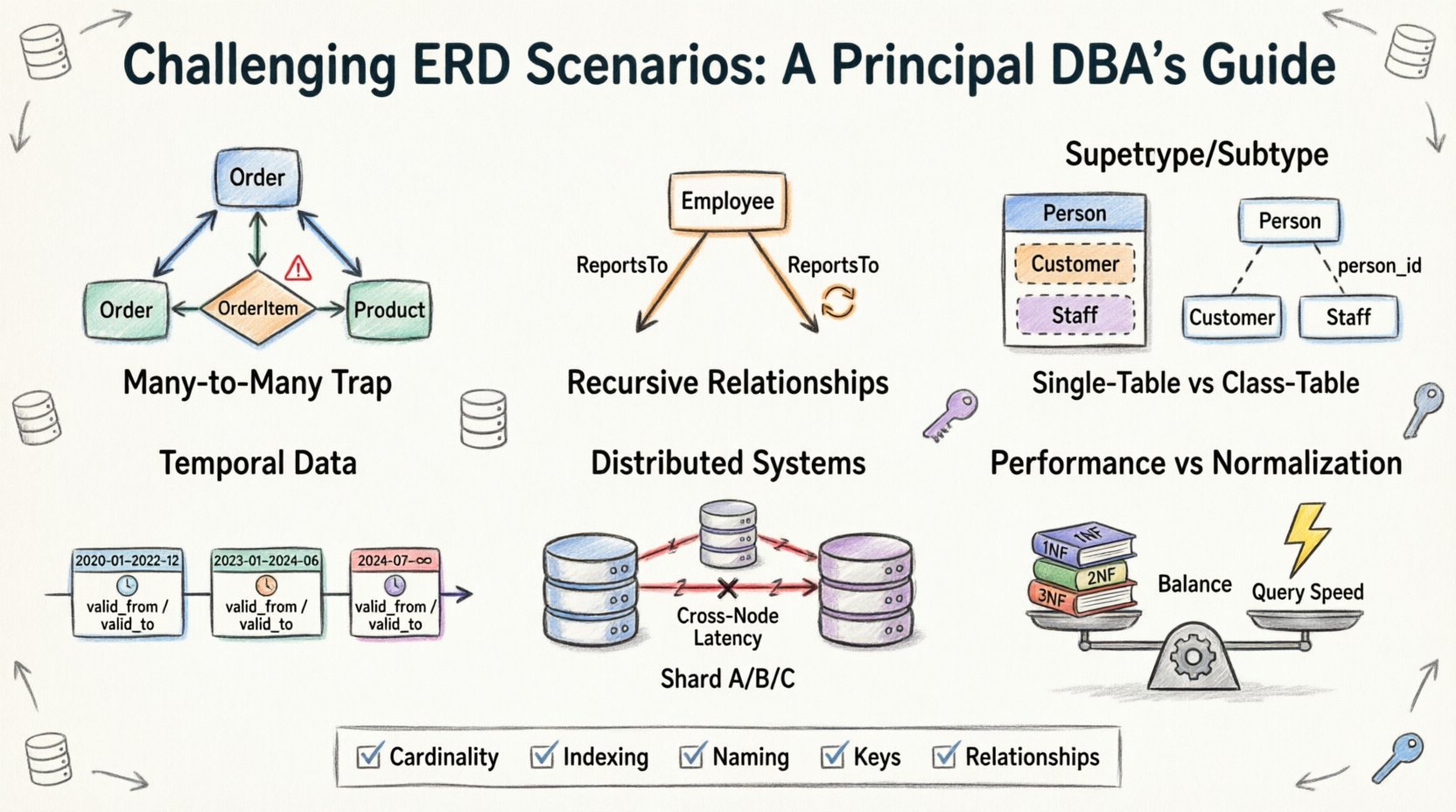
1. Jebakan Banyak-ke-Banyak: Di Luar Tabel Gabungan Sederhana 🕸️
Titik awal yang paling umum dalam perancangan ERD adalah hubungan Banyak-ke-Banyak. Ini terlihat intuitif: seorang Siswa dapat mendaftar di banyak Mata Kuliah, dan sebuah Mata Kuliah dapat memiliki banyak Siswa. Solusi standar melibatkan tabel jembatan atau tabel asosiatif. Namun, kompleksitas muncul ketika atribut dimasukkan langsung ke dalam hubungan itu sendiri.
- Masalahnya:Sering kali, tim mencoba menyimpan data pendaftaran (seperti nilai atau tanggal pendaftaran) di tabel Siswa atau Mata Kuliah utama, yang menyebabkan redundansi besar atau nilai kosong.
- Kenyataannya:Hubungan itu sendiri adalah entitas. Harus memiliki kunci utama sendiri dan kunci asing yang mengarah kembali ke induknya.
- Tantangannya:Menangani penghapusan yang terus-menerus (cascading deletes). Jika sebuah Mata Kuliah dihapus, apa yang terjadi pada catatan Pendaftaran? Jika Pendaftaran dihapus, apakah Siswa menghilang? Keputusan-keputusan ini menentukan integritas data.
Selama diskusi kami, seorang Kepala DBA mencatat bahwa tabel asosiatif sering menjadi titik pembatasan kinerja. Saat melakukan query data melintasi persilangan ini, mesin basis data harus melakukan operasi join yang dapat berkembang buruk seiring jumlah baris tumbuh hingga jutaan. Solusinya tidak selalu bersifat arsitektural; terkadang membutuhkan denormalisasi, tetapi hal ini menimbulkan anomali pembaruan.
Pertimbangan Kunci untuk Banyak-ke-Banyak:
- Apakah hubungan ini memiliki atribut yang memerlukan indeks?
- Apakah hubungan ini aktif atau historis? (misalnya, apakah pendaftaran saat ini berbeda dari yang lalu?)
- Bagaimana sistem akan menangani catatan yang terbengkalai jika induknya dihapus?
2. Hubungan Rekursif: Hierarki yang Mengacu pada Diri Sendiri 🌳
Data hierarkis ada di mana-mana. Bayangkan bagan organisasi, daftar bahan, atau percakapan komentar di forum. Memodelkan ini membutuhkan tabel yang merujuk pada dirinya sendiri. Meskipun secara konseptual sederhana, menerapkannya dalam skema relasional menimbulkan tantangan khusus terkait kedalaman dan penelusuran.
Masalah Struktural:
Anda membuat tabel dengan kunci utama dan kolom kunci asing yang mengarah kembali ke kunci utama tabel yang sama. Ini sering disebut kolom ‘parent_id’. Node akar memiliki induk yang bernilai kosong.
Masalah Kinerja:
Kueri SQL standar kesulitan dengan hierarki yang dalam. Jika Anda perlu mengambil manajer dan semua bawahan langsung maupun tidak langsungnya, JOIN sederhana tidak cukup. Anda memerlukan Common Table Expressions (CTE) rekursif atau prosedur penyimpanan yang berulang melalui tingkatan. Ini bisa sangat mahal secara komputasi.
Masalah Integritas:
Referensi melingkar adalah pembunuh yang sunyi. Jika Karyawan A mengelola Karyawan B, dan Karyawan B mengelola Karyawan A, Anda memiliki siklus. Basis data harus mencegah ini, atau logika aplikasi harus mendeteksinya. Dalam sistem besar, siklus dapat menyebabkan loop tak terbatas di alat pelaporan.
- Batas Kedalaman:Sebagian besar sistem membatasi kedalaman hierarki (misalnya, 32 tingkatan) untuk mencegah kesalahan overflow tumpukan saat melakukan penelusuran.
- Agregasi Jalur:Menghitung total biaya atau jumlah dari sebuah subpohon membutuhkan logika rekursif yang sulit dioptimalkan dalam rencana kueri standar.
3. Pemodelan Supertipe dan Subtipe: Dilema Pewarisan 🧬
Dalam pemrograman berorientasi objek, pewarisan adalah standar. Dalam basis data relasional, ini adalah pilihan desain yang memengaruhi penyimpanan dan pengambilan data. Pertanyaannya adalah: apakah Anda memodelkan Kendaraan sebagai satu tabel, atau membaginya menjadi Kendaraan, Mobil, dan Truk?
Opsi A: Pewarisan Tabel Tunggal
Semua atribut untuk semua tipe turunan berada dalam satu tabel. Nilai null digunakan untuk atribut yang tidak digunakan.
- Kelebihan:Kueri sederhana, tidak perlu join untuk menemukan kendaraan apa pun.
- Kekurangan:Tabel membengkak, sulit menerapkan batasan khusus tipe turunan, banyak kolom yang dapat bernilai null.
Opsi B: Pewarisan Tabel Kelas
Satu tabel untuk tipe induk (Kendaraan), dan tabel terpisah untuk tipe turunan (Mobil, Truk) yang terhubung melalui kunci utama.
- Kelebihan:Pemisahan yang bersih, tidak ada nilai null, batasan ketat per tipe turunan.
- Kekurangan:Pengambilan data membutuhkan penggabungan beberapa tabel, yang dapat memengaruhi kinerja baca.
Para DBA Utama kami menyoroti bahwa pilihan sering tergantung pada pola kueri. Jika Anda sering mengambil data dari tipe turunan tertentu, pendekatan Tabel Kelas lebih baik. Jika Anda sering menggabungkan semua tipe turunan, pendekatan Tabel Tunggal lebih unggul. ERD harus mencerminkan keputusan ini secara jelas agar tidak menimbulkan kebingungan bagi pengembang di masa depan.
4. Data Temporal: Melacak Perubahan Seiring Waktu ⏳
Aturan bisnis berubah. Seorang pelanggan pindah, harga diperbarui, kontrak berakhir. Menyimpan hanya status ‘saat ini’ sering kali tidak cukup untuk audit atau pelaporan. Hal ini mengarah pada desain tabel temporal atau Dimensi yang Berubah Perlahan (SCD).
Kompleksitas:
Alih-alih memperbarui baris, Anda menyisipkan baris baru dengan tanggal mulai dan berakhir yang berlaku. Baris lama ditandai sebagai tidak aktif. Ini menggandakan kebutuhan penyimpanan untuk data historis dan mempersulit kueri tampilan ‘saat ini’.
Tantangan Kueri:
Memilih data ‘pada saat’ titik waktu tertentu membutuhkan penyaringan berdasarkan rentang tanggal. Jika Anda melewatkan logika rentang tanggal, Anda mungkin mengembalikan versi yang salah dari suatu catatan. Ini sering menjadi tempat munculnya masalah integritas data dalam aplikasi keuangan.
- Desain Snapshot:Simpan status pada titik waktu tertentu. Membutuhkan pekerjaan batch berkala untuk menulis snapshot.
- Desain Log Transaksi:Tangkap setiap perubahan. Volume tulis tinggi, logika pengambilan data yang kompleks.
- Desain Periodik:Simpan interval yang valid. Menangani celah waktu dengan baik tetapi membutuhkan manajemen batas yang hati-hati.
5. Sistem Terdistribusi: Sharding dan Hubungan 🔗
Ketika satu basis data tidak dapat menampung data, sharding menjadi diperlukan. Di sinilah desain ERD menghadapi batasan fisik paling berat. Hubungan yang melintasi batas sharding sangat mahal.
Masalah Join:
Jika Tabel A dibagi berdasarkan ID Pengguna, dan Tabel B terhubung ke Tabel A, Tabel B harus dibagi berdasarkan ID Pengguna yang sama untuk menghindari join terdistribusi. Jika Tabel B dibagi berdasarkan hal lain, Anda harus mengarahkan kueri ke beberapa shard, menggabungkan hasilnya, dan melakukan join secara lokal.
Integritas Referensial:
Kendala kunci asing sulit diterapkan di antar node yang terdistribusi. Banyak sistem menonaktifkan kunci asing di lingkungan yang dibagi (sharded) untuk menjaga ketersediaan. Ini memindahkan beban integritas ke lapisan aplikasi, yang rentan terhadap kondisi persaingan (race conditions).
Poin-Poin Utama untuk ERD Terdistribusi:
- Hindari hubungan banyak-ke-banyak yang melintasi beberapa shard.
- Denormalisasi data untuk mengurangi kebutuhan akan operasi join lintas node.
- Rancang kunci partisi (kunci sharding) berdasarkan pola kueri yang paling sering digunakan, bukan hanya berdasarkan kunci utama.
6. Kinerja vs. Normalisasi: Keseimbangan Pertukaran ⚖️
Normalisasi (1NF, 2NF, 3NF) diajarkan sebagai standar emas untuk integritas data. Namun, dalam sistem dengan throughput tinggi, normalisasi yang ketat dapat menghancurkan kinerja. ERD harus menyeimbangkan keduanya.
Kapan saatnya melakukan denormalisasi:
- Beban Baca yang Berat: Jika Anda membaca data jauh lebih sering daripada menulisnya, menambahkan kolom yang redundan dapat menghemat operasi join.
- Persyaratan Pelaporan: Agregasi pada data yang dinormalisasi membutuhkan join yang kompleks yang memperlambat tampilan dashboard.
- Beberapa Beban Tulis yang Berat: Kadang-kadang, menjaga data terpisah dapat mengurangi persaingan kunci saat pembaruan.
Panel kami menekankan bahwa tidak ada skema yang “sempurna”. Ini adalah kompromi. ERD harus mencatat di mana denormalisasi terjadi dan mengapa, agar pemelihara masa depan memahami bahwa redundansi sengaja dibuat, bukan kesalahan.
Perbandingan Pola-Pola Pemodelan 📊
Untuk membantu dalam pengambilan keputusan, berikut ini ringkasan pola-pola pemodelan yang dibahas dan kasus penggunaan umumnya.
| Pola | Kasus Penggunaan Terbaik | Risiko Utama | Kompleksitas |
|---|---|---|---|
| Satu Tabel | Hierarki sederhana, variasi rendah | Kolom null, pembesaran skema | Rendah |
| Tabel Kelas | Subtipe ketat, atribut yang berbeda | Beban join | Sedang |
| Rekursif | Bagan organisasi, kategori | Kedalaman traversal, siklus | Tinggi |
| Entitas Asosiatif | Banyak-ke-Banyak dengan atribut | Kinerja join | Sedang |
| Temporal | Audit, pelacakan riwayat | Kompleksitas query | Tinggi |
| Pembagian Terdistribusi | Skala besar, pertumbuhan horizontal | Integritas referensial | Sangat Tinggi |
Daftar Periksa untuk Tinjauan ERD ✅
Sebelum menyelesaikan Diagram Hubungan Entitas, gunakan daftar periksa ini untuk menangkap kesalahan umum. Lebih baik menangkap masalah ini pada tahap desain daripada di produksi.
- Kardinalitas:Apakah Anda telah dengan jelas mendefinisikan hubungan Satu-ke-Satu, Satu-ke-Banyak, dan Banyak-ke-Banyak? Apakah batasan min/maks (0..1, 1..*) secara eksplisit dinyatakan?
- Jenis Data:Apakah jenis kolom sesuai dengan ukuran data yang diharapkan? (misalnya, menggunakan Integer vs. Varchar untuk ID).
- Kemungkinan Null:Apakah kunci asing dapat bernilai null? Jika ya, apakah logika menangani referensi yang terpisah secara baik?
- Strategi Pengindeksan:Apakah ERD menunjukkan kolom mana yang perlu diindeks untuk kinerja? Kunci asing sering diindeks untuk mempercepat join.
- Konvensi Penamaan:Apakah nama tabel dan kolom konsisten? Hindari singkatan yang mungkin menimbulkan ambiguitas di kemudian hari.
- Aturan Bisnis:Apakah kendala (misalnya, “Seorang pengguna tidak dapat memiliki dua langganan aktif”) diwakili sebagai pemeriksaan logis atau kendala basis data?
- Kemampuan Ekstensi:Apakah skema dapat menampung atribut baru tanpa memerlukan migrasi penuh? (misalnya, menggunakan pola EAV atau kolom JSON di tempat yang sesuai).
Pikiran Akhir tentang Pemodelan Data 🧠
Mendesain Diagram Hubungan Entitas bukan hanya tentang menggambar kotak dan garis. Ini tentang memahami aliran data, batasan perangkat keras, dan kebutuhan bisnis. Skenario yang dibahas di sini mewakili titik-titik gesekan di mana teori bertemu praktik.
Dengan memprediksi tantangan-tantangan ini—kedalaman rekursif, penggabungan terdistribusi, sejarah temporal, dan pertukaran warisan—Anda dapat membangun skema yang tangguh. ERD yang dirancang dengan baik mengurangi utang teknis dan mencegah kebutuhan untuk refaktor yang mahal di kemudian hari. Ini merupakan investasi dalam stabilitas seluruh sistem.
Ingatlah bahwa skema terbaik adalah yang berkembang bersama data. Dokumentasi sangat penting. Pastikan setiap penyimpangan dari normalisasi standar dijelaskan dan dicatat. Transparansi inilah yang membedakan arsitektur basis data yang kuat dari yang rapuh.