











Concevoir des systèmes qui gèrent les données est une tâche complexe. À mesure que les projets passent de petits scripts à des plateformes de niveau entreprise, la documentation décrivant le déplacement des informations à travers l’architecture doit évoluer. Les diagrammes de flux de données (DFD) servent de plans architecturaux pour ces systèmes. Ils cartographient le déplacement des données entre les processus, les magasins de données et les entités externes. Toutefois, un diagramme qui fonctionne pour une application simple s’effondre souvent sous le poids d’un projet à grande échelle. Mettre à l’échelle les DFD exige une approche rigoureuse de la hiérarchie, de la décomposition et de la maintenance. Ce guide explore les stratégies nécessaires pour maintenir la documentation du flux de données claire, précise et utile à mesure que la complexité augmente.
Le passage d’une portée réduite à un environnement à grande échelle introduit des défis qui ne peuvent pas être résolus en ajoutant simplement plus de cases et de flèches. Sans une méthodologie structurée, les diagrammes deviennent des toiles d’araignée illisibles. Cela entraîne de la confusion chez les parties prenantes, les développeurs et les architectes. Pour maintenir la clarté, les équipes doivent adopter des modèles spécifiques d’organisation. Nous examinerons les mécanismes de mise à l’échelle, du niveau de contexte initial jusqu’aux décompositions détaillées des processus. Nous aborderons également la gestion des magasins de données et des frontières externes sans perdre de vue le tableau d’ensemble.
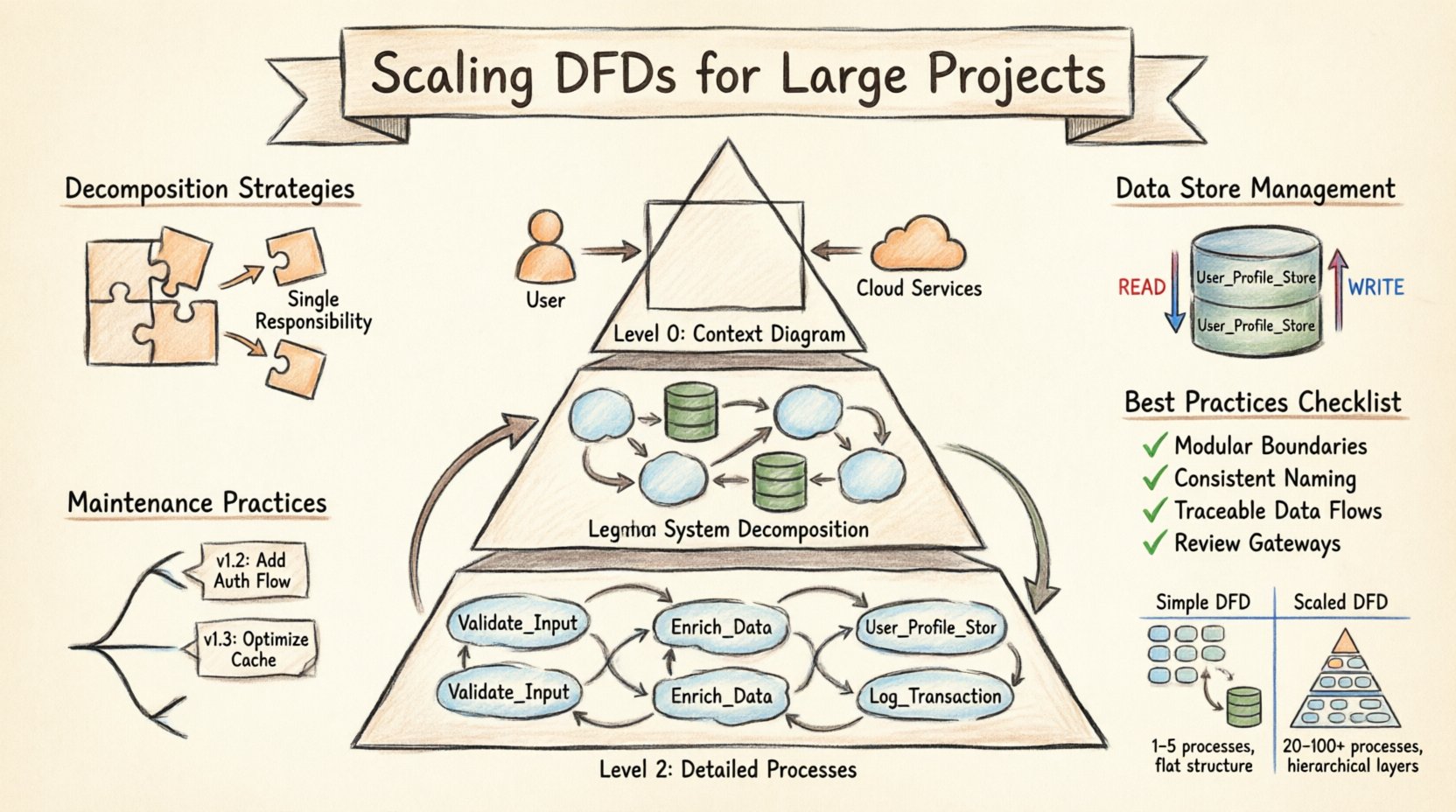
Comprendre la hiérarchie des DFD 📚
La base de la mise à l’échelle réside dans la structure hiérarchique du diagramme lui-même. Un seul diagramme plat est rarement suffisant pour les grands systèmes. En revanche, une approche multi-niveaux permet aux parties prenantes de visualiser le système à différents niveaux de détail. Cette méthode est souvent appelée structure de niveau 0, niveau 1, niveau 2. Chaque niveau s’adresse à un public spécifique et a un objectif précis.
- Niveau 0 (Diagramme de contexte) : Il s’agit de la vue la plus élevée. Elle représente l’ensemble du système comme un seul processus. Elle relie le système aux entités externes, telles que les utilisateurs, les services tiers ou le matériel. L’objectif ici est de définir la frontière du système ainsi que les entrées et sorties majeures. Il ne doit pas contenir de processus internes ni de magasins de données.
- Niveau 1 (Décomposition du système) : Ce niveau divise le processus unique du niveau 0 en sous-processus majeurs. Il introduit les magasins de données et montre comment les données circulent entre les grandes zones fonctionnelles. C’est ici que l’architecture centrale devient visible. Il est généralement utilisé par les architectes système et les développeurs seniors.
- Niveau 2 (Processus détaillés) : Chaque processus majeur du niveau 1 est développé dans un diagramme distinct. Ce niveau détaille la logique, les transformations spécifiques des données et les interactions avec les magasins de données. Il est utilisé par les implémenteurs et les testeurs qui doivent comprendre les mécanismes spécifiques d’une fonction.
Lors de la mise à l’échelle, la relation entre ces niveaux doit être maintenue rigoureusement. Chaque entrée et sortie sur un diagramme du niveau 0 doit être prise en compte au niveau 1. Chaque flux de données sortant d’un processus du niveau 1 doit être expliqué dans le diagramme correspondant du niveau 2. Cette cohérence empêche la perte d’information et garantit la traçabilité. Si un flux de données apparaît dans un diagramme de niveau inférieur mais pas dans un diagramme de niveau supérieur, cela indique une incohérence qui doit être résolue.
Stratégies de décomposition pour la complexité 🔨
La décomposition est l’acte de diviser des processus complexes en composants plus petits et gérables. Dans les projets à grande échelle, cela va au-delà de la simple simplification ; il s’agit de gérer la charge cognitive. Un processus qui gère trop de fonctions distinctes devient un goulot d’étranglement dans la compréhension. Une décomposition efficace suit des règles spécifiques pour garantir que le diagramme reste utile.
- Une fonction par processus : Chaque bulle ou boîte de processus doit représenter une seule transformation distincte des données. Si un processus gère à la fois la validation des données et le stockage des données, il doit être divisé. Cette séparation clarifie la responsabilité de chaque composant.
- Granularité cohérente : Bien que les niveaux varient en détail, la granularité au sein d’un même niveau doit être cohérente. Si un processus est très détaillé, les processus voisins ne doivent pas être des résumés vagues. Ce équilibre empêche le diagramme de devenir inégal et confus.
- Regroupement logique : Regrouper les processus liés visuellement ou selon des conventions de nommage. Cela aide le lecteur à identifier des domaines fonctionnels, tels que « Authentification », « Facturation » ou « Rapport ». Le regroupement logique réduit la nécessité de suivre des lignes à travers toute la page.
- Éviter les fuites entre les niveaux : Ne pas introduire des détails dans un diagramme de niveau supérieur qui appartiennent à un niveau inférieur. À l’inverse, ne pas omettre des magasins de données critiques dans un diagramme de niveau 1 qui sont essentiels à la compréhension de l’état du système.
Lors de la mise à l’échelle, il est courant de rencontrer des processus qui ne s’inscrivent pas facilement dans une seule catégorie. Dans ces cas, le processus peut nécessiter une division en flux parallèles ou être traité via une couche d’interface dédiée. L’objectif est de maintenir un flux linéaire et logique. Si un processus nécessite des données provenant de cinq sources différentes et envoie les résultats à trois destinations différentes, il est probablement trop complexe pour une seule boîte. Le diviser en étapes intermédiaires clarifie la séquence des opérations.
Gestion des magasins de données à grande échelle 🗄️
Les magasins de données représentent l’état persistant du système. Dans les petits projets, une seule base de données peut servir l’application entière. Dans les projets à grande échelle, les données sont réparties sur plusieurs systèmes, schémas et services. Cartographier ces magasins avec précision sur un DFD est crucial pour comprendre l’intégrité des données et les schémas d’accès.
- Nommage explicite : Ne pas étiqueter un magasin de données simplement par « Base de données ». Utilisez des noms précis tels que « Magasin_Profil_Utilisateur » ou « Journal_Transactions ». Cette précision aide les développeurs à identifier quel système contient quelles données.
- Flux de lecture vs. flux d’écriture : Indiquez où les données sont lues versus où elles sont écrites. Bien que les DFD montrent traditionnellement le flux de données sans directionnalité, la mise à l’échelle exige une clarté sur les changements d’état. Utilisez des notations ou des légendes distinctes pour indiquer si un processus met à jour un magasin ou ne fait que le consulter.
- Magasins de données partagés : Les grands systèmes partagent souvent des magasins de données entre les processus. Assurez-vous que le schéma reflète quels processus ont accès à quels magasins. Cela aide à identifier les problèmes éventuels de concurrence ou les vulnérabilités de sécurité.
- Relations entre les magasins de données : Si les données circulent d’un magasin à un autre, montrez-le explicitement. Cela pourrait indiquer un processus de réplication, un travail ETL ou une routine de synchronisation. Ces flux sont souvent négligés, mais ils sont essentiels pour la fiabilité du système.
À mesure que le nombre de magasins de données augmente, le schéma peut devenir encombré. Pour atténuer ce problème, envisagez l’utilisation de techniques de regroupement. Encadrez les magasins de données liés dans une limite représentant un sous-système spécifique. Cela réduit le bruit visuel tout en maintenant les connexions logiques. Toutefois, faites attention à ne pas masquer le flux de données entre ces groupes. Les connexions doivent rester visibles pour garantir que l’image globale soit bien comprise.
Frontières des entités externes 🌐
Les entités externes représentent les sources et les destinations des données situées en dehors des frontières du système. Il peut s’agir d’utilisateurs humains, d’autres systèmes logiciels, de systèmes hérités ou d’organismes régulateurs. Dans les projets à grande échelle, le nombre d’entités externes peut exploser. La gestion de ces frontières est essentielle pour définir le périmètre du projet.
- Définir des interfaces claires : Chaque connexion entre une entité externe et un processus représente une interface. Documentez le format et le protocole attendus pour ces interactions. Cela évite toute ambiguïté lors de l’intégration avec des systèmes tiers.
- Consolider les entités similaires : Si plusieurs utilisateurs effectuent la même fonction, représentez-les par une entité générique unique (par exemple, « Client »), accompagnée d’une note expliquant les variations de rôle. Cela réduit la redondance sans perdre de fonctionnalité.
- Implications en matière de sécurité : Les entités externes représentent souvent des frontières de sécurité. Les données provenant d’une entité externe vers le système peuvent nécessiter une authentification ou un chiffrement. Le schéma DFD devrait idéalement indiquer ces exigences de sécurité, soit dans le texte, soit à l’aide d’une légende.
- Systèmes hérités : Les grands projets interagissent souvent avec des systèmes hérités. Ces entités peuvent avoir des formats de données rigides. Cartographiez ces interactions avec soin pour garantir que le nouveau système puisse traiter les données correctement sans perturber les flux de travail existants.
Lorsqu’on élargit l’échelle, il est tentant d’ignorer les entités externes mineures. Toutefois, même de petites entrées peuvent avoir des effets significatifs en aval. Un changement dans la manière dont une entité mineure envoie des données peut se propager à travers l’ensemble du système. Par conséquent, toutes les entités doivent être prises en compte dans le schéma de contexte et suivies à travers les niveaux de décomposition.
Maintenance et contrôle de version 🔄
Un schéma DFD est un document vivant. Dans les projets à grande échelle, les exigences évoluent fréquemment. Des processus sont ajoutés, des magasins de données sont fusionnés, et des interfaces externes sont abandonnées. Sans une stratégie de maintenance solide, le schéma devient rapidement obsolète, entraînant un décalage entre la documentation et le code.
- Gestion des versions : Attribuez des numéros de version aux schémas. Cela permet aux équipes de suivre les modifications dans le temps. Si un bogue est signalé, vous pouvez référencer la version spécifique du schéma qui était en vigueur au moment où le code a été écrit.
- Journaux des modifications : Maintenez un journal distinct qui décrit les modifications apportées entre les versions. Incluez la date, l’auteur et la raison du changement. Cela fournit un contexte pour les développeurs futurs qui pourraient ne pas se souvenir pourquoi une décision a été prise.
- Cycles de revue : Planifiez des revues régulières des schémas DFD. Elles doivent coïncider avec les cycles de publication majeurs. Pendant ces revues, vérifiez que les schémas correspondent à l’implémentation actuelle. Mettez-les à jour immédiatement si des écarts sont détectés.
- Contrôle d’accès : Assurez-vous que seules les personnes autorisées peuvent modifier les schémas. Les modifications non contrôlées peuvent entraîner des conflits et de la confusion. Utilisez un système qui suit qui a effectué les modifications et quand.
La maintenance est souvent négligée au profit du développement. Toutefois, les schémas obsolètes sont plus dangereux que l’absence de schémas. Ils créent un faux sentiment de sécurité. Les équipes peuvent s’appuyer sur une documentation qui ne reflète pas la réalité. En traitant le schéma DFD comme du code, soumis aux mêmes processus de contrôle de version et de revue, les équipes peuvent garantir son exactitude.
Comparaison : schémas DFD échelonnés vs. simples 📊
Comprendre les différences entre un schéma DFD simple et un schéma DFD échelonné aide les équipes à se préparer à la transition. Le tableau ci-dessous décrit les principales différences en matière de structure, de complexité et de gestion.
| Fonctionnalité | Schéma DFD simple | DFD échelonnée |
|---|---|---|
| Nombre de processus | 1 à 5 | 20 à 100+ |
| Niveaux | 1 (Plat) | 3 à 5 (Hiérarchique) |
| Outils utilisés | Crayon et papier | Logiciels spécialisés de diagrammation |
| Contrôle de version | Manuel | Systèmes automatisés |
| Fréquence de revue | À la livraison | Par sprint/livraison |
| Détail des magasins de données | Général | Spécifique et nommé |
| Entités externes | Minimal | Complet et catégorisé |
Meilleures pratiques pour la qualité de la documentation ✅
Pour garantir que le DFD reste un atout précieux, suivez ces meilleures pratiques. Ces directives mettent l’accent sur la clarté, la cohérence et l’utilisabilité.
- Conventions de nommage cohérentes : Utilisez un format standard pour nommer les processus, les flux de données et les magasins. Par exemple, utilisez « Verbe-Nom » pour les processus (par exemple, « Calculer la taxe »). Cela rend le diagramme lisible et recherchable.
- Minimisez les croisements de lignes : Disposez le diagramme de manière à réduire le nombre de lignes qui se croisent. Cela améliore le flux visuel et réduit l’effort cognitif nécessaire pour suivre les chemins des données.
- Utilisez des légendes et des clés : Si vous utilisez des symboles spéciaux pour la sécurité, les types de données ou les systèmes externes, fournissez une légende. N’assumez pas que le lecteur connaît le sens de chaque symbole.
- Lien vers les spécifications : Lorsque c’est possible, liez le diagramme aux documents détaillés de spécifications ou aux dépôts de code. Cela établit un pont entre la vue d’ensemble et les détails d’implémentation.
- Gardez-le à jour :Privilégiez la précision du diagramme plutôt que son aspect parfait. Un diagramme un peu désordonné mais exact est plus utile qu’un élégant mais obsolète.
Intégration avec d’autres documents 📝
Un diagramme de flux de données n’existe pas en vase clos. Il fait partie d’un écosystème plus large de documentation technique. Pour maximiser sa valeur, il doit s’intégrer aux autres artefacts.
- Schéma de base de données : Les magasins de données du DFD doivent correspondre directement au schéma de base de données. Cela garantit que l’implémentation physique correspond au design logique.
- Spécifications de l’API : Les flux entre les entités externes et les processus correspondent souvent aux points d’entrée de l’API. La référence croisée de ces documents aide à valider les points d’intégration.
- Politiques de sécurité : Les flux de données impliquant des informations sensibles doivent être croisés avec les politiques de sécurité. Cela garantit que les exigences de chiffrement et de contrôle d’accès sont respectées.
- Cas de test : Les cas de test doivent être dérivés des flux de données. Chaque flux représente un chemin potentiel de test. Cela garantit une couverture complète de la logique du système.
Péchés courants à éviter ⚠️
Même avec les meilleures intentions, les équipes peuvent commettre des erreurs lors de l’agrandissement des DFD. La prise de conscience de ces pièges aide à éviter les pièges courants.
- Surconception : Ne créez pas un diagramme trop détaillé par rapport au niveau. Un diagramme de niveau 1 ne doit pas contenir la logique d’un processus de niveau 2. Gardez le niveau d’abstraction adapté.
- Ignorer les flux de contrôle : Bien que les DFD se concentrent sur les données, les signaux de contrôle (comme « Démarrer », « Arrêter », « Erreur ») sont souvent nécessaires dans les systèmes complexes. Distinguez-les clairement des flux de données.
- Supposer la linéarité : Les systèmes sont rarement linéaires. Les boucles, les mécanismes de rétroaction et les événements asynchrones sont fréquents. Représentez-les avec précision, même si cela rend le diagramme plus difficile à lire.
- Manque de standardisation : Si différents membres de l’équipe dessinent les diagrammes dans des styles différents, la documentation globale devient fragmentée. Établissez un guide de style dès le départ et appliquez-le rigoureusement.
Conclusion sur la scalabilité 🏗️
Échelonner les diagrammes de flux de données est une discipline nécessaire pour construire des systèmes robustes et à grande échelle. Cela exige plus que de dessiner davantage de boîtes ; cela demande une approche structurée en matière d’héritage, de décomposition et de maintenance. En suivant les stratégies décrites dans ce guide, les équipes peuvent créer une documentation qui soutient le développement sans devenir une charge. L’objectif est la clarté. Quand le diagramme est clair, le système est plus facile à comprendre, à maintenir et à étendre. Cet investissement dans la documentation rapporte des bénéfices en termes de réduction des erreurs et d’intégration plus rapide des nouveaux membres de l’équipe.
Souvenez-vous que le diagramme est un outil de communication, et non seulement un artefact technique. Il comble le fossé entre les exigences métiers et l’implémentation technique. Au fur et à mesure que le système grandit, la documentation doit évoluer également. Des revues régulières et un contrôle de version strict garantissent que le DFD reste une source fiable de vérité tout au long du cycle de vie du projet. Avec la bonne approche, l’échelonnement des DFD devient une tâche gérable plutôt qu’une entreprise chaotique.