











La modélisation des données est le pilier de toute architecture de base de données solide. Bien que la théorie soit souvent enseignée dans les cours universitaires, son application pratique dans les environnements de production révèle un paysage parsemé de cas limites, de goulets d’étranglement de performance et d’ambiguïtés logiques. Les diagrammes de relations d’entités (ERD) servent de plan à ces systèmes, mais ils deviennent souvent des sources de conflits lorsque le monde réel refuse de s’inscrire proprement dans des cases et des lignes.
Nous avons réuni un panel de DBA principaux et d’architectes de données pour analyser les scénarios qui embêtent régulièrement les équipes pendant la phase de conception. Ce ne sont pas des exercices théoriques ; ce sont des problèmes qui surgissent lorsque les exigences métiers entrent en conflit avec les contraintes de stockage physique. L’objectif ici n’est pas de proposer une solution rapide, mais de fournir une compréhension approfondie des compromis en jeu.
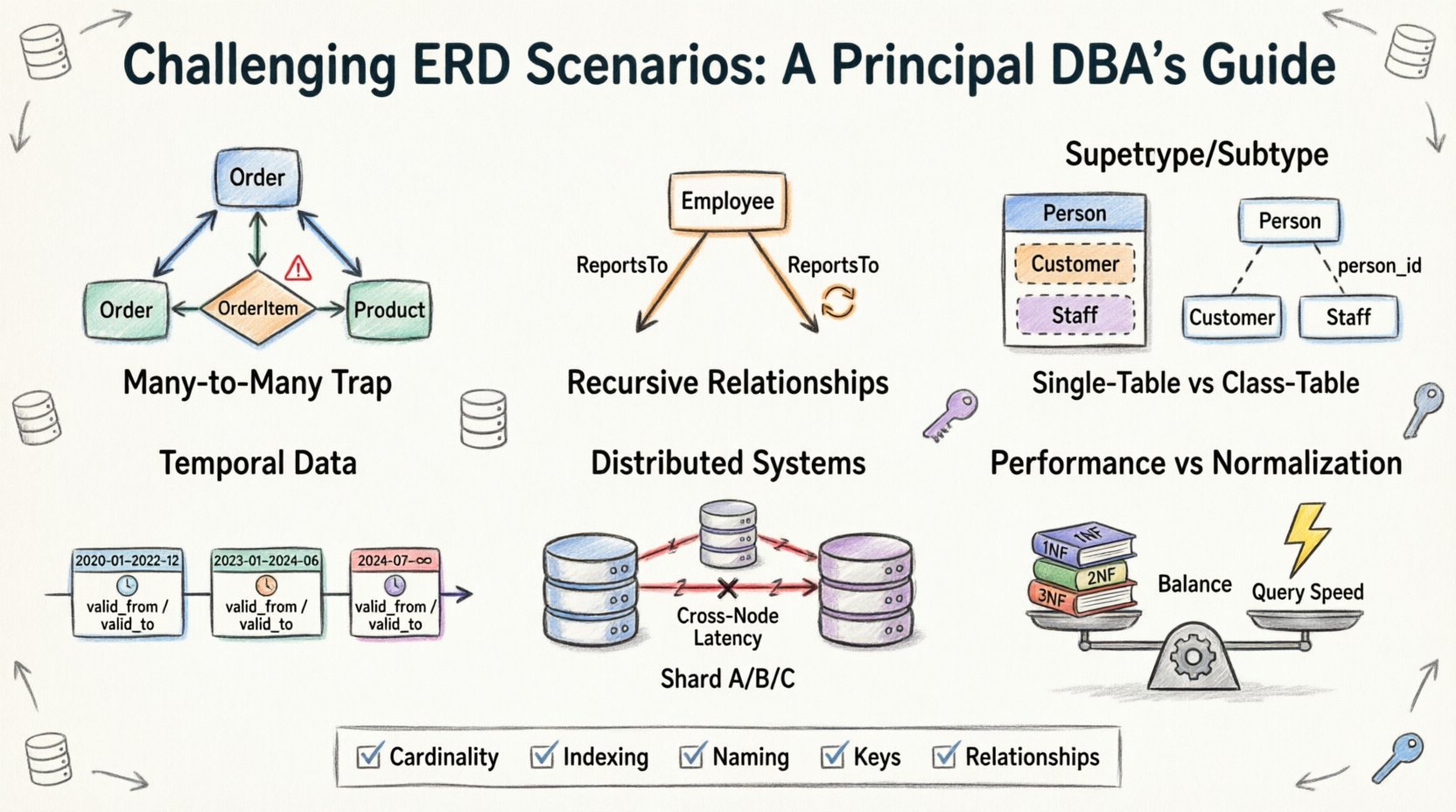
1. Le piège du Many-to-Many : Au-delà des tables de jointure simples 🕸️
Le point de départ le plus courant dans la conception des ERD est la relation Many-to-Many. Cela semble intuitif : un étudiant peut s’inscrire à plusieurs cours, et un cours peut avoir plusieurs étudiants. La solution standard consiste à utiliser une table de pont ou une table associative. Cependant, la complexité apparaît lorsque des attributs sont introduits directement dans la relation elle-même.
- Le problème :Souvent, les équipes tentent de stocker les données d’inscription (comme les notes ou les dates d’inscription) dans la table principale des étudiants ou des cours, ce qui entraîne une redondance massive ou des valeurs nulles.
- La réalité :La relation elle-même est une entité. Elle doit avoir sa propre clé primaire et des clés étrangères qui pointent vers ses parents.
- Le défi :Gérer les suppressions en cascade. Si un cours est supprimé, que deviennent les enregistrements d’inscription ? Si une inscription est supprimée, l’étudiant disparaît-il ? Ces décisions définissent l’intégrité des données.
Pendant notre discussion, un DBA principal a noté que la table associative devient souvent un goulet d’étranglement de performance. Lorsqu’on interroge des données à travers cette jonction, le moteur de base de données doit effectuer une opération de jointure qui peut mal évoluer lorsque le nombre de lignes atteint des millions. La solution n’est pas toujours architecturale ; parfois, elle nécessite une dénormalisation, mais cela introduit des anomalies de mise à jour.
Principaux éléments à considérer pour le Many-to-Many :
- La relation possède-t-elle des attributs qui nécessitent un index ?
- La relation est-elle active ou historique ? (Par exemple, une inscription actuelle est-elle différente d’une ancienne ?)
- Comment le système gérera-t-il les enregistrements orphelins si un parent est supprimé ?
2. Les relations récursives : Hiérarchies auto-référentielles 🌳
Les données hiérarchiques sont partout. Pensez à un organigramme, une liste de matériaux ou un fil de commentaires sur un forum. Modéliser cela nécessite qu’une table se référence elle-même. Bien que cela soit conceptuellement simple, l’implémentation dans un schéma relationnel soulève des défis spécifiques concernant la profondeur et le parcours.
Le problème structurel :
Vous créez une table avec une clé primaire et une colonne de clé étrangère qui pointe vers la même clé primaire de la table. Cela est souvent appelé une colonne « parent_id ». Le nœud racine a un parent nul.
Le problème de performance :
Les requêtes SQL standard peinent avec les hiérarchies profondes. Si vous devez récupérer un manager et tous ses subordonnés directs et indirects, une simple jointure est insuffisante. Vous avez besoin d’expressions de table communes récursives (CTE) ou de procédures stockées qui parcourent les niveaux. Cela peut être très coûteux en calcul.
Le problème d’intégrité :
Les références circulaires sont un tueur silencieux. Si l’employé A gère l’employé B, et que l’employé B gère l’employé A, vous avez un cycle. La base de données doit l’empêcher, ou la logique de l’application doit le détecter. Dans les grands systèmes, un cycle peut provoquer une boucle infinie dans les outils de reporting.
- Limites de profondeur :La plupart des systèmes limitent la profondeur de l’hiérarchie (par exemple, 32 niveaux) pour éviter les erreurs de débordement de pile lors du parcours.
- Agrégation de chemins :Calculer le coût total ou le nombre d’un sous-arbre nécessite une logique récursive difficile à optimiser dans les plans de requête standards.
3. Modélisation des supertypes et sous-types : Le dilemme de l’héritage 🧬
En programmation orientée objet, l’héritage est la norme. En base de données relationnelles, c’est un choix de conception qui impacte le stockage et la récupération. La question est la suivante : modélisez-vous un véhicule dans une seule table, ou le divisez-vous en Vehicle, Car et Truck ?
Option A : Héritage à table unique
Toutes les attributs de tous les sous-types se trouvent dans une seule table. Les valeurs nulles sont utilisées pour les attributs non utilisés.
- Avantages :Requêtes simples, pas besoin de jointures pour trouver un véhicule.
- Inconvénients :Surdimensionnement de la table, difficile d’appliquer des contraintes spécifiques aux sous-types, nombre important de colonnes pouvant être nulles.
Option B : Héritage à tables de classes
Une table pour le type supérieur (Véhicule), et des tables distinctes pour les sous-types (Voiture, Camion) liées par la clé primaire.
- Avantages :Séparation claire, pas de valeurs nulles, contraintes strictes par sous-type.
- Inconvénients :La requête nécessite des jointures sur plusieurs tables, ce qui peut affecter les performances de lecture.
Nos principaux DBA ont souligné que le choix dépend souvent des modèles de requêtes. Si vous interrogez fréquemment des sous-types spécifiques, l’approche à tables de classes est préférable. Si vous agréguez fréquemment tous les sous-types, l’approche à table unique l’emporte. Le schéma ERD doit refléter clairement cette décision afin d’éviter toute confusion pour les développeurs futurs.
4. Données temporelles : Suivi des modifications au fil du temps ⏳
Les règles métier évoluent. Un client déménage, un prix est mis à jour, un contrat expire. Stocker uniquement l’état « actuel » est souvent insuffisant pour l’audit ou le reporting. Cela conduit à la conception de tables temporelles ou de dimensions à changement lent (SCD).
La complexité :
Au lieu de mettre à jour une ligne, vous insérez une nouvelle ligne avec une date de début et de fin effectives. La ligne ancienne est marquée comme inactive. Cela double la demande de stockage pour les données historiques et complique la requête « vue actuelle ».
Le défi de requête :
Sélectionner des données « au moment » d’un point précis nécessite un filtrage sur la plage de dates. Si vous oubliez la logique de plage de dates, vous pourriez retourner la mauvaise version d’un enregistrement. C’est souvent là que des problèmes d’intégrité des données apparaissent dans les applications financières.
- Conception par instantané : Stocker l’état à un instant donné. Nécessite des tâches par lots périodiques pour écrire les instantanés.
- Conception par journal de transactions : Capturer chaque modification. Volume élevé d’écriture, logique de récupération complexe.
- Conception périodique : Stocker les intervalles valides. Gère bien les lacunes dans le temps, mais nécessite une gestion soigneuse des limites.
5. Systèmes distribués : Fractionnement (sharding) et relations 🔗
Lorsqu’une seule base de données ne peut pas contenir les données, le fractionnement devient nécessaire. C’est là que la conception du schéma ERD fait face à ses contraintes physiques les plus sévères. Les relations qui traversent les frontières du fractionnement sont coûteuses.
Le problème de jointure :
Si la table A est fractionnée par ID utilisateur, et que la table B est liée à la table A, la table B doit être fractionnée par le même ID utilisateur pour éviter les jointures distribuées. Si la table B est fractionnée autrement, vous devez acheminer la requête vers plusieurs shards, agréger les résultats, puis effectuer la jointure localement.
Intégrité référentielle :
Les contraintes de clés étrangères sont difficiles à appliquer sur des nœuds distribués. De nombreux systèmes désactivent les clés étrangères dans les environnements fractionnés afin de maintenir la disponibilité. Cela déplace la responsabilité de l’intégrité vers la couche d’application, qui est sujette aux conditions de course.
Points clés pour les modèles ER distribués :
- Évitez les relations plusieurs à plusieurs qui s’étendent sur plusieurs fragments.
- Dénormalisez les données pour réduire la nécessité de jointures entre nœuds.
- Concevez la clé de partition (clé de fractionnement) en fonction des modèles de requête les plus fréquents, et non uniquement de la clé primaire.
6. Performance vs. Normalisation : L’équilibre des compromis ⚖️
La normalisation (1NF, 2NF, 3NF) est enseignée comme la norme d’or pour l’intégrité des données. Toutefois, dans les systèmes à haut débit, une normalisation stricte peut gravement nuire aux performances. Le modèle ERD doit trouver un équilibre entre les deux.
Quand dénormaliser :
- Charge de lecture élevée : Si vous lisez des données beaucoup plus que vous ne les écrivez, l’ajout de colonnes redondantes permet d’économiser des opérations de jointure.
- Exigences de reporting : Les agrégations sur des données normalisées nécessitent des jointures complexes qui ralentissent les tableaux de bord.
- Charge d’écriture élevée : Parfois, conserver les données séparées réduit la contention de verrouillage lors des mises à jour.
Notre panel a souligné qu’il n’existe pas de « schéma parfait ». C’est un compromis. Un modèle ERD doit documenter où la dénormalisation a lieu et pourquoi, afin que les futurs mainteneurs comprennent que la redondance est intentionnelle, et non une erreur.
Comparaison des modèles de conception 📊
Pour aider à la prise de décision, voici un résumé des modèles de conception abordés ainsi que leurs cas d’utilisation typiques.
| Modèle | Meilleur cas d’utilisation | Risque principal | Complexité |
|---|---|---|---|
| Table unique | Hiérarchies simples, faible variété | Champs nuls, gonflement du schéma | Faible |
| Table de classe | Sous-types stricts, attributs distincts | Surcharge de jointure | Moyen |
| Récursif | Organigrammes, catégories | Profondeur de parcours, cycles | Élevé |
| Entité associative | Nombreux-à-nombreux avec attributs | Performance des jointures | Moyen |
| Temporel | Audit, suivi de l’historique | Complexité des requêtes | Élevé |
| Fractionnement distribué | Échelle massive, croissance horizontale | Intégrité référentielle | Très élevé |
Liste de contrôle pour la revue du schéma ER ✅
Avant de finaliser un diagramme d’entités et de relations, utilisez cette liste de contrôle pour détecter les pièges courants. Il est préférable de repérer ces problèmes pendant la phase de conception que lors de la production.
- Cardinalité :Avez-vous clairement défini les relations un-à-un, un-à-plusieurs et plusieurs-à-plusieurs ? Les contraintes min/max (0..1, 1..*) sont-elles explicites ?
- Types de données :Les types de colonnes sont-ils adaptés à la taille attendue des données ? (par exemple, utiliser Integer au lieu de Varchar pour les identifiants).
- Nullabilité :Les clés étrangères sont-elles nullables ? Si oui, la logique gère-t-elle correctement les références orphelines ?
- Stratégie d’indexation :Le schéma ER indique-t-il les colonnes qui doivent être indexées pour des raisons de performance ? Les clés étrangères sont souvent indexées pour accélérer les jointures.
- Conventions de nommage :Les noms de tables et de colonnes sont-ils cohérents ? Évitez les abréviations qui pourraient prêter à confusion ultérieurement.
- Règles métiers :Les contraintes (par exemple, « Un utilisateur ne peut pas avoir deux abonnements actifs ») sont-elles représentées sous forme de vérifications logiques ou de contraintes de base de données ?
- Extensibilité : Le schéma peut-il accueillir de nouveaux attributs sans nécessiter une migration complète ? (par exemple, en utilisant un modèle EAV ou des colonnes JSON là où cela est pertinent).
Réflexions finales sur la modélisation des données 🧠
Concevoir un diagramme d’entité-relation n’est pas seulement une question de dessiner des boîtes et des lignes. C’est comprendre le flux des données, les contraintes du matériel et les besoins de l’entreprise. Les scénarios abordés ici représentent les points de friction où la théorie rencontre la pratique.
En anticipant ces défis — profondeur récursive, jointures distribuées, historique temporel et compromis liés à l’héritage — vous pouvez concevoir des schémas résilients. Un ERD bien conçu réduit la dette technique et évite la nécessité de refactoring coûteux ultérieurement. C’est un investissement dans la stabilité de l’ensemble du système.
Souvenez-vous que le meilleur schéma est celui qui évolue avec les données. La documentation est essentielle. Assurez-vous que chaque déviation par rapport à la normalisation standard est justifiée et enregistrée. Cette transparence est ce qui distingue une architecture de base de données solide d’une fragile.