











Moderniser un système hérité pour le transformer en une architecture de microservices est un parcours semé d’obstacles techniques et organisationnels. Alors que de nombreuses équipes se concentrent fortement sur le restructurage du code et la conteneurisation, un obstacle majeur réside souvent au niveau du traitement des données. Plus précisément, le modèle traditionnel de diagramme de relations entre entités (ERD) peut devenir une contrainte sérieuse lors du passage à des systèmes distribués. 📉
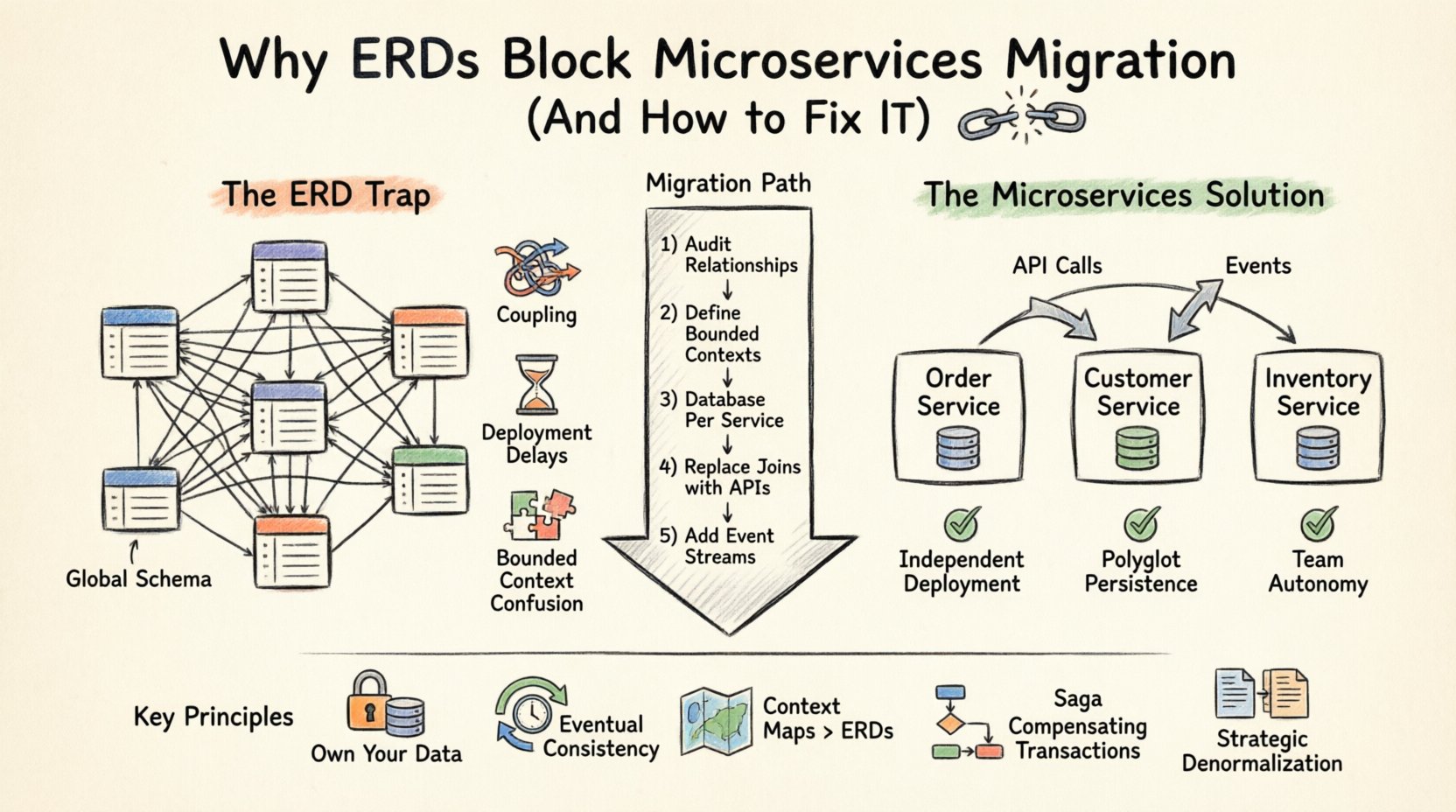
Lorsque vous concevez une application monolithique, votre modèle de données est centralisé. Un ERD représente la source unique de vérité, avec des tables normalisées reliées par des clés étrangères. Cette approche fonctionne bien pour une seule instance de base de données. Cependant, les microservices exigent une autonomie. En imposant une structure monolithique d’ERD à une architecture distribuée, vous créez un couplage étroit qui annule les avantages de la fragmentation de votre système. 🚧
Ce guide explore pourquoi l’approche classique de l’ERD freine l’adoption des microservices et propose une feuille de route concrète pour transformer vos stratégies de modélisation des données. Nous aborderons la gestion distribuée des données, les modèles de cohérence et les techniques de visualisation qui s’alignent sur les principes du design axé sur le domaine. 🗺️
Comprendre le piège de l’ERD dans les systèmes distribués 🧩
Un diagramme de relations entre entités est une représentation visuelle de la structure logique d’une base de données. Il définit les entités (tables), les attributs (colonnes) et les relations (clés étrangères). Dans un environnement monolithique, cette centralisation est un atout. Elle garantit l’intégrité des données grâce aux transactions ACID et simplifie les requêtes sur l’ensemble de l’application.
Cependant, l’architecture des microservices repose sur le principe de l’indépendance des services. Chaque service doit posséder ses propres données et ne les exposer que via une API. Lorsque vous maintenez un ERD partagé qui s’étend sur plusieurs services, vous violez la frontière de la propriété. Cela entraîne les problèmes suivants :
- Dépendances de schéma global : Si le service A doit joindre des données provenant du service B directement au niveau de la base de données, ils ne sont plus indépendants. Un changement dans le schéma du service B casse le service A.
- Frontières des transactions : Les transactions ACID sur plusieurs bases de données sont complexes et lourdes en performance. Les transactions distribuées entraînent souvent des conflits de verrouillage et des pics de latence.
- Couplage du déploiement : Si votre modèle de données est partagé, vous ne pouvez pas déployer les services de manière indépendante. Vous devez coordonner les changements de schéma entre les équipes, ce qui ralentit les cycles de déploiement.
- Confusion autour du contexte borné : Des services différents peuvent interpréter la même entité différemment. Un ERD impose une seule définition, ignorant les nuances propres au domaine.
Le problème du couplage : les clés étrangères et les jointures 🔗
L’une des erreurs les plus fréquentes lors de la migration consiste à tenter de conserver le schéma de base de données existant tout en divisant le code de l’application. Cela entraîne un anti-pattern base de données partagée. Dans ce scénario, plusieurs services se connectent à la même instance de base de données, en s’appuyant sur les clés étrangères pour maintenir les relations.
Bien que cela ressemble à une structure d’ERD valide, il s’agit en réalité d’un monolithe caché. Voici pourquoi cette approche échoue dans un contexte de microservices :
- Latence réseau : Même si la base de données est locale au réseau, les requêtes entre services introduisent des sauts réseau qui dégradent les performances par rapport aux requêtes locales.
- Point de défaillance unique : Si la base de données tombe en panne, tous les services tombent également en panne. Les microservices visent la résilience grâce à l’isolement.
- Risques de sécurité : Un service qui ne devrait pas avoir accès directement aux autres données peut tout de même y accéder via la chaîne de connexion à la base de données. Les API fournissent une interface contrôlée ; l’accès direct à la base de données non.
- Verrouillage technologique : Tous les services doivent utiliser la même technologie de base de données. Les microservices permettent une persistance polyglotte, où différents services utilisent le système de stockage le plus adapté à leurs besoins spécifiques.
Pour résoudre cela, vous devez abandonner les jointures SQL à travers les frontières des services. Au lieu de cela, vous devez utiliser la composition d’API ou la synchronisation de données pilotée par des événements. 🔄
Base de données par service : la règle d’or 🏦
Le modèle fondamental pour l’architecture des données des microservices est Base de données par service. Chaque service possède son propre schéma de base de données. Aucun autre service n’est autorisé à accéder directement à cette base de données. La communication se fait strictement par le biais de l’API publique du service.
Ce changement exige un changement fondamental dans la manière dont vous visualisez vos données. Vous ne pouvez plus dessiner un seul ERD géant pour l’ensemble du système. Au lieu de cela, vous créez plusieurs ERD plus petits, un par service. 📄
| Aspect | ERD monolithique | Modèle de microservices |
|---|---|---|
| Portée du schéma | Global / Unifié | Local / Spécifique au service |
| Relations | Clés étrangères | Appels d’API / Événements |
| Consistance | Fort (ACID) | Éventuelle (BASE) |
| Déploiement | Couplé | Indépendant |
Gérer la consistance sans transactions partagées 🤝
Lorsque vous séparez les bases de données, vous perdez la capacité d’exécuter une seule transaction qui met à jour simultanément le Service A et le Service B. Dans un monolithe, vous pourriez utiliser une transaction de base de données pour transférer de l’argent du compte A au compte B. Dans les microservices, ces comptes pourraient appartenir à des services différents.
Puisque vous ne pouvez pas garantir une consistance immédiate à travers les systèmes distribués, vous devez adopter Consistance éventuelle. Cela signifie que le système atteindra un état cohérent au fil du temps, mais pas nécessairement au moment exact où l’utilisateur clique sur un bouton.
Mise en œuvre des sagas
Pour gérer les flux de travail complexes qui s’étendent sur plusieurs services, utilisez le modèle de saga. Une saga est une séquence de transactions locales où chaque transaction met à jour la base de données au sein d’un seul service. Si une étape échoue, la saga exécute des transactions compensatoires pour annuler les modifications apportées par les étapes précédentes.
- Chorégraphie :Les services émettent des événements qui déclenchent des actions dans d’autres services. Il n’y a pas de coordinateur central.
- Orchestration :Un service coordinateur central gère le flux de travail et indique aux autres services ce qu’ils doivent faire.
Cette approche garantit l’intégrité des données sans nécessiter de verrous partagés ni de transactions distribuées. Elle ajoute de la complexité à l’implémentation, mais est nécessaire pour maintenir la santé du système. 🛡️
Visualiser les données sans les MCD : cartes de contexte 🗺️
Si vous abandonnez le MCD traditionnel, qu’utilisez-vous pour visualiser votre architecture des données ? La réponse réside dansCartes de contexte du Design axé sur le domaine (DDD). Alors qu’un MCD se concentre sur les tables et les colonnes, une carte de contexte se concentre sur les contextes limités et les relations.
Au lieu de dessiner des lignes entre les tables, vous dessinez des lignes entre les services. Vous définissez comment les données circulent entre eux :
- Client-Fournisseur :Un service fournit des données à un autre. Le fournisseur définit le contrat.
- Conformiste :Le service consommateur doit s’adapter au modèle du fournisseur.
- Service hôte ouvert :Un service expose ses données via un protocole ouvert.
- Voies séparées :Les deux services évoluent indépendamment de leurs propres modèles.
Ce changement de visualisation aide les équipes à comprendrepourquoiles données sont dupliquées. Dans un monolithe, la duplication est mauvaise. Dans les microservices, la duplication est souvent une fonctionnalité pour découpler les services. Par exemple, leService de commandepeut stocker une capture instantanée duNom du clientafin d’éviter un appel réseau à chaque visualisation d’une commande. Ce compromis est acceptable pour la performance.
Étapes de migration : passer du MCD à des données distribuées 🚀
Passer d’un MCD centralisé à un modèle de données distribué n’est pas un événement ponctuel. C’est un processus progressif. Voici une approche recommandée pour gérer la migration.
Étape 1 : Audit des relations de données existantes
Avant de diviser quoi que ce soit, documentez chaque relation dans votre MCD actuel. Identifiez les tables qui sont fortement en lecture, celles qui sont fortement en écriture, et celles qui sont fréquemment jointes. Cette analyse vous aide à regrouper les entités en frontières logiques de services. 📊
Étape 2 : Définir les contextes limités
Regroupez les entités en fonction des domaines métiers plutôt que des dépendances techniques. Par exemple, un Catalogue de produits est différent d’un Gestion des stocks système, même s’ils utilisent tous deux le champ ProductID champ. Assurez-vous que les limites correspondent aux structures d’équipes (loi de Conway).
Étape 3 : Mettre en œuvre une base de données par service
Créez une instance de base de données distincte pour chaque service. Migrez les données pertinentes depuis la base de données monolithique. Vous n’avez pas besoin de tout déplacer immédiatement. Commencez par les données essentielles pour le fonctionnement du service. 🏗️
Étape 4 : Remplacer les JOIN par des appels d’API
Réécrivez vos requêtes. Au lieu de JOIN Orders, Customers, votre code doit appeler l’API Customer API pour récupérer les détails. Cela peut introduire une latence, donc envisagez des stratégies de mise en cache ou de dénormalisation là où cela est pertinent.
Étape 5 : Introduire des flux d’événements
Pour les mises à jour en temps réel, mettez en place un bus d’événements. Lorsqu’une entité change dans un service, publiez un événement. Les autres services peuvent s’abonner à ces événements pour mettre à jour leurs copies locales des données. Cela garantit une cohérence éventuelle sans couplage direct.
Péchés courants pendant la migration ⚠️
Même avec un plan, les équipes s’embrouillent souvent pendant la transition. Soyez attentif à ces problèmes courants.
- fractionnement prématuré : Ne divisez pas les services avant de comprendre le flux de données. Une division trop précoce peut entraîner une complexité distribuée avant que vous ne soyez prêts.
- Ignorer la propriété des données : Si plusieurs équipes revendiquent la propriété de la même entité de données, des conflits apparaîtront. Attribuez une propriété claire à chaque service.
- Sur-normalisation : Dans un système distribué, la dénormalisation est souvent préférée pour réduire le nombre d’appels d’API nécessaires pour afficher une page.
- Dépendance au réseau : Ne supposez jamais que le réseau est parfait. Mettez en œuvre des délais d’attente, des réessais et des interrupteurs de circuit pour la communication entre services.
Alignement organisationnel 🤝
L’architecture des données n’est pas seulement technique ; elle est organisationnelle. Un modèle de données distribué exige que les équipes communiquent différemment. Dans un monolithe, les développeurs discutent autour d’un tableau blanc partagé (la base de données). Dans les microservices, ils discutent autour du contrat d’API.
Assurez-vous que vos équipes sont autonomes pour modifier leur schéma de base de données sans consulter un comité de gouvernance central. Cette autonomie est la seule façon de maintenir la vitesse du déploiement indépendant. Si vous introduisez une équipe centrale qui approuve tous les changements de schéma, vous réintroduisez le goulot d’étranglement que vous avez essayé d’éliminer. 👥
Considérations finales pour la stratégie de données 🧭
S’éloigner d’un diagramme traditionnel d’entités et de relations est une étape importante. Elle exige un changement de mentalité par rapport àl’intégrité des données grâce aux contraintes à l’intégrité des données grâce à la logique d’application et aux événements. Le diagramme ER est un outil pour les bases de données relationnelles, et non un plan directeur pour les systèmes distribués.
En adoptant le modèle de base de données par service, en utilisant une architecture pilotée par les événements et en vous concentrant sur les contextes limités, vous pouvez éviter le couplage qui ralentit votre migration. L’objectif n’est pas de détruire votre modèle de données existant, mais de l’évoluer vers une structure qui permet un dimensionnement indépendant et une résilience.
Souvenez-vous qu’une cohérence est un spectre. Vous n’avez pas besoin d’une cohérence forte partout. Identifiez les parties de votre système qui exigent une précision stricte et celles qui peuvent tolérer une cohérence éventuelle. Ce pragmatisme vous évitera de surconcevoir votre solution.
Commencez par auditer vos diagrammes actuels. Identifiez les jointures qui traversent les frontières des services. Prévoyez la migration de ces entités spécifiques. Faites des petits pas. Vérifiez les résultats. Et gardez toujours le domaine métier au cœur de votre conception des données. 🎯
Points clés 📝
- Évitez les bases de données partagées entre les services pour éviter le couplage.
- Utilisez la composition d’API au lieu des jointures SQL pour les données entre services.
- Acceptez la cohérence éventuelle pour gagner en disponibilité et en tolérance aux partitions.
- Visualisez les données à l’aide de cartes de contexte plutôt que de diagrammes ER globaux.
- Attribuez une propriété claire des données aux équipes de services individuelles.
- Prévoyez la duplication des données comme optimisation de performance.
En suivant ces principes, vous pouvez naviguer dans les complexités de la migration des données sans laisser votre diagramme ER imposer les limites de votre nouvelle architecture. Le chemin à suivre est distribué, décentralisé et conçu pour l’évolutivité. 🚀