











Die Gestaltung von Systemen, die Daten verwalten, ist eine komplexe Aufgabe. Wenn Projekte von kleinen Skripten zu enterprise-orientierten Plattformen wachsen, muss die Dokumentation, die beschreibt, wie Informationen durch die Architektur fließen, sich weiterentwickeln. Datenflussdiagramme (DFDs) dienen als architektonische Baupläne für diese Systeme. Sie zeigen die Bewegung von Daten zwischen Prozessen, Datenspeichern und externen Entitäten. Ein Diagramm, das für eine einfache Anwendung funktioniert, kollabiert jedoch oft unter der Last eines Großprojekts. Die Skalierung von DFDs erfordert eine disziplinierte Herangehensweise an Hierarchie, Zerlegung und Wartung. Dieser Leitfaden untersucht die Strategien, die notwendig sind, um die Dokumentation des Datenflusses auch bei steigender Komplexität klar, genau und nützlich zu halten.
Der Übergang von einem kleinen Umfang zu einer großskaligen Umgebung bringt Herausforderungen mit sich, die nicht einfach durch Hinzufügen weiterer Kästchen und Pfeile gelöst werden können. Ohne eine strukturierte Methodik werden Diagramme zu unlesbaren Netzwerken der Verbindungen. Dies führt zu Verwirrung bei Stakeholdern, Entwicklern und Architekten. Um Klarheit zu bewahren, müssen Teams spezifische Muster für die Organisation übernehmen. Wir werden die Mechanismen der Skalierung untersuchen, vom ursprünglichen Kontextniveau bis hin zu detaillierten Prozessaufteilungen. Außerdem werden wir behandeln, wie man Datenspeicher und externe Grenzen verwalten kann, ohne den Überblick über das Gesamtbild zu verlieren.
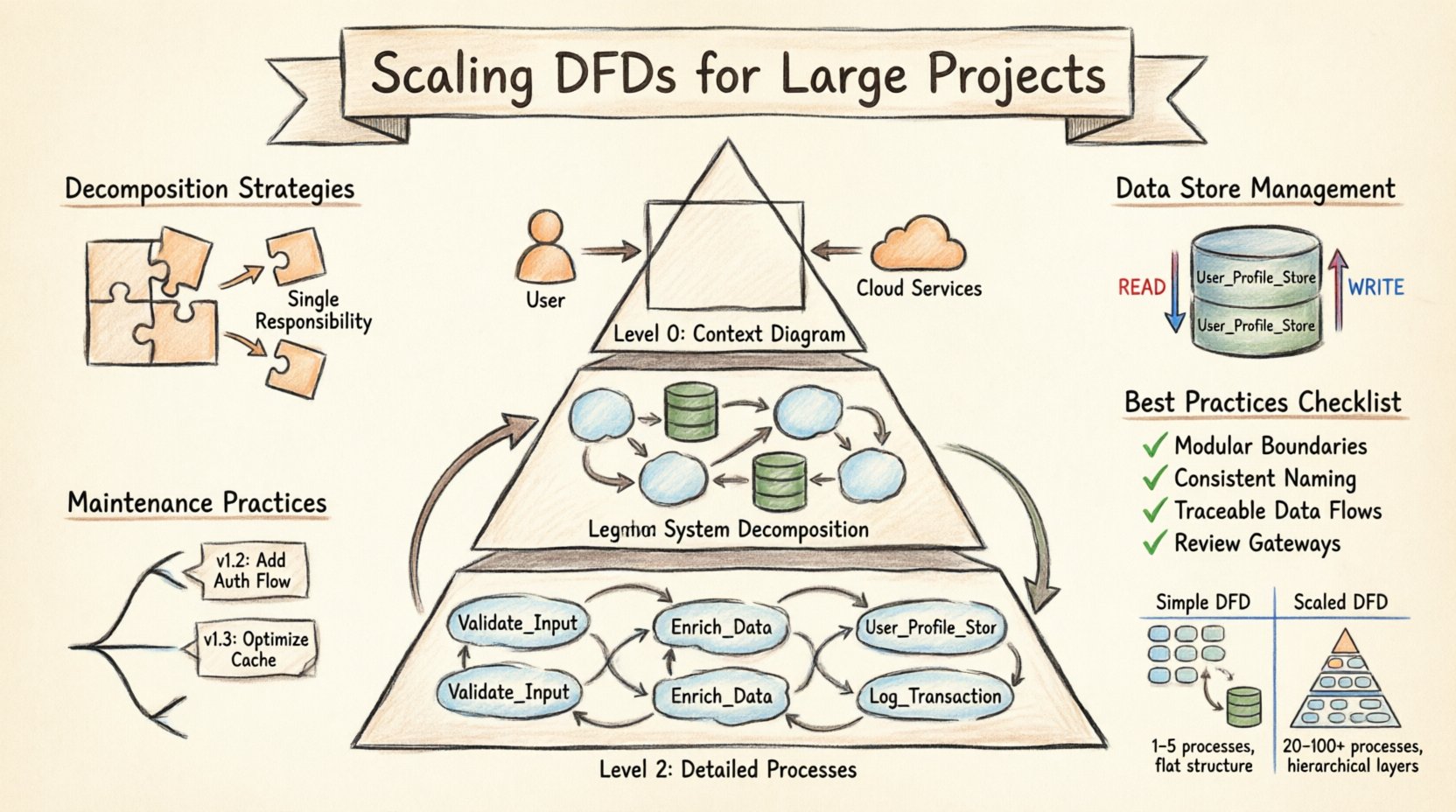
Verständnis der Hierarchie von DFDs 📚
Die Grundlage der Skalierung liegt in der hierarchischen Struktur des Diagramms selbst. Ein einzelnes, flaches Diagramm ist selten ausreichend für große Systeme. Stattdessen ermöglicht ein mehrstufiges Vorgehen, dass Stakeholder das System in unterschiedlichen Detailgraden betrachten können. Diese Methode wird oft als Level-0-, Level-1-, Level-2-Struktur bezeichnet. Jede Ebene dient einer spezifischen Zielgruppe und einem bestimmten Zweck.
- Ebene 0 (Kontextdiagramm): Dies ist die höchste Betrachtungsebene. Es zeigt das gesamte System als einen einzigen Prozess. Es verbindet das System mit externen Entitäten, wie Benutzern, Drittanbieterdiensten oder Hardware. Ziel hierbei ist es, die Grenzen des Systems sowie die wichtigsten Eingaben und Ausgaben zu definieren. Es sollte keine internen Prozesse oder Datenspeicher enthalten.
- Ebene 1 (Systemzerlegung): Diese Ebene zerlegt den einzelnen Prozess aus Ebene 0 in wesentliche Unterverarbeitungen. Sie führt Datenspeicher ein und zeigt, wie Daten zwischen den wichtigsten Funktionsbereichen fließen. Hier wird die Kernarchitektur sichtbar. Sie wird typischerweise von Systemarchitekten und Senior-Entwicklern verwendet.
- Ebene 2 (Detaillierte Prozesse): Jeder Hauptprozess aus Ebene 1 wird in ein separates Diagramm ausgeweitet. Diese Ebene beschreibt die Logik, spezifische Datenumformungen und Interaktionen mit Datenspeichern detailliert. Sie wird von Implementierern und Testern verwendet, die die spezifischen Abläufe einer Funktion verstehen müssen.
Bei der Skalierung muss die Beziehung zwischen diesen Ebenen streng aufrechterhalten werden. Jeder Eingang und jede Ausgabe in einem Diagramm der Ebene 0 muss in Ebene 1 berücksichtigt werden. Jeder Datenfluss, der aus einem Prozess der Ebene 1 herausgeht, muss in dem entsprechenden Diagramm der Ebene 2 erklärt werden. Diese Konsistenz verhindert Informationsverlust und gewährleistet die Rückverfolgbarkeit. Wenn ein Datenfluss in einem Diagramm der unteren Ebene erscheint, aber nicht in einem höheren Diagramm, deutet dies auf eine Diskrepanz hin, die behoben werden muss.
Zerlegungsstrategien für Komplexität 🔨
Zerlegung ist die Handlung, komplexe Prozesse in kleinere, handhabbare Komponenten zu unterteilen. Bei Großprojekten geht es nicht nur um Vereinfachung, sondern um die Bewältigung der kognitiven Belastung. Ein Prozess, der zu viele unterschiedliche Funktionen erfüllt, wird zu einer Engstelle im Verständnis. Eine effektive Zerlegung folgt bestimmten Regeln, um sicherzustellen, dass das Diagramm weiterhin nützlich bleibt.
- Eine Funktion pro Prozess: Jeder Prozess-Kreis oder -Kasten sollte eine einzelne, eindeutige Datenumformung darstellen. Wenn ein Prozess sowohl Datenvalidierung als auch Datenspeicherung behandelt, sollte er aufgeteilt werden. Diese Trennung klärt die Verantwortung jedes einzelnen Bausteins.
- Konsistente Granularität: Während die Ebenen unterschiedlich detailliert sein können, sollte die Granularität innerhalb einer einzelnen Ebene konsistent sein. Wenn ein Prozess sehr detailliert ist, sollten benachbarte Prozesse keine vagen Zusammenfassungen sein. Diese Balance verhindert, dass das Diagramm ungleichmäßig und verwirrend wird.
- Logische Gruppierung: Gruppieren Sie verwandte Prozesse visuell oder durch Namenskonventionen. Dies hilft dem Leser, funktionale Bereiche wie „Authentifizierung“, „Abrechnung“ oder „Berichterstattung“ zu erkennen. Logische Gruppierung verringert die Notwendigkeit, Linien über die gesamte Seite zu verfolgen.
- Vermeidung von Quer-Ebenen-Übergriffen: Fügen Sie keine Details in ein Diagramm der höheren Ebene ein, die in einer niedrigeren Ebene gehören. Umgekehrt dürfen Sie in einem Diagramm der Ebene 1 keine kritischen Datenspeicher auslassen, die für das Verständnis des Systemzustands unerlässlich sind.
Bei der Skalierung begegnet man häufig Prozessen, die sich nicht eindeutig einer einzigen Kategorie zuordnen lassen. In solchen Fällen muss der Prozess möglicherweise in parallele Ströme aufgeteilt oder über eine dedizierte Schnittstellenschicht behandelt werden. Ziel ist es, den Fluss linear und logisch zu halten. Wenn ein Prozess Daten von fünf verschiedenen Quellen benötigt und Ergebnisse an drei verschiedene Ziele sendet, ist er wahrscheinlich zu komplex für ein einzelnes Kästchen. Die Aufteilung in Zwischenschritte klärt die Reihenfolge der Operationen.
Verwaltung von Datenspeichern in der Skalierung 🗄️
Datenspeicher repräsentieren den persistierenden Zustand des Systems. Bei kleinen Projekten könnte eine einzige Datenbank die gesamte Anwendung bedienen. Bei Großprojekten ist die Datenverteilung über mehrere Systeme, Schemata und Dienste verteilt. Die genaue Abbildung dieser Speicher in einem DFD ist entscheidend für das Verständnis der Datenintegrität und der Zugriffsmuster.
- Explizite Benennung: Benennen Sie einen Datenspeicher nicht einfach als „Datenbank“. Verwenden Sie spezifische Namen wie „User_Profile_Store“ oder „Transaction_Log“. Diese Spezifität hilft Entwicklern, zu erkennen, welches System welche Daten enthält.
- Lesen gegenüber Schreiben von Datenflüssen: Geben Sie an, wo Daten gelesen werden und wo sie geschrieben werden. Während DFDs traditionell Datenflüsse ohne Richtungsangabe zeigen, erfordert die Skalierung Klarheit über Zustandsänderungen. Verwenden Sie unterschiedliche Notationen oder Legenden, um anzuzeigen, ob ein Prozess einen Speicher aktualisiert oder lediglich abfragt.
- Geteilte Datenspeicher:Große Systeme teilen sich häufig Datenbanken zwischen Prozessen. Stellen Sie sicher, dass die Darstellung zeigt, welche Prozesse auf welche Speicher zugreifen. Dies hilft, potenzielle Konkurrenzprobleme oder Sicherheitslücken zu erkennen.
- Beziehungen zwischen Datenbanken:Wenn Daten von einem Speicher zu einem anderen fließen, zeigen Sie dies explizit an. Dies könnte einen Replikationsprozess, einen ETL-Job oder eine Synchronisierungsroutine anzeigen. Diese Flüsse werden oft übersehen, sind aber entscheidend für die Zuverlässigkeit des Systems.
Je mehr Datenbanken hinzukommen, desto unübersichtlicher kann die Darstellung werden. Um dies zu vermeiden, sollten Gruppierungstechniken in Betracht gezogen werden. Schließen Sie verwandte Datenbanken innerhalb einer Grenze ein, die ein bestimmtes Subsystem darstellt. Dies verringert die visuelle Störung, während die logische Verbindung erhalten bleibt. Achten Sie jedoch darauf, dass die Datenflüsse zwischen diesen Gruppen nicht verdeckt werden. Die Verbindungen müssen sichtbar bleiben, damit das vollständige Bild verstanden wird.
Grenzen externer Entitäten 🌐
Externe Entitäten stellen die Quellen und Ziele von Daten außerhalb der Systemgrenzen dar. Dazu können menschliche Benutzer, andere Software-Systeme, veraltete Mainframes oder behördliche Stellen gehören. Bei groß angelegten Projekten kann die Zahl externer Entitäten stark ansteigen. Die Verwaltung dieser Grenzen ist entscheidend, um den Projektumfang klar zu definieren.
- Definieren Sie klare Schnittstellen:Jede Verbindung zwischen einer externen Entität und einem Prozess stellt eine Schnittstelle dar. Dokumentieren Sie das erwartete Format und Protokoll für diese Interaktionen. Dies vermeidet Unklarheiten bei der Integration mit Drittsystemen.
- Vereinigen Sie ähnliche Entitäten:Wenn mehrere Benutzer dieselbe Funktion ausführen, stellen Sie sie als eine einzelne generische Entität (z. B. „Kunde“) dar, wobei eine Notiz die Rollenunterschiede erläutert. Dies reduziert Redundanz, ohne Funktionalität zu verlieren.
- Sicherheitsaspekte:Externe Entitäten stellen oft Sicherheitsgrenzen dar. Daten, die von einer externen Entität in das System fließen, können Authentifizierung oder Verschlüsselung erfordern. Der DFD sollte diese Sicherheitsanforderungen idealerweise im Text oder über eine Legende dokumentieren.
- Veraltete Systeme:Große Projekte interagieren oft mit veralteten Systemen. Diese Entitäten können starre Datenformate aufweisen. Karten Sie diese Interaktionen sorgfältig ab, um sicherzustellen, dass das neue System die Daten korrekt verarbeiten kann, ohne bestehende Arbeitsabläufe zu stören.
Beim Skalieren ist es verführerisch, kleinere externe Entitäten zu ignorieren. Doch selbst geringfügige Eingaben können erhebliche nachgelagerte Auswirkungen haben. Eine Änderung im Datenaufbau einer kleinen Entität kann sich durch das gesamte System auswirken. Daher müssen alle Entitäten im Kontextdiagramm berücksichtigt und in den Dekompositionsebenen verfolgt werden.
Wartung und Versionskontrolle 🔄
Ein DFD ist ein lebendiges Dokument. Bei groß angelegten Projekten ändern sich die Anforderungen häufig. Prozesse werden hinzugefügt, Datenbanken zusammengeführt und externe Schnittstellen abgeschaltet. Ohne eine robuste Wartungsstrategie wird die Darstellung schnell veraltet und führt zu einer Diskrepanz zwischen Dokumentation und Code.
- Versionsverwaltung:Weisen Sie Diagrammen Versionsnummern zu. Dadurch können Teams Änderungen im Laufe der Zeit verfolgen. Wenn ein Fehler gemeldet wird, können Sie die spezifische Version des Diagramms referenzieren, die zum Zeitpunkt der Codeerstellung gültig war.
- Änderungsprotokolle:Führen Sie ein separates Protokoll, das beschreibt, was zwischen den Versionen geändert wurde. Fügen Sie das Datum, den Autor und den Grund für die Änderung hinzu. Dies liefert zukünftigen Entwicklern Kontext, die sich möglicherweise nicht mehr daran erinnern, warum eine Entscheidung getroffen wurde.
- Überprüfungszyklen:Planen Sie regelmäßige Überprüfungen der DFDs. Diese sollten mit den Haupt-Release-Zyklen zusammenfallen. Überprüfen Sie während dieser Überprüfungen, ob die Diagramme der aktuellen Implementierung entsprechen. Aktualisieren Sie sie sofort, falls Abweichungen festgestellt werden.
- Zugriffssteuerung:Stellen Sie sicher, dass nur autorisiertes Personal die Diagramme ändern darf. Unkontrollierte Änderungen können zu Konflikten und Verwirrung führen. Verwenden Sie ein System, das protokolliert, wer Änderungen vorgenommen und wann dies geschah.
Die Wartung wird oft der Entwicklung vorgezogen und vernachlässigt. Doch veraltete Diagramme sind gefährlicher als gar keine Diagramme. Sie erzeugen ein falsches Sicherheitsgefühl. Teams können auf Dokumentationen vertrauen, die der Realität nicht entsprechen. Indem man den DFD wie Code behandelt, der denselben Versionskontroll- und Überprüfungsprozessen unterliegt, können Teams die Genauigkeit sicherstellen.
Vergleich: Skalierte vs. einfache DFDs 📊
Das Verständnis der Unterschiede zwischen einem einfachen DFD und einem skalierten DFD hilft Teams, sich auf die Umstellung vorzubereiten. Die folgende Tabelle zeigt die wesentlichen Unterschiede in Struktur, Komplexität und Verwaltung auf.
| Funktion | Einfacher DFD | Skaliertes DFD |
|---|---|---|
| Anzahl der Prozesse | 1 bis 5 | 20 bis 100+ |
| Ebenen | 1 (Flach) | 3 bis 5 (Hierarchisch) |
| Verwendete Werkzeuge | Stift und Papier | Spezialisierte Diagrammierungssoftware |
| Versionskontrolle | Manuell | Automatisierte Systeme |
| Häufigkeit der Überprüfung | Zum Zeitpunkt der Lieferung | Pro Sprint/Release |
| Datenspeicherdetail | Generisch | Spezifisch und benannt |
| Externe Entitäten | Minimal | Umfassend und kategorisiert |
Best Practices für die Dokumentationsqualität ✅
Um sicherzustellen, dass das DFD ein wertvoller Bestandteil bleibt, sollten diese Best Practices befolgt werden. Diese Richtlinien konzentrieren sich auf Klarheit, Konsistenz und Nutzbarkeit.
- Konsistente Namenskonventionen:Verwenden Sie ein standardisiertes Format für die Benennung von Prozessen, Datenflüssen und Speichern. Verwenden Sie beispielsweise „Verb-Nomen“ für Prozesse (z. B. „Steuer berechnen“). Dadurch wird das Diagramm lesbar und durchsuchbar.
- Minimieren Sie Linienkreuzungen:Ordnen Sie das Diagramm so an, dass die Anzahl der sich kreuzenden Linien minimiert wird. Dies verbessert den visuellen Fluss und verringert die kognitive Anstrengung, um Datenpfade nachzuverfolgen.
- Verwenden Sie Legenden und Schlüssel: Wenn spezielle Symbole für Sicherheit, Datentypen oder externe Systeme verwendet werden, stellen Sie eine Legende bereit. Gehen Sie nicht davon aus, dass der Leser die Bedeutung jedes Symbols kennt.
- Link zu Spezifikationen: Wo möglich, verknüpfen Sie das Diagramm mit detaillierten Anforderungsdokumenten oder Code-Repositories. Dies schafft eine Brücke zwischen der übergeordneten Sicht und den Implementierungsdetails.
- Bleiben Sie aktuell:Priorisieren Sie die Genauigkeit des Diagramms gegenüber einem perfekten Aussehen. Ein etwas unordentliches, aber genaues Diagramm ist nützlicher als ein aufgeräumtes, aber veraltetes.
Integration mit anderen Dokumenten 📝
Ein DFD existiert nicht isoliert. Er ist Teil eines größeren Ökosystems an technischer Dokumentation. Um seinen Wert zu maximieren, muss er mit anderen Artefakten integriert werden.
- Datenbank-Schema:Die Datenspeicher im DFD sollten direkt dem Datenbank-Schema entsprechen. Dadurch wird sichergestellt, dass die physische Implementierung der logischen Gestaltung entspricht.
- API-Spezifikationen:Die Flüsse zwischen externen Entitäten und Prozessen entsprechen oft API-Endpunkten. Die Querverweise in diesen Dokumenten helfen, die Integrationspunkte zu validieren.
- Sicherheitsrichtlinien:Datenflüsse, die sensible Informationen betreffen, sollten mit Sicherheitsrichtlinien abgeglichen werden. Dadurch wird sichergestellt, dass Verschlüsselungs- und Zugriffssteuerungsanforderungen erfüllt sind.
- Testfälle:Testfälle sollten aus den Datenflüssen abgeleitet werden. Jeder Fluss stellt einen möglichen Testpfad dar. Dadurch wird eine umfassende Abdeckung der Systemlogik sichergestellt.
Häufige Fehler, die vermieden werden sollten ⚠️
Selbst mit den besten Absichten können Teams Fehler machen, wenn sie DFDs skalieren. Die Aufmerksamkeit für diese Fallen hilft, häufige Fallen zu vermeiden.
- Überdimensionierung:Erstellen Sie kein Diagramm, das für die Ebene zu detailliert ist. Ein Diagramm der Ebene 1 sollte die Logik eines Prozesses der Ebene 2 nicht enthalten. Halten Sie die Abstraktionsstufe angemessen.
- Ignorieren von Steuerflüssen:Während DFDs sich auf Daten konzentrieren, sind Steuerzeichen (wie „Start“, „Stop“, „Fehler“) oft in komplexen Systemen notwendig. Unterscheiden Sie diese klar von Datenflüssen.
- Annahme der Linearität:Systeme sind selten linear. Schleifen, Rückkopplungsmechanismen und asynchrone Ereignisse sind häufig. Stellen Sie diese genau dar, auch wenn das das Lesen des Diagramms erschwert.
- Mangel an Standardisierung:Wenn verschiedene Teammitglieder Diagramme in unterschiedlichen Stilen zeichnen, wird die Gesamtdokumentation fragmentiert. Legen Sie früh ein Stilhandbuch fest und setzen Sie es durch.
Schlussfolgerung zur Skalierbarkeit 🏗️
Die Skalierung von Datenflussdiagrammen ist eine notwendige Disziplin für die Entwicklung robuster, großskaliger Systeme. Es erfordert mehr als nur mehr Kästchen zu zeichnen; es erfordert einen strukturierten Ansatz für Hierarchie, Zerlegung und Wartung. Durch die Einhaltung der in diesem Leitfaden beschriebenen Strategien können Teams Dokumentation erstellen, die die Entwicklung unterstützt, ohne zur Last zu werden. Das Ziel ist Klarheit. Wenn das Diagramm klar ist, ist das System leichter zu verstehen, zu pflegen und zu erweitern. Diese Investition in Dokumentation zahlt sich in Form von weniger Fehlern und schnellerer Einarbeitung neuer Teammitglieder aus.
Denken Sie daran, dass das Diagramm ein Kommunikationswerkzeug ist, kein bloßes technisches Artefakt. Es schließt die Lücke zwischen Geschäftsanforderungen und technischer Umsetzung. Je größer das System wird, desto mehr muss auch die Dokumentation wachsen. Regelmäßige Überprüfungen und strenge Versionskontrolle stellen sicher, dass das DFD während des gesamten Projekt-Lebenszyklus eine zuverlässige Quelle der Wahrheit bleibt. Mit der richtigen Herangehensweise wird die Skalierung von DFDs zu einer beherrschbaren Aufgabe statt zu einem chaotischen Unterfangen.