











In der Architektur von Informationssystemen ist Klarheit Währung. Zwei grundlegende Werkzeuge dominieren das Gebiet der Systemanalyse und Datenbankgestaltung: das Datenumlaufdiagramm (DFD) und das Entitäts-Beziehungs-Diagramm (ERD). Obwohl beide dazu dienen, komplexe Systeme visuell darzustellen, arbeiten sie auf grundlegend unterschiedlichen Abstraktionsebenen. Einem liegt die Bewegung und Transformation zugrunde; dem anderen die Struktur und Speicherung. Die Verwechslung beider kann zu architektonischen Fehlern, Dateninkonsistenzen und Prozessengpässen führen. Dieser Leitfaden bietet einen tiefen Einblick in die Mechanismen, Anwendungen und Unterschiede dieser Modellierungstechniken.
Verständnis des Datenumlaufdiagramms 🔄
Ein Datenumlaufdiagramm zeigt den Fluss von Informationen durch ein System. Es handelt sich um ein prozessorientiertes Modell. Der zentrale Aspekt hierbei ist nicht, wo Daten gespeichert sind, sondern wie sie sich bewegen, verändern und miteinander interagieren. Diese Diagrammart ist entscheidend für das Verständnis der Logik eines Geschäftsprozesses oder einer Softwareanwendung.
Wichtige Bestandteile eines DFD
Um ein gültiges DFD zu erstellen, muss man die vier Standard-Symbole verstehen, die zur Darstellung von Systemelementen verwendet werden:
- Prozesse:Dargestellt durch Kreise oder abgerundete Rechtecke. Ein Prozess transformiert Eingabedaten in Ausgabedaten. Er speichert keine Informationen, sondern wirkt auf sie ein. Beispiele sind „Steuer berechnen“ oder „Anmeldung überprüfen“.
- Datenbanken:Dargestellt durch offene Rechtecke oder parallele Linien. Dies zeigt an, wo Daten ruhend gespeichert werden. Es ist das Gedächtnis des Systems, beispielsweise eine Datei, eine Datenbanktabelle oder ein physisches Archiv.
- Externe Entitäten:Dargestellt durch Quadrate. Es handelt sich um Quellen oder Ziele von Daten außerhalb der Systemgrenze. Sie können Benutzer, andere Systeme oder Hardwaregeräte sein. Sie initiieren oder empfangen Daten, verarbeiten sie jedoch intern nicht.
- Datenflüsse:Dargestellt durch Pfeile. Sie zeigen die Richtung der Datenbewegung zwischen Prozessen, Speichern und Entitäten an. Jeder Fluss muss einen spezifischen Namen haben, der den Inhalt beschreibt, beispielsweise „Rechnung“ oder „Benutzeranfrage“.
Ebenen der DFD-Detailgenauigkeit
DFDs sind hierarchisch aufgebaut. Sie werden selten in einer einzigen Ansicht gezeichnet. Stattdessen werden sie in Ebenen der Detailgenauigkeit aufgeteilt:
- Kontextdiagramm (Ebene 0):Die höchste Ebene der Darstellung. Es zeigt das gesamte System als einen einzigen Prozess, der mit externen Entitäten interagiert. Es definiert die Grenzen.
- Diagramm der Ebene 1:Zerlegt den Hauptprozess in wesentliche Teilprozesse. Es führt die erste Ebene von Datenbanken und Datenflüssen ein.
- Ebene 2 und darüber:Weitere Aufteilung spezifischer Teilprozesse in fein granulierte Aktionen. Diese Ebene wird für detaillierte Spezifikationen verwendet.
Verständnis des Entitäts-Beziehungs-Diagramms 🗃️
Ein Entitäts-Beziehungs-Diagramm konzentriert sich auf die statische Struktur von Daten. Es handelt sich um ein konzeptionelles Modell, das vor allem während der Datenbankgestaltung verwendet wird. Ziel ist es, die Datenintegrität zu gewährleisten, Redundanz zu minimieren und Beziehungen zwischen verschiedenen Informationsbestandteilen zu definieren.
Wichtige Bestandteile eines ERD
Das ERD stützt sich auf eine spezifische Notation, um festzulegen, wie Datenentitäten zueinander in Beziehung stehen:
- Entitäten:Dargestellt durch Rechtecke. Eine Entität ist ein Gegenstand oder Begriff aus der realen Welt, über den Daten gespeichert werden. Beispiele sind „Kunde“, „Produkt“ oder „Bestellung“.
- Attribute:Dargestellt durch Ovale oder innerhalb des Entitätsrechtecks aufgelistet. Sie beschreiben die Eigenschaften einer Entität. Bei einer „Kunde“-Entität könnten Attribute beispielsweise „Name“, „Adresse“ und „Telefonnummer“ sein.
- Beziehungen: Werden durch Rauten oder Linien dargestellt, die Entitäten verbinden. Dies definiert, wie Entitäten miteinander interagieren. Zum Beispiel „stellt“ ein Kunde eine Bestellung auf.
- Kardinalität: Definiert die Anzahl der Beziehungen. Ist es ein-zu-eins? Ein-zu-viele? Viele-zu-viele? Dies bestimmt die strukturellen Einschränkungen der Datenbank.
Normalisierung im ERD-Entwurf
Während DFDs normalerweise keine Normalisierung behandeln, sind ERDs eng damit verknüpft. Der Entwurfsprozess beinhaltet die Organisation von Daten, um Duplikate zu reduzieren. Ein ERD muss die Regeln der ersten Normalform, der zweiten Normalform usw. widerspiegeln. Dadurch wird sichergestellt, dass die resultierende Datenbank effizient und skalierbar ist. Das Versäumnis, Datenstrukturen zu normalisieren, führt oft zu Aktualisierungsanomalien, bei denen die Änderung eines einzelnen Informationsstücks Bearbeitungen an mehreren Stellen erfordert.
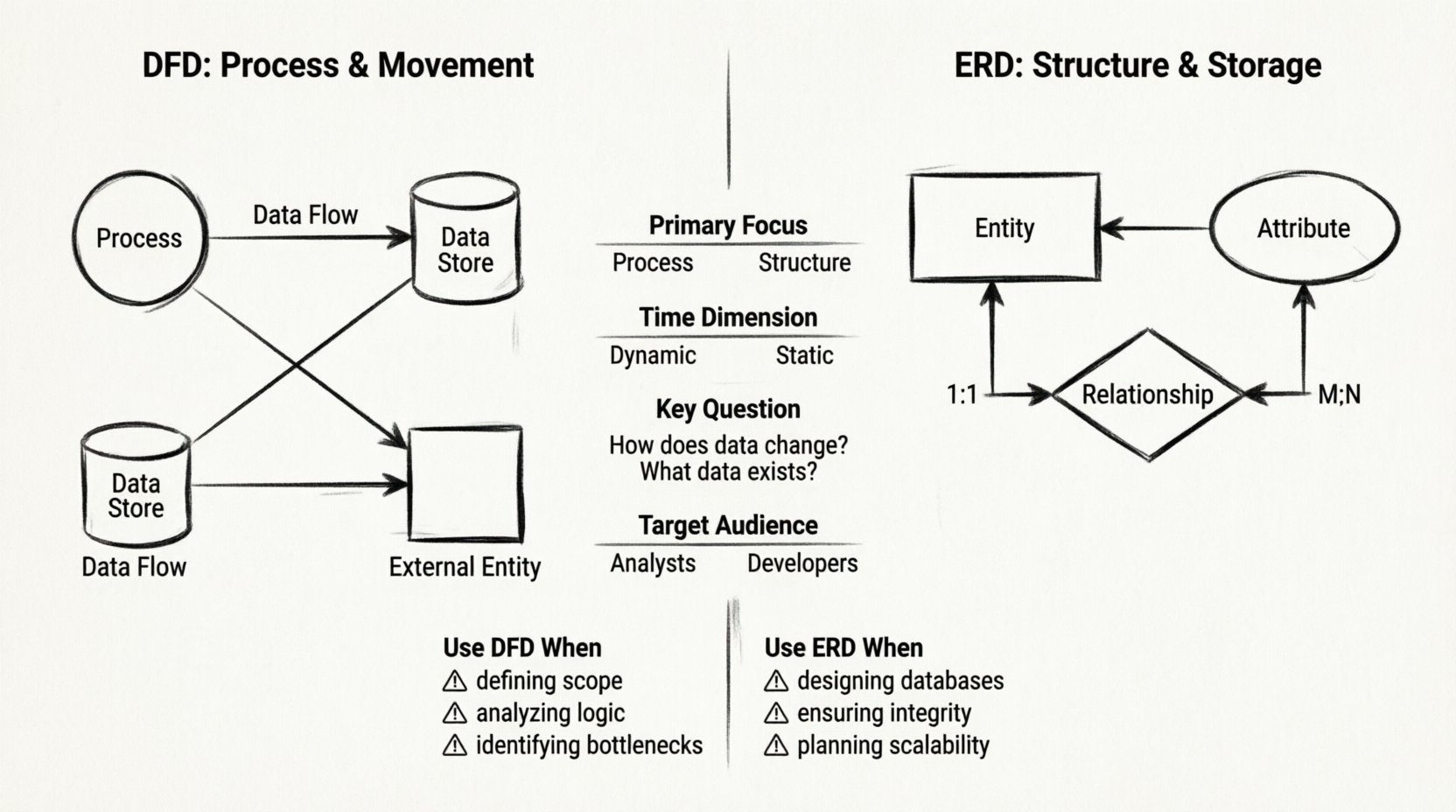
Struktureller Vergleich: DFD vs. ERD 📊
Um die Unterschiede zu klären, vergleichen wir die beiden Modelle über mehrere Dimensionen. Diese Tabelle hebt die funktionelle Divergenz zwischen Prozessfluss und Datenstruktur hervor.
| Funktion | Datenumlaufdiagramm (DFD) | Entitäts-Beziehungs-Diagramm (ERD) |
|---|---|---|
| Hauptaugenmerk | Prozess und Bewegung | Struktur und Speicherung |
| Zeitdimension | Dynamisch (Reihenfolge von Ereignissen) | Statisch (Momentaufnahme der Daten) |
| Wichtige Frage | Wie ändert sich die Daten? | Welche Daten existieren? |
| Zielgruppe | Geschäftsanalysten, Benutzer | Datenbankadministratoren, Entwickler |
| Speicherhandhabung | Generische Datenspeicher | Spezifische Tabellen und Schlüssel |
| Logikdarstellung | Transformationen und Logik | Einschränkungen und Regeln |
Wann soll jedes Diagramm eingesetzt werden 📅
Die Wahl des richtigen Werkzeugs hängt von der Phase des Projektlebenszyklus ab. Die Verwendung eines ERD, um einen Geschäftsprozess einem Stakeholder zu erklären, wird sie verwirren. Die Verwendung eines DFD, um Tabellenbeziehungen einem Entwickler zu erklären, wird sie frustrieren. Hier ist eine Aufschlüsselung optimaler Einsatzszenarien.
Verwenden Sie DFD, wenn:
- Definition des Systemumfangs: Sie müssen zeigen, was innerhalb des Systems liegt, im Gegensatz zu dem, was außerhalb liegt.
- Analyse der Geschäftslogik: Sie müssen nachvollziehen können, wie eine Anforderung von einer Benutzereingabe zu einer gespeicherten Aufzeichnung gelangt.
- Identifizierung von Engpässen: Sie müssen sehen können, wo Daten sich ansammeln oder wo Prozesse stocken.
- Kommunikation mit Stakeholdern:Nicht-technische Benutzer verstehen Abläufe besser als Tabellen.
Verwenden Sie ERD, wenn:
- Entwicklung von Datenbanken:Sie richten die physische oder logische Speicherebene ein.
- Sicherstellung der Datenintegrität:Sie müssen Primärschlüssel, Fremdschlüssel und Einschränkungen definieren.
- Planung für Skalierbarkeit:Sie müssen sicherstellen, dass das Datenmodell zukünftiges Wachstum ohne Redundanz unterstützt.
- API-Dokumentation:Sie müssen das Schema definieren, das externen Verbrauchern zugänglich gemacht wird.
Erstellen eines Datenflussdiagramms von Grund auf 🛠️
Die Erstellung eines robusten DFD erfordert einen systematischen Ansatz. Bei der Zielsetzung der Genauigkeit gibt es keine Abkürzungen in diesem Prozess. Befolgen Sie diese Schritte, um ein zuverlässiges Modell zu erstellen.
Schritt 1: Identifizieren der Grenzen
Beginnen Sie mit der Definition der Systemgrenze. Was liegt im Umfang? Was ist extern? Zeichnen Sie ein Rechteck um das System. Alles, was innerhalb liegt, ist Teil des Systems; alles außerhalb ist eine externe Entität.
Schritt 2: Abbildung externer Entitäten
Listen Sie alle Personen, Abteilungen oder Systeme auf, die mit Ihrem Projekt interagieren. Zeichnen Sie sie außerhalb der Grenze. Beschriften Sie sie deutlich.
Schritt 3: Definition der Hauptprozesse
Identifizieren Sie die Hauptfunktionen des Systems. Diese werden zu Kreisen im Diagramm. Zum Beispiel könnten bei der Entwicklung eines Bibliothekssystems die Prozesse „Buch ausleihen“ und „Buch zurückgeben“ sein.
Schritt 4: Verbinden mit Datenflüssen
Zeichnen Sie Pfeile, die Entitäten mit Prozessen und Prozesse mit Datenspeichern verbinden. Stellen Sie sicher, dass jeder Pfeil beschriftet ist. Ein Datenfluss ohne Namen ist bedeutungslos. Stellen Sie sicher, dass Daten nicht direkt von einer Entität zu einer anderen Entität fließen, ohne dass sie zuvor einen Prozess durchlaufen.
Schritt 5: Überprüfung der Erhaltung
Überprüfen Sie die Datenkonservierung. Wenn ein Prozess Daten ausgibt, müssen diese von irgendwoher stammen. Wenn ein Prozess Eingaben erhält, müssen diese irgendwohin gehen. Es sollte keine Daten geben, die einfach verschwinden oder aus dem Nichts auftauchen.
Erstellen eines Entitäts-Beziehungs-Diagramms von Grund auf 🏗️
Ein ERD erfordert Genauigkeit bezüglich Beziehungen und Schlüssel. Die Struktur bestimmt die Leistungsfähigkeit und Zuverlässigkeit der Anwendung.
Schritt 1: Entitäten identifizieren
Scannen Sie die Anforderungen nach Substantiven. Dies sind potenzielle Entitäten. Streichen Sie vage Substantive aus. Behalten Sie nur solche, die eindeutige, wertvolle Objekte darstellen. Zum Beispiel sind in einem Krankenhaus-System „Patient“ und „Arzt“ Entitäten. „Behandlung“ könnte eine Entität oder eine Beziehung sein, abhängig von der Komplexität.
Schritt 2: Attribute definieren
Listen Sie die spezifischen Details für jede Entität auf. Bestimmen Sie, welche Attribute eindeutige Identifikatoren (Primärschlüssel) sind. Bei einer „Patient“-Entität ist die „Patienten-ID“ der Schlüssel. „Name“ ist ein Attribut. Stellen Sie sicher, dass Attribute atomar sind; speichern Sie „Adresse“ nicht als einzelnes Feld, wenn Sie nach Stadt abfragen müssen.
Schritt 3: Beziehungen festlegen
Ermitteln Sie, wie Entitäten miteinander verbunden sind. Ein Patient wird von einem Arzt behandelt. Dies ist eine Beziehung. Bestimmen Sie die Kardinalität. Behandelt ein Arzt viele Patienten? Ja. Ist es eine viele-zu-viele-Beziehung? Ja. Hat ein Patient viele Ärzte? Ja.
Schritt 4: Lösen von viele-zu-viele-Beziehungen
Datenbanken können viele-zu-viele-Beziehungen nicht natively speichern. Wenn ein Student viele Kurse besuchen kann und ein Kurs viele Studenten hat, müssen Sie eine assoziative Entität (häufig als Verknüpfungstabelle bezeichnet) erstellen. Dadurch wird die Beziehung in zwei viele-zu-eins-Beziehungen aufgeteilt.
Schritt 5: Überprüfung der Normalformen
Wenden Sie die Normalisierungsregeln an. Stellen Sie sicher, dass nicht-schlüsselbezogene Attribute sich ausschließlich auf den Primärschlüssel beziehen. Wenn ein Attribut nur einen Teil des Schlüssels beeinflusst, verschieben Sie es in eine neue Entität. Dieser Schritt verhindert Datenanomalien.
Häufige Fehler, die vermieden werden sollten ⚠️
Selbst erfahrene Architekten machen Fehler beim Modellieren. Die Kenntnis häufiger Fehler hilft, die Integrität des Designs zu erhalten.
DFD-Fehler
- Datenflüsse zwischen Entitäten:Daten müssen immer durch einen Prozess laufen. Direkte Linien zwischen externen Entitäten deuten auf mangelnde Systemkontrolle hin.
- Schwarze Löcher: Ein Prozess, der Eingaben hat, aber keine Ausgaben. Dies ist logisch unmöglich in einem funktionierenden System.
- Graue Löcher: Ein Prozess mit Eingaben, aber keinerlei Ausgaben, oder Ausgaben, die den Eingabeanforderungen nicht entsprechen.
- Unbenannte Flüsse: Ein Pfeil ohne Namen gibt keine Informationen über den übertragenen Inhalt.
ERD-Fehler
- Fehlende Kardinalität:Das Auslassen der Definition, ob eine Beziehung eine-eins- oder eine-zu-viele-Beziehung ist, führt zu Unklarheiten bei der Implementierung im Code.
- Redundante Entitäten:Erstellen von Entitäten, die im Wesentlichen Duplikate anderer sind, was zu Dateninkonsistenzen führt.
- Ignorieren von Nullwerten: Das Versäumnis, zu entscheiden, ob ein Attribut leer sein kann. Dies beeinflusst Datenbankbeschränkungen und Anwendungslogik.
- Über-Normalisierung:Die Aufteilung von Daten in zu viele Tabellen kann Abfragen langsam und komplex machen. Gleichgewicht ist entscheidend.
Beide in der Systemarchitektur integrieren 🏗️
Während DFDs und ERDs unterschiedlich sind, sind sie nicht wechselseitig ausschließend. Eine reife Systemgestaltung nutzt beide gleichzeitig. Der DFD beschreibt die Reise der Daten, während der ERD das Ziel und die Speicherung der Daten beschreibt.
Der Integrationsprozess
Während der Anforderungsphase beginnen Sie mit einem Kontextdiagramm. Dies legt die Grundlage. Wenn Sie das System zerlegen, identifizieren Sie Datenspeicher. Diese Datenspeicher werden letztendlich zu Entitäten in Ihrem ERD. Die Flüsse im DFD werden zu Fremdschlüsseln und Beziehungen im ERD.
Zum Beispiel, wenn ein DFD einen Prozess „Profil aktualisieren“ zeigt, der Daten in einen „Benutzer-Info“-Speicher bewegt, muss der ERD eine „Benutzer“-Entität mit Attributen definieren, die mit diesem Speicher übereinstimmen. Die Beziehung zwischen Prozess und Speicher im DFD informiert über Lese-/Schreibberechtigungen und Transaktionslogik im ERD.
Konsistenz der Dokumentation
Die Konsistenz zwischen den beiden Diagrammen ist entscheidend. Wenn sich der DFD ändert, um eine neue Datenquelle hinzuzufügen, muss der ERD aktualisiert werden, um die neue Tabelle oder Spalte widerzuspiegeln. Wenn sich der ERD in der Struktur einer Tabelle ändert, muss der DFD den neuen Datenflussnamen oder -ziel anzeigen. Abweichungen führen hier zu Integrationsfehlern und Datenverlust.
Fortgeschrittene Überlegungen für moderne Systeme 🚀
Obwohl diese Diagramme in der Ära der Mainframes entstanden sind, bleiben ihre Prinzipien auch in modernen Microservices- und Cloud-Architekturen relevant.
Cloud und DFDs
In Cloud-Umgebungen durchlaufen Datenflüsse oft verschiedene Regionen oder Dienste. Ein DFD muss diese Grenzen explizit anzeigen. Er hilft dabei, Latenz und Anforderungen an die Datenhoheit zu verstehen. Wenn beispielsweise Daten von einem Benutzer in Europa zu einem Server in den USA fließen, können Compliance-Vorschriften gelten.
NoSQL und ERDs
Traditionelle ERDs gehen von einer relationalen Struktur aus. NoSQL-Datenbanken verwenden oft Dokument- oder Graphmodelle. Während das Kernkonzept von Entitäten und Beziehungen erhalten bleibt, unterscheidet sich die Umsetzung. In einem Dokumentenspeicher ist die „Entität“ das Dokument selbst. Beziehungen könnten eingebettet oder über IDs verknüpft sein, anstatt strikter Fremdschlüssel. Der ERD dient weiterhin als Bauplan, doch die Notation kann sich an die schemafreie Natur der Technologie anpassen.
Zusammenfassung der Unterschiede
Der Unterschied zwischen diesen beiden Diagrammen liegt in ihrem Zweck. Der DFD ist eine Karte der Bewegung. Er beantwortet die Frage: „Was geschieht mit den Daten?“ Der ERD ist eine Karte der Struktur. Er beantwortet die Frage: „Was sind die Daten?“ Beide sind erforderlich, um ein vollständiges Bild eines Software-Systems zu erhalten. Die Abhängigkeit von nur einem ohne den anderen hinterlässt eine Lücke im Verständnis, die das Projekt gefährden kann.
Durch die Beherrschung der Erstellung und Anwendung beider Modelle stellen Sie sicher, dass das System nicht nur in seinen Abläufen funktional ist, sondern auch in der Datenverwaltung robust. Dieser doppelte Ansatz berücksichtigt die dynamischen und statischen Aspekte der Informationsarchitektur und bietet eine umfassende Grundlage für Entwicklung und Analyse.
Häufig gestellte Fragen
Kann ich ein Diagramm für beide Zwecke verwenden?
Nein. Ein DFD kann Tabellenschlüssel oder Normalisierungsregeln nicht effektiv darstellen. Ein ERD kann Prozesslogik oder Schritte der Datenumwandlung nicht effektiv darstellen. Sie dienen unterschiedlichen Stakeholdern und Phasen.
Welches sollte ich zuerst erstellen?
Typischerweise beginnen Sie mit dem DFD. Sie müssen die Prozesse verstehen, bevor Sie wissen, welche Daten gespeichert werden müssen. Sobald die Datenspeicher im DFD identifiziert sind, können Sie sie zu einem vollständigen ERD erweitern.
Funktionieren diese Diagramme mit agilen Methoden?
Ja. In agilen Methoden werden diese Diagramme oft genau dann erstellt, wenn sie für bestimmte User Stories benötigt werden, anstatt als umfangreiche Dokumente zu Beginn. Sie dienen als lebendige Dokumentation, die sich mit dem Produkt entwickelt.