











Dans l’architecture des systèmes d’information, la clarté est la monnaie. Deux outils fondamentaux dominent le paysage de l’analyse des systèmes et de la conception des bases de données : le diagramme de flux de données (DFD) et le diagramme entité-association (ERD). Bien qu’ils servent tous deux à visualiser des systèmes complexes, ils opèrent sur des plans d’abstraction fondamentalement différents. L’un se concentre sur le mouvement et la transformation ; l’autre sur la structure et le stockage. Confondre les deux peut entraîner des échecs architecturaux, des incohérences de données et des goulets d’étranglement dans les processus. Ce guide offre une analyse approfondie des mécanismes, des applications et des distinctions de ces techniques de modélisation.
Comprendre le diagramme de flux de données 🔄
Un diagramme de flux de données représente le flux d’information à travers un système. Il s’agit d’un modèle orienté processus. L’objectif principal ici n’est pas de savoir où les données sont stockées, mais de comprendre comment elles se déplacent, évoluent et interagissent. Ce type de diagramme est essentiel pour comprendre la logique d’un processus métier ou d’une application logicielle.
Composants fondamentaux d’un DFD
Pour construire un DFD valide, il faut comprendre les quatre symboles standards utilisés pour représenter les éléments du système :
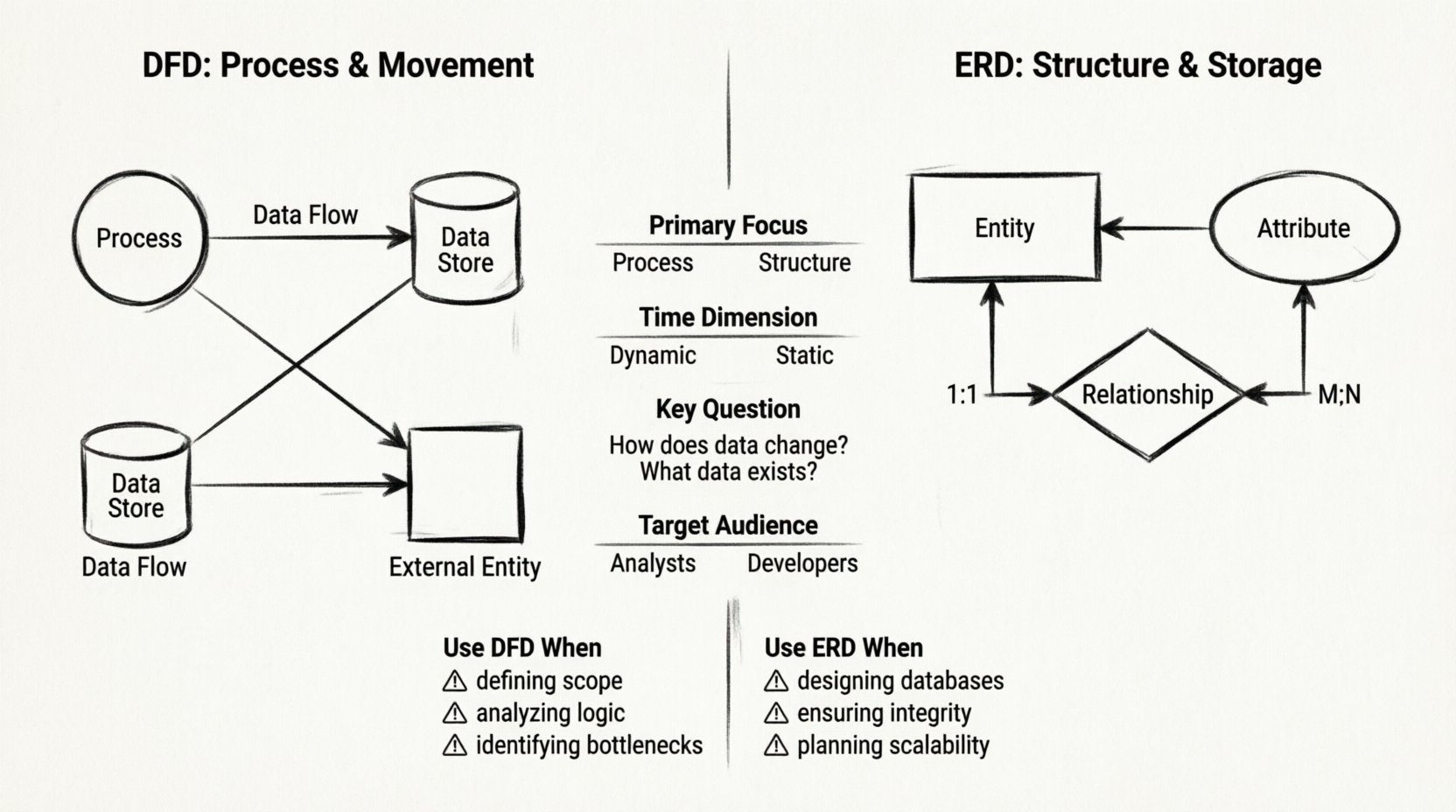
- Processus :Représentés par des cercles ou des rectangles arrondis. Un processus transforme les données d’entrée en données de sortie. Il ne stocke pas d’information, mais agit sur elle. Des exemples incluent « Calculer la taxe » ou « Valider la connexion ».
- Stockages de données :Représentés par des rectangles ouvertes ou des lignes parallèles. Cela indique l’emplacement où les données sont stockées au repos. C’est la mémoire du système, comme un fichier, une table de base de données ou un archivage physique.
- Entités externes :Représentés par des carrés. Ce sont des sources ou des destinations de données situées à l’extérieur de la frontière du système. Ils peuvent être des utilisateurs, d’autres systèmes ou des périphériques matériels. Ils initient ou reçoivent des données, mais ne les traitent pas internement.
- Flux de données :Représentés par des flèches. Elles indiquent la direction du déplacement des données entre les processus, les stockages et les entités. Chaque flux doit avoir un nom spécifique décrivant son contenu, comme « Facture » ou « Demande utilisateur ».
Niveaux de détail du DFD
Les DFD sont hiérarchiques. Ils sont rarement dessinés en une seule vue. En revanche, ils sont décomposés en niveaux de détail :
- Diagramme de contexte (niveau 0) :La vue de niveau le plus élevé. Il représente l’ensemble du système comme un seul processus interagissant avec des entités externes. Il définit les limites.
- Diagramme de niveau 1 :Décompose le processus principal en sous-processus majeurs. Il introduit la première couche de stockages de données et de flux.
- Niveau 2 et au-delà :Découpage supplémentaire de sous-processus spécifiques en actions granulaires. Ce niveau est utilisé pour une spécification détaillée.
Comprendre le diagramme entité-association 🗃️
Un diagramme entité-association se concentre sur la structure statique des données. Il s’agit d’un modèle conceptuel utilisé principalement pendant la phase de conception de base de données. L’objectif est de garantir l’intégrité des données, de minimiser la redondance et de définir les relations entre différentes pièces d’information.
Composants fondamentaux d’un ERD
L’ERD repose sur une notation spécifique pour définir la manière dont les entités de données se rapportent les unes aux autres :
- Entités :Représentées par des rectangles. Une entité est un objet ou un concept du monde réel dont les données sont stockées. Des exemples incluent « Client », « Produit » ou « Commande ».
- Attributs :Représentés par des ovales ou listés à l’intérieur du rectangle de l’entité. Ils décrivent les propriétés d’une entité. Pour une entité « Client », les attributs pourraient inclure « Nom », « Adresse » et « Numéro de téléphone ».
- Relations : Représentées par des losanges ou des lignes reliant des entités. Cela définit la manière dont les entités interagissent. Par exemple, un Client « Place » une Commande.
- Cardinalité : Définit la quantité de relations. S’agit-il d’une relation un-à-un ? un-à-plusieurs ? plusieurs-à-plusieurs ? Cela détermine les contraintes structurelles de la base de données.
Normalisation dans la conception des diagrammes Entité-Relation
Bien que les diagrammes de flux de données (DFD) n’abordent généralement pas la normalisation, les diagrammes Entité-Relation (ERD) y sont profondément liés. Le processus de conception consiste à organiser les données afin de réduire la duplication. Un ERD doit refléter les règles de la Première Forme Normale, de la Deuxième Forme Normale, etc. Cela garantit que la base de données résultante est efficace et évolutif. Le fait de ne pas normaliser les structures de données conduit souvent à des anomalies de mise à jour, où modifier une seule information nécessite des modifications à plusieurs endroits.
Comparaison structurelle : DFD vs. ERD 📊
Pour clarifier les différences, nous comparons les deux modèles selon plusieurs dimensions. Ce tableau met en évidence la divergence fonctionnelle entre le flux de processus et la structure des données.
| Fonctionnalité | Diagramme de flux de données (DFD) | Diagramme Entité-Relation (ERD) |
|---|---|---|
| Focus principal | Processus et mouvement | Structure et stockage |
| Dimension temporelle | Dynamique (séquence d’événements) | Statique (instantané des données) |
| Question clé | Comment les données évoluent-elles ? | Quelles données existent ? |
| Public cible | Analystes métiers, utilisateurs | Administrateurs de bases de données, développeurs |
| Gestion du stockage | Magasins de données génériques | Tables et clés spécifiques |
| Représentation de la logique | Transformations et logique | Contraintes et règles |
Quand déployer chaque diagramme 📅
Le choix de l’outil approprié dépend de la phase du cycle de vie du projet. Utiliser un MCD pour expliquer un processus métier à un intervenant le confondra. Utiliser un MLD pour expliquer les relations entre les tables à un développeur le frustrera. Voici une analyse des scénarios d’utilisation optimaux.
Utilisez le MLD lorsque :
- Définition du périmètre du système : Vous devez montrer ce qui se trouve à l’intérieur du système par rapport à ce qui se trouve à l’extérieur.
- Analyse de la logique métier : Vous devez suivre le parcours d’une requête depuis une entrée utilisateur jusqu’à un enregistrement stocké.
- Identification des goulets d’étranglement : Vous devez voir où les données s’accumulent ou où les processus s’arrêtent.
- Communication avec les intervenants : Les utilisateurs non techniques comprennent mieux les flux que les tableaux.
Utilisez le MCD lorsque :
- Conception de bases de données : Vous êtes en train de mettre en place la couche de stockage physique ou logique.
- Assurance de l’intégrité des données : Vous devez définir les clés primaires, les clés étrangères et les contraintes.
- Planification de la scalabilité : Vous devez vous assurer que le modèle de données supporte la croissance future sans redondance.
- Documentation de l’API : Vous devez définir le schéma qui sera exposé aux consommateurs externes.
Construction d’un diagramme de flux de données depuis zéro 🛠️
Créer un MLD robuste exige une approche méthodique. Il n’y a pas de raccourcis dans ce processus si l’exactitude est l’objectif. Suivez ces étapes pour construire un modèle fiable.
Étape 1 : Identifier les limites
Commencez par définir la limite du système. Qu’est-ce qui est inclus dans le périmètre ? Qu’est-ce qui est externe ? Dessinez un cadre autour du système. Tout ce qui est à l’intérieur fait partie du système ; tout ce qui est à l’extérieur est une entité externe.
Étape 2 : Cartographier les entités externes
Listez toutes les personnes, départements ou systèmes qui interagissent avec votre projet. Dessinez-les à l’extérieur de la limite. Étiquetez-les clairement.
Étape 3 : Définir les principaux processus
Identifiez les fonctions principales du système. Elles deviennent les cercles du diagramme. Par exemple, si vous construisez un système de bibliothèque, les processus pourraient inclure « Distribuer un livre » et « Rendre un livre ».
Étape 4 : Connecter par des flux de données
Dessinez des flèches reliant les entités aux processus et les processus aux entrepôts de données. Assurez-vous que chaque flèche porte une étiquette. Un flux de données sans nom est sans signification. Assurez-vous que les données ne circulent pas directement d’une entité à une autre sans passer par un processus.
Étape 5 : Vérifier la conservation
Vérifiez la conservation des données. Si un processus produit des données, celles-ci doivent provenir de quelque part. Si un processus reçoit une entrée, elle doit aller quelque part. Aucune donnée ne doit disparaître ou apparaître de nulle part.
Création d’un diagramme entité-association depuis zéro 🏗️
Un diagramme entité-association exige une précision concernant les relations et les clés. La structure détermine les performances et la fiabilité de l’application.
Étape 1 : Identifier les entités
Analysez les exigences à la recherche de noms communs. Ceux-ci sont des entités potentielles. Éliminez les noms vagues. Gardez uniquement ceux qui représentent des objets distincts de valeur. Par exemple, dans un système hospitalier, « Patient » et « Médecin » sont des entités. « Traitement » pourrait être une entité ou une relation, selon la complexité.
Étape 2 : Définir les attributs
Listez les détails spécifiques pour chaque entité. Déterminez quels attributs sont des identifiants uniques (clés primaires). Pour une entité « Patient », « ID du patient » est la clé. « Nom » est un attribut. Assurez-vous que les attributs sont atomiques ; ne stockez pas « Adresse » dans un seul champ si vous devez effectuer des requêtes par ville.
Étape 3 : Établir les relations
Déterminez comment les entités sont connectées. Un patient est traité par un médecin. Cela constitue une relation. Déterminez la cardinalité. Un médecin traite-t-il plusieurs patients ? Oui. S’agit-il d’une relation plusieurs-à-plusieurs ? Oui. Un patient a-t-il plusieurs médecins ? Oui.
Étape 4 : Résoudre les relations plusieurs-à-plusieurs
Les bases de données ne peuvent pas stocker nativement les relations plusieurs-à-plusieurs. Si un étudiant peut suivre plusieurs cours et qu’un cours comporte plusieurs étudiants, vous devez créer une entité associative (souvent appelée table de jonction). Cela divise la relation en deux relations un-à-plusieurs.
Étape 5 : Vérifier les formes normales
Appliquez les règles de normalisation. Assurez-vous que les attributs non clés dépendent uniquement de la clé primaire. Si un attribut dépend d’une partie de la clé, déplacez-le vers une nouvelle entité. Cette étape prévient les anomalies de données.
Péchés courants à éviter ⚠️
Même les architectes expérimentés commettent des erreurs lors de la modélisation. Être conscient des erreurs courantes aide à préserver l’intégrité du design.
Pièges des diagrammes de flux de données
- Flux de données entre les entités :Les données doivent toujours passer par un processus. Des lignes directes entre des entités externes suggèrent un manque de contrôle du système.
- Les trous noirs :Un processus qui a une entrée mais aucune sortie. Cela est logiquement impossible dans un système fonctionnel.
- Les trous gris :Un processus ayant une entrée mais aucune sortie du tout, ou une sortie qui ne correspond pas aux exigences d’entrée.
- Flux non étiquetés :Une flèche sans nom ne fournit aucune information sur le contenu transféré.
Pièges des diagrammes entité-association
- Cardinalité manquante :Ne pas définir si une relation est une-à-une ou une-à-plusieurs entraîne une ambiguïté dans l’implémentation du code.
- Entités redondantes :Créer des entités qui sont essentiellement des duplicatas d’autres, entraînant une incohérence des données.
- Ignorer les valeurs nulles : Ne pas parvenir à décider si un attribut peut être vide. Cela affecte les contraintes de base de données et la logique de l’application.
- Sur-normalisation : Diviser les données en trop nombreuses tables peut ralentir et compliquer les requêtes. L’équilibre est la clé.
Intégrer les deux dans l’architecture du système 🏗️
Bien que les diagrammes de flux de données (DFD) et les diagrammes entité-association (ERD) soient distincts, ils ne sont pas mutuellement exclusifs. Une conception mature de système utilise les deux conjointement. Le DFD décrit le parcours des données, tandis que l’ERD décrit la destination et le stockage des données.
Le processus d’intégration
Pendant la phase de spécifications, commencez par un diagramme de contexte. Cela fixe le cadre. En décomposant le système, vous identifierez des magasins de données. Ces magasins de données deviennent finalement les entités de votre ERD. Les flux du DFD deviennent les clés étrangères et les relations dans l’ERD.
Par exemple, si un DFD montre un processus « Mettre à jour le profil » qui déplace des données vers un magasin « Informations utilisateur », l’ERD doit définir une entité « Utilisateur » avec des attributs correspondant à ce magasin. La relation entre le processus et le magasin dans le DFD informe les autorisations de lecture/écriture et la logique des transactions dans l’ERD.
Consistance de la documentation
Maintenir la cohérence entre les deux diagrammes est essentiel. Si le DFD change pour ajouter une nouvelle source de données, l’ERD doit être mis à jour pour refléter la nouvelle table ou colonne. Si l’ERD modifie la structure d’une table, le DFD doit afficher le nouveau nom de flux de données ou sa destination. Les écarts ici entraînent des bogues d’intégration et des pertes de données.
Considérations avancées pour les systèmes modernes 🚀
Bien que ces diagrammes aient vu le jour à l’époque des systèmes centraux, leurs principes restent pertinents dans les architectures modernes de microservices et de cloud.
Cloud et DFD
Dans les environnements cloud, les flux de données traversent souvent différentes régions ou services. Un DFD doit explicitement montrer ces frontières. Cela aide à comprendre les contraintes de latence et de souveraineté des données. Par exemple, si les données circulent d’un utilisateur en Europe vers un serveur aux États-Unis, des réglementations de conformité peuvent s’appliquer.
NoSQL et ERD
Les ERD traditionnels supposent une structure relationnelle. Les bases de données NoSQL utilisent souvent des modèles document ou graphe. Bien que le concept fondamental d’entités et de relations demeure, l’implémentation diffère. Dans un magasin de documents, l’« entité » est le document lui-même. Les relations peuvent être intégrées ou liées via des identifiants plutôt que par des clés étrangères strictes. L’ERD continue de servir de plan, mais la notation peut s’adapter à la nature sans schéma de la technologie.
Résumé des différences
La différence entre ces deux diagrammes réside dans leur intention. Le DFD est une carte du mouvement. Il répond à la question : « Que devient les données ? » L’ERD est une carte de structure. Il répond à la question : « Qu’est-ce que les données ? » Les deux sont nécessaires pour avoir une vision complète d’un système logiciel. Se fier à l’un sans l’autre laisse une lacune dans la compréhension qui peut compromettre le projet.
En maîtrisant la construction et l’application des deux modèles, vous assurez que le système est non seulement fonctionnel dans ses opérations, mais aussi robuste dans sa gestion des données. Cette approche double couvre les aspects dynamiques et statiques de l’architecture de l’information, offrant une base complète pour le développement et l’analyse.
Questions fréquemment posées
Puis-je utiliser un seul diagramme à la fois ?
Non. Un DFD ne peut pas efficacement montrer les clés de table ou les règles de normalisation. Un ERD ne peut pas efficacement montrer la logique des processus ou les étapes de transformation des données. Ils servent des parties prenantes et des phases différentes.
Lequel dois-je créer en premier ?
Généralement, commencez par le DFD. Vous devez comprendre les processus avant de savoir quelles données doivent être stockées. Une fois les magasins de données identifiés dans le DFD, vous pouvez les développer en un ERD complet.
Ces diagrammes fonctionnent-ils avec les méthodologies Agile ?
Oui. Dans Agile, ces diagrammes sont souvent créés au moment opportun pour des histoires d’utilisateur spécifiques, plutôt que comme de gros documents préliminaires. Ils servent de documentation vivante qui évolue avec le produit.