











सूचना प्रणालियों की वास्तुकला में स्पष्टता मुद्रा है। तकनीकी विश्लेषण और डेटाबेस डिजाइन के क्षेत्र में दो मूलभूत उपकरण प्रमुख हैं: डेटा फ्लो डायग्राम (DFD) और एंटिटी रिलेशनशिप डायग्राम (ERD)। दोनों जटिल प्रणालियों के दृश्यमान रूप से प्रस्तुत करने के उद्देश्य से उपयोग किए जाते हैं, लेकिन वे मूल रूप से अलग-अलग स्तरों पर अब्स्ट्रैक्शन पर काम करते हैं। एक गति और परिवर्तन पर ध्यान केंद्रित करता है; दूसरा संरचना और भंडारण पर। दोनों को गलती से मिलाने से वास्तुकला की विफलता, डेटा असंगतता और प्रक्रिया के बॉटलनेक आ सकते हैं। यह मार्गदर्शिका इन मॉडलिंग तकनीकों के यांत्रिकी, उपयोग और अंतरों के गहन विश्लेषण का अवलोकन करती है।
डेटा फ्लो डायग्राम को समझना 🔄
एक डेटा फ्लो डायग्राम एक प्रणाली के माध्यम से सूचना के प्रवाह को नक्शा बनाता है। यह एक प्रक्रिया-केंद्रित मॉडल है। यहाँ मुख्य चिंता यह नहीं है कि डेटा कहाँ रहता है, बल्कि यह है कि डेटा कैसे आगे बढ़ता है, कैसे बदलता है और कैसे बातचीत करता है। यह डायग्राम प्रकार व्यवसाय प्रक्रिया या सॉफ्टवेयर एप्लिकेशन की तर्क को समझने के लिए आवश्यक है।
DFD के मुख्य घटक
एक वैध DFD बनाने के लिए, एक को प्रणाली के तत्वों को दर्शाने के लिए उपयोग किए जाने वाले चार मानक प्रतीकों को समझना आवश्यक है:
- प्रक्रियाएँ:वृत्त या गोल कोने वाले आयत द्वारा दर्शाया जाता है। एक प्रक्रिया इनपुट डेटा को आउटपुट डेटा में बदलती है। यह जानकारी को संग्रहीत नहीं करती है, लेकिन इस पर कार्य करती है। उदाहरण के लिए “कर की गणना” या “लॉगिन की पुष्टि”।
- डेटा स्टोर्स:खुले छोर वाले आयत या समानांतर रेखाओं द्वारा दर्शाया जाता है। इससे यह संकेत मिलता है कि डेटा विश्राम की स्थिति में कहाँ रखा जाता है। यह प्रणाली की स्मृति है, जैसे एक फ़ाइल, एक डेटाबेस तालिका या एक भौतिक आर्काइव।
- बाहरी एंटिटीज:वर्गों द्वारा दर्शाया जाता है। ये प्रणाली की सीमा के बाहर डेटा के स्रोत या गंतव्य हैं। इनमें उपयोगकर्ता, अन्य प्रणालियाँ या हार्डवेयर उपकरण शामिल हो सकते हैं। ये डेटा को प्रारंभ करते हैं या उसे प्राप्त करते हैं, लेकिन इसका आंतरिक रूप से प्रसंस्करण नहीं करते हैं।
- डेटा प्रवाह:तीरों द्वारा दर्शाया जाता है। ये प्रक्रियाओं, स्टोर्स और एंटिटीज के बीच डेटा के गति की दिशा दिखाते हैं। प्रत्येक प्रवाह को विशिष्ट नाम होना चाहिए जो उसकी सामग्री का वर्णन करे, जैसे “इन्वॉइस” या “उपयोगकर्ता अनुरोध”।
DFD विवरण के स्तर
DFD हीरार्किक होते हैं। वे एक ही दृश्य में बहुत कम बनाए जाते हैं। इसके बजाय, उन्हें विवरण के स्तरों में विभाजित किया जाता है:
- संदर्भ डायग्राम (स्तर 0):उच्चतम स्तर का दृश्य। यह पूरी प्रणाली को एकल प्रक्रिया के रूप में दिखाता है जो बाहरी एंटिटीज के साथ बातचीत करती है। यह सीमाओं को परिभाषित करता है।
- स्तर 1 डायग्राम:मुख्य प्रक्रिया को मुख्य उप-प्रक्रियाओं में विभाजित करता है। यह डेटा स्टोर्स और प्रवाहों की पहली परत को पेश करता है।
- स्तर 2 और उससे आगे:विशिष्ट उप-प्रक्रियाओं को विस्तृत क्रियाओं में और विभाजित करना। इस स्तर का उपयोग विस्तृत विवरण के लिए किया जाता है।
एंटिटी रिलेशनशिप डायग्राम को समझना 🗃️
एक एंटिटी रिलेशनशिप डायग्राम डेटा की स्थिर संरचना पर ध्यान केंद्रित करता है। यह एक अवधारणात्मक मॉडल है जिसका उपयोग मुख्य रूप से डेटाबेस डिजाइन चरण के दौरान किया जाता है। लक्ष्य डेटा अखंडता सुनिश्चित करना, अतिरिक्तता को कम करना और विभिन्न जानकारी के टुकड़ों के बीच संबंधों को परिभाषित करना है।
ERD के मुख्य घटक
ERD विशिष्ट नोटेशन पर निर्भर करता है जो डेटा एंटिटीज के बीच संबंधों को परिभाषित करता है:
- एंटिटीज:आयतों द्वारा दर्शाया जाता है। एक एंटिटी वास्तविक दुनिया की वस्तु या अवधारणा है जिसके बारे में डेटा संग्रहीत किया जाता है। उदाहरण के लिए “ग्राहक”, “उत्पाद” या “आदेश”।
- गुण:गोलाकार आकृतियों या एंटिटी आयत के भीतर सूचीबद्ध किए जाते हैं। ये एंटिटी के गुणों का वर्णन करते हैं। एक “ग्राहक” एंटिटी के लिए, गुणों में “नाम”, “पता” और “फ़ोन नंबर” शामिल हो सकते हैं।
- संबंध: ही आकृतियों या एकत्रित वस्तुओं को जोड़ने वाली रेखाओं द्वारा दर्शाई जाती है। यह वस्तुओं के बीच बातचीत को परिभाषित करती है। उदाहरण के लिए, एक ग्राहक एक आदेश “देता है”।
- गणना: संबंधों की मात्रा को परिभाषित करता है। क्या यह एक-से-एक है? एक-से-बहुत? बहुत-से-बहुत? यह डेटाबेस की संरचनात्मक सीमाओं को निर्धारित करता है।
ERD डिज़ाइन में सामान्यीकरण
जबकि DFDs आमतौर पर सामान्यीकरण को नहीं संबोधित करते हैं, ERDs इससे गहराई से जुड़े होते हैं। डिज़ाइन प्रक्रिया में डुप्लीकेशन को कम करने के लिए डेटा को व्यवस्थित करना शामिल है। एक ERD को पहले सामान्य रूप, दूसरे सामान्य रूप आदि के नियमों को दर्शाना चाहिए। इससे यह सुनिश्चित होता है कि परिणामी डेटाबेस कुशल और स्केलेबल हो। डेटा संरचनाओं को सामान्यीकृत न करने के कारण अक्सर अपडेट विचलन होते हैं, जहां एक ही जानकारी को बदलने के लिए बहुत स्थानों पर संपादन करने की आवश्यकता होती है।
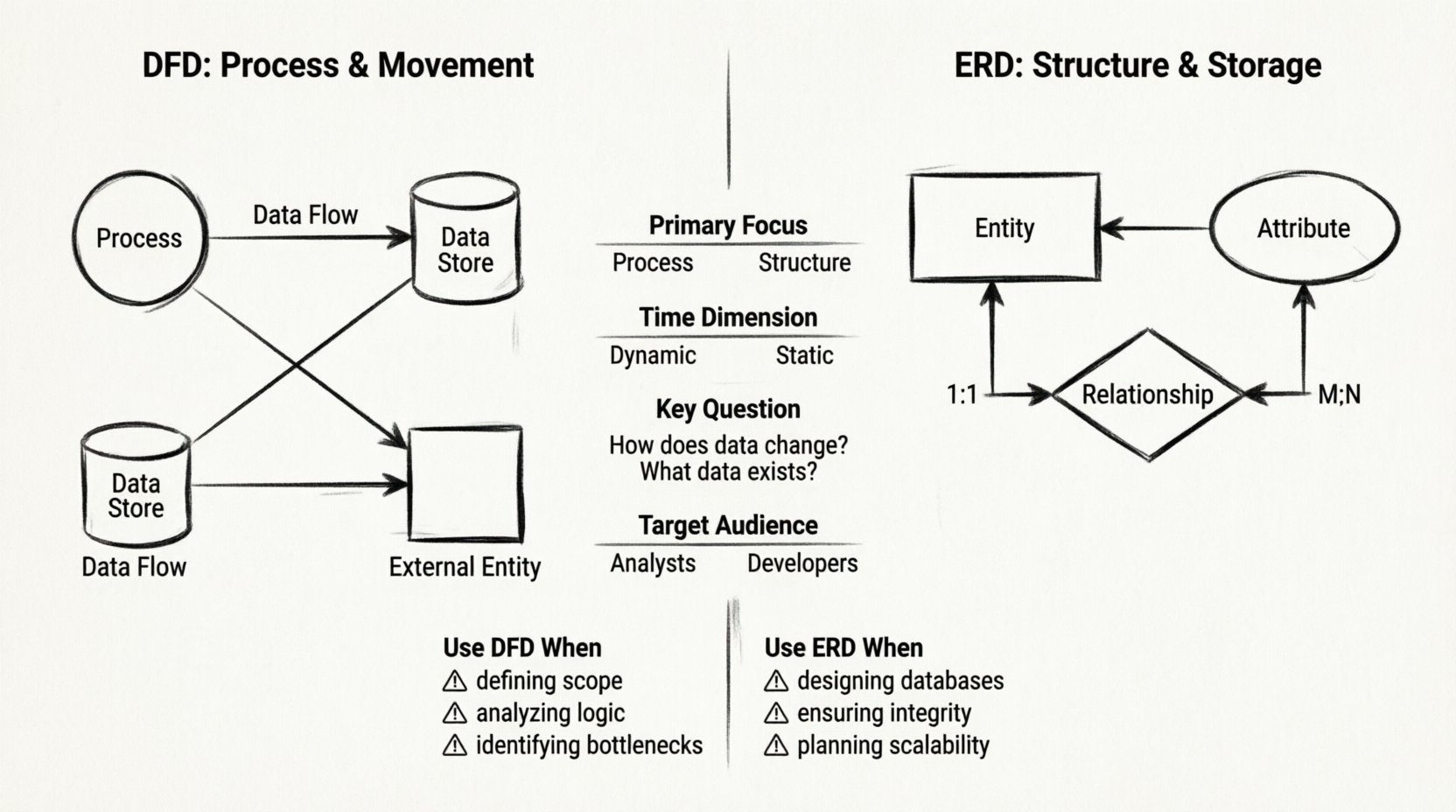
संरचनात्मक तुलना: DFD बनाम ERD 📊
अंतरों को स्पष्ट करने के लिए, हम दोनों मॉडलों की कई दिशाओं के आधार पर तुलना करते हैं। यह तालिका प्रक्रिया प्रवाह और डेटा संरचना के बीच कार्यात्मक विचलन को उजागर करती है।
| विशेषता | डेटा प्रवाह आरेख (DFD) | एंटिटी संबंध आरेख (ERD) |
|---|---|---|
| प्राथमिक ध्यान केंद्र | प्रक्रिया और गति | संरचना और भंडारण |
| समय आयाम | गतिशील (घटनाओं का क्रम) | स्थिर (डेटा की स्नैपशॉट) |
| मुख्य प्रश्न | डेटा कैसे बदलता है? | कौन सा डेटा मौजूद है? |
| लक्षित दर्शक | व्यापार विश्लेषक, उपयोगकर्ता | डेटाबेस प्रबंधक, विकासकर्ता |
| भंडारण प्रबंधन | सामान्य डेटा भंडार | विशिष्ट तालिकाएं और कुंजियां |
| तर्क प्रतिनिधित्व | रूपांतरण और तर्क | सीमाएं और नियम |
प्रत्येक आरेख को कब लगाना है 📅
सही उपकरण का चयन परियोजना जीवन चक्र के चरण पर निर्भर करता है। एक स्टेकहोल्डर को व्यवसाय प्रक्रिया की व्याख्या करने के लिए ERD का उपयोग करने से उन्हें भ्रमित कर दिया जाएगा। एक डेवलपर को तालिका संबंधों की व्याख्या करने के लिए DFD का उपयोग करने से उन्हें निराशा होगी। यहां उत्तम उपयोग के परिदृश्यों का विश्लेषण दिया गया है।
DFD का उपयोग करें जब:
- सिस्टम की सीमा निर्धारित करना: आपको यह दिखाने की आवश्यकता है कि सिस्टम के अंदर क्या है और बाहर क्या है।
- व्यवसाय तर्क का विश्लेषण करना: आपको यह ट्रैक करने की आवश्यकता है कि एक अनुरोध उपयोगकर्ता इनपुट से संग्रहीत रिकॉर्ड तक कैसे आगे बढ़ता है।
- बॉटलनेक की पहचान करना: आपको यह देखने की आवश्यकता है कि डेटा कहां संचित होता है या प्रक्रियाएं कहां रुक जाती हैं।
- स्टेकहोल्डर्स के साथ संचार करना: गैर-तकनीकी उपयोगकर्ता प्रवाह को तालिकाओं की तुलना में बेहतर समझते हैं।
ERD का उपयोग करें जब:
- डेटाबेस डिज़ाइन करना: आप भौतिक या तार्किक स्टोरेज लेयर सेट कर रहे हैं।
- डेटा अखंडता सुनिश्चित करना: आपको प्राथमिक कुंजियों, विदेशी कुंजियों और सीमाओं को परिभाषित करने की आवश्यकता है।
- स्केलेबिलिटी की योजना बनाना: आपको यह सुनिश्चित करने की आवश्यकता है कि डेटा मॉडल भविष्य के विकास को बिना अतिरिक्त डेटा के समर्थन करे।
- API दस्तावेज़ीकरण: आपको उस स्कीमा को परिभाषित करने की आवश्यकता है जिसे बाहरी उपभोक्ताओं को उपलब्ध कराया जाएगा।
शुरुआत से एक डेटा प्रवाह आरेख बनाना 🛠️
एक विश्वसनीय DFD बनाने के लिए एक व्यवस्थित दृष्टिकोण की आवश्यकता होती है। यदि सटीकता लक्ष्य है, तो इस प्रक्रिया में कोई त्वरित रास्ता नहीं है। एक विश्वसनीय मॉडल बनाने के लिए इन चरणों का पालन करें।
चरण 1: सीमाओं की पहचान करें
सिस्टम सीमा को परिभाषित करके शुरुआत करें। क्या अंदर आता है? क्या बाहर है? सिस्टम के चारों ओर एक बॉक्स खींचें। सब कुछ अंदर सिस्टम का हिस्सा है; सब कुछ बाहर एक बाहरी एकाधिकार है।
चरण 2: बाहरी एकाधिकारों को मैप करें
अपने परियोजना के साथ बातचीत करने वाले सभी लोगों, विभागों या प्रणालियों की सूची बनाएं। उन्हें सीमा के बाहर खींचें। उन्हें स्पष्ट रूप से लेबल करें।
चरण 3: मुख्य प्रक्रियाओं को परिभाषित करें
सिस्टम के मुख्य कार्यों की पहचान करें। इन्हें आरेख में वृत्त बनाया जाता है। उदाहरण के लिए, यदि एक पुस्तकालय प्रणाली बना रहे हैं, तो प्रक्रियाओं में “पुस्तक जारी करना” और “पुस्तक वापस करना” शामिल हो सकते हैं।
चरण 4: डेटा प्रवाह के साथ जोड़ें
एकाधिकारों को प्रक्रियाओं और प्रक्रियाओं को डेटा भंडारों से जोड़ने वाली तीर खींचें। सुनिश्चित करें कि प्रत्येक तीर का लेबल हो। नाम रहित डेटा प्रवाह अर्थहीन है। सुनिश्चित करें कि डेटा किसी एकाधिकार से दूसरे एकाधिकार में सीधे नहीं बहता है, बल्कि प्रक्रिया से गुजरना चाहिए।
चरण 5: संरक्षण की जांच करें
डेटा संरक्षण की जाँच करें। यदि कोई प्रक्रिया डेटा आउटपुट करती है, तो उस डेटा का कहीं से आना आवश्यक है। यदि कोई प्रक्रिया इनपुट प्राप्त करती है, तो उसे कहीं जाना चाहिए। कोई भी डेटा न तो गायब होना चाहिए और न ही बिना किसी कारण उपस्थित होना चाहिए।
शुरुआत से एक एंटिटी रिलेशनशिप डायग्राम बनाना 🏗️
एक एरडी (ERD) संबंधों और कुंजियों के संबंध में सटीकता की आवश्यकता होती है। संरचना एप्लिकेशन के प्रदर्शन और विश्वसनीयता को निर्धारित करती है।
चरण 1: एंटिटीज की पहचान करें
आवश्यकताओं में संज्ञाओं की जांच करें। ये संभावित एंटिटीज हैं। अस्पष्ट संज्ञाओं को फ़िल्टर करें। केवल उन्हीं को रखें जो मूल्यवान विशिष्ट वस्तुओं का प्रतिनिधित्व करती हैं। उदाहरण के लिए, एक अस्पताल प्रणाली में, “रोगी” और “डॉक्टर” एंटिटीज हैं। “उपचार” एक एंटिटी या संबंध हो सकता है, जटिलता के आधार पर।
चरण 2: लक्षणों को परिभाषित करें
प्रत्येक एंटिटी के लिए विशिष्ट विवरणों की सूची बनाएं। निर्धारित करें कि कौन से लक्षण अद्वितीय पहचानकर्ता (प्राथमिक कुंजी) हैं। एक “रोगी” एंटिटी के लिए, “रोगी आईडी” कुंजी है। “नाम” एक लक्षण है। सुनिश्चित करें कि लक्षण परमाणु हों; यदि आप शहर के आधार पर प्रश्न पूछना चाहते हैं, तो “पता” को एकल फ़ील्ड के रूप में स्टोर न करें।
चरण 3: संबंधों को स्थापित करें
यह तय करें कि एंटिटीज कैसे जुड़ती हैं। एक रोगी का इलाज एक डॉक्टर द्वारा किया जाता है। यह एक संबंध है। कार्डिनैलिटी तय करें। क्या एक डॉक्टर बहुत सारे रोगियों का इलाज करता है? हाँ। क्या यह बहुत-से-से-बहुत-से है? हाँ। क्या एक रोगी के बहुत सारे डॉक्टर हैं? हाँ।
चरण 4: बहुत-से-से-बहुत-से को हल करें
डेटाबेस बहुत-से-से-बहुत-से संबंधों को मूल रूप से स्टोर नहीं कर सकते हैं। यदि एक छात्र बहुत सारे कोर्स ले सकता है और एक कोर्स में बहुत सारे छात्र हैं, तो आपको एक सह-संबंधित एंटिटी (आमतौर पर जंक्शन टेबल कहलाती है) बनाना होगा। इससे संबंध दो एक-से-बहुत के संबंधों में तोड़ दिया जाता है।
चरण 5: सामान्य रूपों की समीक्षा करें
नॉर्मलाइजेशन नियमों को लागू करें। सुनिश्चित करें कि गैर-कुंजी लक्षण केवल प्राथमिक कुंजी पर निर्भर हों। यदि कोई लक्षण कुंजी के हिस्से पर निर्भर है, तो उसे एक नई एंटिटी में स्थानांतरित करें। इस चरण से डेटा विचलनों को रोका जा सकता है।
बचने के लिए सामान्य गलतियाँ ⚠️
यहां तक कि अनुभवी वास्तुकार भी मॉडलिंग के दौरान गलतियां करते हैं। सामान्य त्रुटियों के बारे में जागरूक रहना डिज़ाइन की अखंडता को बनाए रखने में मदद करता है।
DFD की गलतियाँ
- एंटिटीज के बीच डेटा प्रवाह: डेटा को हमेशा किसी प्रक्रिया से गुजरना चाहिए। बाहरी एंटिटीज के बीच सीधी रेखाएं प्रणाली नियंत्रण की कमी को दर्शाती हैं।
- काले छेद: एक प्रक्रिया जिसमें इनपुट है लेकिन आउटपुट नहीं है। यह एक कार्यरत प्रणाली में तार्किक रूप से असंभव है।
- ग्रे होल्स: एक प्रक्रिया जिसमें इनपुट है लेकिन कोई आउटपुट ही नहीं है, या आउटपुट जो इनपुट की आवश्यकताओं के अनुरूप नहीं है।
- अनलेबल्ड प्रवाह: एक नाम रहित तीर संचारित सामग्री के बारे में कोई जानकारी प्रदान नहीं करता है।
एरडी की गलतियाँ
- कार्डिनैलिटी का अभाव: संबंध एक-से-एक या एक-से-बहुत है या नहीं, इसकी परिभाषा न करने से कोड के कार्यान्वयन में अस्पष्टता आती है।
- आवश्यकता से अधिक एंटिटीज: ऐसी एंटिटीज बनाना जो दूसरों की वास्तविक दोहराव हैं, जिससे डेटा असंगति उत्पन्न होती है।
- नल को नजरअंदाज करना: एक विशेषता खाली हो सकती है या नहीं, इसका निर्णय लेने में विफलता। इसका डेटाबेस की सीमाओं और एप्लिकेशन लॉजिक पर प्रभाव पड़ता है।
- अत्यधिक सामान्यीकरण: डेटा को बहुत अधिक तालिकाओं में बांटने से क्वेरी स्लो और जटिल हो सकती है। संतुलन महत्वपूर्ण है।
सिस्टम आर्किटेक्चर में दोनों का एकीकरण 🏗️
जबकि DFDs और ERDs अलग-अलग हैं, वे एक-दूसरे के विपरीत नहीं हैं। एक परिपक्व सिस्टम डिजाइन दोनों का समान रूप से उपयोग करता है। DFD डेटा के यात्रा का वर्णन करता है, जबकि ERD डेटा के गंतव्य और भंडारण का वर्णन करता है।
एकीकरण प्रक्रिया
आवश्यकता चरण के दौरान, एक संदर्भ आरेख से शुरुआत करें। यह दृश्य को तैयार करता है। जैसे-जैसे आप सिस्टम को विभाजित करते हैं, आप डेटा स्टोर की पहचान करेंगे। इन डेटा स्टोर को अंततः आपके ERD में एंटिटीज बन जाते हैं। DFD में प्रवाह ERD में विदेशी कुंजियों और संबंधों में बदल जाते हैं।
उदाहरण के लिए, यदि एक DFD एक “प्रोफाइल अपडेट” प्रक्रिया को दिखाता है जो डेटा को “उपयोगकर्ता जानकारी” स्टोर में ले जाता है, तो ERD में उस स्टोर के साथ मेल खाने वाले विशेषताओं वाले एक “उपयोगकर्ता” एंटिटी को परिभाषित करना होगा। DFD में प्रक्रिया और स्टोर के बीच संबंध ERD में पढ़ने/लिखने के अनुमति और लेनदेन लॉजिक को प्रभावित करता है।
दस्तावेज़ीकरण सुसंगतता
दोनों आरेखों के बीच सुसंगतता बनाए रखना महत्वपूर्ण है। यदि DFD में एक नए डेटा स्रोत को जोड़ने के लिए बदलाव किया जाता है, तो ERD को नए टेबल या कॉलम को दर्शाने के लिए अपडेट किया जाना चाहिए। यदि ERD में एक टेबल की संरचना बदली जाती है, तो DFD में नए डेटा प्रवाह के नाम या गंतव्य को दिखाना चाहिए। यहां अंतर एकीकरण बग और डेटा हानि का कारण बन सकते हैं।
आधुनिक सिस्टम के लिए उन्नत विचार 🚀
जबकि इन आरेखों की उत्पत्ति मेनफ्रेम के युग में हुई थी, उनके सिद्धांत आधुनिक माइक्रोसर्विसेज और क्लाउड आर्किटेक्चर में भी संबंधित रहते हैं।
क्लाउड और DFDs
क्लाउड पर्यावरण में, डेटा प्रवाह अक्सर अलग-अलग क्षेत्रों या सेवाओं के माध्यम से जाता है। DFD को इन सीमाओं को स्पष्ट रूप से दिखाना चाहिए। यह लेटेंसी और डेटा स्वायत्तता की आवश्यकताओं को समझने में मदद करता है। उदाहरण के लिए, यदि यूरोप में एक उपयोगकर्ता से डेटा यूएस में सर्वर तक बहता है, तो संपादन नियम लागू हो सकते हैं।
NoSQL और ERDs
पारंपरिक ERDs एक संबंधात्मक संरचना के बारे में मानते हैं। NoSQL डेटाबेस अक्सर दस्तावेज़ या ग्राफ मॉडल का उपयोग करते हैं। जबकि एंटिटीज और संबंधों की मूल अवधारणा बनी रहती है, कार्यान्वयन अलग होता है। एक दस्तावेज़ स्टोर में, “एंटिटी” दस्तावेज़ ही होता है। संबंध आईडी के माध्यम से एम्बेडेड या लिंक किए जा सकते हैं, सख्त विदेशी कुंजियों के बजाय। ERD अभी भी ब्लूप्रिंट के रूप में कार्य करता है, लेकिन नोटेशन तकनीक की स्कीमा-रहित प्रकृति के अनुसार अनुकूलित हो सकता है।
अंतरों का सारांश
इन दोनों आरेखों के बीच अंतर उनके उद्देश्य में है। DFD गति का नक्शा है। यह प्रश्न का उत्तर देता है: “डेटा पर क्या होता है?” ERD संरचना का नक्शा है। यह प्रश्न का उत्तर देता है: “डेटा क्या है?” एक सॉफ्टवेयर सिस्टम की पूरी छवि के लिए दोनों की आवश्यकता होती है। एक के बिना दूसरे पर भरोसा करने से समझ में खामी आती है जो प्रोजेक्ट को कमजोर कर सकती है।
दोनों मॉडलों के निर्माण और अनुप्रयोग को समझने से आप सुनिश्चित करते हैं कि सिस्टम केवल अपने संचालन में कार्यक्षम ही नहीं, बल्कि डेटा प्रबंधन में भी मजबूत है। इस द्वैत दृष्टिकोण से सूचना आर्किटेक्चर के गतिशील और स्थैतिक पहलुओं को कवर किया जाता है, जो विकास और विश्लेषण के लिए एक व्यापक आधार प्रदान करता है।
अक्सर पूछे जाने वाले प्रश्न
क्या मैं एक आरेख का दोनों उद्देश्यों के लिए उपयोग कर सकता हूँ?
नहीं। DFD टेबल कुंजियों या सामान्यीकरण नियमों को प्रभावी ढंग से दिखा नहीं सकता है। ERD प्रक्रिया तर्क या डेटा रूपांतरण चरणों को प्रभावी ढंग से नहीं दिखा सकता है। वे अलग-अलग स्टेकहोल्डर्स और चरणों के लिए कार्य करते हैं।
मैं सबसे पहले कौन सा बनाऊं?
आमतौर पर, DFD से शुरुआत करें। आपको यह समझने की आवश्यकता है कि प्रक्रियाएं क्या हैं, जब तक आप नहीं जानते कि कौन सा डेटा भंडारित करने की आवश्यकता है। जब DFD में डेटा स्टोर की पहचान कर ली जाती है, तो आप उन्हें पूर्ण ERD में विस्तारित कर सकते हैं।
क्या इन आरेखों का उपयोग एजाइल पद्धतियों के साथ किया जा सकता है?
हाँ। एजाइल में, इन आरेखों को आमतौर पर विशिष्ट उपयोगकर्ता कहानियों के लिए तुरंत बनाया जाता है, बजाय बड़े आगे के दस्तावेजों के। वे उत्पाद के साथ विकसित होने वाले जीवंत दस्तावेज़ के रूप में कार्य करते हैं।