




सिस्टम विश्लेषण और डिज़ाइन जटिल जानकारी को संचारित करने के लिए दृश्य प्रतिनिधित्व पर भारी निर्भरता रखता है। उपलब्ध मॉडलिंग तकनीकों में से, डेटा फ्लो डायग्राम (DFD) एक मूल उपकरण के रूप में उभरता है जो जानकारी के एक सिस्टम में गति को समझने में मदद करता है। यह मार्गदर्शिका DFD के सैद्धांतिक आधार और व्यावहारिक अनुप्रयोगों का अध्ययन करती है, जिसमें किसी विशिष्ट सॉफ्टवेयर उपकरण पर निर्भरता नहीं है। मूल सिद्धांतों पर ध्यान केंद्रित करके, व्यावसायिक व्यक्ति ऐसे ठोस सिस्टम का डिज़ाइन कर सकते हैं जो डेटा की आवश्यकताओं और प्रसंस्करण तर्क को सटीक रूप से प्रतिबिंबित करते हैं।
डेटा फ्लो डायग्राम को समझना 🧐
एक डेटा फ्लो डायग्राम एक सूचना प्रणाली के माध्यम से डेटा के प्रवाह का आलेखीय प्रतिनिधित्व है। एक फ्लोचार्ट के विपरीत जो नियंत्रण तर्क और संचालन के क्रम पर ध्यान केंद्रित करता है, एक DFD प्रक्रियाओं, डेटा स्टोर और बाहरी एकाधिकारों के बीच डेटा के गति पर जोर देता है। यह सिस्टम वास्तुकारों और विश्लेषकों के लिए इनपुट, आउटपुट और रूपांतरण को दृश्य रूप से देखने के लिए एक नक्शा के रूप में कार्य करता है।
DFD का मुख्य उद्देश्य वर्णन करना है क्या सिस्टम करता है, बल्कि कैसे यह करता है। यह अंतर आवश्यकता संग्रह चरण के दौरान निर्णायक है। यह स्टेकहोल्डर्स को कोड लिखे जाने से पहले सिस्टम के तर्क की पुष्टि करने की अनुमति देता है। यह विधि 1970 के दशक में विकसित संरचित विश्लेषण तकनीकों से उत्पन्न हुई, विशेष रूप से एडवर्ड यूरडॉन और लैरी कॉन्स्टेंटाइन द्वारा, और आधुनिक सॉफ्टवेयर इंजीनियरिंग में अब भी प्रासंगिक बनी हुई है।
DFD के मूल घटक 🧱
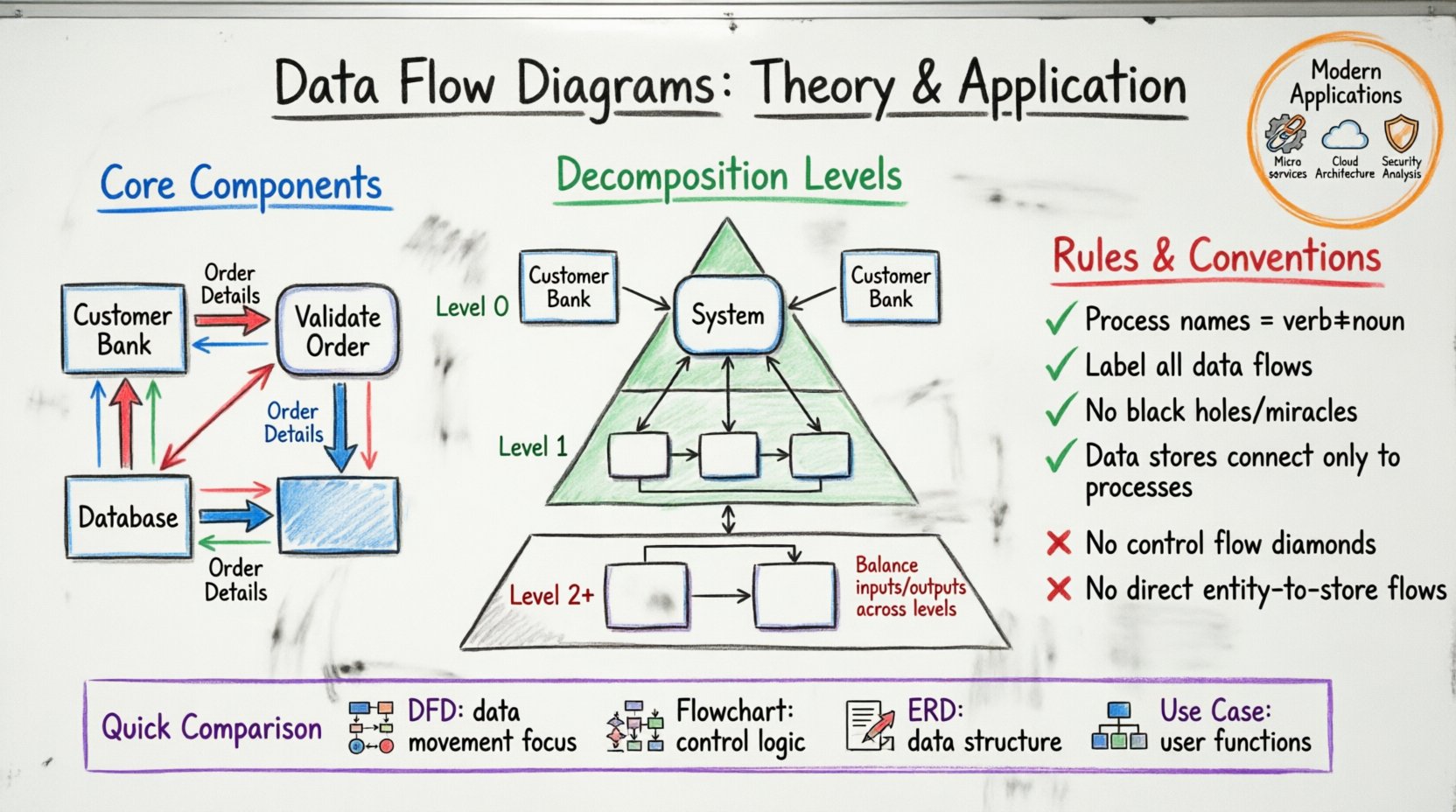
एक वैध आरेख बनाने के लिए, एक को सिस्टम तत्वों का प्रतिनिधित्व करने के लिए उपयोग किए जाने वाले चार मूल संकेतों को समझना आवश्यक है। प्रत्येक संकेत का आरेखीय संरचना में एक विशिष्ट अर्थ और कार्य होता है।
- बाहरी एकाधिकार: इन्हें अंतिम बिंदु, स्रोत या निकास के रूप में भी जाना जाता है, ये लोगों, संगठनों या अन्य प्रणालियों का प्रतिनिधित्व करते हैं जो मॉडल की जा रही प्रणाली से बातचीत करते हैं। ये इनपुट डेटा का स्रोत या आउटपुट डेटा का गंतव्य होते हैं। इन्हें आमतौर पर आयताकार आकृति में बनाया जाता है।
- प्रक्रियाएँ: ये डेटा पर किए जाने वाले क्रियाओं या रूपांतरणों का प्रतिनिधित्व करते हैं। एक प्रक्रिया इनपुट डेटा प्रवाह लेती है, उन्हें संशोधित करती है और आउटपुट डेटा प्रवाह उत्पन्न करती है। DFD नोटेशन में, प्रक्रियाओं को अक्सर गोल आयताकार या वृत्ताकार आकृति में दर्शाया जाता है।
- डेटा स्टोर: ये वे स्थान हैं जहाँ डेटा भविष्य के उपयोग के लिए संग्रहीत किया जाता है। इन्हें भौतिक डेटाबेस, फाइलें या यहां तक कि हाथ से फाइल करने वाली प्रणाली भी हो सकती है। डेटा स्टोर को आमतौर पर खुले छोर वाले आयताकार या समानांतर रेखाओं के रूप में बनाया जाता है।
- डेटा प्रवाह: ये घटकों को जोड़ने वाली तीर हैं। ये डेटा के गति की दिशा को दर्शाते हैं और स्थानांतरित हो रही विशिष्ट जानकारी को लेबल करते हैं। डेटा प्रवाह को अर्थपूर्ण नाम होना चाहिए जो सामग्री का वर्णन करे।
इन घटकों के बीच बातचीत को समझना एक सुसंगत मॉडल बनाने का पहला चरण है। डेटा सिर्फ उपस्थित हो या गायब नहीं हो सकता; यह किसी एकाधिकार से शुरू होना चाहिए, एक प्रक्रिया के माध्यम से गुजरना चाहिए और संभवतः एक स्टोर में या दूसरे एकाधिकार को बाहर जाना चाहिए।
विघटन के स्तर 📉
जटिल प्रणालियों को एक ही दृश्य में पर्याप्त रूप से प्रतिनिधित्व नहीं किया जा सकता है। DFDs जटिल प्रक्रियाओं को छोटे, प्रबंधनीय भागों में तोड़ने के लिए एक तकनीक जिसे विघटन कहा जाता है, का उपयोग करते हैं। इससे आरेखों का एक पदानुक्रम बनता है, जिसे आमतौर पर स्तर कहा जाता है।
संदर्भ आरेख (स्तर 0)
संदर्भ आरेख सबसे ऊँचे स्तर के सारांश को दर्शाता है। यह पूरी प्रणाली को एकल प्रक्रिया के रूप में दिखाता है और इसके बाहरी एकाधिकारों के साथ बातचीत को दर्शाता है। यह आरेख एक उच्च स्तर का अवलोकन प्रदान करता है, जिससे सुनिश्चित होता है कि सभी मुख्य इनपुट और आउटपुट को ध्यान में रखा गया है। यह प्रणाली और इसके वातावरण के बीच की सीमा को परिभाषित करता है।
स्तर 1 DFD
जब संदर्भ स्थापित हो जाता है, तो मुख्य प्रक्रिया अपने प्रमुख उप-प्रक्रियाओं में विस्फोटित हो जाती है। एक स्तर 1 DFD प्रणाली के प्रमुख कार्यात्मक क्षेत्रों को दिखाता है। यह इन उप-प्रक्रियाओं और बाहरी एकाधिकारों के बीच मुख्य डेटा प्रवाहों को विस्तार से दर्शाता है। इस स्तर का उपयोग अक्सर व्यावसायिक स्टेकहोल्डर्स के साथ संचार के लिए किया जाता है जो प्रमुख कार्यों को समझना चाहते हैं।
स्तर 2 और उससे आगे
अधिक विस्तृत विश्लेषण के लिए, स्तर 1 प्रक्रियाओं को और अधिक स्तर 2 DFD में विघटित किया जा सकता है। यह तब तक जारी रहता है जब तक प्रक्रियाएँ इंप्लीमेंट करने के लिए पर्याप्त सरल नहीं हो जाती हैं। प्रत्येक स्तर को बनाए रखना चाहिए संतुलनका अर्थ है कि एक मातृ प्रक्रिया के इनपुट और आउटपुट को उसकी बच्ची प्रक्रियाओं के इनपुट और आउटपुट के योग के बराबर होना चाहिए।
DFD स्तरों की तुलना
| स्तर | फोकस | प्राथमिक दर्शक | विवरण की तुलना |
|---|---|---|---|
| संदर्भ (स्तर 0) | प्रणाली सीमा | हितधारक, प्रबंधन | बहुत उच्च (एकल प्रक्रिया) |
| स्तर 1 | मुख्य कार्य | प्रोजेक्ट प्रबंधक, विश्लेषक | उच्च (उप-प्रक्रियाएँ) |
| स्तर 2 | विशिष्ट तर्क | विकासकर्ता, तकनीकी नेता | मध्यम (विस्तृत चरण) |
| स्तर 3+ | एल्गोरिदमिक तर्क | प्रोग्रामर | निम्न (परमाणु संचालन) |
नियम और व्यवहार ✅
कठोर नियमों का पालन करने से यह सुनिश्चित होता है कि आरेख पठनीय और सटीक हों। इन नियमों के उल्लंघन से प्रणाली डिजाइन में अस्पष्टता और त्रुटियाँ हो सकती हैं।
- डेटा स्टोर इंटरैक्शन: एक प्रक्रिया और डेटा स्टोर के बीच डेटा का प्रवाह होना चाहिए। प्रक्रियाएँ बिना डेटा के प्रवाह के दूसरी प्रक्रियाओं से सीधे बातचीत नहीं कर सकती हैं, और डेटा को किसी एकांत के बिना प्रसंस्करण के बिना स्टोर में सीधे प्रवाहित नहीं किया जा सकता है।
- प्रक्रिया नामकरण: प्रत्येक प्रक्रिया का एक क्रिया-संज्ञा नाम होना चाहिए (उदाहरण के लिए, “कर की गणना करें”, “कर” नहीं)। इससे लिया जा रहा क्रिया स्पष्ट हो जाता है।
- डेटा प्रवाह नामकरण: तीरों को चल रहे विशिष्ट डेटा के साथ लेबल किया जाना चाहिए। “सूचना” या “डेटा” जैसे सामान्य लेबल से बचें।
- कोई काले छेद नहीं: एक प्रक्रिया में केवल इनपुट और कोई आउटपुट नहीं होना चाहिए। प्रत्येक प्रक्रिया को डेटा को किसी अन्य चीज में बदलना चाहिए।
- कोई चमत्कारी प्रक्रियाएँ नहीं: एक प्रक्रिया में केवल आउटपुट और कोई इनपुट नहीं होना चाहिए। प्रत्येक आउटपुट किसी इनपुट से उत्पन्न होना चाहिए।
- सांस्कृतिकता: डेटा प्रवाह लेबल को आरेख के सभी स्तरों पर संगत रहना चाहिए।
DFD बनाना: चरण-दर-चरण मार्गदर्शिका 🛠️
डेटा प्रवाह आरेख विकसित करना एक तार्किक प्रगति का अनुसरण करता है। यह व्यापार संदर्भ को समझने के साथ शुरू होता है और एक विस्तृत तकनीकी विवरण के साथ समाप्त होता है।
चरण 1: बाहरी एंटिटी की पहचान करें
सभी डेटा स्रोतों और गंतव्यों की सूची बनाने से शुरुआत करें। लेनदेन कौन शुरू करता है? रिपोर्ट कौन प्राप्त करता है? इन्हें सिस्टम सीमा के चारों ओर आयताकार आकृतियों के रूप में बनाएं।
चरण 2: केंद्रीय प्रक्रिया को परिभाषित करें
संदर्भ आरेख के लिए, केंद्र में एक एकल वृत्त या गोल आयत बनाएं। इसे सिस्टम के नाम से लेबल करें।
चरण 3: प्रमुख डेटा प्रवाहों को नक्शा बनाएं
बाहरी एंटिटी को केंद्रीय प्रक्रिया से तीरों के उपयोग से जोड़ें। प्रत्येक तीर को आदान-प्रदान किए जा रहे डेटा के साथ लेबल करें। सुनिश्चित करें कि प्रत्येक एंटिटी को कम से कम एक कनेक्शन हो।
चरण 4: प्रक्रिया को विभाजित करें
केंद्रीय प्रक्रिया को उप-प्रक्रियाओं में विस्तारित करें। सिस्टम लक्ष्य प्राप्त करने के लिए आवश्यक प्रमुख कार्यों की पहचान करें। इन्हें सीमा के भीतर नए वृत्तों के रूप में बनाएं।
चरण 5: डेटा स्टोर जोड़ें
डेटा कहाँ स्थायी रूप से रखा जाता है? डेटाबेस या फाइलों का प्रतिनिधित्व करने के लिए आयताकार आकृतियाँ जोड़ें। प्रक्रियाओं को इन स्टोर्स से जोड़कर दिखाएं कि डेटा कहाँ पढ़ा या लिखा जाता है।
चरण 6: समीक्षा और संतुलन
सुनिश्चित करें कि मुख्य और बच्चे के आरेखों के बीच सभी इनपुट और आउटपुट मेल खाते हैं। सत्यापित करें कि कोई भी डेटा प्रवाह अंतरक्रिया के नियमों का उल्लंघन नहीं करता है।
DFD बनाम अन्य आरेखण तकनीकें 🔄
जबकि DFDs शक्तिशाली हैं, उन्हें अक्सर अन्य मॉडलिंग उपकरणों के साथ भ्रमित किया जाता है। अंतरों को समझने से यह सुनिश्चित होता है कि सही उपकरण सही कार्य के लिए उपयोग किया जाता है।
- फ्लोचार्ट्स:फ्लोचार्ट्स नियंत्रण प्रवाह, निर्णय बिंदुओं और लूप्स पर ध्यान केंद्रित करते हैं। वे किसी प्रोग्राम की तर्क प्रणाली का वर्णन करते हैं। DFDs डेटा के आंदोलन और परिवर्तन पर ध्यान केंद्रित करते हैं, नियंत्रण तर्क को नजरअंदाज करते हैं।
- एंटिटी-संबंध आरेख (ERD):ERDs डेटा की संरचना का मॉडल बनाते हैं, विशेष रूप से एंटिटी और गुणों के बीच संबंधों का। DFDs उस डेटा के प्रक्रियाओं के माध्यम से गति का मॉडल बनाते हैं।
- उपयोग केस आरेख:उपयोग केस आरेख उपयोगकर्ता के दृष्टिकोण से कार्यात्मक आवश्यकताओं का वर्णन करते हैं। DFDs उन कार्यों के प्रक्रमण के आंतरिक तंत्र का वर्णन करते हैं।
बचने के लिए सामान्य गलतियाँ ❌
यहां तक कि अनुभवी विश्लेषक भी डेटा प्रवाह के मॉडलिंग में गलतियां करते हैं। सामान्य जाल में जागरूकता आरेख की अखंडता बनाए रखने में मदद करती है।
- डेटा प्रवाह में नियंत्रण प्रवाह: एक मानक DFD में निर्णय हीरे या लूप शामिल न करें। इनका स्थान प्रवाह चार्ट या काल्पनिक कोड में होता है।
- गायब डेटा स्टोर्स: कभी-कभी विश्लेषक अस्थायी डेटा या लॉग के लिए स्टोर को शामिल करना भूल जाते हैं। सुनिश्चित करें कि सभी स्थायी डेटा का ध्यान रखा गया है।
- असंगत नामकरण: यदि एक आरेख में डेटा प्रवाह को “ऑर्डर जानकारी” कहा जाता है, तो दूसरे में इसे “ऑर्डर डेटा” नहीं कहा जाना चाहिए। रखरखाव के लिए संगतता महत्वपूर्ण है।
- अत्यधिक जटिलता: एक ही आरेख पर पूरे एंटरप्राइज सिस्टम को फिट करने की कोशिश न करें। जटिलता को प्रबंधित करने के लिए विघटन का उपयोग करें।
- डेटा सत्यापन को नजरअंदाज करना: जबकि DFDs में सत्यापन तर्क नहीं दिखाए जाते हैं, सुनिश्चित करें कि प्रक्रिया में प्रवेश करने वाले डेटा की पर्याप्त मात्रा है ताकि वह प्रक्रिया सही तरीके से काम कर सके।
आधुनिक सिस्टम डिजाइन में उपयोग 📝
डेटा प्रवाह आरेखों का उपयोग लेगेसी सिस्टम से आगे तक जाता है। वे क्लाउड आर्किटेक्चर, माइक्रोसर्विस डिजाइन और व्यवसाय प्रक्रिया पुनर्डिजाइन में अनिवार्य हैं।
माइक्रोसर्विस आर्किटेक्चर
वितरित प्रणालियों में, डेटा सीमाओं को समझना महत्वपूर्ण है। DFDs सहायता करते हैं कि कौन सी सेवाएं संचार करने की आवश्यकता है और क्या पेलोड वे आदान-प्रदान करती हैं। वे API अनुबंधों और संदेश भंडार को परिभाषित करने में सहायता करते हैं।
व्यवसाय प्रक्रिया पुनर्डिजाइन
संगठन DFDs का उपयोग वर्तमान प्रवाह (अब तक) को मानचित्रित करने और भविष्य के प्रवाह (आगे जाने वाला) को डिजाइन करने के लिए करते हैं। इससे बफलेट, आवश्यक चरणों और स्वचालन के क्षेत्रों की पहचान में मदद मिलती है।
सुरक्षा विश्लेषण
सुरक्षा पेशेवर DFDs का उपयोग डेटा संवेदनशीलता की पहचान करने के लिए करते हैं। डेटा के प्रवाह के मार्ग का पता लगाकर वे यह निर्धारित कर सकते हैं कि एन्क्रिप्शन या पहुंच नियंत्रण की आवश्यकता कहां है। उदाहरण के लिए, यदि व्यक्तिगत डेटा एक सार्वजनिक प्रक्रिया के माध्यम से बहता है, तो एक सुरक्षा जोखिम की पहचान की जाती है।
दस्तावेजीकरण के लिए सर्वोत्तम प्रथाएं 📋
दस्तावेजीकरण आरेख के साथ आता है। यह संदर्भ प्रदान करता है जो दृश्य प्रतीक नहीं बता सकते।
- शब्दकोश: आरेख में उपयोग किए गए सभी शब्दों, अक्षराक्षरों और डेटा तत्वों के नाम को परिभाषित करें।
- डेटा शब्दकोश: प्रत्येक डेटा स्टोर और डेटा प्रवाह (फील्ड नाम, प्रकार, आकार) की संरचना का वर्णन करने वाला एक अलग दस्तावेज बनाए रखें।
- प्रक्रिया विशिष्टताएं: जटिल प्रक्रियाओं के लिए, संरचित अंग्रेजी या काल्पनिक कोड में विस्तृत तर्क प्रदान करें।
- संस्करण नियंत्रण: आरेखों में परिवर्तनों का अनुसरण करें। प्रणालियां विकसित होती हैं, और आरेखों में इन परिवर्तनों को दर्शाना चाहिए।
प्रतीक संदर्भ सारणी 🎨
संरचित विश्लेषण में उपयोग किए जाने वाले मानक प्रतीक प्रतिनिधित्व के लिए इस सारणी को देखें।
| तत्व | आकृति | कार्य | उदाहरण |
|---|---|---|---|
| बाहरी एकाधिकार | आयत | डेटा का स्रोत या स्तंभ | ग्राहक, बैंक प्रणाली |
| प्रक्रिया | गोलाकार आयत / वृत्त | डेटा का परिवर्तन | लॉगिन की पुष्टि करें, कुल गणना करें |
| डेटा भंडार | खुला आयत / समानांतर रेखाएँ | सक्रिय भंडारण | ग्राहक तालिका, लॉग फ़ाइल |
| डेटा प्रवाह | तीर | गति की दिशा | आदेश विवरण, भुगतान पुष्टि |
उन्नत विचार 🚀
जैसे-जैसे प्रणालियाँ अधिक जटिल होती हैं, DFD को अनुकूलित करना होगा। रियल-टाइम प्रणालियाँ, इवेंट-आधारित आर्किटेक्चर और असिंक्रोनस प्रोसेसिंग ऐसे बातें लाती हैं जिन्हें मानक DFD पूरी तरह से नहीं दर्शा सकते।
- घटना ट्रिगर्स: इवेंट-आधारित प्रणालियों में, एक प्रक्रिया किसी विशिष्ट संकेत का इंतजार कर सकती है। जबकि DFD समय को स्पष्ट रूप से नहीं दिखाते, एक विशिष्ट इनपुट की उपस्थिति एक ट्रिगर को संकेत कर सकती है।
- समानांतर प्रसंस्करण: जब एक साथ कई प्रक्रियाएँ होती हैं, तो सुनिश्चित करें कि आरेख में स्वतंत्र डेटा पथ दिखाए जाएँ जो एक दूसरे के साथ बाधा न डालें।
- सुरक्षा क्षेत्र: नेटवर्क आरेखों में, सुरक्षा सीमाओं को पार करने वाले डेटा प्रवाहों को स्पष्ट रूप से चिह्नित किया जाना चाहिए ताकि एन्क्रिप्शन या प्रमाणीकरण की आवश्यकता का संकेत मिल सके।
मुख्य बातों का सारांश 🏁
डेटा प्रवाह आरेख प्रणाली तर्क को दृश्यमान बनाने का एक संरचित तरीका प्रदान करते हैं। वे डेटा गति को नियंत्रण तर्क से अलग करते हैं, जिससे वे आवश्यकता विश्लेषण के लिए आदर्श होते हैं। विघटन, संतुलन और नोटेशन के नियमों का पालन करके विश्लेषक स्पष्ट, रखरखाव योग्य मॉडल बना सकते हैं।
इन आरेखों के निर्माण के दौरान सटीकता और स्पष्टता पर ध्यान केंद्रित करें। अनावश्यक जटिलता से बचें। सुनिश्चित करें कि प्रत्येक डेटा प्रवाह का एक उद्देश्य है और प्रत्येक प्रक्रिया में स्पष्ट परिवर्तन है। नियमित रूप से स्टेकहोल्डर्स के साथ आरेखों की समीक्षा करें ताकि समझ की पुष्टि हो सके। इस सहयोगात्मक दृष्टिकोण से यह सुनिश्चित होता है कि अंतिम प्रणाली इच्छित व्यापार लक्ष्यों को पूरा करती है।
डेटा फ्लो के मॉडलिंग की अनुशासन विकास चरण में लाभ देता है। यह अस्पष्टता को कम करता है, स्कोप क्रीप को रोकता है और टीम सदस्यों के बीच बेहतर संचार को सुविधा प्रदान करता है। एक सरल डेटाबेस एप्लिकेशन या एक जटिल एंटरप्राइज प्लेटफॉर्म के डिज़ाइन करते समय भी, डेटा फ्लो डायग्राम के सिद्धांत प्रभावी सिस्टम डिज़ाइन की एक मूल बात बने रहते हैं।