











Designing a robust data architecture requires balancing conflicting priorities. Integrity, performance, and maintainability often pull in different directions. When the system shifts focus toward read-heavy operations, the traditional rules of schema design face significant stress. The Entity Relationship Diagram (ERD) becomes more than a static blueprint; it acts as the contract between the application logic and the storage engine. This guide explores the strategic divergence between normalized and denormalized approaches specifically within the context of high-volume read workloads.
The decision to normalize or denormalize is not binary. It involves understanding the cost of data duplication against the cost of data retrieval. In environments where read operations dominate transaction logs, minimizing join complexity often becomes the primary optimization target. However, introducing redundancy creates new challenges for data consistency and write operations. We must analyze the trade-offs to select the appropriate structural strategy.
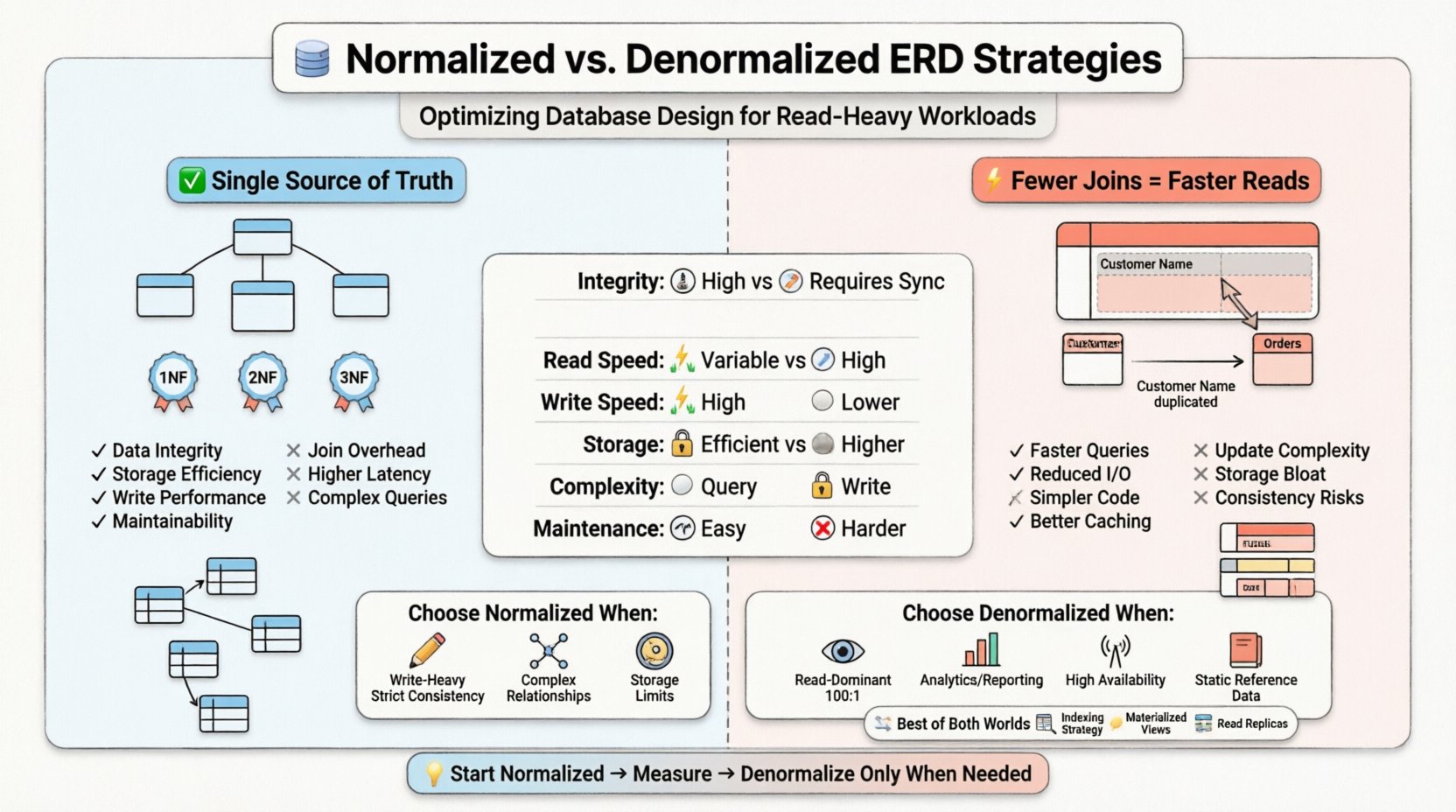
🏗️ Understanding Normalization in ERD Design
Normalization is a systematic process used to reduce data redundancy and improve data integrity. It organizes attributes and tables in a relational database to minimize anomalies during insert, update, and delete operations. The goal is to ensure that each piece of data is stored in exactly one place.
Core Principles of Normalization
When constructing an Entity Relationship Diagram, architects typically adhere to a hierarchy of rules known as Normal Forms. Each form addresses specific types of redundancy.
- First Normal Form (1NF): Ensures that each column contains atomic values and that there are no repeating groups. This establishes a flat structure for rows.
- Second Normal Form (2NF): Builds upon 1NF by removing partial dependencies. Attributes must depend on the entire primary key, not just a portion of it.
- Third Normal Form (3NF): Eliminates transitive dependencies. Non-key attributes must depend only on the primary key, not on other non-key attributes.
In a highly normalized ERD, tables are granular. A customer table might exist separately from their address table, which is linked via a foreign key. An order table references the customer, and an order item table references the order. This structure ensures that if a customer moves, the update happens in one location and propagates automatically.
Advantages of a Normalized Schema
- Data Integrity: Single sources of truth reduce the risk of conflicting information.
- Storage Efficiency: Less redundant data means the database footprint is smaller.
- Write Performance: Insert, update, and delete operations are generally faster because fewer rows need to be touched across multiple tables.
- Maintainability: Changes to data structures are localized. Adding a new attribute to a specific entity does not require cascading changes to unrelated tables.
Disadvantages for Read-Heavy Systems
While normalization excels in write-heavy or mixed environments, it introduces friction for read operations. Every join required to assemble a complete record represents a physical operation on the disk or memory cache. In a read-heavy workload, the system may need to fetch data from five or six different tables to render a single dashboard view.
- Join Overhead: The query processor must match keys across tables. This consumes CPU cycles and memory bandwidth.
- I/O Operations: If tables are large, the storage engine must perform multiple seeks to retrieve related data.
- Latency: The cumulative time of multiple lookups increases the response time for the end-user.
🔗 The Denormalization Approach
Denormalization is the deliberate introduction of redundancy into a database design. The objective is to optimize the system for read performance by reducing the number of joins required. In the Entity Relationship Diagram, this manifests as columns that duplicate data from other tables or wider tables that consolidate related information.
How Denormalization Works
Instead of storing a foreign key to look up a customer name, a denormalized order table might store the customer name directly. If the customer changes their name, the order record must be updated or flagged, or the system accepts that the order reflects the name at the time of purchase.
This strategy shifts the complexity from the read path to the write path. The system must now handle the logic of updating redundant copies of data.
Benefits for Read-Heavy Workloads
- Faster Query Execution: Fewer joins mean less computational overhead.
- Reduced I/O: More data is retrieved in a single table scan rather than multiple lookups.
- Simplified Queries: Application code requires less logic to assemble results.
- Caching Efficiency: Flatter structures are often easier to cache effectively in memory.
Risks and Drawbacks
The primary cost of denormalization is data consistency. If the source data changes, all redundant copies must be updated simultaneously. Failure to do so results in stale data.
- Update Anomalies: Updating a customer name requires finding and changing every order record that references that customer.
- Storage Bloat: Replicating data increases the total size of the database.
- Complexity in Writes: Write transactions become more complex, often requiring more locks or longer transaction times.
- Schema Rigidity: Adding a new field may require updating multiple tables, not just one.
📈 Analyzing Read-Heavy Workload Characteristics
To choose the correct strategy, one must understand the specific nature of the workload. Read-heavy systems differ significantly from transactional systems where writes are frequent and critical.
Query Patterns
Does the application perform complex analytical queries or simple lookups? Complex queries involving aggregations across many tables benefit from denormalization. Simple lookups by ID might perform adequately with normalization if indexes are well-tuned.
- Point Queries: Retrieving a single record by ID.
- Range Queries: Retrieving a set of records within a date range.
- Aggregations: Calculating totals, averages, or counts across large datasets.
Latency Requirements
High-frequency trading platforms or real-time dashboards cannot afford the latency introduced by complex joins. In these scenarios, denormalization is often a requirement rather than a choice. Conversely, if the application can tolerate a few hundred milliseconds of delay, normalization might suffice with proper indexing.
Data Consistency Tolerance
Is immediate consistency required? If the system can tolerate eventual consistency, denormalization becomes much safer. Read replicas or asynchronous update mechanisms can handle the synchronization of redundant data without blocking write operations.
📋 Strategic Comparison Table
The following table summarizes the key differences between the two approaches in the context of database design.
| Feature | Normalized Schema | Denormalized Schema |
|---|---|---|
| Data Integrity | High (Single source of truth) | Lower (Requires sync logic) |
| Read Performance | Variable (Depends on joins) | High (Fewer joins) |
| Write Performance | High (Minimal redundancy) | Lower (Update multiple rows) |
| Storage Usage | Efficient | Higher (Redundant data) |
| Complexity | High Query Complexity | High Write Complexity |
| Maintainability | Easy for Schema Changes | Harder for Schema Changes |
🧭 Decision Framework for Architects
Selecting the right path requires evaluating the business requirements against technical constraints. The following framework helps guide the decision-making process.
When to Choose Normalization
- Write Intensity: If write operations occur frequently relative to reads, normalization prevents update anomalies.
- Strict Consistency: Financial systems or medical records often require strict ACID compliance where redundancy is unacceptable.
- Complex Relationships: When entities have many-to-many relationships that change frequently, normalization handles the mapping cleanly.
- Storage Constraints: If disk space is a premium, minimizing redundancy is beneficial.
When to Choose Denormalization
- Read Dominance: If reads outnumber writes by a significant margin (e.g., 100:1), performance gains from fewer joins outweigh write costs.
- Reporting & Analytics: Data warehouses and reporting engines often denormalize to speed up aggregation queries.
- High Availability: Distributed systems may denormalize data to allow reads on local nodes without network hops to other partitions.
- Static Reference Data: Data that rarely changes (e.g., country codes, currency rates) is a prime candidate for duplication.
🛠️ Hybrid Approaches and Optimization
It is rarely necessary to choose one extreme over the other. Modern systems often employ hybrid strategies to balance the benefits of both models.
Indexing Strategies
Before denormalizing, ensure that the normalized schema is fully indexed. Covering indexes can allow the storage engine to retrieve all necessary data from the index itself, avoiding table lookups. This can sometimes achieve near-denormalized read speeds without the data redundancy.
- Composite Indexes: Order columns by the most selective fields to speed up range scans.
- Partial Indexes: Index only specific subsets of data to reduce index size and maintenance cost.
Materialized Views
A materialized view is a database object that stores the result of a query physically. It allows the system to maintain a denormalized view of the data without altering the base tables. When the underlying data changes, the materialized view can be refreshed.
- Pre-computation: Complex aggregations are calculated in advance.
- Refresh Cycles: Can be set to run on a schedule or trigger on data change.
- Read Separation: Queries hit the materialized view, while writes go to the base tables.
Read Replicas
In distributed architectures, read replicas can be configured to host denormalized copies of data. The primary node handles writes and maintains the normalized schema. The replica receives updates asynchronously and serves read traffic with the optimized schema.
- Scale Reads: Distributes the load across multiple nodes.
- Geographic Proximity: Places data closer to the user.
- Eventual Consistency: Accepts a slight delay in data propagation.
⚠️ Common Pitfalls in Schema Design
Even with a clear strategy, implementation errors can undermine performance. Architects must remain vigilant against common mistakes.
Over-Normalization
Creating too many tables for a single concept can lead to excessive joins. While 3NF is a standard, adhering to it blindly in read-heavy systems can degrade performance. Sometimes, a controlled violation of 3NF is necessary.
Inconsistent Denormalization
Denormalizing only some parts of the application while leaving others normalized creates a fragmented system. The inconsistency makes it difficult for developers to predict performance characteristics.
Ignoring Data Volume
A schema that works for a small dataset may fail when the volume scales. Denormalization increases storage requirements linearly with the number of records. If data grows exponentially, the storage cost and maintenance overhead of redundancy can become unmanageable.
Update Logic Complexity
Implementing the logic to keep redundant data in sync is non-trivial. It often requires triggers, application-level transactions, or message queues. If this logic fails, data corruption occurs silently.
🔍 Implementation Considerations
When moving from design to implementation, specific technical details must be addressed to ensure success.
Transaction Management
Denormalized updates often span multiple rows. These must be wrapped in a single transaction to ensure atomicity. If the system crashes halfway through, the data must roll back to avoid inconsistency.
Caching Layers
Even with denormalization, caching frequently accessed data in memory can reduce database load further. The cache should invalidate or update when the underlying data changes.
Monitoring and Metrics
Continuous monitoring is essential. Track query execution times, lock contention, and storage growth. If write latency spikes, it may indicate that the denormalization update logic is too heavy.
📝 Final Considerations for Architects
The choice between normalized and denormalized ERD strategies is a fundamental architectural decision. It dictates how data flows through the system and how the storage engine interacts with the application. There is no single correct answer that applies to every scenario.
- Measure First: Do not optimize based on assumptions. Profile the current workload to identify bottlenecks.
- Start Simple: Begin with a normalized design. Denormalize only when performance metrics indicate a need.
- Document Decisions: Clearly record why redundancy was introduced. Future maintainers need to understand the trade-offs.
- Plan for Evolution: Schema designs must evolve. A strategy that works today may need adjustment as data patterns change.
By understanding the mechanics of joins, the cost of redundancy, and the specific demands of read-heavy workloads, architects can design systems that are both robust and performant. The goal is not to follow a rigid rule, but to apply the most appropriate tool for the specific data environment.