











W nowoczesnej inżynierii oprogramowania systemy rzadko istnieją jako jednolite jednostki. Składają się z wielu usług, procesów i jednostek przechowywania danych, które wzajemnie oddziałują przez granice sieci. Zrozumienie, jak informacje przemieszczają się między tymi różnymi jednostkami, jest kluczowe do utrzymania integralności systemu, diagnozowania awarii oraz planowania skalowalności. Niniejszy przewodnik omawia proces mapowania i wizualizacji przepływu danych w architekturach rozproszonych, używając konkretnie modelu C4 jako strukturalnego ramowienia.
Bez jasnej dokumentacji systemy rozproszone szybko stają się czarnymi skrzynkami. Inżynierowie mają trudności z śledzeniem żądań, identyfikacją węzłów zatrzasku lub zrozumieniem skutków zmian. Wizualizacja ruchu danych zapewnia przejrzystość. Przekształca abstrakcyjną logikę w konkretne schematy, które mogą zrozumieć wszyscy zaangażowani. Niniejszy dokument przedstawia metodyki definiowania granic, mapowania połączeń oraz utrzymywania tych schematów w czasie.
1. Krajobraz architektury 🌍
Systemy rozproszone wprowadzają złożoność, której nie muszą znosić aplikacje jednolite. Gdy pojedynczy proces obsługuje całą logikę, przepływ danych jest wewnętrzny i liniowy. Gdy zaangażowane są wiele kontenerów lub usług, dane przemieszczają się przez sieci, przechodzą przez zapory ogniowe i przekraczają granice zaufania. Każdy skok wprowadza opóźnienia oraz potencjalne punkty awarii.
Wizualizacja tego krajobrazu wymaga znormalizowanego podejścia. Schematy stworzone na chwilę często prowadzą do niezgodności. Jeden inżynier może narysować bazę danych jako walec, a inny — jako prostokąt. Standardyzacja zapewnia, że gdy schemat jest oglądany, jego znaczenie jest od razu zrozumiałe. Model C4 zapewnia tę standardyzację poprzez definiowanie określonych poziomów abstrakcji.
Główne wyzwania w wizualizacji rozproszonej obejmują:
- Opóźnienia sieciowe: Wizualizacja miejsc, gdzie dane czekają w kolejkach lub sieciach.
- Spójność danych: Pokazywanie, jak stan jest zsynchronizowany między węzłami.
- Strefy awarii: Identyfikacja tego, co dzieje się, gdy jeden kontener przestaje odpowiadać.
- Granice bezpieczeństwa: Oznaczanie miejsc, gdzie wymagana jest szyfrowanie danych lub uwierzytelnianie.
2. Wyjaśnienie modelu C4 📐
Model C4 to hierarchia schematów używanych do opisywania architektury oprogramowania. Składa się z czterech poziomów, każdy z nich służy innej grupie odbiorców i celom. W kontekście wizualizacji przepływu danych między kontenerami najbardziej istotne są poziomy Kontenera i Komponentu.
Poziom 1: Kontekst systemu
To widok najwyższego poziomu pokazuje system jako pojedynczy blok oraz jego interakcje z zewnętrznymi użytkownikami i systemami. Odpowiada na pytanie: „Co robi ten system i kto go używa?” Choć przydatny w kontekście, nie pokazuje wewnętrznego przepływu danych między kontenerami.
Poziom 2: Kontenery
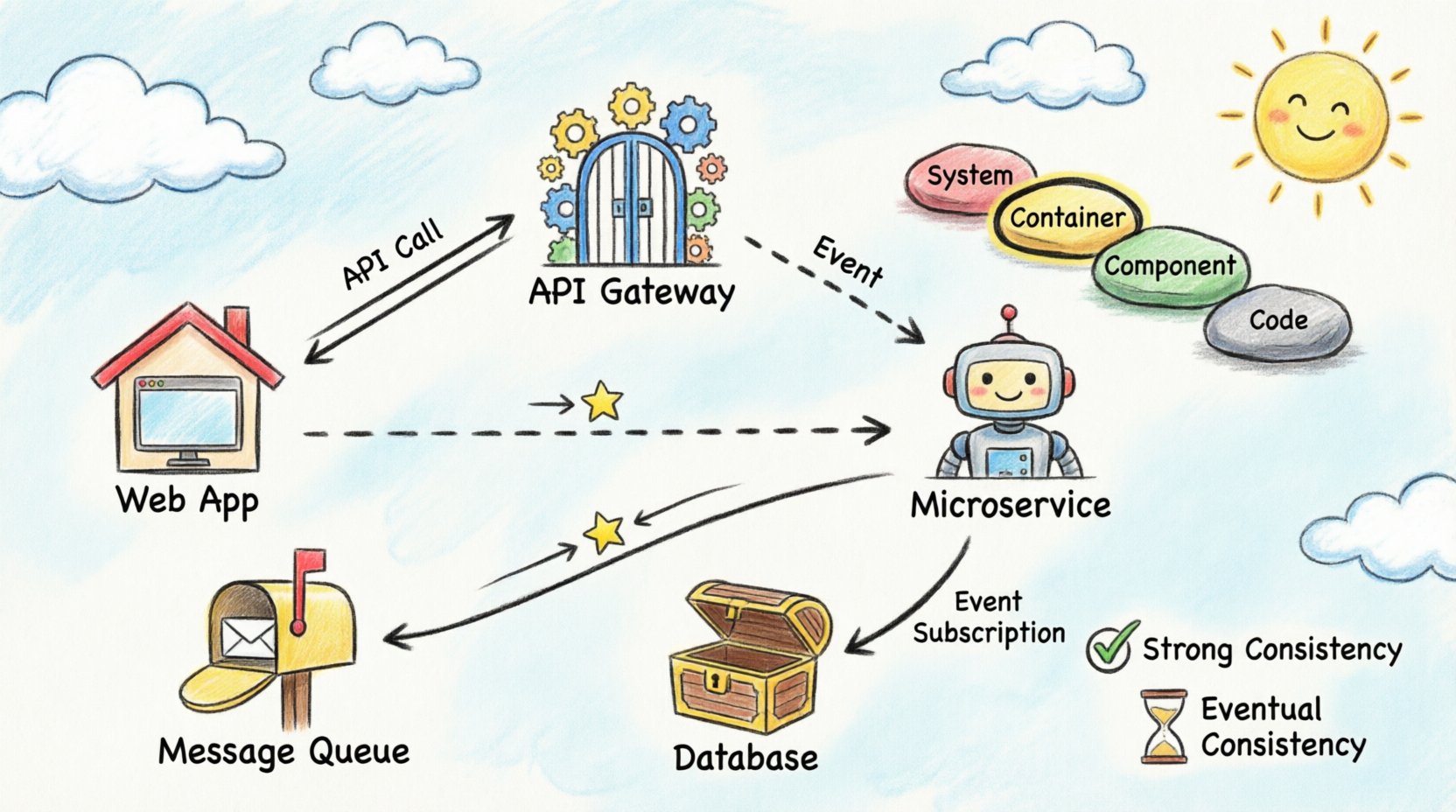
To jądro wizualizacji rozproszonej. Kontener reprezentuje odrębną jednostkę wdrażania. Przykłady to aplikacje internetowe, aplikacje mobilne, mikroserwisy i magazyny danych. Ten poziom ilustruje sposób przepływu danych między tymi jednostkami. To idealne miejsce do mapowania wywołań interfejsów API, kolejek komunikatów oraz bezpośrednich połączeń z bazami danych.
Poziom 3: Komponenty
W ramach kontenera komponenty reprezentują odrębne części oprogramowania. Ten poziom głębiej bada logikę, pokazując wewnętrzne interakcje klas lub zależności modułów. Choć ważny, często jest zbyt szczegółowy do analizy przepływu danych na najwyższym poziomie.
Poziom 4: Kod
Ten poziom odnosi się do konkretnych klas i metod. Zazwyczaj nie jest potrzebny do dokumentacji przepływu architektonicznego i jest lepiej dopasowany do materiałów referencyjnych przeznaczonych dla programistów.
3. Identyfikacja granic kontenerów 🚧
Zanim narysujesz linie przepływu danych, musisz określić, co stanowi kontener. Kontener to jednostka wdrażalna. Ma niezależny cykl życia w stosunku do innych kontenerów. Może działać na tym samym serwerze fizycznym lub być rozproszony na różnych regionach.
Typowe typy kontenerów to:
- Aplikacje internetowe:Interfejsy frontendowe dostępne przez przeglądarki.
- Usługi mikroserwisowe:Usługi zaplecza obsługujące określone logiki biznesowe.
- Bramy interfejsów API:Punkty wejściowe, które kierują ruch do usług wewnętrznych.
- Magazyny danych:Bazy danych, pamięci podręczne lub systemy plików.
- Procesy partii:Zaplanowane zadania przetwarzające dane asynchronicznie.
Podczas definiowania granic należy wziąć pod uwagę strategię wdrażania. Jeśli dwie usługi są zawsze wdrażane razem i współdzielą pamięć, mogą należeć do jednego kontenera. Jeśli mogą być skalowane niezależnie, powinny być osobnymi kontenerami. Ta decyzja ma wpływ na sposób wizualizacji przepływu danych.
4. Mapowanie wzorców przepływu danych 📡
Przepływ danych to nie tylko linia łącząca dwa pola. Reprezentuje określony wzorzec interakcji. Zrozumienie tego wzorca jest kluczowe dla poprawnej wizualizacji. Poniższa tabela przedstawia najczęściej występujące wzorce oraz sposób ich przedstawienia.
| Wzorzec | Kierunek | Widoczność | Przypadek użycia |
|---|---|---|---|
| Synchroniczne żądanie/odpowiedź | Dwukierunkowy (Klient → Serwer → Klient) | Natychmiastowa | Wywołania interfejsów API, przesyłanie formularzy |
| Asynchroniczne wysyłanie i zapominanie | Jednokierunkowy (Klient → Serwer) | Odłożona | Rejestrowanie, zdarzenia analizy |
| Przetwarzanie oparte na pobieraniu | Jednokierunkowy (Pracownik ← Kolejka) | Na żądanie | Zadania w tle, inżynieria danych |
| Subskrypcja zdarzeń | Jednokierunkowy (Nadawca → Odbiorca) | Wyzwolone przez zdarzenie | Powiadomienia, zmiany stanu |
Komunikacja synchroniczna
W przepływach synchronicznych nadawca oczekuje odpowiedzi. Jest to powszechne w interakcjach API. Podczas wizualizacji używaj linii ciągłych z strzałkami wskazującymi żądanie i odpowiedź. Oznacz używany protokół, np. HTTP lub gRPC. Pomaga to inżynierom zrozumieć blokujący charakter interakcji.
Komunikacja asynchroniczna
Przepływy asynchroniczne rozłączają nadawcę od odbiorcy. Nadawca umieszcza wiadomość w kolejce i kontynuuje. Odbiorca przetwarza wiadomość później. Wizualizuj to za pomocą linii przerywanych lub odrębnych ikon reprezentujących broker wiadomości. Kluczowe jest wskazanie nazwy kolejki, aby odróżnić różne strumienie danych.
5. Obsługa synchronizacji i spójności ⚖️
Jednym z najtrudniejszych aspektów przepływu danych rozproszonych jest zarządzanie stanem. Gdy dane są zapisywane w jednym kontenerze, czy natychmiast odzwierciedlają się w innym? Wizualizacja musi odzwierciedlać te wymagania spójności.
Silna spójność
Niektóre systemy wymagają, aby wszystkie węzły widziały te same dane w tym samym czasie. Oznacza to często jednoznaczny źródło prawdy lub replikację synchroniczną. W diagramach oznacz te połączenia etykietami wskazującymi „Silna spójność” lub „ACID”. Informuje to stakeholderów, że awaria w jednej części systemu może wpłynąć na inne.
Końcowa spójność
Wiele systemów rozproszonych priorytetowo ustawia dostępność przed natychmiastową spójnością. Dane mogą potrzebować sekund lub minut na rozpropagowanie. Wizualizuj to dodając wskaźnik czasu lub etykietę „Sync” z oznaczeniem opóźnienia. Pomaga to zarządzać oczekiwaniami dotyczącymi momentu, w którym użytkownicy zobaczą zaktualizowane informacje.
Kontenery bezstanowe vs. zstanowe
Kontenery bezstanowe nie przechowują danych lokalnie. Opierają się na zewnętrznych bazach danych lub pamięciach podręcznych. Kontenery zstanowe przechowują dane w własnym magazynie. Podczas mapowania przepływu upewnij się, że zewnętrzny magazyn jest wyraźnie oddzielony od kontenera. Jeśli kontener przechowuje dane, linia przepływu powinna wskazywać na ikonę magazynu wewnątrz lub przypiętą do tego kontenera.
6. Konserwacja dokumentacji 📝
Diagram jest użyteczny tylko wtedy, gdy jest dokładny. Z czasem zmienia się kod, dodawane są nowe usługi, a przestarzałe usługi usuwane są. Diagramy statyczne szybko stają się przestarzałe. Wymagana jest strategia konserwacji.
Najlepsze praktyki utrzymywania dokumentacji aktualnej obejmują:
- Generowanie automatyczne:Tam, gdzie to możliwe, generuj diagramy z adnotacji kodu lub plików konfiguracyjnych. Zmniejsza to wysiłek ręczny i zapobiega rozbieżnościom między kodem a dokumentacją.
- Cykle przeglądu:Zawieraj aktualizacje diagramów w definicji gotowości dla żądań zmian. Jeśli zmienia się interfejs usługi, diagram również musi się zmienić.
- Wersjonowanie:Traktuj diagramy architektury jak kod. Przechowuj je w systemach kontroli wersji, aby śledzić historię i umożliwić cofnięcie zmiany, jeśli jest niepoprawna.
- Standardy narzędzi:Używaj spójnego zestawu narzędzi. Unikaj zmiany platform do tworzenia diagramów między różnymi zespołami.
7. Powszechne pułapki do uniknięcia 🛑
Nawet przy strukturalnym podejściu mogą pojawić się błędy podczas procesu wizualizacji. Znajomość powszechnych błędów pomaga utrzymać wysoką jakość dokumentacji.
Zbyt duża abstrakcja
Czytelnik ma skłonność do zbyt dużego uproszczenia diagramów. Jeśli połączysz dziesięć usług w jednym pudełku oznaczonym „Backend”, tracisz możliwość śledzenia konkretnych ścieżek danych. Zachowaj poziom szczegółowości na poziomie kontenera. Nie łącz jednostek wdrożeniowych, chyba że mają dokładnie taki sam cykl życia.
Ignorowanie ścieżek awarii
Większość diagramów pokazuje drogę sukcesu, gdzie wszystko działa. Solidna wizualizacja również wskazuje tryby awarii. Dokąd idzie przepływ, jeśli usługa przekroczy limit czasu? Czy istnieje usługa rezerwowa? Czy istnieje kolejka wiadomości nieprzetworzonych? Dodanie tych ścieżek czyni diagram narzędziem do planowania odporności.
Niezgodne nazewnictwo
Używaj tej samej terminologii dla usług na diagramie, jak w kodzie źródłowym. Jeśli usługa nazywa się „Order-Service” w kodzie, nie oznaczaj jej jako „Orders API” na diagramie. Powoduje to zamieszanie podczas sesji debugowania.
Brakujące typy danych
Linia między dwoma kontenerami informuje Cię o *tym*, że dane się przemieszczają, ale nie o *tym*, jakie dane się przemieszczają. Warto oznaczać linie typem danych przesyłanych. Na przykład: „Dane w formacie JSON”, „Obraz binarny” lub „Pakiet CSV”. Pozwala to inżynierom ocenić złożoność przetwarzania wymaganego po stronie odbiorczej.
8. Najlepsze praktyki utrzymania i rozwoju 📈
Wraz z rozwojem systemu diagram może stać się zatłoczony. Zarządzanie złożonością to ciągła praca. Oto strategie utrzymania wizualizacji czystej i użytecznej.
- Warstwowanie: Używaj różnych warstw dla różnych zagadnień. Jedna warstwa dla bezpieczeństwa, druga dla przepływu danych, trzecia dla topologii wdrażania. Unikaj rysowania wszystkich tych elementów na jednej stronie.
- Linki do szczegółów: Jeśli kontener jest skomplikowany, stwórz osobny poddiagram dla niego. Połącz główny diagram z widokiem szczegółowym, zamiast rysować każdy komponent na stronie przeglądowej.
- Kodowanie kolorami: Używaj kolorów do oznaczania statusu lub krytyczności. Czerwony dla kluczowych ścieżek, niebieski dla standardowych przepływów, szary dla przestarzałych połączeń. Pozwala to szybko ocenić stan systemu.
- Metadane: Dołącz wersję diagramu oraz datę ostatniej przeglądu w stopce dokumentu. To zapewnia kontekst dotyczący aktualności informacji.
9. Integracja z obserwacją 🔍
Diagramy statyczne są statyczne. Systemy rzeczywiste są dynamiczne. Nowoczesne architektury integrują diagramy z platformami obserwacji. Oznacza to, że diagram nie jest tylko obrazem, ale interfejsem działającym w czasie rzeczywistym.
Podczas wizualizacji przepływu danych rozważ, jak diagram jest powiązany z danymi monitoringu. Jeśli w narzędziu monitoringu widzisz wysoką opóźnienie na konkretnym połączeniu, diagram powinien jasno pokazywać to połączenie. To połączenie pomaga w analizie przyczyn. Inżynierowie mogą kliknąć linię na diagramie i zobaczyć aktualne metryki dla tego połączenia.
Ta integracja wymaga, aby format diagramu wspierał osadzanie lub łączenie z zewnętrznymi źródłami danych. Upewnij się, że wybrana metoda tworzenia diagramów pozwala na tę elastyczność bez konieczności ręcznej aktualizacji przy każdym zmianie metryki.
10. Podsumowanie kluczowych wniosków ✅
Wizualizacja przepływu danych w systemach rozproszonych to dziedzina, która balansuje dokładnością techniczną z czytelnością. Przestrzeganie modelu C4 pozwala zespołom tworzyć spójny język architektury. Poziom kontenerów zapewnia niezbędną szczegółowość do zrozumienia interakcji między usługami bez nadmiernego skomplikowania.
Kluczowe punkty do zapamiętania:
- Jasno zdefiniuj granice: Upewnij się, że kontenery są zgodne z jednostkami wdrażania.
- Jasno zaznacz wzorce: Rozróżnij przepływy synchroniczne i asynchroniczne.
- Dokumentuj modele spójności: Wskaż, jak zarządzane jest stan między granicami.
- Utrzymuj z należytą starannością: Traktuj diagramy jako żywe dokumenty, które ewoluują razem z kodem.
- Unikaj nadużyć: Skup się na przejrzystości i dokładności, a nie na promowaniu architektury.
Przestrzegając tych zasad, zespoły inżynieryjne mogą zmniejszyć obciążenie poznawcze, przyspieszyć wdrażanie nowych członków zespołu oraz poprawić ogólną niezawodność ich rozproszonej infrastruktury. Celem nie jest jedynie rysowanie linii, ale budowanie wspólnej rozumienia, jak działa system.