











Projektowanie solidnej struktury danych to fundament każdego niezawodnego systemu informacyjnego. W centrum tego projektowania znajduje się diagram relacji encji (ERD), wizualny szkic określający sposób wzajemnego działania encji danych. Jednak sam diagram nie gwarantuje efektywności. Prawdziwa siła ERD pojawia się wtedy, gdy łączy się ją z rygorystycznymi strategiami normalizacji. Cel jest jasny: osiągnąć przechowywanie bez nadmiarowości. Oznacza to eliminację danych powtarzających się, aby zapewnić integralność, zmniejszyć koszty przechowywania i uprościć utrzymanie.
Nadmiarowość to nie tylko problem przechowywania; to błąd logiczny gotowy spowodować niezgodności. Gdy dane powtarzają się w wielu wierszach lub tabelach bez ściśle określonej relacji, anomalie aktualizacji stają się nieuniknione. Zmiana jednego atrybutu może wymagać aktualizacji dziesiątek miejsc. Jeśli jedno zostanie pominięte, baza danych staje się uszkodzona. Niniejszy przewodnik bada mechanizmy normalizacji w kontekście projektowania ERD, skupiając się na zastosowaniu praktycznym i czystości strukturalnej.
🧱 Zrozumienie podstaw modelowania danych
Zanim zastosuje się zasady normalizacji, należy zrozumieć składniki diagramu relacji encji. ERD składa się z encji, atrybutów i relacji. Encje reprezentują obiekty lub pojęcia, takie jak Klient lub Produkt. Atrybuty to właściwości opisujące te encje, np. Imię lub Cena. Relacje określają sposób połączenia encji, często za pomocą kluczy obcych.
Normalizacja to proces organizowania tych atrybutów w celu minimalizacji nadmiarowości i zależności. Polega na dzieleniu dużych tabel na mniejsze, logicznie powiązane oraz definiowaniu relacji między nimi. Celem jest izolacja danych, aby każda informacja była przechowywana tylko w jednym miejscu.
Zastanów się nad różnicą między podejściem nienormalizowanym a normalizowanym. W podejściu nienormalizowanym jedna tabela może zawierać wszystkie informacje o zamówieniu, w tym adres i numer telefonu klienta przy każdym nowym zamówieniu. Jeśli klient zmieni adres, musisz zaktualizować każdy rekord zamówienia. W podejściu normalizowanym adres klienta znajduje się w osobnej tabeli Klient. Tabela Zamówienie zawiera tylko odniesienie do ID Klienta. Ta separacja to esencja braku nadmiarowości.
📉 Ryzyko danych nienormalizowanych
Dlaczego brak nadmiarowości jest tak krytyczny? Odpowiedź tkwi w rodzajach anomalii, które pojawiają się, gdy ignoruje się normalizację. Te anomalie zagrożone niezawodności całego systemu.
- Anomalie wstawiania:Nie możesz dodać danych dla jednej encji bez dodania danych dla innej. Na przykład, jeśli nowy pracownik jeszcze nie został przypisany do projektu, możesz nie być w stanie zarejestrować jego istnienia, jeśli tabela wymaga ID projektu.
- Anomalie usuwania:Usunięcie danych dla jednej encji może niechcący usunąć dane dla innej. Jeśli usuniesz ostatnie zamówienie klienta, możesz całkowicie stracić informacje kontaktowe tego klienta.
- Anomalie aktualizacji:To najpowszechniejszy problem. Jeśli adres klienta jest przechowywany w wielu rekordach zamówień, aktualizacja adresu wymaga znalezienia i zmiany każdego rekordu. Niepowodzenie w tym zadaniu prowadzi do sprzecznych danych.
Osiągnięcie braku nadmiarowości bezpośrednio zmniejsza te ryzyka. Zapewniając, że każda informacja ma jedno miejsce przechowywania, system staje się samokorygujący. Aktualizacje odbywają się raz, a zmiana rozprzestrzenia się logicznie poprzez relacje.
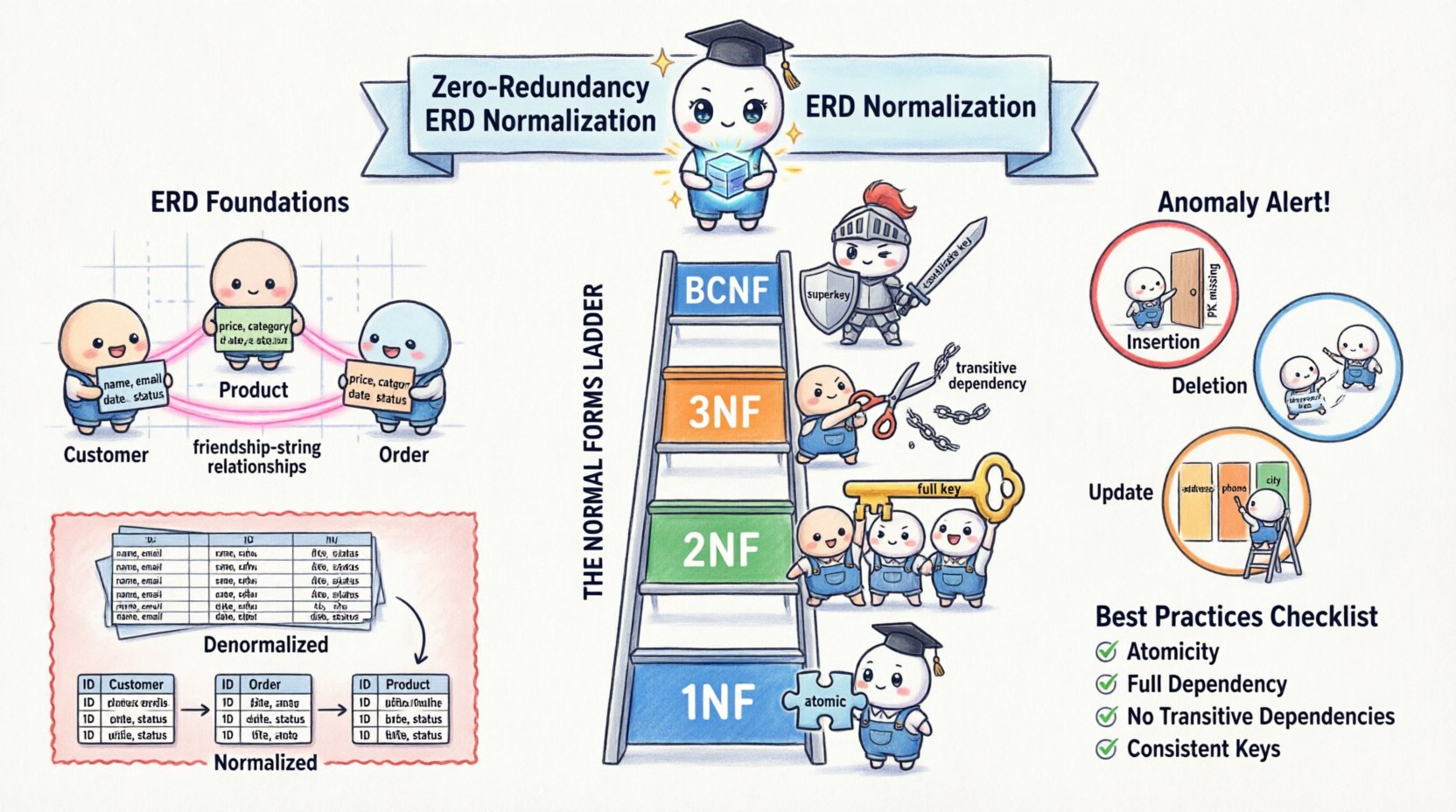
🪜 Droga do form normalnych
Normalizacja to nie pojedynczy krok, ale postęp przez różne etapy nazywane Formami Normalnymi. Każda forma rozwiązuje konkretne typy nadmiarowości. Choć modele teoretyczne sięgają piątej formy normalnej (5NF), praktyczny projekt bazy danych zwykle skupia się na pierwszych trzech formach oraz Formie Normalnej Boyce’a-Codda (BCNF).
1️⃣ Pierwsza Forma Normalna (1NF)
Pierwsza zasada normalizacji to zapewnienie atomowości. Tabela znajduje się w 1NF, jeśli nie zawiera powtarzających się grup ani tablic. Każda kolumna musi zawierać jedną wartość, a każdy wiersz musi być unikalny.
- Wartości atomowe:Pole nie może zawierać listy wartości. Zamiast kolumny o nazwie „Umiejętności” zawierającej „Java, SQL, Python”, powinieneś utworzyć osobne wiersze dla każdej umiejętności lub osobną tabelę dla umiejętności.
- Unikalne wiersze:Każdy wiersz musi być odróżnialny od każdego innego wiersza. Zazwyczaj wymaga to klucza podstawowego.
W kontekście ERD oznacza to sprawdzenie każdego atrybutu. Jeśli atrybut opisuje własność wielowartościową, musi zostać wyodrębniony. To podstawowy krok. Bez 1NF wyższe formy nie mogą być skutecznie zastosowane.
2️⃣ Druga Forma Normalna (2NF)
Gdy tabela znajduje się w 1NF, musi spełniać kryteria 2NF. Tabela znajduje się w 2NF, jeśli jest w 1NF i wszystkie atrybuty niekluczowe są całkowicie zależne od całego klucza podstawowego.
Ta zasada głównie dotyczy tabel z kluczami złożonymi (kluczami złożonymi z wielu kolumn). Jeśli tabela ma klucz złożony, każdy atrybut musi zależeć od całego klucza, a nie tylko od jego części.
- Pełna zależność:Jeśli kolumna zależy tylko od jednej części klucza złożonego, powinna znajdować się w osobnej tabeli.
- Zależność częściowa:To jest określona nadmiarowość, którą eliminuje 2NF. Na przykład w tabeli łączącej Studentów z Przedmiotami, jeśli przechowywane jest „Imię Studenta”, zależy ono wyłącznie od ID Studenta, a nie od ID Przedmiotu. Powoduje to nadmiarowość.
Rozwiązanie polega na podzieleniu tabeli. Tworzysz tabelę Student i tabelę Przedmiot, połączoną tabelą pośrednią. Zapewnia to, że dane studenta nie są powtarzane dla każdego kursu, który odbywa.
3️⃣ Trzecia postać normalna (3PN)
Trzecia postać normalna dotyczy zależności przechodnich. Tabela znajduje się w 3PN, jeśli jest w 2PN i żaden atrybut niekluczowy nie zależy od innego atrybutu niekluczowego.
W uproszczeniu: atrybuty nie powinny zależeć od innych atrybutów, które nie są częścią klucza podstawowego. Zdarza się to często, gdy kolumna opisuje inną kolumnę, a nie sam wiersz.
- Zależność przechodnia: Jeśli A decyduje o B, a B decyduje o C, to A decyduje o C. Jeśli B nie jest kluczem, to C jest przechowywane nadmiarowo.
- Przykład:W tabeli Pracownika, jeśli przechowujesz „Nazwę Departamentu” i „Kierownika Departamentu”, kierownik zależy od nazwy departamentu. Jeśli nazwa departamentu się zmieni, kolumna Kierownik może stać się niezgodna, jeśli nie zostanie odpowiednio zarządzana.
Aby to naprawić, przenieś informacje o departamencie do osobnej tabeli Departament. Tabela Pracownika zawiera wtedy tylko ID Departamentu. Pozwala to izolować dane departamentu, zapewniając, że jeśli departament zostanie zmieniony, zmianę dokonasz w jednym miejscu.
4️⃣ Postać normalna Boyce’a-Codd’a (PNBC)
PNBC to bardziej rygorystyczna wersja 3PN. Stosuje się ją, gdy istnieje wiele kluczy kandydujących lub gdy atrybut niekluczowy decyduje o innym atrybucie niekluczowym w określony sposób. Tabela znajduje się w PNBC, jeśli dla każdej zależności funkcyjnej X → Y, X jest nadkluczem.
Ta postać obsługuje złożone sytuacje, w których 3PN może nadal dopuszczać anomalie. Gwarantuje, że każdy determinant jest kluczem kandydującym. Choć nie zawsze konieczna dla każdej schematu, dążenie do PNBC zapewnia najwyższy poziom integralności strukturalnej przy zerowej nadmiarowości.
🛠️ Obsługa anomalii: widok porównawczy
Zrozumienie wpływu normalizacji wymaga jasnego obrazu, jak manifestują się anomalie. Poniższa tabela przedstawia różnice między stanem znormalizowanym a nieznormalizowanym pod kątem typowych problemów danych.
| Typ anomalii | Stan nieznormalizowany | Stan znormalizowany (bez nadmiarowości) |
|---|---|---|
| Aktualizacja | Wymaga zmiany danych w wielu wierszach. Wysokie ryzyko niezgodności. | Wymaga zmiany danych w jednym wierszu. Zgodność jest automatyczna. |
| Wstawienie | Może wymagać danych fałszywych, aby spełnić ograniczenia klucza obcego. | Nowe encje mogą być dodawane niezależnie bez niepowiązanych danych. |
| Usunięcie | Usunięcie rekordu może usunąć istotne dane dotyczące innej encji. | Usunięcie rekordu wpływa tylko na określoną encję, zachowując pozostałe. |
| Przechowywanie | Wysokie zużycie pamięci z powodu powtarzających się ciągów i wartości. | Minimalne zużycie pamięci; wartości są odwoływane za pomocą identyfikatorów. |
Jak pokazano, podejście znormalizowane znacznie zmniejsza obciążenie operacyjne zarządzania danymi. Koszt to nieco bardziej złożone zapytania, ponieważ do pobrania pełnych informacji wymagane są połączenia. Jednak kompromis sprzyja integralności i długoterminowej utrzymywalności.
🛠️ Strategie wdrożenia
Wdrożenie tych strategii w fazie projektowania ERD jest kluczowe. Znacznie łatwiej zapobiegać nadmiarowości niż naprawiać ją po wypełnieniu danych. Oto działające kroki dla projektantów.
1. Wczesne identyfikowanie zależności funkcyjnych
Zanim narysujesz linie między encjami, wymień atrybuty i określ, co decyduje o czym. Jeśli wiesz, że atrybut A decyduje o atrybucie B, wiesz, że powinny one prawdopodobnie znajdować się w tej samej encji, chyba że A nie jest kluczem.
- Zaprojektuj wszystkie relacje.
- Zapytaj: „Czy ten atrybut zależy od całego klucza?”
- Zapytaj: „Czy ten atrybut zależy od innego atrybutu niekluczowego?”
2. Oddzielanie encji na podstawie cyklu życia
Encje o różnych częstotliwościach aktualizacji powinny często być rozdzielone. Jeśli tabela referencyjna statyczna (np. lista krajów) jest mieszana z tabelą transakcyjną (np. zamówienia), dane statyczne powodują niepotrzebną nadmiarowość w tabeli transakcyjnej.
3. Używanie kluczy zastępczych
Zamiast używać danych naturalnych jako klucza głównego, rozważ użycie klucza zastępczego (unikalnego identyfikatora generowanego przez system). Zapobiega to problemom, gdy klucz sam zmienia się z czasem, co spowodowałoby zerwanie relacji w znormalizowanym systemie.
4. Weryfikacja za pomocą danych testowych
Zanim zakończysz projekt ERD, spróbuj wypełnić go danymi testowymi. Spróbuj stworzyć anomalie opisane wcześniej. Jeśli możesz pomyślnie dodać klienta bez zamówienia i usunąć zamówienie bez utraty klienta, projekt prawdopodobnie jest poprawny.
⚖️ Zrównoważenie wydajności i czystości
Osiągnięcie zerowej nadmiarowości nie oznacza maksymalizacji liczby tabel. Nadmierna normalizacja może prowadzić do pogorszenia wydajności. Gdy zapytanie wymaga danych z dziesięciu różnych tabel, system musi wykonać dziesięć połączeń. Może to znacznie spowolnić operacje odczytu.
Kiedy dokonywać denormalizacji
Istnieją uzasadnione powody, aby celowo ponownie wprowadzić nadmiarowość. Nazywa się to często denormalizacją.
- Systemy z dużym obciążeniem odczytu: W magazynach danych lub narzędziach raportujących priorytetem jest szybkość odczytu, a nie spójność zapisu. Kolumny obliczane z góry mogą zmniejszyć złożoność połączeń.
- Zrzuty historyczne: Jeśli chcesz wiedzieć, jaki był adres klienta w momencie zamówienia, nie możesz polegać na aktualnym adresie w tabeli Klient. Musisz przechowywać adres w tabeli Zamówienie.
- Dostosowanie wydajności: Jeśli zapytania są ciągle wolne z powodu połączeń, może być konieczne dodanie nadmiarowej kolumny, która jest aktualizowana za pomocą wyzwalaczy lub logiki aplikacji.
Kluczem jest celowość. Nie przyjmuj nadmiarowości jako domyślnej. Przyjmuj ją tylko wtedy, gdy istnieje mierzalna korzyść wydajności, która przewyższa koszt utrzymania.
🔄 Przeglądanie i utrzymanie schematu
Normalizacja to nie jednorazowa czynność. Wymagania biznesowe się zmieniają, a dane rosną. Schemat znormalizowany pięć lat temu może dziś wymagać dostosowania.
Regularne audyty
Zaplanuj okresowe przeglądy swojego ERD. Szukaj wzorców powtarzających się danych. Jeśli znajdziesz ten sam ciąg znaków pojawiający się w wielu tabelach, zbadaj dlaczego. Może to być oznaką błędu projektowego lub celowej decyzji o denormalizacji, która wymaga dokumentacji.
Kontrola wersji dla modeli danych
Traktuj swój ERD jak kod. Używaj systemów kontroli wersji do śledzenia zmian. Pozwala to na cofnięcie zmiany, jeśli wprowadza ona nadmiarowość lub niszczy relacje. Dokumentuj powody każdej istotnej zmiany strukturalnej.
Szczepienie zespołu
Upewnij się, że wszyscy uczestniczący w wprowadzaniu danych lub tworzeniu aplikacji rozumieją zasady normalizacji. Jeśli deweloperzy obejdą schemat, aby bezpośrednio wstawić dane, mogą ponownie wprowadzić nadmiarowość poprzez logikę aplikacji. Jasna dokumentacja wyjaśniająca, dlaczego schemat został zbudowany w ten sposób, jest niezbędna.
📝 Podsumowanie najlepszych praktyk
Aby utrzymać wysoki poziom jakości danych i efektywności przechowywania, przestrzegaj poniższej listy kontrolnej podczas procesu projektowania.
- Atomowość: Upewnij się, że każda kolumna zawiera jedną wartość (1NF).
- Pełna zależność: Upewnij się, że atrybuty niekluczowe zależą od całego klucza głównego (2NF).
- Brak zależności przechodnich: Upewnij się, że atrybuty niekluczowe nie zależą od innych atrybutów niekluczowych (3NF).
- Spójne klucze: Upewnij się, że każdy determinant jest kluczem kandydującym (BCNF).
- Dokumentuj decyzje: Zapisz, dlaczego wprowadzono konkretne nadmiarowości.
- Monitoruj wzrost: Obserwuj wzorce powtarzających się danych w miarę skalowania bazy danych.
Przestrzegając tych zasad, tworzysz system odporny na zmiany. Dane pozostają czyste, a logika pozostaje poprawna. Brak nadmiarowości to nie tylko oszczędność miejsca na dysku; to budowanie fundamentu, na którym zachowana jest prawda danych.
🚀 Ostateczne rozważania na temat integralności strukturalnej
Droga prowadząca do przechowywania bez nadmiarowości to inwestycja w długowieczność architektury danych. Choć wymaga dyscypliny w fazie projektowania, zyski są widoczne w zmniejszonych błędach, niższych kosztach utrzymania oraz większym zaufaniu do systemu informacyjnego.
Gdy patrzysz na diagram relacji encji, nie widzisz go tylko jako zbiór prostokątów i linii, ale jako mapę prawdy. Każda linia reprezentuje relację konieczną. Każdy prostokąt reprezentuje odrębny fakt. Poprzez skuteczną normalizację zapewnicasz, że ta mapa pozostaje dokładna, nawet gdy teren Twojego biznesu się zmienia.
Skup się na logice, a nie tylko na przechowywaniu. Niech struktura służy danym, a nie na odwrót. Posiadając jasne zrozumienie strategii normalizacji, jesteś gotów stworzyć systemy, które wytrzymają próbę czasu i objętości danych.