









企業アーキテクチャでは、システムが意図した通りに機能することを保証するために明確な定義が必要です。データはこの機能の基盤となります。ArchiMateフレームワーク内でモデル化する際、データがどこに存在するか、アプリケーションとどのように相互作用するかを理解することは不可欠です。アプリケーション層は、情報がどのように処理されるかを可視化するための特定の文脈を提供します。このガイドでは、この特定の層内でのデータモデルの構造化手法について詳述します。関係性、要素、正確な表現に必要なベストプラクティスについて検討します。
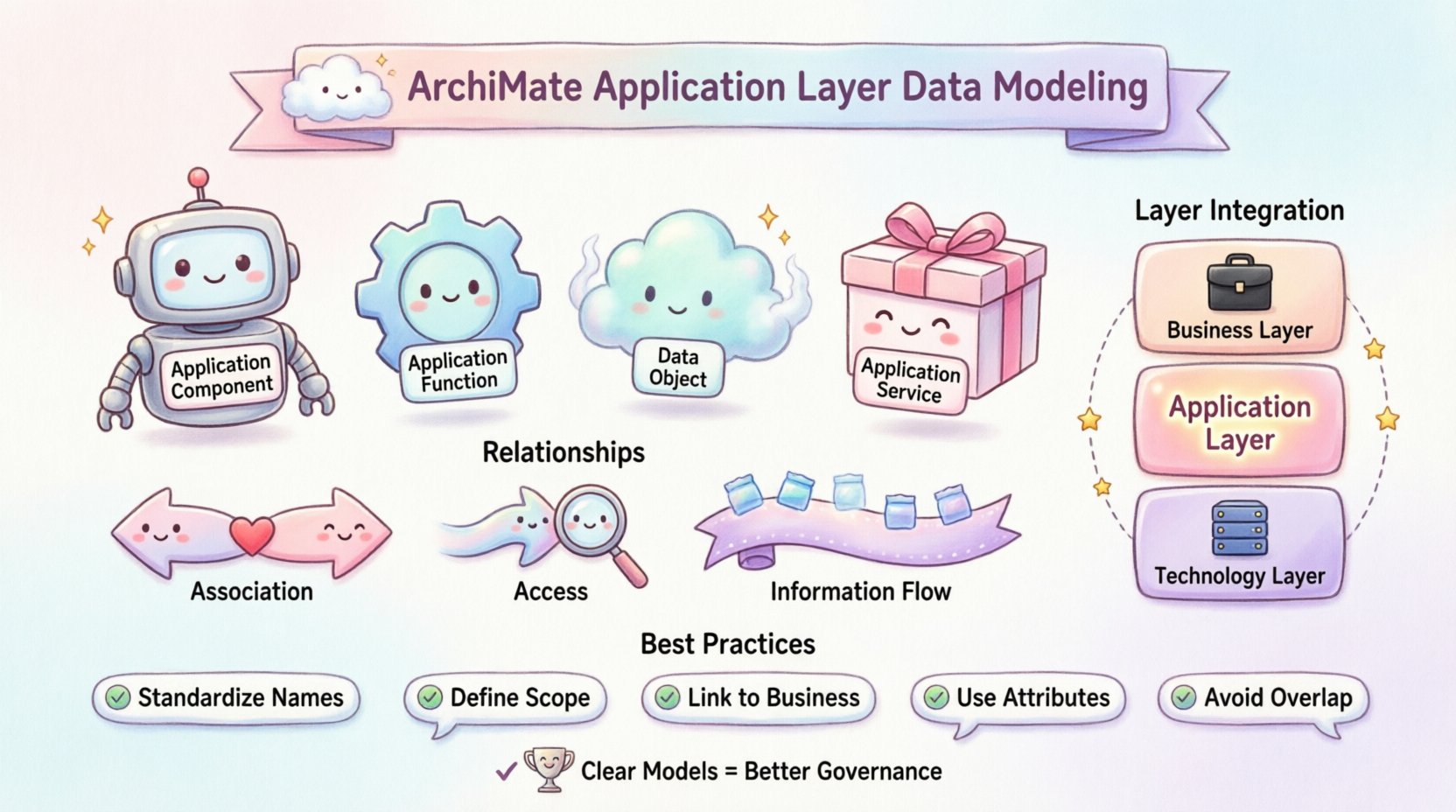
📊 アプリケーション層の文脈
アプリケーション層は、ビジネス要件と技術的実装の間のインターフェースとして機能します。組織に機能を提供するソフトウェアコンポーネントおよびサービスを記述します。ビジネス層がプロセスや役割に注目するのに対し、アプリケーション層はどのようにデータ処理の方法に注目します。この層のデータオブジェクトは、特定のアプリケーションが管理する情報状態を表します。
これらのモデルを正しく構造化することで、曖昧さを防ぐことができます。明確なモデルは、ステークホルダーがどのアプリケーションがどのデータを所有しているかを理解できるようにします。この明確さはガバナンスを支援し、技術的負債を削減します。以下のものが、この構造に関与する主要なコンポーネントです:
- アプリケーションコンポーネント: 情報を処理するデプロイ可能なソフトウェア単位。
- アプリケーション機能: アプリケーションコンポーネントによって実行される論理的な機能。
- データオブジェクト: アプリケーションが管理する情報状態または文書。
- アプリケーションサービス: アプリケーションが外部世界に提供する機能。
🔗 データの関係性の定義
関係性は、アーキテクチャ内でのデータの流れと依存関係を定義します。アプリケーション層では、特定の関係性タイプが関数とコンポーネント間での情報の移動をマッピングします。これらのマッピングを理解することは、データのルートを追跡するために不可欠です。
1. データオブジェクトとの関連
ある関連関連関係は、特定の関数またはコンポーネントがデータオブジェクトと相互作用していることを示します。これはデータモデリングで最も一般的なリンクです。関数がデータオブジェクトから読み取り、書き込み、または変更していることを意味します。
- 方向: 通常は双方向ですが、意味論的に流れを示すこともあります。
- 使用法: 所有権または直接アクセスを示すために使用します。
- 例: 「顧客管理機能」は「顧客記録」データオブジェクトと関連します。
2. アクセス関係
関連と似ていますが、アクセス関係は、1つの関数がデータオブジェクトにアクセスすることを指定する。これは、インタラクションが読み込み中心である場合や、関数が別のコンポーネントによって管理されているデータストアにアクセスするクライアントである場合にしばしば使用される。
- 使用法:所有権と使用状況の違いを明確にする。
- 明確さ:どのコンポーネントが真実のソースであるかを特定するのを助ける。
3. 情報フロー
情報フローデータが1つの要素から別の要素へ移動する様子を説明する。アプリケーション層では、この移動が関数の間、または関数と外部エンティティの間で頻繁に発生する。
- トリガー:特定のイベントが発生したときにデータが移動する。
- フォーマット:フローは特定のデータオブジェクト型を運ぶ。
- 文脈:統合マッピングに有用である。
📝 データオブジェクトを関数にマッピングする
データを効果的に構造化するためには、オブジェクトをそれらを操作する関数にマッピングする必要がある。このマッピングにより、データ所有権の行列が作成される。以下の表は、異なるデータ要素がアプリケーション関数とどのように相互作用するかを概説している。
| データ要素の種類 | 関数との相互作用 | 関係の種類 |
|---|---|---|
| 取引記録 | 処理関数 | アクセス |
| マスタデータ | 管理関数 | 関連 |
| ログファイル | モニタリング関数 | アクセス |
| レポート出力 | レポート関数 | 情報フロー |
この構造化されたアプローチは、データの重複を特定するのに役立ちます。複数の関数が同じデータオブジェクトに関連している場合、それらが同じソースを共有しているか、あるいは一方がコピーであるかを確認する必要があります。この検証は、データの一貫性をサポートします。
🛠️ モデリングのベストプラクティス
これらのモデルを構築する際には一貫性が鍵となります。既存の規則に従うことで、アーキテクチャが時間の経過とともに理解しやすくなることが保証されます。以下の実践をモデル化プロセスに組み込むべきです。
- 命名規則を標準化する:データオブジェクトに明確で一意の名前を付けるようにしてください。他の場所で文書化されていない省略語は避けてください。
- 範囲を明確に定義する:データオブジェクトが論理的か物理的かを明確にします。アプリケーション層は通常、論理的なデータ構造を扱います。
- ビジネス層にリンクする:データオブジェクトをビジネスオブジェクトに遡って追跡します。これにより、ビジネスコンテキストが保持されます。
- 属性を使用する:データオブジェクトの構造を説明するために属性を定義しますが、図を複雑にしすぎないようにします。
- 重複を避ける:論理的と物理的などの特定の理由がある場合を除き、同じデータオブジェクトを複数のレイヤーにモデル化しないでください。
⚠️ 避けるべき一般的な落とし穴
経験豊富なアーキテクトですら、データモデル化の際にミスを犯します。これらのパターンを認識することで、大幅な再作業を回避できます。以下は、構造化プロセス中に発生する一般的な問題です。
1. レイヤーの混同
ビジネスオブジェクトをアプリケーション層に直接配置すると混乱が生じます。ビジネスオブジェクトはビジネス層に属します。アプリケーション層には、そのビジネスコンセプトの実装を表すデータオブジェクトを含めるべきです。
- 修正:実現関係を介して、ビジネスオブジェクトをデータオブジェクトにマッピングする。
- 影響:レイヤーの混同は、ビジネスの意図とシステム機能の境界を曖昧にします。
2. 過剰モデル化
アプリケーション層内でデータベースのすべてのフィールドを文書化しようとするのは、混雑を招きます。このレイヤーの目的は、機能とフローを示すものであり、詳細なスキーマを記述することではありません。
- 修正:高レベルのデータオブジェクトを使用する。技術仕様に必要な場合にのみ、物理モデルに掘り下げること。
- 影響:アーキテクチャを可視化可能かつ保守可能に保ちます。
3. 永続性を無視する
データモデルは永続性を考慮しなければなりません。一部のデータは一時的(メモリ内)であり、他のデータは保存済み(データベース)です。これらを区別しないと、システムの耐障害性に関する誤った仮定をすることになります。
- 修正: 属性内または別々のテクノロジー層マッピングを通じて、永続化メカニズムに注意すること。
- 影響: データのライフサイクルおよび復旧要件を明確にする。
🔗 他のレイヤーとの統合
アプリケーションレイヤーは孤立して存在するものではない。ビジネスレイヤーおよびテクノロジー層と接続されている。適切な統合により、一貫性のあるアーキテクチャが確保される。
ビジネスレイヤーとの接続
アプリケーションレイヤーのデータはビジネスプロセスを支援する。A 実現関係により、ビジネスオブジェクトがアプリケーションデータオブジェクトにリンクされる。これにより、アプリケーションがビジネス要件を支援していることが確認される。
- フロー: ビジネスプロセスがビジネスオブジェクトを作成 → アプリケーション関数がアプリケーションデータオブジェクトを作成。
- 利点: 要件から実装へのトレーサビリティを確保する。
テクノロジー層との接続
アプリケーションレイヤーは、ストレージおよび計算のためにテクノロジー層に依存している。デプロイメント関係により、アプリケーションコンポーネントがテクノロジー・ノードにマッピングされる。アプリケーションレイヤーのデータオブジェクトは、テクノロジーレイヤーでデータストアとして実現される可能性がある。
- マッピング: アプリケーションデータオブジェクト → テクノロジー・データストア。
- 利点: テクニカルインフラが論理的なデータ要件をサポートしていることを検証する。
📈 データガバナンスの管理
モデルが構造化されると、ガバナンスの参照として機能する。モデル内の要素にデータガバナンスポリシーを適用できる。これにより、コンプライアンスおよび品質基準が満たされることを保証する。
- 所有権: モデル内の特定のデータオブジェクトにデータ所有者を割り当てる。
- 分類: 敏感度に基づいてデータオブジェクトにタグを付ける(例:公開、社内、機密)。
- 保持期間: データオブジェクトに関連する保持ポリシーを定義する。
- アクセス制御:ビジネス層のロールを、データにアクセスする関数にマッピングする。
このガバナンス層は、単なる可視化以上の価値を提供する。アーキテクチャモデルを管理ツールに変える。これらのモデルの定期的なレビューにより、ガバナンスポリシーが実際のシステム動作と一致したまま保たれる。
🧩 高度なシナリオ
場合によっては、標準的なモデリングでは複雑なシナリオに対応できない。高度な状況では、関係性や制約を慎重に検討する必要がある。
1. 複雑なデータ変換
データに大きな変換が加わる場合、複数の関数が関与する可能性がある。1つの関数が原始データを読み込み、処理済みデータを出力する場合がある。
- モデリング:入力状態と出力状態を表すために、2つの異なるデータオブジェクトを使用する。
- リンク:変換関数を介してそれらを接続する。
- 利点:変換によって追加される価値を明確に示す。
2. 共有データリソース
複数のアプリケーションが同じデータリソースを共有する可能性がある。これにより、ボトルネックやセキュリティリスクが生じる可能性がある。
- モデリング:1つのデータオブジェクトを作成し、複数のアプリケーション関数をそれとリンクする。
- 分析:このビューを使って、競合状態やロック戦略を分析する。
- 利点:依存関係と共有リスクを強調する。
3. 歴史的データ
アプリケーションはしばしばデータの歴史的バージョンを保存する必要がある。これには、時間ベースの属性をモデル化する必要がある。
- モデリング:バージョン管理や有効日を示すために、データオブジェクトに属性を追加する。
- 関係:関数が更新ロジックを正しく処理することを確認する。
- 利点:監査トレーやコンプライアンス要件をサポートする。
🔍 レビューと検証
データモデルを構造化した後は、検証が必要です。このプロセスにより、モデルが目標状態を正確に反映していることを保証します。検証には、完全性、一貫性、正確性の確認が含まれます。
- 完全性:すべての重要なデータオブジェクトが表現されていますか?
- 一貫性:モデル全体で名前と定義が一貫していますか?
- 正確性:関係性はシステムの動作を正確に反映していますか?
この段階で専門分野のエキスパートを関与させることを推奨します。彼らは、モデル化されたフローが実際の運用状態と一致しているかを検証できます。このフィードバックループにより、アーキテクチャの正確性が向上します。
🔄 モデルの維持
アーキテクチャは一度きりの作業ではありません。システムは進化し、データモデルもそれに伴って進化しなければなりません。維持作業には、変更を追跡し、モデルをそれに応じて更新することを含みます。
- 変更管理:アーキテクチャの更新を変更要求プロセスに統合する。
- バージョン管理:モデルのバージョン履歴を保持し、進化を追跡する。
- ドキュメント:モデル要素に変更が生じた際には、関連ドキュメントを更新する。
モデルと実際のシステムとの定期的な同期により、ずれが防がれます。ずれとは、モデルが現実を反映しなくなり、計画に役立たなくなる状態を指します。
📉 成功の測定
構造化作業が成功したとどうやって知るのでしょうか?データモデリングの効果を測るために、いくつかの指標を使用できます。
- 冗長性の低減:重複するデータストアが少なくなる。
- 明確性の向上:ステークホルダーがデータフローを簡単に追跡できる。
- 迅速な統合:定義されたデータ契約に基づいて、新しいシステムを迅速に統合できる。
- より良いガバナンス:データポリシーが一貫して適用される。
これらの指標は、アーキテクチャ作業の定量的根拠を提供します。構造化されたデータモデルが組織に与える価値を示しています。
🎯 主な要素の要約
要約すると、アプリケーションレイヤーのデータモデルは特定の要素と関係性に依存しています。成功したモデルは、これらのコンポーネントをスムーズに統合します。
- 要素:アプリケーションコンポーネント、機能、サービス、およびデータオブジェクト。
- 関係:関連、アクセス、情報フロー、実現。
- レイヤー:ビジネス、アプリケーション、テクノロジー、および動機。
- プロセス:定義、マッピング、検証、維持。
これらの原則に従うことで、アーキテクトは組織のデータ戦略を支援する強固なモデルを構築できる。その結果、情報が技術的環境の中でビジネス価値をどのように駆動しているかを明確に把握できる。