











データフローダイアグラム(DFD)は、システム論理の設計図として機能し、情報がプロセスを通じてどのように移動するかを示す。これらは、システム分析および設計において重要な成果物であり、ビジネス要件と技術的実装の間の橋渡しを行う。しかし、検証のない図は単なるスケッチに過ぎない。アーキテクチャの整合性を確保するため、すべてのDFDは厳密な検証を受ける必要がある。
このガイドは、データフローダイアグラムの検証のための包括的なフレームワークを提供する。構造的一貫性、論理的正確性、およびビジネスルールとの整合性に焦点を当てる。このチェックリストに従うことで、分析担当者は開発ライフサイクルの後半で高コストな再作業を回避できる。
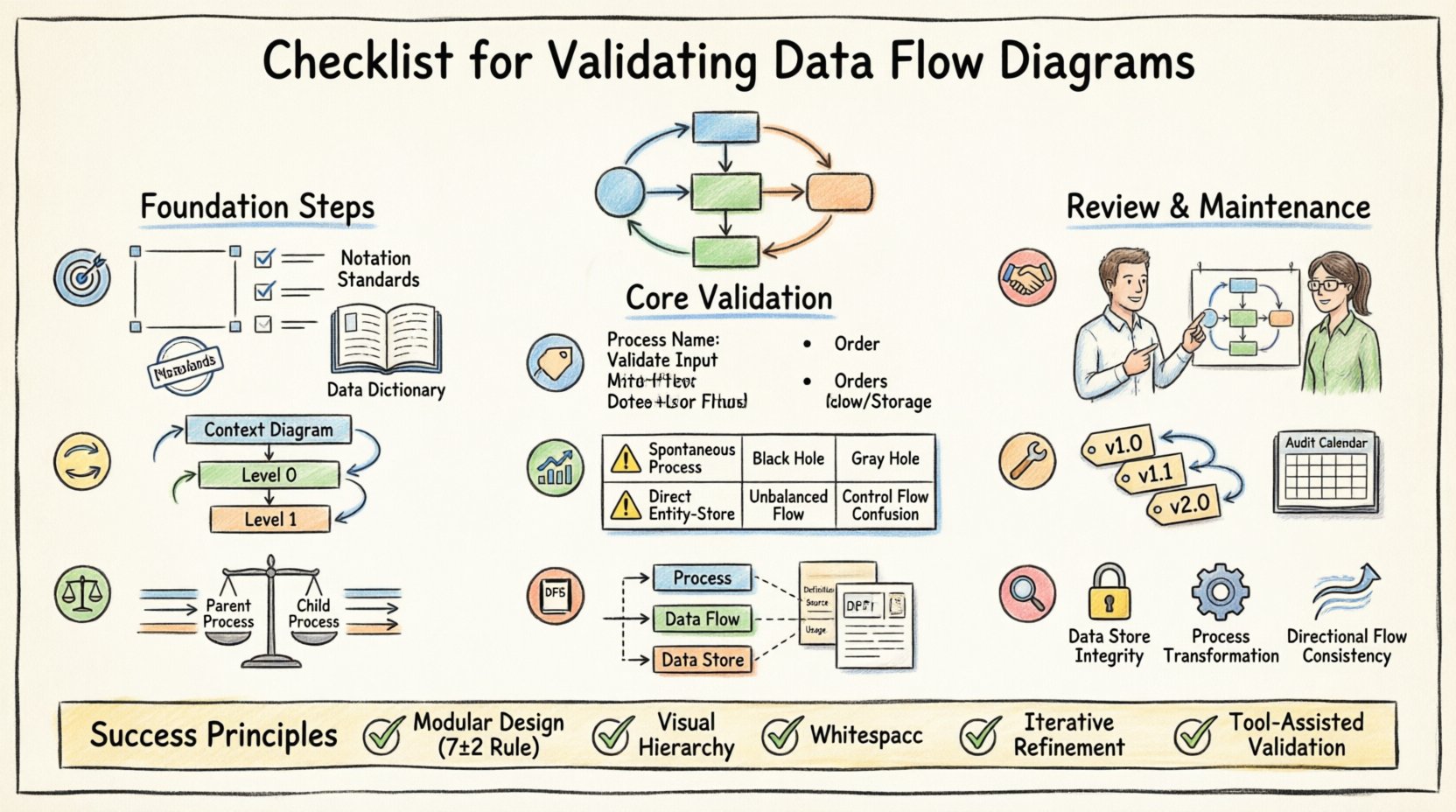
📋 検証前の準備
図の視覚的要素を検討する前に、文脈を明確にしなければならない。検証は空洞の中で行われることはできない。以下の前提条件が、レビュー過程の効果を確保する。
- システム境界を定義する:システム内部と外部を明確に識別する。外部エンティティ(情報源およびシンク)は明確に定義されなければならない。
- 要件を収集する:機能要件および非機能要件を用意しておく。図はこれらの仕様に直接対応している必要がある。
- 標準を確立する:表記規則の標準(例:Gane & Sarson と Yourdon & Coad)を合意する。異なる表記を混在させると、曖昧さが生じる。
- データ辞書を確認する:データ要素のマスターリストが存在することを確認する。データ定義が欠落している場合、DFDは有効とは言えない。
🔄 構造階層と分解
DFDは階層構造を持つ。コンテキスト図から始まり、レベル0、レベル1、さらに深いレベルへと分解される。検証には、これらの層間の関係を確認することが求められる。
1. コンテキスト図の検証
コンテキスト図(レベル-1)は、システムを単一のプロセスとして表現する。より深いレベルのレビューを行う前に、正確である必要がある。
- 単一のプロセスノード:システム全体を表すプロセスが正確に1つ存在することを確認する。
- 外部エンティティ:すべての外部情報源および目的地が存在することを確認する。エンティティが欠落していると、データフローも欠落していることを意味する。
- データフロー:システムへのすべての入力および出力を捉えていることを確認する。データの突然の生成や消滅は許されない。
2. レベル0と分解
レベル0では、単一のプロセスが主要なサブプロセスに分解される。ここから複雑性が生じ始める。
- プロセス数:プロセス数を管理可能な範囲(通常5〜9個)に制限する。プロセスが多すぎると、読者が混乱する。
- プロセス名:プロセス名は、動詞+名詞のアクション指向にするべきである。たとえば「請求書の計算」という名前が「請求書」よりも適切である。
- データストア: このレベルでデータが保持されている場所を特定してください。プロセスを介さずにデータストアが外部エンティティに直接接続されないようにしてください。
⚖️ バランスルール
DFD作成における最も一般的な誤りの一つは、バランスルールに違反することです。このルールは、親プロセスの入力と出力は、その子プロセスの入力と出力と完全に一致しなければならないと定めています。
- 入力の保存: 親プロセスが「顧客注文」を受け取る場合、子プロセスは collectively その「顧客注文」を受け取らなければなりません。親プロセスに存在しなかった新しい入力は、子レベルに出現してはいけません。
- 出力の保存: 親プロセスが「請求書」を送信する場合、子プロセスは collectively その「請求書」を送信しなければなりません。出力が突然消失したり、予期せぬ形で出現してはいけません。
- フローの検証: 親プロセスに入力するすべての線を追跡してください。親プロセスから出力するすべての線を追跡してください。それらが子図に存在することを確認してください。
- ストアの整合性: 親レベルでアクセスされるデータストアは、子レベルでデータの書き込みや読み取りが行われる場合、子レベルでもアクセス可能でなければなりません。
バランスが取れないと、高レベルの視点と詳細な実装との間に乖離が生じます。これにより、スコープ外の機能を開発者が実装したり、重要なデータ要件を無視する結果になることがよくあります。
🏷️ 名前付け規則
名前の一貫性は、可読性と保守性にとって非常に重要です。曖昧な名前は、システムの振る舞いを誤解する原因になります。
- プロセス: 動詞の後に名詞を使用してください。単語だけの名前は避けてください。正しい例: 「在庫を更新する」。誤りの例: 「在庫更新」。
- データフロー: 単数の名詞を使用してください。正しい例: 「アイテム」。誤りの例: 「アイテムたち」。
- データストア: 複数形の名詞を使用してください。正しい例: 「注文」。誤り: 「注文」。
外部エンティティ: 固有名詞またはビジネス用語を使用する。正しい: 「顧客」。誤り: 「ユーザー」。
📊 一般的な誤りと検証リスク
経験豊富なアナリストですら誤りを犯すことがあります。以下の表は、頻発する違反とそれらがシステムアーキテクチャに及ぼす可能性のある影響を概説しています。
| チェックカテゴリ | 検証基準 | 無視した場合のリスク |
|---|---|---|
| 自発的プロセス | すべてのプロセスには少なくとも1つの入力フローが必要である。 | データが何からも生成されており、システム論理に違反している。 |
| ブラックホール | すべてのプロセスには少なくとも1つの出力フローが必要である。 | 結果がなくデータが消費されているため、論理的なギャップを示している。 |
| グレイホール | 入力と出力のデータ内容は一致しなければならない。 | 変換の明確な定義なしにデータが変換されている。 |
| エンティティからストアへの直接接続 | エンティティとデータストアを直接結ぶデータフローが存在しない。 | ビジネスルールおよび検証ロジックを回避している。 |
| バランスの取れていないフロー | 親フローと子フローは一致しなければならない。 | アーキテクチャのずれ;実装が設計と一致しない。 |
| 制御フロー | DFDは制御信号ではなくデータを示す。 | データの移動とシステムのトリガーの間の混乱。 |
📚 データ辞書との整合性
データフローダイアグラムの質は、それを支えるデータ定義の質に依存する。データ辞書は、すべてのデータフローとデータストアの構造を定義するメタデータのリポジトリである。
- データ要素の整合性: DFDに記載されたデータ要素がデータ辞書に存在するか確認する。
- データ構造: データフローの構成を確認する。「カスタマーオーダー」には、定義された通り「カスタマーアイディー」と「オーダー日付」が含まれているか?
- 一意の識別子: データ整合性をサポートするために、データストアにプライマリキーが明確に識別されていることを確認する。
- 別名: ドキュメント全体でデータ要素に複数の名前が使われている場合、混乱を避けるために統一する。
- データ型: 図面とデータベーススキーマの間で、データ型(数値、文字列、日付)が整合していることを検証する。
🤝 ステークホルダーによるレビューと承認
技術的な正確さだけでは不十分である。図面は、要件を提供したビジネスのステークホルダーが理解できるものでなければならない。
- ビジネス用語:ラベルに技術用語を使用しないでください。ビジネスが使用する言葉を使うこと。
- ウォークスルー: ステークホルダーが特定の取引におけるデータの流れを追跡できるように、ウォークスルー会議を実施する。
- ギャップ分析: ステークホルダーに、図面に重要なビジネス活動が欠けているかどうか尋ねる。
- 検証承認: 公式的な承認を得る。これにより、図面が合意されたビジネス論理を正確に反映していることが確認される。
🛠️ メンテナンスとバージョン管理
システムは進化する。要件は変化する。今日有効なDFDが明日には無効になる可能性がある。メンテナンスは検証ライフサイクルの一部である。
- 変更管理: プロセス論理に変更がある場合は、DFDの更新が必要である。図面を更新せずにコードを更新してはならない。
- バージョン管理: 図面にバージョン番号と日付を付与する。変更履歴を維持し、システムの進化を理解する。
- リンク: DFDを要件仕様書にリンクする。要件が変更された場合、対応する図のノードをマークしなければならない。
- 定期監査: 実際のシステム動作と照らし合わせて、DFDの定期的なレビューをスケジュールする。時間の経過とともにずれが生じる。
🔍 詳細な技術的整合性チェック
一般的なルールを超えて、図が実装可能になることを確実にするために、特定の技術的制約を守らなければならない。
1. データストアの整合性
データストアは永続的ストレージを表す。一時的なものであってはならない。
- 読み取り/書き込みアクセス:ストアに書き込むすべてのプロセスが、必要に応じてそのストアから読み取っていることを確認する。データの変更が含まれる場合は、読み取り要件がないプロセスがストアに書き込まないことを保証する。
- 開放/閉鎖境界:データストアには開放境界があってはならない。すべてのデータストアは、少なくとも1つのプロセスに接続されている必要がある。
- ストア名:名前は内容を反映すべきであり、たとえば「従業員ファイル」のように、『ファイル1』のようなものではない。
2. プロセス論理の完全性
プロセスは変換論理を表す。
- 変換:プロセスが実際にデータを変更していることを確認する。データを単に通過させるだけのものは流れであり、プロセスではない。
- 決定ポイント: DFDは決定論理を明示的に示さない(フローチャートとは異なり)が、必要に応じて流れのラベルが条件を示すようにするべきである(たとえば「有効な注文」と「無効な注文」)。
- 外部依存: プロセスが外部システムに依存する場合、それは魔法の箱ではなく、外部エンティティまたはサブプロセスとして表現されるべきである。
3. フローの方向性
矢印はデータ移動の方向を示す。
- 単一方向:矢印は発信元から受信先へ向かうべきである。データフローが同じステップ内で真正に双方向である場合を除き、二重頭の矢印を使用してはならない。
- ラベルの明確さ: すべての矢印にはラベルがなければならない。ラベルのない流れは曖昧である。
- 交差禁止: 交差する線を最小限に抑える。線が交差する場合は、クロスオーバー記号を使用するか、レイアウトを再構成して可読性を向上させる。
🧠 認知負荷の低減
有効なDFDは技術的に正しいだけでなく、認知的にアクセスしやすいものでなければならない。図が複雑すぎると、その主な目的であるコミュニケーションに失敗する。
- モジュール化:複雑なプロセスをサブプロセスに分割する。プロセスの入力または出力が7つ以上ある場合は、分解する。
- 視覚的階層:プロセスには一貫した形状を使用し、データストアにはダイアモンド(表記法による)、エンティティには長方形を使用する。一貫性があることで認知負荷が軽減される。
- 余白:要素の間に余白を設ける。ごちゃごちゃした図はエラーを隠してしまう。
- 色分け:ツールが許す場合は、色を使って異なる種類のフロー(例:入力と出力)を区別するが、モノクロ印刷でも読み取り可能であることを確認する。
📝 最終的な考慮事項
検証は反復的なプロセスである。初回で成功することはめったにない。目標は、堅牢で明確かつ現実と整合したモデルを構築することである。
- 反復的精緻化:図の修正を複数回行うことを想定する。各修正によって明確性が向上するべきである。
- ドキュメントの整備:図とドキュメントを同期させる。テキストと図が矛盾している場合、システムは失敗する。
- トレーニング:チームが表記法を理解していることを確認する。レビュアーが記号を理解していないなら、チェックリストは無意味である。
- ツールの活用:構文規則を強制するモデリングツールを使用する。チェックリストは手動だが、ツールはバランスチェックなどの基本的なチェックを自動化できる。
この包括的なチェックリストに従うことで、データフローダイアグラムがシステムの信頼できる基盤として機能することを保証する。これらは開発をガイドし、ビジネスロジックを検証する動的な文書となる。この規律によりリスクが低減され、コミュニケーションが向上し、最終製品が意図された要件を満たすことが保証される。
図は単なる納品物ではなく、思考の道具であることを忘れないでください。図の検証を行うことで、アナリストはテスト開始まで隠れたままだった論理的な穴に直面せざるを得ません。徹底的に検証する時間を確保しましょう。