











システム分析およびソフトウェア工学の分野において、情報の流れを可視化することは極めて重要である。データフローダイアグラム(DFD)は、情報システム内を流れているデータの流れを図式化したものである。制御フローをマッピングするフローチャートとは異なり、DFDはデータの入力、出力、および保存にのみ焦点を当てる。この違いは、データの処理方法の手続き的論理に巻き込まれることなく、システムが扱うデータの内容を理解する必要があるアーキテクトやアナリストにとって、極めて重要である。
1970年代に開発されたDFDは、要件工学における基盤的な技術として今もなお重要である。DFDはシステムの高レベルな視点を提供し、ステークホルダーがすべての必要なデータ入力が捕捉されていること、すべての必要な出力が生成されていることを検証できる。複雑なシステムを扱いやすい構成要素に分割することで、技術チームとビジネスユーザーの間のコミュニケーションを促進する。このガイドでは、正確な図を構築するために必要な構造的要素、表記法の違い、および手法上のルールについて詳述する。
データフローダイアグラムの核心的な構成要素 🔍
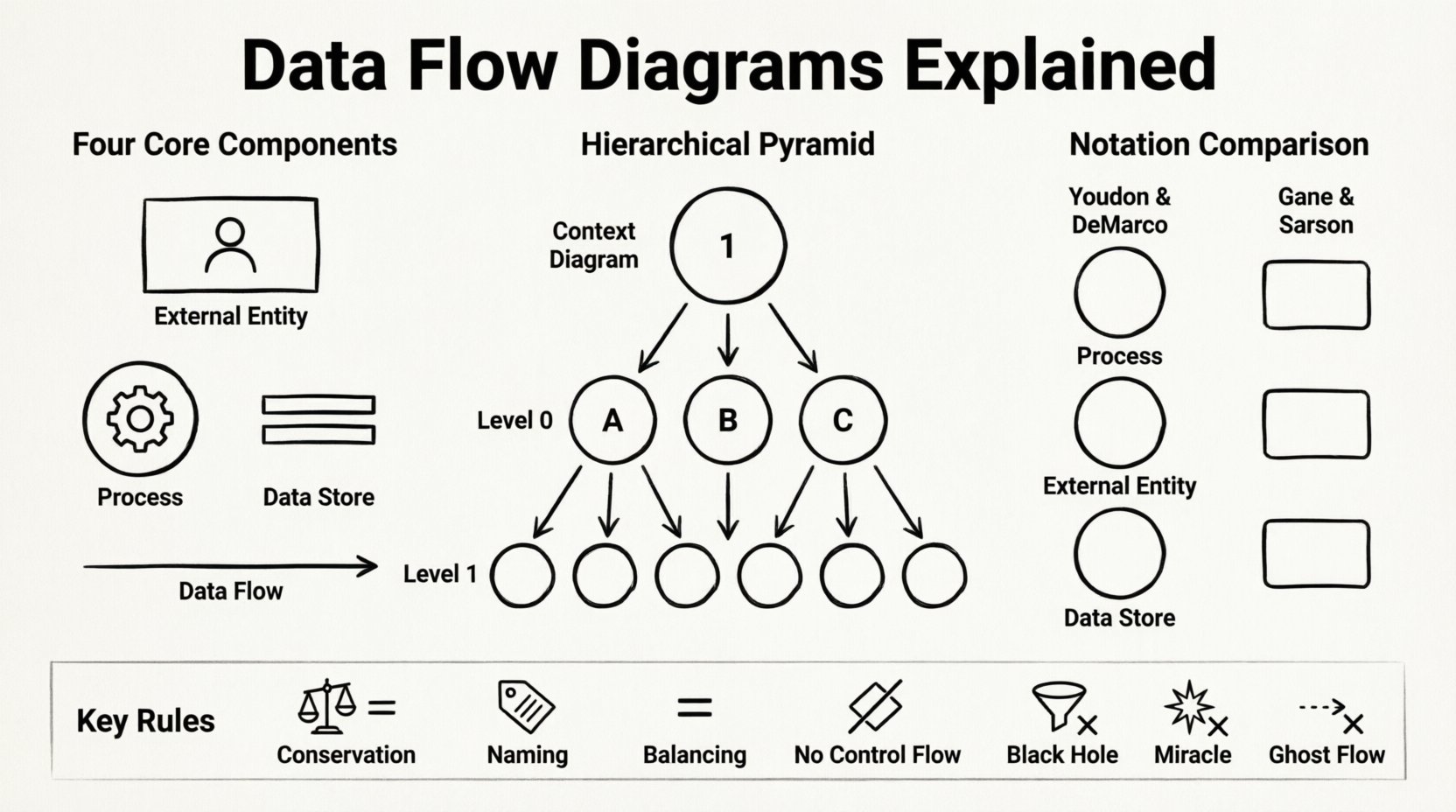
有効なDFDを構築するためには、4つの基本的な構成要素を理解する必要がある。複雑さに関係なく、すべての図はこれらの要素に依存して、システムの境界と内部動作を表現する。これらの構成要素を誤認すると、曖昧なモデルや論理的に整合性のないモデルが生じる可能性がある。
- 外部エンティティ:終端またはソースとも呼ばれるこれらは、モデル化されているシステムとやり取りする人、組織、または外部システムを表す。これらはデータフローの出発点または終点となる。エンティティはシステム境界の外に存在し、データをシステムに送信するか、システムからデータを受け取る。たとえば、注文を出す顧客や、報告書を受け取る政府の税務機関などである。
- プロセス:これらはシステム内で発生するアクションまたは変換を指す。プロセスは1つ以上のソースからデータを受け取り、それを変更して他の宛先に送信する。プロセスはデータを保存しないことに注意が必要である。プロセスはデータを変換するのみである。プロセスは通常、「税金を計算する」や「ユーザー認証情報を検証する」などの動詞句でラベル付けされる。
- データストア:これらは後で使用するためにデータを保持するリポジトリを表す。プロセスとは異なり、データストアは計算を行わない。これらは受動的なコンテナである。物理的な文脈では、データベーステーブル、ファイル、または実際の書類棚を指すことがある。論理的な文脈では、情報が永続化される場所を単に示す。データフローはデータストアに入り、出ていくことで、更新や取得を示す。
- データフロー:これらは構成要素をつなぐ矢印である。データの移動を表す。データフローには、データパケットの内容を説明する名前が必要である。たとえば「注文詳細」や「支払い確認」などである。すべてのデータフローは2つの構成要素を接続しなければならない。空中に途中から始まったり、途中で終わったりすることはできない。
データフローダイアグラムの種類 🗺️
DFDは階層的である。複雑なシステムは1つの視点では理解できない。そのため、標準的な手法として、システムを複数の抽象レベルに分解する。このアプローチにより、アナリストは全体の文脈を失うことなく、特定の領域に注目して詳細を確認できる。
1. コンテキスト図(レベル0)
これは最も高い抽象度である。システム全体を1つのプロセスバブルとして描写する。システムと外部エンティティとの関係を示す。この段階では、内部プロセスやデータストアは表示されない。目的は、システムの境界を明確に定義することである。この図は、「このシステムは外部世界に対して何を実行するのか?」という問いに答える。
2. レベル0図(図0)
コンセプトモデルとも呼ばれるこの図では、コンテキスト図の単一プロセスを主要なサブプロセスに分解する。システムの主要機能のマップを提供する。主要なデータフローが主なプロセスとデータストア、外部エンティティをどのように接続しているかを示す。これは詳細設計の最初のステップとしてよく用いられる。
3. レベル1と分解
分析が進むにつれて、レベル0のプロセスはさらにレベル1の図に分解される。このプロセスは、プロセスが直接実装可能なほど単純になるまで繰り返される。各子図は親図とバランスを取らなければならない。つまり、親図のプロセスの入力と出力は、展開されたプロセスを含む子図の入力と出力と一致しなければならない。
表記法の標準比較 📐
DFDを描くための単一の普遍的な標準は存在しない。業界を支配する2つの主要な流派がある。両者とも同じ論理情報を伝えるが、構成要素を表すために異なる形状を使用する。プロジェクト内の一貫性を保つためには、1つの標準を選択し、それを徹底的に守ることが不可欠である。
| 構成要素 | Yourdon & DeMarco表記法 | Gane & Sarson表記法 |
|---|---|---|
| プロセス | 円またはラウンド矩形 | ラウンド矩形 |
| データストア | 平行な水平線が2本 | 開口のある長方形 |
| 外部エンティティ | 長方形 | 長方形 |
| データフロー | 曲がったまたは直線の矢印 | 直線の矢印 |
| 注釈 | フローの近くのテキスト | フローの近くのテキスト |
形状は異なっても、接続を規定するルールは同一である。Yourdon & DeMarcoスタイルは、古いレガシードキュメントでよく好まれるが、Gane & Sarsonスタイルは、より洗練された長方形の美学から、現代のシステムで頻繁に採用されている。
論理的と物理的の違い 🔄
DFDモデリングにおける重要な概念は、論理設計と物理設計の分離である。この区別により、基盤技術が変更されてもモデルが有効であることが保証される。
- 論理的DFD: ビジネス要件に焦点を当てる。システムが何をするかを記述するが、その方法は記述しない。論理図では、「データベース」は、SQL、NoSQL、またはフラットファイルであるかを指定せずに、一般的にデータストアとして表現されることがある。「プロセス」は、承認が人間、スクリプト、またはAIアルゴリズムによって行われるかに関わらず、「ローン承認」である可能性がある。
- 物理的DFD: 実装の詳細に焦点を当てる。システムがどのように構築されているかを記述する。ここでは、データストアは「Server AのOracleテーブル」として指定されることがある。プロセスは「Java Servletによるリクエスト処理」となる。物理図は、開発者がコーディング段階で使用する。
これらのレベルを1つの図に混在させると混乱を招く。ステークホルダーのレビュー用に論理ビューを維持し、技術的実装用に物理ビューを維持することがベストプラクティスである。
DFDの作成ルール ⚙️
図を描くことは単に形状を描くことではない。厳密な論理ルールに従うことが重要である。これらのルールを違反すると、図は技術的に無効となり、分析に役立たなくなる。
1. データの保存則
データはプロセス内で作成または破壊できない。データがプロセスに入れば、そのデータはプロセスから出るか、保存されなければならない。入力されていないデータを出力することはできないが、他の入力から導出されたデータは例外である。これにより、システム設計における「奇跡」を防ぐ。
2. 名前付けの規則
すべての要素には一意の名前が必要である。データフローは名詞(例:「請求書」)とする。プロセスは動詞+名詞の表現(例:「請求書処理」)とする。データストアは複数形の名詞(例:「請求書」)とする。名前の一貫性により、システムのナビゲーションと理解が容易になる。
3. バランス
このルールは階層的分解に適用される。プロセスがサブプロセスに分解される場合、親プロセスの入力と出力は、子プロセスの入力と出力の合計と等しくなければならない。分解中にデータが消えたり、魔法のように現れることはない。
4. コントロールフローの回避
DFDはコントロールフローダイアグラムではない。例えば「XならばY」といった決定ポイントを示さない。データの移動を示すものである。決定ロジックは図自体ではなく、プロセスの説明の中で扱われる。これにより、視覚的表現が明確になり、データに焦点が当たる。
避けるべき一般的な落とし穴 ❌
経験豊富なアナリストでさえ、DFDに誤りをもたらすことがあります。一般的なミスに気づくことで、モデルの整合性を保つことができます。
- ブラックホール:入力はあるが出力がないプロセス。これはデータが消費され、一切使われないことを意味しており、論理的な誤りです。
- 奇跡:出力はあるが入力がないプロセス。これはデータが空から生成されていることを意味します。
- ゴーストフロー:どのコンポーネントにも接続されていないデータフロー。すべての矢印には明確な出所と目的地が必要です。
- 関数の重複:単一のプロセスボックスがやりすぎようとしている状態。プロセスボックスに7つ以上の入力または出力がある場合、多くのことを試みている可能性が高く、分割すべきです。
- 外部エンティティのループ:外部エンティティ同士は直接接続してはいけません。すべての相互作用はシステム境界を経由しなければなりません。
システム分析における利点 🛠️
これらの図を描くために時間を投資する理由は何か?その価値は単なる文書化をはるかに超えています。
- コミュニケーション:技術者と非技術者との間のギャップを埋めます。視覚的なモデルはテキストによる要件よりも議論しやすいです。
- ギャップ分析:フローをマッピングすることで、アナリストは欠落しているデータ要件を特定できます。ユーザーがレポートを必要としているが、そのレポートをサポートするデータストアに至るデータフローがない場合、早期にギャップが明らかになります。
- テストの基盤:データフローがテストケースを定義します。特定のデータフローが定義されている場合、テストはそのフローを通じてデータが正しく移動していることを確認しなければなりません。
- システム文書化:システムが進化するにつれて、DFDは動的な地図として機能します。新しい機能が追加されると図が更新され、文書化がコードと同期されたまま保たれます。
よくある質問 ❓
DFDとフローチャートの違いは何ですか?
フローチャートはアルゴリズムの制御論理と決定ポイントをマッピングします。ステップの順序を示します。DFDはデータをマッピングします。データの出所と到着先を示し、処理の順序とは無関係です。フローチャートはコード論理用、DFDはシステムアーキテクチャ用です。
DFDはセキュリティ制御を示すことができますか?
標準的なDFDは、暗号化や認証のようなセキュリティプロトコルを明示的に示しません。しかし、セキュリティアナリストはデータフローに注釈を加えることで、機密データがどのように扱われるか、またはアクセス制御が適用される場所を示すことができます。これは通常、特定のデータフローに付随するメモとして表現されます。
DFDを描くために特定のツールが必要ですか?
いいえ。多くのソフトウェアツールは存在しますが、図は概念的な産物です。紙、ホワイトボード、または任意のベクターグラフィックツールで描くことができます。媒体がモデルの論理を変えることはありません。
DFDはリアルタイムデータをどのように扱いますか?
DFDは一般的に静的な表現です。タイミングや遅延を本質的に示すことはありません。リアルタイムシステムの場合、DFDは状態遷移図やタイミング図と組み合わせて、データ移動の時間的側面を捉えます。
手法に関する結論
データフローダイアグラムを作成することは、抽象化のための厳格な作業である。アナリストは実装の詳細を排除し、データ移動の本質に注目する必要がある。構造上のルールおよび表記の標準に従うことで、チームは情報システムの明確なブループリントを構築できる。この明確さによりリスクが低減され、コミュニケーションが向上し、最終的なシステムが処理するデータの実際のニーズを満たすことが保証される。
DFDは、根本的な問いかけ「データはどこへ行くのか?」に答えるため、依然として重要性を保っている。複雑で分散型のシステムが主流となる現代において、情報の流れを追跡することはかつてないほど重要である。シンプルなウェブアプリケーションであろうと大規模なエンタープライズシステムであろうと、DFDモデリングの原則は設計と分析の安定した基盤を提供する。