











Dans le paysage de l’analyse système et du génie logiciel, visualiser le mouvement de l’information est primordial. Un diagramme de flux de données, souvent abrégé en DFD, sert de représentation graphique du flux de données à travers un système d’information. Contrairement aux diagrammes de flux qui cartographient le flux de contrôle, un DFD se concentre strictement sur les entrées de données, les sorties et le stockage. Cette distinction est cruciale pour les architectes et les analystes qui doivent comprendre quelles données un système traite sans s’embrouiller dans la logique procédurale de leur traitement.
Développé dans les années 1970, le DFD reste une technique fondamentale pour l’ingénierie des exigences. Il fournit une vue d’ensemble du système, permettant aux parties prenantes de valider que toutes les entrées de données nécessaires sont capturées et que toutes les sorties requises sont produites. En décomposant les systèmes complexes en composants gérables, les DFD facilitent la communication entre les équipes techniques et les utilisateurs métiers. Ce guide détaille les éléments structurels, les variations de notation et les règles méthodologiques nécessaires à la construction de diagrammes précis.
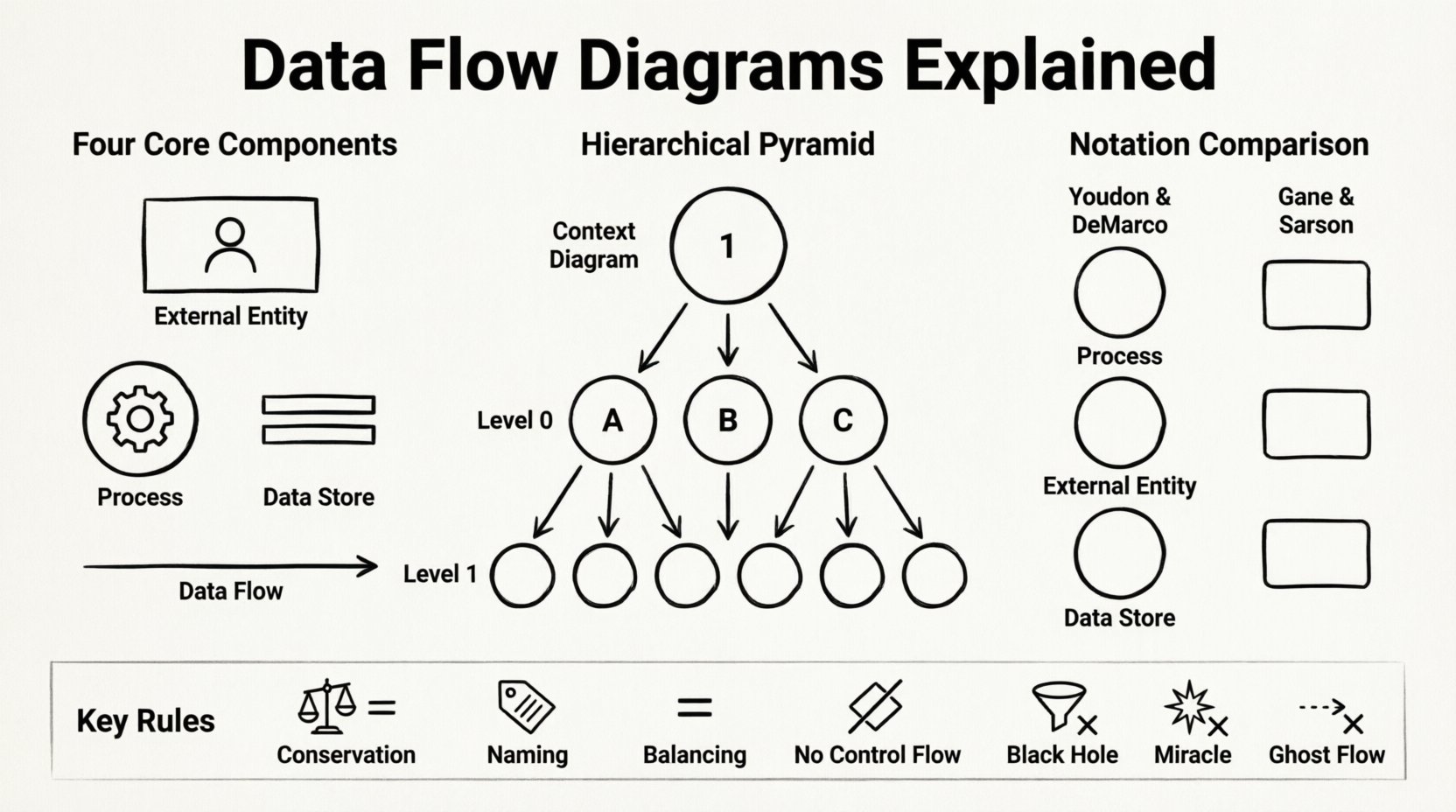
Composants fondamentaux d’un diagramme de flux de données 🔍
Pour construire un DFD valide, il faut comprendre les quatre blocs de construction fondamentaux. Chaque diagramme, quelle que soit sa complexité, repose sur ces éléments pour représenter les frontières du système et ses opérations internes. Une mauvaise identification de ces composants peut entraîner des modèles ambigus ou logiquement incohérents.
- Entités externes : Aussi appelées terminaisons ou sources, elles représentent des personnes, des organisations ou des systèmes externes qui interagissent avec le système modélisé. Elles constituent les points de départ ou d’arrivée des flux de données. Une entité existe en dehors de la frontière du système et envoie des données vers le système ou en reçoit. Par exemple, un client passant une commande ou une administration fiscale gouvernementale recevant des rapports.
- Traitements : Ce sont les actions ou transformations qui ont lieu à l’intérieur du système. Un traitement prend des données provenant d’une ou plusieurs sources, les modifie, puis les envoie vers d’autres destinations. Il est crucial de se rappeler qu’un traitement ne stocke pas de données ; il ne les transforme que. Les traitements sont généralement étiquetés par une expression verbale, comme « Calculer la taxe » ou « Vérifier les identifiants utilisateur ».
- Stockages de données : Ils représentent des répertoires où les données sont conservées pour une utilisation ultérieure. Contrairement aux traitements, les stockages de données ne réalisent pas de calculs. Ils sont des conteneurs passifs. Dans un contexte physique, ils peuvent être des tables de base de données, des fichiers ou des classeurs physiques. Dans un contexte logique, ils indiquent simplement où les informations sont persistées. Les flux de données doivent entrer et sortir des stockages de données pour indiquer des mises à jour ou des récupérations.
- Flux de données : Ce sont les flèches reliant les composants. Elles représentent le déplacement des données. Un flux de données doit avoir un nom qui décrit le contenu du paquet de données, comme « Détails de la commande » ou « Confirmation de paiement ». Chaque flux de données doit relier deux composants ; il ne peut ni commencer ni finir en l’air.
Types de diagrammes de flux de données 🗺️
Les DFD sont hiérarchiques. Un système complexe ne peut pas être compris en une seule vue. Par conséquent, la pratique standard consiste à décomposer le système en plusieurs niveaux d’abstraction. Cette approche permet aux analystes de zoomer sur des zones spécifiques sans perdre le contexte global.
1. Diagramme de contexte (Niveau 0)
Il s’agit du niveau d’abstraction le plus élevé. Il représente l’ensemble du système sous la forme d’une seule bulle de processus. Il montre la relation entre le système et les entités externes. Aucun processus interne ni stockage de données n’est visible à ce stade. Le but est de définir clairement la frontière du système. Il répond à la question : « Que fait ce système pour le monde extérieur ? »
2. Diagramme de niveau 0 (Diagramme 0)
Également appelé modèle conceptuel, ce diagramme éclate le processus unique du diagramme de contexte en sous-processus principaux. Il fournit une cartographie des fonctions principales du système. Il montre comment les principaux flux de données relient les processus principaux aux stockages de données et aux entités externes. Il constitue souvent la première étape de la conception détaillée.
3. Niveau 1 et décomposition
Au fur et à mesure que l’analyse progresse, les processus du niveau 0 sont décomposés davantage en diagrammes du niveau 1. Ce processus se poursuit jusqu’à ce que les processus soient suffisamment simples pour être implémentés directement. Chaque diagramme enfant doit être équilibré par rapport à son parent. Cela signifie que les entrées et sorties d’un processus dans le diagramme parent doivent correspondre aux entrées et sorties du diagramme enfant contenant le processus décomposé.
Comparaison des normes de notation 📐
Il n’existe pas de norme universelle unique pour dessiner les DFD. Deux grandes écoles de pensée dominent l’industrie. Les deux transmettent les mêmes informations logiques, mais utilisent des formes différentes pour représenter les composants. Choisir une norme et s’y tenir est essentiel pour assurer la cohérence au sein d’un projet.
| Composant | Notation Yourdon & DeMarco | Notation Gane & Sarson |
|---|---|---|
| Processus | Cercle ou rectangle arrondi | Rectangle arrondi |
| Stockage de données | Deux lignes horizontales parallèles | Rectangle ouvert |
| Entité externe | Rectangle | Rectangle |
| Flux de données | Flèche courbe ou droite | Flèche droite |
| Annotation | Texte près du flux | Texte près du flux |
Bien que les formes diffèrent, les règles régissant les connexions restent identiques. Le style Yourdon & DeMarco est souvent préféré dans la documentation ancienne et héritée, tandis que le style Gane & Sarson est fréquemment adopté dans les systèmes modernes en raison de son esthétique rectangulaire plus propre.
La distinction logique vs. physique 🔄
Un concept fondamental dans la modélisation DFD est la séparation de la conception logique de la conception physique. Cette distinction garantit que le modèle reste valide même si la technologie sous-jacente change.
- DFD logique : Se concentre sur les exigences métiers. Il décrit ce que le système fait, et non comment il le fait. Dans un diagramme logique, une « base de données » pourrait être représentée de manière générique comme un stockage de données, sans préciser s’il s’agit de SQL, NoSQL ou d’un fichier plat. Un « processus » pourrait être « Approuver un prêt », indépendamment du fait que l’approbation soit effectuée par un humain, un script ou un algorithme d’IA.
- DFD physique : Se concentre sur les détails d’implémentation. Il décrit comment le système est construit. Ici, le stockage de données pourrait être précisé comme « Tables Oracle sur le serveur A ». Le processus pourrait être « Servlet Java traitement de la requête ». Les diagrammes physiques sont utilisés par les développeurs pendant la phase de codage.
Mélanger ces niveaux dans un seul diagramme crée de la confusion. Il est de bonne pratique de maintenir une vue logique pour la revue par les parties prenantes et une vue physique pour l’implémentation technique.
Règles pour la construction d’un DFD ⚙️
Créer un diagramme ne consiste pas seulement à dessiner des formes ; il s’agit de respecter des règles logiques strictes. Violation de ces règles rend le diagramme techniquement invalide et inutile pour l’analyse.
1. Conservation des données
Les données ne peuvent pas être créées ou détruites au sein d’un processus. Si des données entrent dans un processus, elles doivent soit en sortir, soit être stockées. Un processus ne peut pas produire des données qui n’ont pas été entrées, sauf si ces données sont dérivées d’autres entrées. Cela évite les « miracles » dans la conception du système.
2. Conventions de nommage
Chaque élément doit avoir un nom unique. Les flux de données doivent être des noms (par exemple, « Facture »). Les processus doivent être des phrases verbe-nom (par exemple, « Traiter la facture »). Les stockages de données doivent être des noms pluriels (par exemple, « Factures »). La cohérence dans le nommage facilite la navigation et la compréhension du système.
3. Équilibre
Cette règle s’applique à la décomposition hiérarchique. Si un processus est décomposé en sous-processus, les entrées et sorties du processus parent doivent être égales à la somme des entrées et sorties des sous-processus. Aucune donnée ne peut disparaître ou apparaître magiquement lors de la décomposition.
4. Éviter le flux de contrôle
Les DFD ne sont pas des diagrammes de flux de contrôle. Ils ne montrent pas de points de décision comme « Si X, alors Y ». Ils montrent le déplacement des données. La logique décisionnelle est traitée dans la description du processus, et non sur le diagramme lui-même. Cela maintient la représentation visuelle claire et centrée sur les données.
Péchés courants à éviter ❌
Même les analystes expérimentés peuvent introduire des erreurs dans un DFD. Être conscient des erreurs courantes aide à préserver l’intégrité du modèle.
- Les trous noirs : Un processus qui a des entrées mais pas de sorties. Cela implique que les données sont consommées et jamais utilisées, ce qui constitue une erreur logique.
- Les miracles : Un processus qui a des sorties mais pas d’entrées. Cela implique que les données sont générées de nulle part.
- Les flux fantômes : Des flux de données qui ne sont connectés à aucun composant. Chaque flèche doit avoir une source et une destination claires.
- Les fonctions chevauchantes : Lorsqu’une seule boîte de processus essaie de faire trop de choses. Si une boîte de processus a plus de sept entrées ou sorties, elle essaie probablement de faire trop de choses et doit être divisée.
- Les cycles d’entités externes : Les entités externes ne doivent pas être connectées directement entre elles. Toutes les interactions doivent passer par la frontière du système.
Avantages de l’analyse système 🛠️
Pourquoi investir du temps à créer ces diagrammes ? La valeur va au-delà de la simple documentation.
- Communication : Elle comble le fossé entre les parties prenantes techniques et non techniques. Les modèles visuels sont plus faciles à discuter que les exigences textuelles.
- Analyse des écarts : En cartographiant le flux, les analystes peuvent identifier les exigences de données manquantes. Si un utilisateur a besoin d’un rapport, mais qu’il n’y a pas de flux de données menant à un stockage de données qui soutient ce rapport, un écart est détecté tôt.
- Base de test : Les flux de données définissent les cas de test. Si un flux de données spécifique est défini, un test doit vérifier que les données se déplacent correctement à travers ce flux.
- Documentation du système : Au fur et à mesure que les systèmes évoluent, les DFD servent de carte vivante. Lorsque de nouvelles fonctionnalités sont ajoutées, le diagramme est mis à jour, garantissant que la documentation reste synchronisée avec le code.
Questions fréquemment posées ❓
Quelle est la différence entre un DFD et un organigramme ?
Un organigramme cartographie la logique de contrôle et les points de décision d’un algorithme. Il montre la séquence des étapes. Un DFD cartographie les données. Il montre d’où viennent les données et où elles vont, indépendamment de l’ordre des opérations. Les organigrammes sont pour la logique du code ; les DFD sont pour l’architecture du système.
Un DFD peut-il montrer des contrôles de sécurité ?
Les DFD standards ne montrent pas explicitement les protocoles de sécurité tels que le chiffrement ou l’authentification. Toutefois, un analyste sécurité peut annoter les flux de données pour indiquer où les données sensibles sont traitées ou où les contrôles d’accès sont appliqués. Cela est souvent représenté par une note attachée au flux de données spécifique.
Un outil spécifique est-il nécessaire pour dessiner des DFD ?
Non. Bien que de nombreux outils logiciels existent, le diagramme est un artefact conceptuel. Il peut être dessiné sur papier, sur un tableau blanc ou à l’aide de n’importe quel outil de graphisme vectoriel. Le support n’a pas d’effet sur la logique du modèle.
Comment les DFD traitent-ils les données en temps réel ?
Les DFD sont généralement des représentations statiques. Ils ne montrent pas intrinsèquement le temps ou la latence. Pour les systèmes en temps réel, les DFD sont souvent associés à des diagrammes de transition d’état ou des diagrammes de temporisation pour capturer les aspects temporels du déplacement des données.
Conclusion sur la méthodologie
La construction d’un diagramme de flux de données est un exercice rigoureux d’abstraction. Elle oblige l’analyste à éliminer les détails d’implémentation et à se concentrer sur l’essence du déplacement des données. En respectant les règles structurelles et les normes de notation, les équipes peuvent créer un plan clair de leurs systèmes d’information. Cette clarté réduit les risques, améliore la communication et garantit que le système final répond aux besoins réels des données qu’il traite.
Le DFD reste pertinent car il aborde une question fondamentale : « Où vont les données ? » À une époque de systèmes complexes et distribués, suivre le parcours de l’information est plus crucial que jamais. Que ce soit pour une application web simple ou un système d’entreprise à grande échelle, les principes de modélisation DFD fournissent une base stable pour la conception et l’analyse.