











データフローダイアグラム(DFD)は、システム分析および設計の重要な設計図として機能します。情報がシステム内でどのように移動するかを視覚的に表現し、制御論理ではなくデータの流れに焦点を当てます。新しいエンタープライズリソースプランニングシステムの設計中であろうと、既存のレガシーアプリケーションの分析中であろうと、データの動きを理解することは明確さと効率性のために不可欠です。このガイドでは、特定の商業ツールに依存せずに、効果的なDFDを作成するためのメカニズム、ルール、およびベストプラクティスを検討します。
データフローダイアグラムとは何か? 🤔
データフローダイアグラムは、システム内のデータの流れを可視化するために使用される構造化分析手法です。複雑なシステムをより小さな、管理しやすい部分に分解し、データがどのように入力され、処理され、保存され、出力されるかを示します。他の図が時間的な順序や意思決定論理に注目するのに対し、DFDはデータエンティティとその変換を厳密に追跡します。
これらの図は、ソフトウェア開発ライフサイクルにおいて、いくつかの重要な目的を果たします:
- コミュニケーション: 技術チームとステークホルダーの間のギャップを埋めるために、視覚的な言語を提供します。
- ギャップ分析: 要件収集フェーズ中に、欠落しているプロセスやデータ経路を特定するのに役立ちます。
- ドキュメント化: 将来の保守やトラブルシューティングのための参照資料として機能します。
- 最適化: データが蓄積されたり、非効率的に移動するボトルネックを明らかにします。
DFDは階層的です。複雑なシステムは単一のビューで描かれることがめったにありません。代わりに、複数の詳細レベルに分解され、分析者が必要に応じて特定の領域にズームインできるようになります。
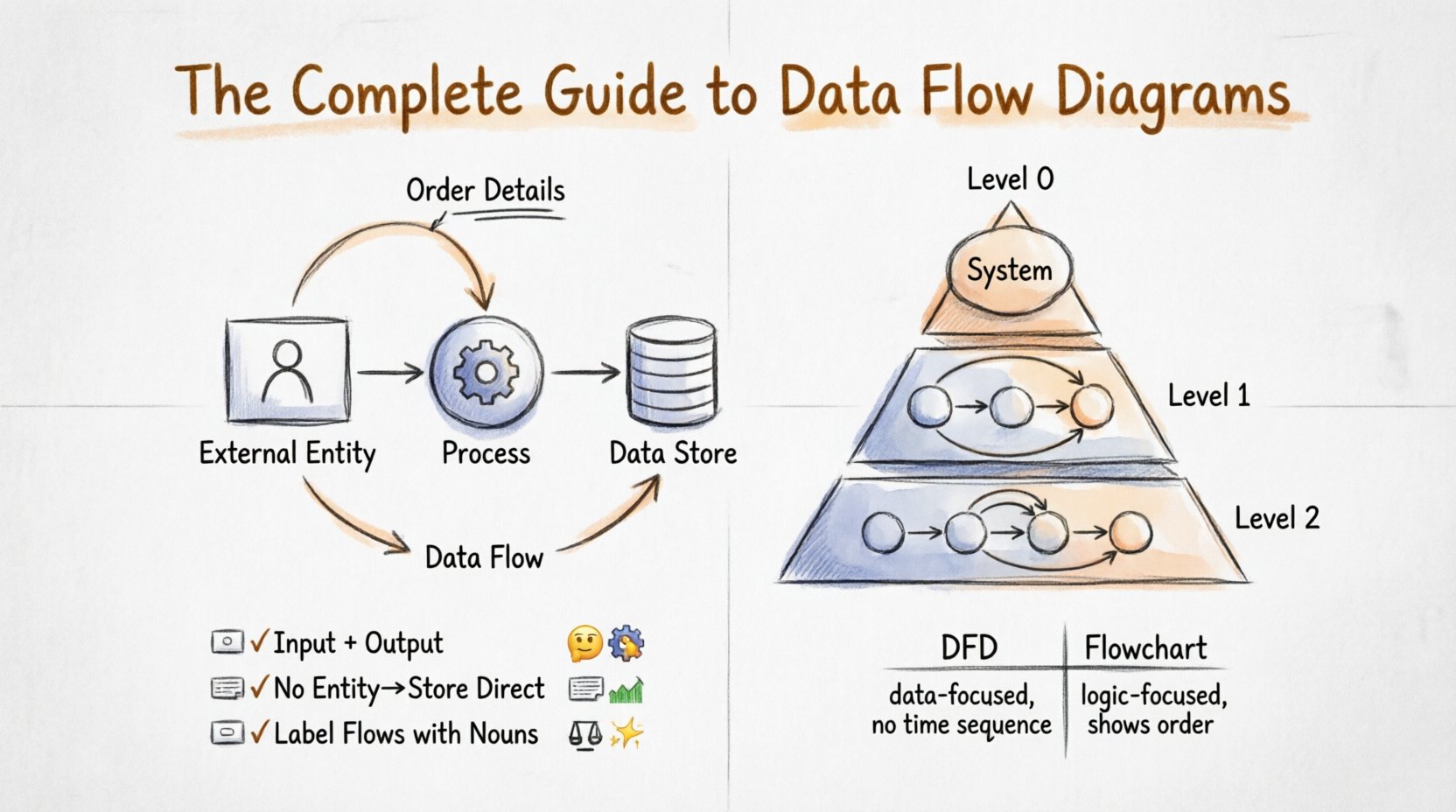
4つの核心的な構成要素 🧩
有効なデータフローダイアグラムを構築するには、4つの基本的な構成要素を理解する必要があります。DFD内のすべての要素は、これらのカテゴリのいずれかに属します。
| 構成要素 | 記号の説明 | 機能 | 例 |
|---|---|---|---|
| 外部エンティティ | 長方形または正方形 | システム境界外のデータの発生源または目的地。 | 顧客、管理者、サードパーティAPI |
| プロセス | 円または角が丸い長方形 | 入力データを出力データに変換する。 | 税金計算、ユーザー検証、レポート生成 |
| データストア | 開口部のある長方形または平行線 | 後で取得するためにデータが保存される場所。 | データベース、ファイルシステム、メール受信トレイ |
| データフロー | 矢印 | コンポーネント間をデータが移動する経路。 | 注文詳細、ログイン資格情報、請求書 |
1. 外部エンティティ 🧑💼
終端とも呼ばれるこれらは、あなたのシステムとやり取りするが、その制御外にある人、組織、または他のシステムを表す。データフローの出発点または終着点となる。外部エンティティと内部プロセスの違いを明確に定義するために、システム境界を明確にすることが不可欠である。
2. プロセス ⚙️
プロセスは作業が行われるアクティブな要素である。データを入力し、変換して出力する。プロセスは常に少なくとも1つの入力と1つの出力を持つ必要がある。入力はあるが出力がない場合、それは「ブラックホール」である。出力はあるが入力がない場合、それは「ミラクル」である。両方とも論理上の誤りである。
3. データストア 🗃️
データストアは、情報が一時的に保管される受動的なリポジトリを表す。データを処理するのではなく、保持する。物理的なデータベース、紙のファイルボックス、クラウドのバケットなどである。DFDでは、データが保存のためにストアに入り、取得のために出力される。
4. データフロー ➡️
データフローは接続要素である。情報の移動を表す。すべてのフローは、何が移動しているかを示す名詞句(例:「支払い情報」)でラベル付けされなければならない。動詞(例:「支払いを送信」)ではいけない。フローは、プロセスまたはストアが間にない限り、システム境界を越えてはならない。
DFDのレベルについて説明 📈
DFDは階層的に構造化されている。これにより、システムを抽象化の段階に分けて複雑さを管理できる。
レベル0:コンテキスト図
コンテキスト図は最高レベルの視点である。システム全体を1つのプロセスバブルとして示す。すべての外部エンティティと、システムに入り出る主要なデータフローを特定する。この図は「システムは何かを実行するか?」という問いに答える。システム境界を明確に設定する。
レベル1:主要プロセス
レベル1では、コンテキスト図の単一プロセスを主要なサブプロセスに展開する。このレベルでは、システムの主要な機能領域が明らかになる。たとえば、「販売システム」は「注文処理」、「在庫管理」、「請求」に分解される。データストアもここで導入される。
レベル2:詳細プロセス
レベル2では、レベル1の特定のプロセスをより詳細に分析する。ここでは細かいステップをマッピングする。たとえば、レベル1の「請求」プロセスは「料金計算」、「割引適用」、「請求書作成」に分解される。このレベルはしばしば最も詳細になり、実装のガイドラインとして使用される。
表記スタイル 📐
DFDを描くために使用される主な表記スタイルは2つある。両方とも同じ論理情報を伝えるが、形状が異なる。
- YourdonとDeMarco表記:プロセスには円を使用し、データストアには開かれた長方形を使用する。このスタイルは古くからの手法に関連しているが、広く認識されている。
- GaneとSarson表記:プロセスには丸みを帯びた長方形を使用し、データストアには平行な水平線を使用する。このスタイルは、明確さのため、現代のシステム設計で好まれることが多い。
図を作成する際には一貫性が鍵となる。1つの表記スタイルを選択し、文書全体にわたってそれを守ることで、ステークホルダー間の混乱を避ける。
必須のルールと制約 ⚖️
データフローダイアグラムの整合性を確保するためには、特定のルールに従わなければなりません。これらのルールに違反すると、図は論理的に無効になります。
- データのバランス:すべてのプロセスには、少なくとも1つの入力フローと1つの出力フローが必要です。データは空から生成されたり、痕跡なく破壊されることはありません。
- エンティティからストアへの直接フローは禁止:外部エンティティからデータストアへデータが直接流れることはできません。まずプロセスを経由しなければなりません。これにより、データが保存される前に検証または変換されていることが保証されます。
- ストアからストアへの直接フローは禁止:データは1つのストアから別のストアへ直接移動することはできません。データの整合性を確保するために、プロセスが転送を仲介しなければなりません。
- 一貫した命名:データフローには一意で説明的な名前を付ける必要があります。同じデータが複数の場所を移動する場合、追跡可能性を保つために同じ名前を付けるべきです。
- 分解: プロセスを低レベルに分解する際には、入力と出力が親プロセスと一致している必要があります。これを「バランス」といいます。
避けるべき一般的な誤り ⚠️
経験豊富なアナリストですら、データフローのモデル化において誤りを犯すことがあります。一般的な誤りを認識することで、図の品質を維持できます。
1. ブラックホール
ブラックホールとは、データを受け取るが、出力がないプロセスを指します。これはデータが結果のないままシステム内に消えていることを意味します。有効なDFDでは、これを行うことは不可能です。プロセスに入力されるすべてのデータは、何らかの変化または出力に結びついていなければなりません。
2. グレイホール
グレイホールとは、入力データと出力データが論理的に一致しないプロセスを指します。たとえば、入力が「顧客名」であるのに、出力が「配送先住所」である場合、変換プロセスが欠落しています。出力を作成するために必要なデータは、すべて考慮しなければなりません。
3. フローの多さ
1つのプロセスに多すぎるデータフローを押し込むと、図が読みにくくなります。プロセスの入力または出力が7つ以上ある場合は、処理内容が多すぎると考えられ、より小さなサブプロセスに分解すべきです。
4. コントロールフローの混同
DFDはコントロールフロー、時間順序、ループを示しません。矢印を使って「ここから始める」や「次にこれを行う」を示してはいけません。すべての矢印はデータの移動を表します。論理やタイミングを示したい場合は、フローチャートを使用してください。
DFDとフローチャートの違い 🔄
データフローダイアグラムとフローチャートを混同することはよくあります。両者とも矢印や図形を使用しますが、目的は異なります。
| 特徴 | データフローダイアグラム(DFD) | フローチャート |
|---|---|---|
| 注目点 | データの移動と保存。 | コントロールフローと意思決定論理。 |
| プロセス | データを変換する。 | ステップまたは意思決定を実行する。 |
| 時間 | 順序を示さない。 | 処理の順序を示す。 |
| 意思決定ポイント | 使用されない。 | 頻繁に使用される(ダイヤモンド型)。 |
| 最適な用途 | システム分析と要件定義。 | アルゴリズム設計とプログラミング論理。 |
ステップバイステップの作成プロセス 🛠️
DFDを作成するには構造的なアプローチが必要です。堅牢なモデルを構築するには、以下のステップに従ってください。
- システム境界を特定する:システムの内部と外部にあるものを定義する。これにより、外部エンティティが決定される。
- コンテキスト図を描く:システムを中央の1つのプロセスとして配置する。外部エンティティすべてに矢印を引き、高レベルのデータ移動を示す。
- 主要プロセスを特定する:中心プロセスをレベル1プロセスに分解する。これらがシステムの主要機能である。
- データストアを追加する:プロセス間でデータを保存する必要がある場所を決定する。関連するプロセスに接続する。
- データフローを精査する:プロセス、ストア、エンティティの間で矢印を描く。すべてのラベルが明確な名詞であることを確認する。
- バランスの確認:レベル1プロセスの入力と出力がコンテキスト図と一致していることを確認する。
- さらに分解する:レベル1プロセスが複雑すぎる場合は、内部構造を詳細に示すためにレベル2図を作成する。
システムアーキテクチャへの利点 🏗️
DFDの導入は、システムアーキテクチャと開発チームに実質的な利点をもたらす。
- 明確さ: 視覚モデルは要件の曖昧さを軽減します。ステークホルダーは、自分が送信および受信しているデータが正確にどのようなものかを確認できます。
- スケーラビリティ: ハイエラルキカル図は、アーキテクトが詳細に煩わされることなく、システム設計をスケーリングできるようにします。
- 統合: DFDは、異なるサブシステムがどのように相互作用しているかを識別しやすくし、マイクロサービスや分散システムにおいて非常に重要です。
- セキュリティ: データフローをマッピングすることで、セキュリティチームは機密データがどこを通過するかを特定し、適切な場所で暗号化やアクセス制御を適用できます。
保守と反復 🔁
DFDは一度だけ作成するものではありません。システムは進化し、データ要件も変化します。図を最新の状態に保つことは非常に重要です。
- バージョン管理: 図をコードのように扱いましょう。バージョン管理を使って、変更を時間の経過とともに追跡しましょう。
- 変更管理: 新しい要件が追加されたら、すぐにDFDを更新して、新しいデータ経路を反映させましょう。
- レビューのサイクル: ステークホルダーとの定期的なレビューをスケジュールし、図がビジネスの現実と一致していることを確認しましょう。
- 廃止: プロセスが削除されたら、関連するすべてのデータフローも削除されていることを確認し、孤立したデータ参照を防ぎましょう。
明確性のためのベストプラクティス ✨
データフローダイアグラムが効果的であることを確実にするため、以下のガイドラインに従いましょう。
- 明確なラベルを使用する: プロセスには動詞と名詞を組み合わせて名前を付ける(例:「注文処理」)。データフローは名詞で名前を付ける(例:「注文詳細」)。
- 線の交差を避ける: 矢印の交差を最小限に抑えるように要素を配置しましょう。交差する場合は「ジャンプ」記号を使用するか、レイアウトを再調整しましょう。
- シンプルさを保つ: プロセスあたり最大7つの項目を目指しましょう。これを超える場合は、プロセスを分割してください。
- 一貫した方向性: 外部エンティティは左と右に、データストアは下または上に配置して、一貫性を持たせましょう。
- ユーザーとレビューする: 実際のシステム利用者に図を提示しましょう。技術アナリストが見落とす可能性のある、欠落しているデータフローを、彼らがしばしば発見します。
最終的な考慮事項 🔍
データフローダイアグラムは構造化分析の基盤のままです。技術的な実装の詳細に巻き込まれることなく、システム要件について中立的な方法で議論できるようにします。データの移動に注目することで、チームは設計段階の初期に非効率や論理的な穴を特定できます。
図は単なる文書化のためのツールではなく、思考のためのツールであることを思い出してください。フローを描くという行為は、以前はテキスト記述の中に隠れていた問題を明らかにすることがあります。アジャイル環境でも、従来のウォーターフォールモデルでも、データフローをマッピングするという規律が、堅牢で保守可能なシステムアーキテクチャを保証します。
ルールを遵守し、一般的な落とし穴を避け、システムの進化に伴って図を維持することで、ドキュメントがソフトウェアのライフサイクル全体を通じて信頼できる真実の源のままになることを保証できます。