











システム分析およびソフトウェア開発の複雑な状況において、明確さは極めて重要です。ステークホルダー、開発者、アナリストがシステム内の情報の流れを理解しようとする際、曖昧さは高コストな誤りを招くことがあります。このような状況で、データフローダイアグラム(DFD)が重要な役割を果たします。DFDは、システム内の情報の流れを構造的に表現する手段を提供し、論理的なプロセスと物理的な実装を分離します。
DFDは単なる図面ではなく、コミュニケーションツールです。チームがコードの詳細に囚われることなく、データの入力、変換、出力を可視化できるようにします。これらの流れをマッピングすることで、組織はボトルネックを特定し、データの整合性を確保し、ビジネス目標を技術的側面と一致させることができます。このガイドでは、現代の情報システムにおけるデータフローダイアグラムのメカニズム、構成要素、戦略的価値について探求します。
核心的な目的を理解する 🎯
データフローダイアグラムの主な機能は、何をシステムが行うことを、どのように行うか行うかを説明することです。この違いは要件収集段階において極めて重要です。コードスニペットやデータベーススキーマは実装を示す一方で、DFDは動作を示します。これはシステムの論理のためのブループリントとして機能します。
銀行アプリケーションを考えてみましょう。フローチャートはユーザーがクリックするボタンの順序を示すかもしれません。一方、DFDはユーザー口座から取引帳へと移動する資金に注目します。これはデータの変換を強調します。この抽象化により、アナリストは技術的知識のないステークホルダーと、混乱を招くことなくシステムの論理について議論できます。
可視化が重要な理由
- コミュニケーション:ビジネスニーズと技術的実行の間のギャップを埋めます。
- 分析:欠落しているデータポイントや冗長なプロセスを明らかにします。
- 文書化:将来の保守や更新のための参照資料として機能します。
- 検証:すべてのデータ入力が把握され、正しく処理されていることを確認するのに役立ちます。
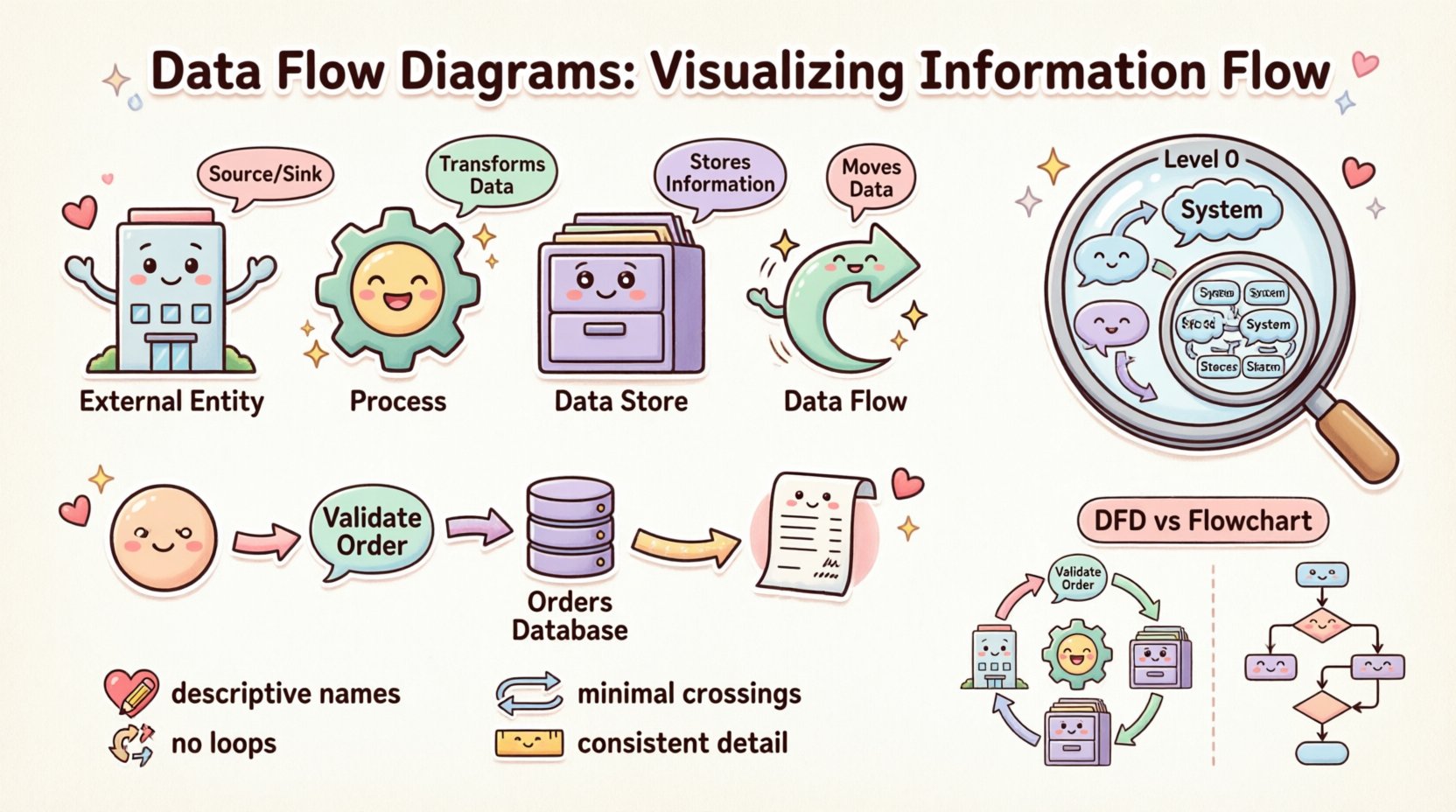
4つの必須構成要素 🧱
すべてのデータフローダイアグラムは、4つの基本的な構成要素から構成されます。正確な図を描くためには、これらの要素を理解することが前提です。各構成要素は、情報フローのエコシステムにおいて特定の役割を果たします。
1. 外部エントリ(情報の発生源と終着点) 🏢
外部エントリは、分析対象のシステムの境界外に存在する人、組織、または他のシステムを表します。これらはシステムに入力されるデータの発生源、またはデータが外部へ出る先として機能します。
- 用語:しばしば「ソース」「シンク」「アクター」とも呼ばれます。
- 機能:プロセスの開始を促すか、最終的な出力を受信します。
- 例:顧客、銀行、仕入先、または外部の決済ゲートウェイ。
2. プロセス(変換) ⚙️
プロセスは、入力データを出力データに変換する活動を表します。プロセスは図のアクティブな要素です。プロセスはデータの状態や形式を変更します。
- 用語:関数または変換とも呼ばれます。
- 機能:データを受け取り、それを変更して送出します。
- 例:「税金を計算する」、「ユーザーのログインを検証する」、または「請求書を生成する」。
3. データストア(記憶装置) 🗄️
データストアは、後で使用するために情報を保持する場所を表します。アクションを開始するのではなく、システム境界内にデータを保持します。これは物理的なデータベース、ファイル、あるいはレガシーな文脈では物理的なファイルボックスを指すこともあります。
- 用語:データベース、ファイル、リポジトリ、またはキュー。
- 機能:データの保存と取得。
- 例:「顧客データベース」、「注文履歴ログ」、または「在庫ファイル」。
4. データフロー(移動) 🔄
データフローは、エンティティ、プロセス、ストア間での情報の移動を示します。これらは図を統合する接続要素です。フローには、移動中の情報の内容を説明する名前が必要です。
- 用語:矢印、ストリーム、またはライン。
- 機能:ポイントAからポイントBへデータを輸送する。
- 方向:フローは方向性を持ちます。プロセスからストアに向かう矢印はデータの書き込みを示し、ストアからプロセスに向かう矢印はデータの読み込みを示します。
各要素の比較
明確さを確保するために、これらの要素を並べて比較すると役立ちます。この表は、図の構造において各要素が果たす異なる役割を概説しています。
| 要素 | 役割 | 記号の形状 | 回答される質問 |
|---|---|---|---|
| 外部エンティティ | ソース/シンク | 長方形 | システムとやり取りしているのは誰か、あるいは何か? |
| プロセス | 変換器 | 円または角が丸い長方形 | データに対してどのような作業が行われているか? |
| データストア | リポジトリ | 開かれた長方形 | データはどこに保管されているか? |
| データフロー | 輸送装置 | 矢印 | データはどのように移動するか? |
抽象度のレベル 📉
単一の図では、全体のシステムの複雑さをほとんど捉えることはできません。この複雑さを管理するために、DFDは異なる詳細度で作成されます。この手法は分解と呼ばれます。これにより、分析者はシステムアーキテクチャの詳細を拡大・縮小して確認できるようになります。
コンテキスト図(レベル0) 🌍
コンテキスト図は最も高いレベルの視点です。システム全体を単一のプロセスとして示します。システムの境界を定義し、システムとやり取りするすべての外部エンティティを特定します。この図は、「システムの全体的な目的は何か?」という問いに答えます。
- 範囲:1つの中心プロセス。
- 詳細:最小限。主な入力と出力のみが表示される。
- 目的:ステークホルダーに対してシステムの境界を定義する。
レベル1図(主要プロセス) 🔍
コンテキストが確立されると、中心プロセスが主要なサブプロセスに分解されます。このレベル1図では、システムがその主要な機能領域に分解されます。データがこれらの主要なコンポーネントと外部エンティティの間でどのように移動するかを示します。
- 範囲:3~7つの主要プロセス。
- 詳細: 高レベルの内部相互作用。
- 目的: 主要な機能モジュールを理解する。
レベル2図(詳細プロセス) 🔬
レベル2でさらに分解が行われます。レベル1の特定のプロセスが、より細かいステップに分解されます。ここが論理が具体的になる場所です。開発チームがコーディングの正確な要件を理解するためによく使用されます。
- 範囲:詳細なサブプロセス。
- 詳細:特定のデータ変換。
- 目的:実装と論理設計をガイドする。
バランスの概念 ⚖️
DFD作成における重要なルールがバランスです。親プロセスの入力と出力は、その子図(次のレベル)の入力と出力と一致しなければなりません。レベル1のプロセスが「注文データ」を受け取る場合、そのプロセスのレベル2での分解は、そのデータを単に消してはいけません。依然として「注文データ」を入力として受け入れなければなりません。
バランスルールを違反すると、システムモデルに一貫性の欠如が生じます。データが空から生成されているか、痕跡もなく消えているように見えるからです。バランスを保つことで、抽象化のすべてのレベルでシステムの論理的整合性が維持されます。
データフローダイアグラムとフローチャートの比較 🆚
データフローダイアグラムとフローチャートを混同することはよくある誤りです。見た目は似ていますが、目的や構造は大きく異なります。
- フローチャート: 注目する点:制御フロー。ステップ、決定、ループの順序を示します。次に何が起こるかを答えます。特定のアルゴリズムやユーザーインターフェースの相互作用の論理を説明するためによく使用されます。
- データフローダイアグラム: 注目する点:データフロー。情報の移動を示します。データはどこへ行くのかを答えます。ループや決定ポイントを明示的に示すことは通常ありません。代わりに変換を示します。
間違った図の種類を使うと、開発チームを混乱させます。ユーザーのログイン手順とエラー処理を文書化する必要がある場合は、フローチャートが適しています。ユーザーのデータがフォームからデータベースへどのように移動するかを文書化する必要がある場合は、DFDが適しています。
明確性のためのベストプラクティス ✨
DFDを作成することは、規律の練習です。既定の規則に従うことで、図が長期間にわたり読みやすく、有用な状態を保つことができます。
1. 名前付けのルール 📝
ラベルは明確でなければなりません。『プロセス1』や『データA』のような曖昧な用語を避けましょう。代わりに、『パスワードを検証する』のように動詞+名詞の組み合わせをプロセスに使用してください。データフローには、内容を説明する名詞を使用し、『配送先住所』や『支払い領収書』などとします。一貫した命名は、ユーザーが図を推測せずに navigating できるようにします。
2. データフローループの回避 🚫
データフローは、同じプロセスに直ちに戻ってはいけません。データが他のコンポーネントを経由してプロセスに戻ることは可能ですが、直接の自己ループは論理的な誤りやプロセスの境界の誤解を示すことが多いです。プロセスは入力を受け取り、変換し、出力するべきです。出力をそのまま自分自身に戻すと、無限の処理が行われていることを意味します。
3. 交差の最小化 🧵
ごちゃごちゃした図は無意味な図です。コンポーネントを配置して、データが自然に流れることを確保しましょう。通常、左から右、または上から下へと流れます。矢印の交差数を最小限に抑えてください。線が交差すると、特定のデータの経路を追跡するのが難しくなります。カーブや折れ線を使うことで、視覚的な流れを保ちましょう。
4. 一貫した粒度 📏
1つの図の中で、詳細のレベルは一貫しているべきです。高レベルのプロセスと低レベルのサブプロセスを混在させてはいけません。1つのプロセスが3つのステップに分解されているなら、その同じビュー内の他のすべての主要プロセスも、同じレベルの分解であるべきです。
一般的な落とし穴とその解決策 ⚠️
経験豊富なアナリストですら、図を構築する際に誤りに遭遇することがあります。これらの一般的な落とし穴を認識することで、レビュー段階での時間を節約できます。
ブラックホール
ブラックホールとは、プロセスに入力はあるが出力がない状態を指します。データがプロセスに入り、消えてしまうのです。これは、データストアが欠落しているか、外部エンティティへのフローが欠けていることを示すことが多いです。データを受け入れるすべてのプロセスは、何らかの結果を出力しなければなりません。
ミラクルプロセス
これはブラックホールの反対です。ミラクルプロセスは出力はあるが入力がない状態です。情報の消費なしにデータを生成します。これは物理的に不可能です。すべての出力は、何らかの入力データから導かれるべきです。
ゴーストデータ
ゴーストデータとは、示唆はされているが描かれていないデータフローを指します。プロセスが顧客IDを必要としているのに、そのIDをプロセスに導く矢印がない場合、論理は不完全です。すべてのデータ要件は明示的に接続されている必要があります。
外部エンティティの混同
アナリストは、内部コンポーネントを外部エンティティと混同することがあります。コンポーネントがシステム境界の一部であれば、それはプロセスまたはストアです。システム外にある場合はエンティティです。境界線を描くことで、この区別を明確にできます。
開発ライフサイクルへの統合 🛠️
データフローダイアグラムは静的な資産ではなく、プロジェクトと共に進化する動的な文書です。ソフトウェア開発ライフサイクルのさまざまな段階で役立ちます。
- 要件定義:DFDは、データがビジネスに入り出しする様子を可視化することで、ユーザーのニーズを捉えるのを助けます。すべての必要なデータポイントが特定されていることを検証します。
- システム設計:データベース設計をガイドします。DFD内のデータストアは、データベーススキーマ内のテーブルやコレクションに直接対応します。
- テスト:テストケースはデータフローから導出できます。図にフローが存在するなら、データの整合性を確保するためにテストされるべきです。
- 保守:変更が発生すると、DFDが更新されます。これは、新規メンバーがシステムを素早く理解するのに役立つ高レベルの概要を提供します。
視覚化の心理学 🧠
なぜ私たちはテキストではなく図に頼るのでしょうか?人間の脳は視覚情報をテキストよりもはるかに速く処理します。DFDは空間的推論を活用して複雑な論理を整理します。視覚的に、文章の段落では見逃されがちな関係性を把握できるようにします。
ステークホルダーが図を見ると、欠落している接続を即座に発見できます。矢印の隙間は、要件文書の隙間よりもはるかに目立ちます。この視覚的な即時性により、誤解のリスクが低下します。チーム間で共有された認知モデルが形成されます。
データ可視化の未来 🔮
システムがより分散化され、クラウドネイティブ化するにつれ、DFDの役割は依然として重要です。現代のシステムにはマイクロサービス、API、サードパーティ統合が含まれます。これらは本質的に外部エンティティとデータフローです。
自動化されたドキュメント作成ツールが、コードリポジトリからDFDを生成し始めています。これらのツールは一貫性を保つのに役立ちますが、フローの論理的な正しさを確認するために、依然として手動でのレビューが必要です。分解とバランスの原則は、テクノロジーのスタックに関係なく、常に一定です。
戦略的価値の要約 💡
データフローダイアグラムは、情報システムを理解するための構造化されたアプローチを提供します。複雑さを扱いやすいコンポーネントに分解します。技術者と非技術者との間のコミュニケーションを促進します。データベース設計やプロセス最適化の基盤となります。
バランス、明確な命名、適切な抽象化の原則に従うことで、アナリストは時代を超えて通用する図を構築できます。新しいアプリケーションの構築か、既存のシステムの監査かに関わらず、DFDは情報の流れを可視化する基本的なツールのままです。抽象的な論理を具体的な地図に変換し、開発をガイドするとともに、ビジネス目標との整合性を確保します。
次にシステム分析のタスクに取り組む際は、明確さが目的であることを思い出してください。DFDを使ってデータの旅路をマッピングしましょう。すべての情報が、出所、宛先、経路を持っていることを確認してください。この規律が、より強固なシステムと誤解の少ない状態をもたらします。