











In der komplexen Landschaft der Systemanalyse und Softwareentwicklung ist Klarheit entscheidend. Wenn Stakeholder, Entwickler und Analysten versuchen, zu verstehen, wie Informationen durch ein System fließen, kann Unklarheit zu kostspieligen Fehlern führen. Hier kommt das Datenflussdiagramm (DFD) als entscheidendes Instrument ins Spiel. Es bietet eine strukturierte Möglichkeit, den Informationsfluss innerhalb eines Systems darzustellen, wobei logische Prozesse von der physischen Implementierung getrennt werden.
Ein DFD ist nicht bloß eine Zeichnung; es ist ein Kommunikationsinstrument. Es ermöglicht Teams, Daten-Eingaben, Transformationen und Ausgaben zu visualisieren, ohne sich in Code-Spezifika zu verlieren. Durch die Abbildung dieser Flüsse können Organisationen Engpässe identifizieren, die Datenintegrität gewährleisten und geschäftliche Ziele mit technischen Fähigkeiten abstimmen. Dieser Leitfaden untersucht die Mechanik, Komponenten und strategischen Vorteile von Datenflussdiagrammen in modernen Informationssystemen.
Das Kernziel verstehen 🎯
Die primäre Funktion eines Datenflussdiagramms besteht darin, zu beschreibenwasein System tut, anstattwiees tut. Diese Unterscheidung ist während der Anforderungserhebung entscheidend. Während ein Code-Ausschnitt oder eine Datenbank-Schema die Implementierung zeigen, zeigt ein DFD das Verhalten. Es dient als Bauplan für die Logik des Systems.
Betrachten Sie eine Bankanwendung. Ein Flussdiagramm könnte die Reihenfolge der Tasten zeigen, die ein Benutzer drückt. Ein DFD hingegen konzentriert sich auf das Geld, das vom Benutzerkonto zum Transaktionsbuch fließt. Es hebt die Transformation von Daten hervor. Diese Abstraktion ermöglicht es Analysten, die Logik des Systems mit nicht-technischen Stakeholdern zu besprechen, ohne Verwirrung zu erzeugen.
Warum Visualisierung wichtig ist
- Kommunikation: Es schließt die Lücke zwischen geschäftlichen Anforderungen und technischer Umsetzung.
- Analyse: Es offenbart fehlende Datenpunkte oder überflüssige Prozesse.
- Dokumentation: Es dient als Referenz für zukünftige Wartung und Aktualisierungen.
- Validierung: Es hilft dabei, sicherzustellen, dass alle Daten-Eingaben berücksichtigt und korrekt verarbeitet werden.
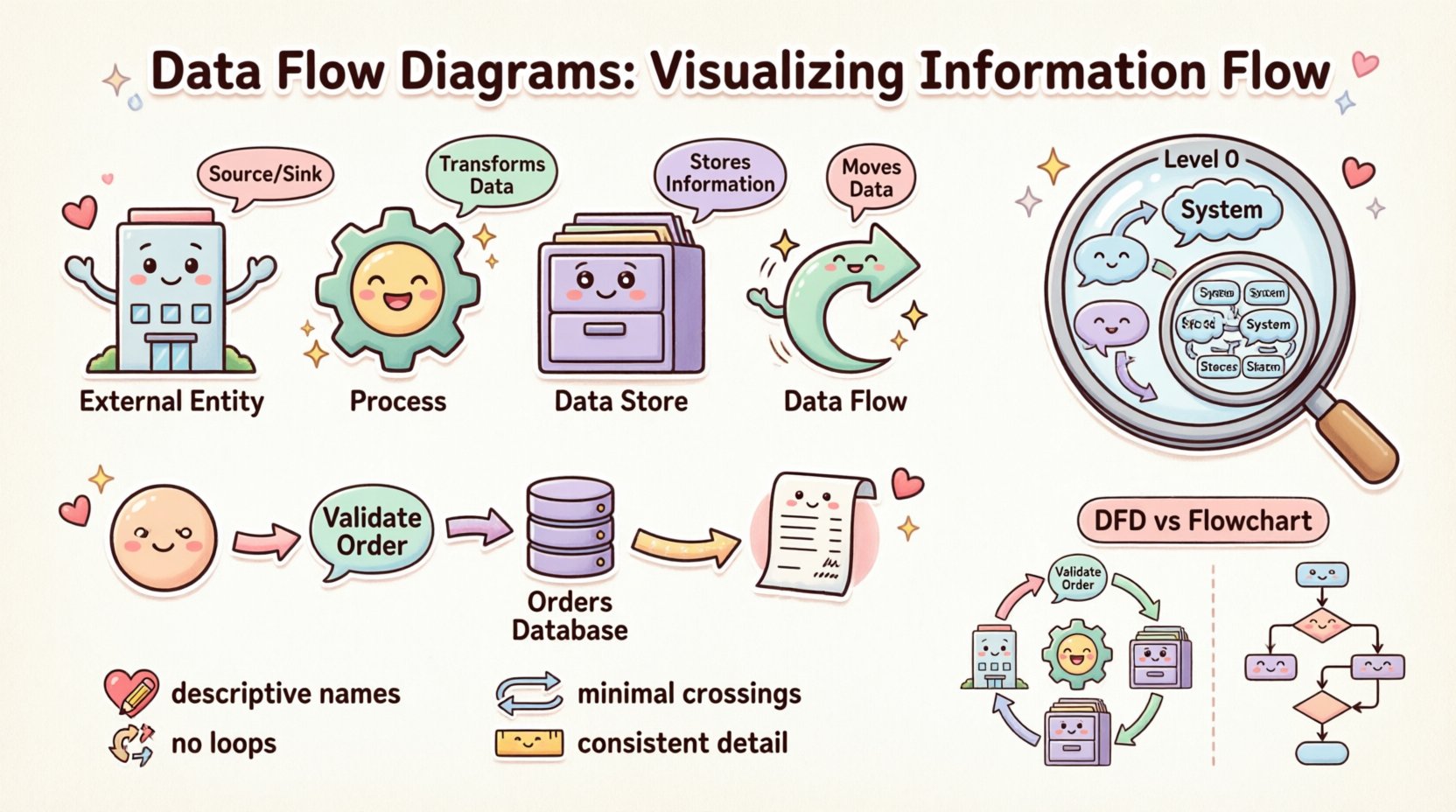
Die vier wesentlichen Komponenten 🧱
Jedes Datenflussdiagramm besteht aus vier grundlegenden Bausteinen. Das Verständnis dieser Elemente ist Voraussetzung für die Erstellung genauer Diagramme. Jeder Baustein hat eine spezifische Rolle im Ökosystem des Informationsflusses.
1. Externe Entitäten (die Quelle und Senke) 🏢
Externe Entitäten stellen Personen, Organisationen oder andere Systeme dar, die außerhalb der Grenze des analysierten Systems liegen. Sie fungieren als Quelle für Daten, die in das System eintreten, oder als Ziel, an das Daten verlassen.
- Begrifflichkeit: Häufig als Quellen, Senken oder Akteure bezeichnet.
- Funktion: Sie initiieren einen Prozess oder empfangen die endgültige Ausgabe.
- Beispiel: Ein Kunde, eine Bank, ein Lieferant oder ein externer Zahlungsgateway.
2. Prozesse (die Transformation) ⚙️
Prozesse stellen Aktivitäten dar, die Eingabedaten in Ausgabedaten umwandeln. Sie sind die aktiven Elemente des Diagramms. Ein Prozess verändert den Zustand oder die Form der Daten.
- Begrifflichkeiten: Auch bekannt als Funktionen oder Transformationen.
- Funktion: Es nimmt Daten entgegen, modifiziert sie und sendet sie weiter.
- Beispiel: „Steuern berechnen“, „Benutzeranmeldung überprüfen“ oder „Rechnung generieren.“
3. Datenbanken (Der Speicher) 🗄️
Datenbanken stellen Orte dar, an denen Informationen für spätere Verwendung gespeichert werden. Sie initiieren keine Aktionen, sondern halten Daten innerhalb der Systemgrenzen. Dies könnte eine physische Datenbank, eine Datei oder sogar ein physischer Aktenordner in veralteten Kontexten sein.
- Begrifflichkeiten: Datenbanken, Dateien, Repositories oder Warteschlangen.
- Funktion: Speicherung und Abruf von Daten.
- Beispiel: „Kunden-Datenbank“, „Bestellverlauf-Protokoll“ oder „Lagerverzeichnis.“
4. Datenflüsse (Die Bewegung) 🔄
Datenflüsse zeigen die Bewegung von Informationen zwischen Entitäten, Prozessen und Speichern an. Sie sind die Verbindungen, die das Diagramm zusammenhalten. Ein Fluss muss einen Namen haben, der die übertragenen Informationen beschreibt.
- Begrifflichkeiten: Pfeile, Ströme oder Linien.
- Funktion: Übertragung von Daten von Punkt A nach Punkt B.
- Richtung: Der Fluss ist gerichtet. Ein Pfeil, der von einem Prozess zu einem Speicher zeigt, bedeutet Daten schreiben; ein Pfeil, der von einem Speicher zu einem Prozess zeigt, bedeutet Daten lesen.
Vergleich der Komponenten
Um Klarheit zu gewährleisten, ist es hilfreich, diese Komponenten nebeneinander zu vergleichen. Diese Tabelle zeigt die unterschiedlichen Rollen jeder Komponente im Diagrammaufbau auf.
| Komponente | Rolle | Notationsform | Beantwortete Frage |
|---|---|---|---|
| Externe Entität | Quelle/Senke | Rechteck | Wer oder was interagiert mit dem System? |
| Prozess | Transformator | Kreis oder abgerundetes Rechteck | Welche Arbeit wird an den Daten durchgeführt? |
| Datenbank | Repository | Offenes Rechteck | Wo werden Daten gespeichert? |
| Datenfluss | Transporteur | Pfeil | Wie bewegt sich die Daten? |
Abstraktionsstufen 📉
Ein einzelnes Diagramm erfasst selten die Komplexität eines gesamten Systems. Um diese Komplexität zu verwalten, werden DFDs auf verschiedenen Detailstufen erstellt. Diese Technik wird als Zerlegung bezeichnet. Sie ermöglicht es Analysten, in die Systemarchitektur hinein- und herauszumischen.
Kontextdiagramm (Ebene 0) 🌍
Das Kontextdiagramm ist die höchste Abstraktionsstufe. Es zeigt das gesamte System als einen einzigen Prozess. Es definiert die Grenzen des Systems und identifiziert alle externen Entitäten, die mit ihm interagieren. Dieses Diagramm beantwortet die Frage: „Was ist der Gesamtzweck des Systems?“
- Umfang: Ein zentraler Prozess.
- Detail: Minimal. Es werden nur die wichtigsten Eingaben und Ausgaben angezeigt.
- Ziel: Definieren der Systemgrenzen für die Stakeholder.
Ebene-1-Diagramm (Hauptprozesse) 🔍
Sobald der Kontext festgelegt ist, wird der zentrale Prozess in Hauptunterprozesse zerlegt. Dieses Ebene-1-Diagramm zerlegt das System in seine primären Funktionsbereiche. Es zeigt, wie Daten zwischen diesen Hauptkomponenten und externen Entitäten fließen.
- Umfang: 3 bis 7 Hauptprozesse.
- Detail: Hochrangige interne Wechselwirkungen.
- Ziel:Verstehen der wichtigsten funktionalen Module.
Ebene-2-Diagramm (detaillierte Prozesse) 🔬
Weitere Zerlegung erfolgt auf Ebene 2. Spezifische Prozesse aus Ebene 1 werden in feinere Schritte aufgeteilt. Hier wird die Logik konkret. Es wird häufig von Entwicklerteams genutzt, um die genauen Anforderungen für die Programmierung zu verstehen.
- Umfang:Detaillierte Unterprozesse.
- Detail:Spezifische Datenumwandlungen.
- Ziel:Leiten der Implementierung und der Logikgestaltung.
Das Konzept der Abstimmung ⚖️
Eine entscheidende Regel bei der Erstellung von DFDs ist die Abstimmung. Die Eingaben und Ausgaben eines übergeordneten Prozesses müssen mit den Eingaben und Ausgaben seines Kinddiagramms (der nächsten Ebene darunter) übereinstimmen. Wenn ein Prozess der Ebene 1 „Bestelldaten“ erhält, darf der Prozess der Ebene 2 diese Daten nicht einfach verschwinden lassen; er muss „Bestelldaten“ weiterhin als Eingabe akzeptieren.
Die Verletzung der Abstimmungsregeln führt zu Inkonsistenzen im Systemmodell. Es suggeriert, dass Daten aus dem Nichts entstehen oder spurlos verschwinden. Die Einhaltung der Abstimmung stellt sicher, dass die logische Integrität des Systems über alle Abstraktionsstufen hinweg erhalten bleibt.
Datenflussdiagramme im Vergleich zu Ablaufdiagrammen 🆚
Es ist ein häufiger Fehler, Datenflussdiagramme mit Ablaufdiagrammen zu verwechseln. Obwohl sie eine visuelle Ähnlichkeit aufweisen, unterscheiden sich ihr Zweck und ihre Struktur erheblich.
- Ablaufdiagramme: Fokus auf Steuerfluss. Sie zeigen die Reihenfolge von Schritten, Entscheidungen und Schleifen. Sie beantworten die Frage „Was geschieht als Nächstes?“ Sie werden häufig verwendet, um die Logik eines bestimmten Algorithmus oder einer Benutzeroberflächeninteraktion zu beschreiben.
- Datenflussdiagramme: Fokus auf Datenfluss. Sie zeigen die Bewegung von Informationen. Sie beantworten die Frage „Wohin geht die Daten?“ Sie zeigen typischerweise Schleifen oder Entscheidungspunkte nicht explizit; sie zeigen Transformationen.
Die Verwendung des falschen Diagrammtyps kann die Entwicklerteams verwirren. Wenn Sie eine Benutzeranmeldefolge mit Fehlerbehandlung dokumentieren müssen, ist ein Ablaufdiagramm besser geeignet. Wenn Sie dokumentieren müssen, wie Benutzerdaten vom Formular zur Datenbank gelangen, ist ein DFD angemessen.
Best Practices für Klarheit ✨
Die Erstellung eines DFD ist eine Übung in Disziplin. Die Einhaltung etablierter Konventionen stellt sicher, dass das Diagramm über die Zeit hinweg lesbar und nützlich bleibt.
1. Namenskonventionen 📝
Beschriftungen müssen beschreibend sein. Vermeiden Sie vage Begriffe wie „Prozess 1“ oder „Daten A“. Verwenden Sie stattdessen Verb-Nomen-Kombinationen für Prozesse, wie beispielsweise „Passwort überprüfen“. Bei Datenflüssen verwenden Sie Substantive, die den Inhalt beschreiben, wie beispielsweise „Versandadresse“ oder „Zahlungsbestätigung“. Konsistente Benennung hilft den Benutzern, sich im Diagramm ohne Vermutungen zurechtzufinden.
2. Vermeidung von Datenfluss-Schleifen 🚫
Ein Datenfluss sollte nicht sofort zurück zum selben Prozess führen. Obwohl Daten nach dem Durchlaufen anderer Komponenten zu einem Prozess zurückkehren können, deuten direkte Selbstschleifen oft auf einen logischen Fehler oder ein Missverständnis der Prozessgrenze hin. Ein Prozess sollte Eingaben nehmen, sie verarbeiten und Ausgaben erzeugen. Wenn er direkt wieder auf sich selbst ausgibt, bedeutet dies eine unendliche Verarbeitung.
3. Minimierung von Kreuzungen 🧵
Ein unübersichtliches Diagramm ist ein nutzloses Diagramm. Ordnen Sie die Komponenten so an, dass die Datenflüsse natürlich verlaufen, typischerweise von links nach rechts oder von oben nach unten. Minimieren Sie die Anzahl der Pfeilkreuzungen. Wenn Linien sich kreuzen, wird es schwierig, den Weg bestimmter Daten nachzuverfolgen. Verwenden Sie Kurven oder Unterbrechungen, um den visuellen Fluss aufrechtzuerhalten.
4. Konsistente Granularität 📏
Innerhalb eines einzelnen Diagramms sollte das Detailniveau konsistent sein. Mischen Sie keine Hoch-Level-Prozesse mit Niedrig-Level-Unterprozessen. Wenn ein Prozess in drei Schritte aufgeteilt ist, sollten alle anderen Hauptprozesse in dieser Ansicht auf demselben Dekompositionsgrad liegen.
Häufige Fallen und Lösungen ⚠️
Sogar erfahrene Analysten begehen Fehler beim Erstellen von Diagrammen. Die Erkennung dieser häufigen Fallen kann Zeit im Überprüfungsprozess sparen.
Das Schwarze Loch
Ein Schwarzes Loch entsteht, wenn ein Prozess Eingaben hat, aber keine Ausgaben. Daten betreten den Prozess und verschwinden. Dies deutet meist auf einen fehlenden Datenspeicher oder einen fehlenden Fluss zu einer externen Entität hin. Jeder Prozess, der Daten akzeptiert, muss ein Ergebnis erzeugen.
Der Wunderprozess
Dies ist das Gegenteil eines Schwarzen Lochs. Ein Wunderprozess hat Ausgaben, aber keine Eingaben. Er erzeugt Daten, ohne Informationen zu verbrauchen. Dies ist physikalisch unmöglich. Jede Ausgabe muss aus bestimmten Eingabedaten abgeleitet werden.
Geisterdaten
Geisterdaten beziehen sich auf Datenflüsse, die angenommen, aber nicht gezeichnet sind. Wenn ein Prozess eine Kunden-ID benötigt, aber kein Pfeil die ID in den Prozess bringt, ist die Logik unvollständig. Jede Datenanforderung muss explizit verbunden sein.
Verwirrung um externe Entitäten
Analysten verwechseln manchmal interne Komponenten mit externen Entitäten. Wenn eine Komponente Teil der Systemgrenze ist, handelt es sich um einen Prozess oder einen Speicher. Wenn sie außerhalb des Systems liegt, ist sie eine Entität. Eine Grenzlinie hilft, diese Unterscheidung klar zu machen.
Integration in den Entwicklungslebenszyklus 🛠️
Datenflussdiagramme sind keine statischen Artefakte; sie sind lebendige Dokumente, die sich mit dem Projekt entwickeln. Sie spielen in verschiedenen Phasen des Softwareentwicklungslebenszyklus eine Rolle.
- Anforderungserhebung: DFDs helfen dabei, Benutzerbedürfnisse zu erfassen, indem sie visualisieren, wie Daten in das Unternehmen eintreten und es verlassen. Sie bestätigen, dass alle erforderlichen Datenpunkte identifiziert wurden.
- Systemdesign: Sie leiten das Datenbankdesign. Die Datenspeicher im DFD werden direkt in Tabellen oder Sammlungen im Datenbankschema übersetzt.
- Testen: Testfälle können aus den Datenflüssen abgeleitet werden. Wenn ein Fluss im Diagramm existiert, muss er getestet werden, um die Datenintegrität zu gewährleisten.
- Wartung: Bei Änderungen wird das DFD aktualisiert. Es bietet einen Überblick auf hoher Ebene, der neuen Teammitgliedern hilft, das System schnell zu verstehen.
Die Psychologie der Visualisierung 🧠
Warum verlassen wir uns auf Diagramme statt auf Text? Der menschliche Geist verarbeitet visuelle Informationen deutlich schneller als Text. Ein DFD nutzt räumliches Denken, um komplexe Logik zu strukturieren. Er ermöglicht es dem Betrachter, Beziehungen zu erkennen, die in einem Absatz Text verloren gehen könnten.
Wenn Stakeholder das Diagramm sehen, können sie fehlende Verbindungen sofort erkennen. Eine Lücke in den Pfeilen ist deutlicher sichtbar als eine Lücke in einem Anforderungsdokument. Diese visuelle Unmittelbarkeit verringert das Risiko von Missverständnissen. Sie schafft ein gemeinsames mentales Modell innerhalb des Teams.
Zukunft der Datenvisualisierung 🔮
Da Systeme zunehmend verteilte und cloud-native Strukturen aufweisen, bleibt die Bedeutung des DFD relevant. Moderne Systeme beinhalten Mikrodienste, APIs und Drittanbieter-Integrationen. Diese sind im Wesentlichen externe Entitäten und Datenflüsse.
Automatisierte Dokumentationstools beginnen, DFDs aus Code-Repositories zu generieren. Obwohl diese Tools nützlich sind, um Konsistenz zu gewährleisten, ist dennoch eine manuelle Überprüfung notwendig, um die logische Richtigkeit des Flusses zu gewährleisten. Die grundlegenden Prinzipien der Zerlegung und des Ausgleichs bleiben unabhängig von der Technologie-Stack-Struktur konstant.
Zusammenfassung des strategischen Wertes 💡
Datenumflussdiagramme bieten einen strukturierten Ansatz zur Verständnis von Informationssystemen. Sie zerlegen Komplexität in handhabbare Komponenten. Sie erleichtern die Kommunikation zwischen technischen und nicht-technischen Teams. Sie dienen als Grundlage für die Datenbankgestaltung und die Prozessoptimierung.
Durch Einhaltung der Prinzipien des Ausgleichs, klarer Benennung und angemessener Abstraktion können Analysten Diagramme erstellen, die der Zeit standhalten. Ob man eine neue Anwendung entwickelt oder eine bestehende überprüft, das DFD bleibt ein grundlegendes Werkzeug zur Visualisierung des Informationsflusses. Es wandelt abstrakte Logik in eine konkrete Karte um, die die Entwicklung leitet und die Ausrichtung an den Geschäftszielen sicherstellt.
Wenn Sie sich beim nächsten Mal einer Systemanalyse-Aufgabe nähern, denken Sie daran, dass Klarheit das Ziel ist. Verwenden Sie das DFD, um die Reise Ihrer Daten zu kartieren. Stellen Sie sicher, dass jedes Stück Information eine Quelle, ein Ziel und einen Weg hat. Diese Disziplin führt zu robusteren Systemen und weniger Missverständnissen.