











情報システムのアーキテクチャにおいて、明確さが価値である。システム分析およびデータベース設計の分野を支配する2つの基盤的なツールが存在する:データフローダイアグラム(DFD)とエンティティ関係図(ERD)。両者とも複雑なシステムを可視化する目的を持つが、根本的に異なる抽象化のレベルで動作する。一方は移動と変換に注目し、他方は構造と保存に注目する。これらを混同すると、アーキテクチャ上の失敗やデータの不整合、プロセスのボトルネックが生じる。このガイドでは、これらのモデリング技法のメカニズム、応用、および違いについて詳しく解説する。
データフローダイアグラムの理解 🔄
データフローダイアグラムは、システム内を流れている情報の流れをマッピングするものである。これはプロセス指向のモデルである。ここでの主な関心は、データがどこに存在するかではなく、どのように移動し、変化し、相互に作用するかにある。この図は、ビジネスプロセスやソフトウェアアプリケーションの論理を理解するために不可欠である。
DFDの核心的な構成要素
有効なDFDを構築するには、システム要素を表すために使用される4つの標準的な記号を理解する必要がある:
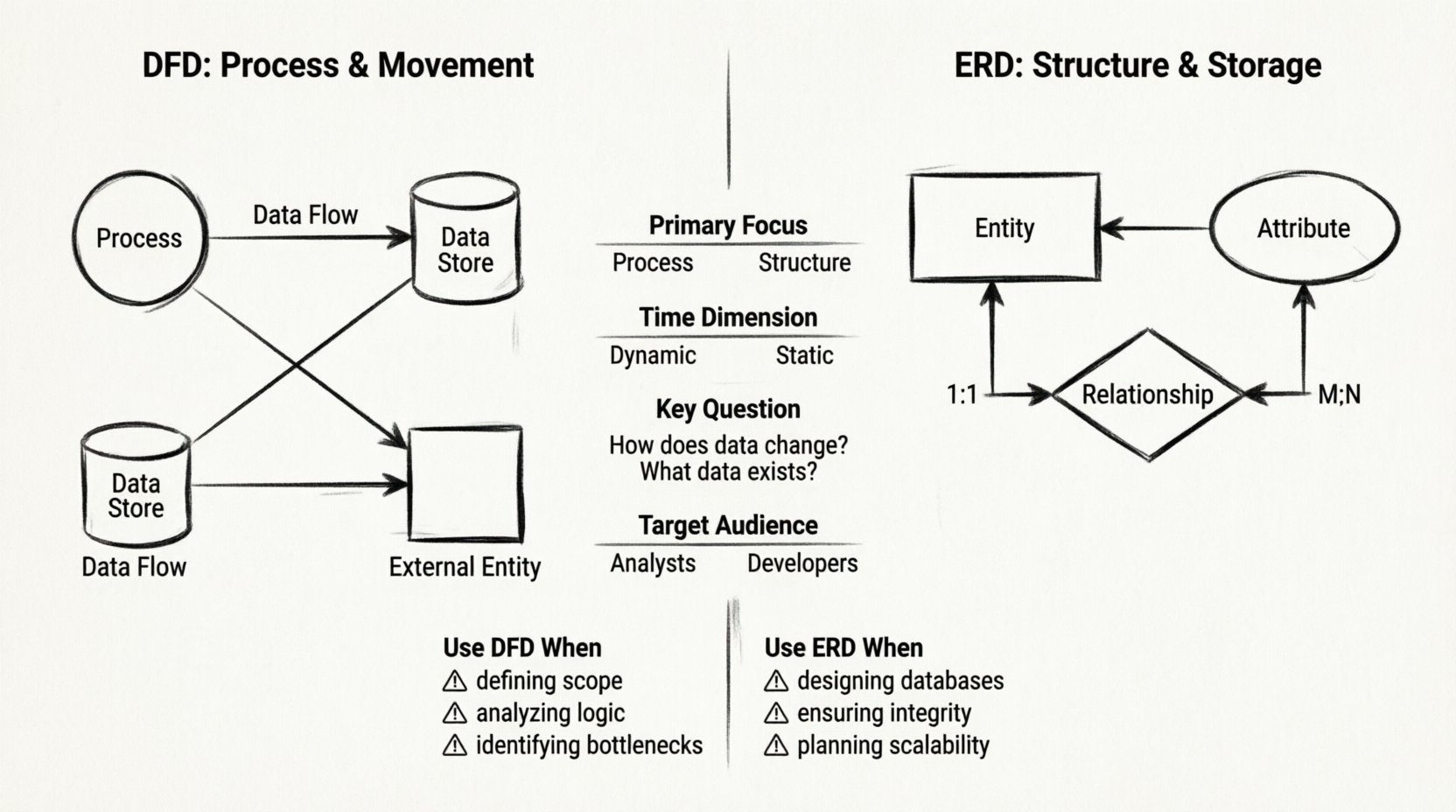
- プロセス:円または丸みを帯びた長方形で表される。プロセスは入力データを出力データに変換する。情報は保存しないが、それを処理する。例として「税金計算」や「ログイン検証」がある。
- データストア:開口部のある長方形または平行線で表される。これはデータが静止状態で保持される場所を示す。システムの記憶装置であり、ファイルやデータベーステーブル、物理的なアーカイブなどが含まれる。
- 外部エンティティ:四角で表される。これらはシステム境界外のデータの発生源または到着先である。ユーザー、他のシステム、ハードウェアデバイスなどが含まれる。データを発信または受信するが、内部で処理は行わない。
- データフロー:矢印で表される。これらはプロセス、ストア、エンティティ間のデータ移動の方向を示す。各フローには、内容を説明する明確な名前が必要であり、たとえば「請求書」や「ユーザー要求」などが含まれる。
DFDの詳細レベル
DFDは階層的である。単一のビューで描かれるのは稀である。代わりに、詳細のレベルに分解される:
- コンテキスト図(レベル0):最も高いレベルの視点。システム全体を外部エンティティと相互作用する単一のプロセスとして示す。境界を定義する。
- レベル1図:主プロセスを主要なサブプロセスに分解する。最初の段階のデータストアとフローを導入する。
- レベル2以降:特定のサブプロセスを細かいアクションにさらに分解する。このレベルは詳細な仕様定義に使用される。
エンティティ関係図の理解 🗃️
エンティティ関係図は、データの静的構造に注目する。これは主にデータベース設計段階で使用される概念モデルである。目的はデータの整合性を確保し、冗長性を最小限に抑え、異なる情報の間の関係を定義することである。
ERDの核心的な構成要素
ERDは、データエンティティが互いにどのように関係するかを定義するために特定の記法に依存している:
- エンティティ:長方形で表される。エンティティとは、データが格納される対象となる現実世界の物体または概念である。例として「顧客」、「製品」、「注文」などがある。
- 属性:楕円で表されるか、エンティティの長方形内に記載される。これらはエンティティの性質を説明する。たとえば「顧客」エンティティの場合、属性には「名前」、「住所」、「電話番号」などが含まれる。
- 関係:ダイヤモンドまたはエンティティを結ぶ線で表されます。これはエンティティ間の相互作用を定義します。たとえば、顧客が注文を「作成する」という関係です。
- 基数:関係の数を定義します。1対1ですか?1対多ですか?多対多ですか?これによりデータベースの構造的制約が決まります。
ERD設計における正規化
DFDは通常、正規化を扱いませんが、ERDはこれと深く結びついています。設計プロセスでは、重複を減らすためにデータを整理します。ERDは第一正規形、第二正規形など、各正規化規則を反映しなければなりません。これにより、結果として得られるデータベースが効率的でスケーラブルになることを保証します。データ構造を正規化しないと、1つの情報の変更が複数の場所で編集を必要とする更新異常が発生する傾向があります。
構造的比較:DFD対ERD 📊
違いを明確にするために、両モデルを複数の次元で比較します。この表は、プロセスフローとデータ構造の間の機能的違いを強調しています。
| 機能 | データフローダイアグラム(DFD) | エンティティ関係図(ERD) |
|---|---|---|
| 主な焦点 | プロセスと移動 | 構造と保存 |
| 時間次元 | 動的(イベントの順序) | 静的(データのスナップショット) |
| 核心的な質問 | データはどのように変化するか? | どのようなデータが存在するか? |
| 対象読者 | ビジネスアナリスト、ユーザー | データベース管理者、開発者 |
| 保存の取り扱い | 一般的なデータストア | 特定のテーブルとキー |
| 論理の表現 | 変換と論理 | 制約とルール |
各図の展開時期 📅
適切なツールを選ぶことは、プロジェクトライフサイクルの段階に依存します。ステークホルダーにビジネスプロセスを説明するためにERDを使用すると、混乱を招きます。開発者にテーブルの関係を説明するためにDFDを使用すると、イライラさせてしまいます。以下に、最適な使用シナリオの概要を示します。
以下の場合にはDFDを使用してください:
- システム範囲の定義: システム内部と外部の違いを示す必要がある場合。
- ビジネスロジックの分析: リクエストがユーザー入力から保存されたレコードへとどのように移動するかを追跡する必要がある場合。
- ボトルネックの特定: データが蓄積される場所やプロセスが停止する場所を把握する必要がある場合。
- ステークホルダーとのコミュニケーション: 非技術者ユーザーは、フローの理解の方がテーブルよりも得意です。
以下の場合にはERDを使用してください:
- データベースの設計: 物理的または論理的なストレージレイヤーを構築している場合。
- データ整合性の確保: 主キー、外部キー、制約を定義する必要がある場合。
- スケーラビリティの計画: データモデルが冗長性を伴わずに将来の成長をサポートすることを確実にする必要がある場合。
- APIドキュメント作成: 外部利用者に公開されるスキーマを定義する必要がある場合。
スクラッチからデータフローダイアグラムを構築する 🛠️
信頼性の高いDFDを作成するには、体系的なアプローチが必要です。正確さを目的とするならば、このプロセスには裏技はありません。信頼できるモデルを構築するには、以下のステップに従ってください。
ステップ1:境界を特定する
まず、システムの境界を定義してください。範囲内にあるものは何ですか?外部にあるものは何ですか?システムを囲むボックスを描いてください。ボックス内のすべてがシステムの一部であり、ボックス外のすべてが外部エンティティです。
ステップ2:外部エンティティをマッピングする
プロジェクトとやり取りするすべての人、部門、またはシステムをリストアップしてください。境界の外にそれらを描画し、明確にラベルを付けます。
ステップ3:主要プロセスを定義する
システムの主な機能を特定してください。これらが図の円になります。たとえば、図書館システムを構築する場合、プロセスには「本の貸出」と「本の返却」などが含まれます。
ステップ4:データフローで接続する
エンティティとプロセス、プロセスとデータストアを矢印でつなぎます。すべての矢印にラベルを付けることを確認してください。名前のないデータフローは意味がありません。データがエンティティから別のエンティティへ直接流れることのないように、プロセスを経由させるようにしてください。
ステップ5:保存の確認
データ保存の確認を行う。プロセスがデータを出力する場合、そのデータはどこかから来ている必要がある。プロセスが入力を受ける場合、そのデータはどこかに送られる必要がある。データが突然消えたり、突然現れたりしてはならない。
スクラッチからエンティティ関係図を作成する 🏗️
ERDは関係性とキーに関して正確さが求められる。構造がアプリケーションのパフォーマンスと信頼性を決定する。
ステップ1:エンティティを特定する
要件を読み、名詞を探す。これらは潜在的なエンティティである。曖昧な名詞は除外する。価値のある明確な対象を表すものだけを残す。たとえば、病院システムでは「患者」と「医師」はエンティティである。「治療」は複雑さによってエンティティか関係性かが変わる。
ステップ2:属性を定義する
各エンティティの具体的な詳細をリストアップする。どの属性が一意の識別子(主キー)であるかを決定する。「患者」エンティティの場合、「患者ID」がキーとなる。「名前」は属性である。属性が原子的であることを確認する。都市ごとに検索する必要がある場合、「住所」を1つのフィールドに保存してはならない。
ステップ3:関係性を確立する
エンティティがどのようにつながるかを決定する。患者は医師によって治療される。これは関係性である。基数を決定する。1人の医師が多くの患者を治療するか?はい。多対多か?はい。1人の患者が複数の医師を持つか?はい。
ステップ4:多対多の解決
データベースは多対多の関係をネイティブに保存できない。学生が複数の授業を受講でき、授業に複数の学生がいる場合、関連エンティティ(しばしば結合テーブルと呼ばれる)を作成しなければならない。これにより、関係が2つの1対多の関係に分解される。
ステップ5:正規形の確認
正規化ルールを適用する。非キー属性が主キーのみに依存していることを確認する。属性がキーの一部に依存する場合、それを新しいエンティティに移動する。このステップでデータの不整合を防ぐ。
避けるべき一般的な落とし穴 ⚠️
経験豊富なアーキテクトですらモデル化の際にミスを犯す。一般的な誤りに気づくことで、設計の整合性を保つことができる。
DFDの落とし穴
- エンティティ間のデータフロー:データは常にプロセスを経由しなければならない。外部エンティティの間に直接の線が引かれていると、システムの制御が不十分であることを示唆する。
- ブラックホール:入力はあるが、出力がないプロセス。これは機能するシステムでは論理的に不可能である。
- グレイホール:入力はあるが、まったく出力がないプロセス、または入力要件と一致しない出力を持つプロセス。
- ラベルのないフロー:名前が付いていない矢印は、転送中のコンテンツについて何の情報も提供しない。
ERDの落とし穴
- 基数の欠落:関係が1対1か1対多かを定義しないと、コード実装において曖昧さが生じる。
- 重複するエンティティ:他のエンティティと本質的に重複するエンティティを作成することで、データの不整合が生じる。
- NULLの無視: 属性が空になれるかどうかを判断できなかった場合、データベースの制約やアプリケーションロジックに影響します。
- 過剰な正規化: データをあまりにも多くのテーブルに分割すると、クエリが遅くなり、複雑になります。バランスが重要です。
システムアーキテクチャにおける両方の統合 🏗️
DFDとERDは別々のものですが、互いに排他的ではありません。成熟したシステム設計では、両者を併用します。DFDはデータの流れを説明し、ERDはデータの到着地点と保存方法を説明します。
統合プロセス
要件段階では、コンテキスト図から始めましょう。これにより、全体の枠組みが明確になります。システムを分解していく中で、データストアを特定します。これらのデータストアは最終的にERDのエンティティになります。DFDの流れは、ERDの外部キーと関係性になります。
たとえば、DFDで「プロフィール更新」プロセスが「ユーザー情報」ストアにデータを移動している場合、ERDではそのストアと一致する属性を持つ「ユーザー」エンティティを定義しなければなりません。DFDにおけるプロセスとストアの関係は、ERDにおける読み書き権限やトランザクションロジックを決定します。
ドキュメントの整合性
両方の図の整合性を保つことは非常に重要です。DFDで新しいデータソースを追加した場合、ERDは新しいテーブルやカラムを反映する必要があります。ERDでテーブルの構造が変更された場合、DFDは新しいデータフロー名や宛先を示す必要があります。ここでの不整合は、統合バグやデータ損失を引き起こします。
現代システムにおける高度な考慮事項 🚀
これらの図はメインフレーム時代に誕生しましたが、その原則は現代のマイクロサービスやクラウドアーキテクチャにおいても依然として重要です。
クラウドとDFD
クラウド環境では、データの流れが異なるリージョンやサービスを横断することがよくあります。DFDはこれらの境界を明確に示す必要があります。これにより、レイテンシーやデータ主権の要件を理解しやすくなります。たとえば、ヨーロッパのユーザーから米国のサーバーへデータが流れている場合、コンプライアンス規制が適用される可能性があります。
NoSQLとERD
従来のERDはリレーショナル構造を前提としています。NoSQLデータベースはしばしばドキュメントモデルやグラフモデルを使用します。エンティティと関係性の核心的な概念は維持されますが、実装方法は異なります。ドキュメントストアでは、「エンティティ」はドキュメントそのものになります。関係性は外部キーではなく、IDによる埋め込みやリンクで表現されることがあります。ERDは依然としてブループリントとして機能しますが、スキーマレスな技術特性に応じて表記法が調整されることがあります。
違いの要約
これらの2つの図の違いは、その目的にあります。DFDは動きの地図です。データに何が起こるかという問いに答えます。ERDは構造の地図です。データとは何かという問いに答えます。ソフトウェアシステムの完全な姿を把握するには、両方が必要です。片方だけに頼ると、理解の穴が生じ、プロジェクトの品質が損なわれる可能性があります。
両モデルの構築と応用を習得することで、システムの運用機能だけでなく、データ管理の堅牢性も確保できます。この二重アプローチは情報アーキテクチャの動的・静的側面をカバーし、開発と分析の包括的な基盤を提供します。
よくある質問
1つの図で両方の目的に使えるでしょうか?
いいえ。DFDはテーブルキーまたは正規化ルールを効果的に示すことはできません。ERDはプロセスロジックやデータ変換ステップを効果的に示すことはできません。両者は異なるステークホルダーとフェーズに応じて使用されます。
どちらを最初に作成すべきでしょうか?
通常はDFDから始めます。何を保存するデータが必要かを知るには、まずプロセスを理解する必要があります。DFDでデータストアが特定されたら、それを完全なERDに拡張できます。
これらの図はアジャイル手法と併用できますか?
はい。アジャイルでは、これらの図は大規模な事前文書として作成されるのではなく、特定のユーザーストーリー用にタイムリーに作成されます。製品とともに進化する、動的なドキュメントとして機能します。