











現代アプリケーションのデータ構造を設計するには、情報がどのように接続され、保持され、スケーリングされるかを慎重に検討する必要があります。この設計プロセスの中心にはエンティティ関係図(ERD)があります。この視覚的モデルは、データエンティティとその相互作用を理解するための設計図として機能します。アプリケーションの複雑性が増すにつれて、関係型アプローチとグラフベースのアプローチの選択が重要になります。両方の方法は、データ関係の性質やシステムのパフォーマンス要件に応じて、それぞれ独自の利点を提供します。
各モデリング手法の微細な違いを理解することで、アーキテクトは堅牢で、保守性が高く、効率的なシステムを構築できます。このガイドでは、関係型とグラフベースのERDの選択における基盤となる原則、構造上の違い、実用的な影響について探求します。これらの手法を深く検討することで、チームは特定のビジネスロジックと技術的制約に合致した、情報に基づいた意思決定を行うことができます。
🏛️ 関係型アプローチ:構造と整合性
関係型モデルは数十年にわたりデータ管理の基盤となってきました。データは行と列から構成されるテーブルに整理される、厳格な構造に依存しています。関係型ERDでは、エンティティはテーブルとして表現され、関係は異なるテーブル間の主キーをリンクする外部キーによって定義されます。
関係型モデリングの基本原則
- 正規化:関係型データベースは、冗長性を減らすために正規化を重視します。各情報が1か所にのみ格納されるように、データを複数のテーブルに分割します。これにより、更新や削除時のデータ異常を最小限に抑えることができます。
- 参照整合性:制約により、関係が有効な状態を保ちます。親テーブルのレコードが削除された場合、ルールによって子レコードの処理方法が決まります。例えば、連鎖削除や操作の禁止などが該当します。
- スキーマ定義:構造はデータの挿入前に定義されます。すべての列には特定のデータ型と制約が必要であり、データセット全体に一貫性を保証します。
- クエリ言語:データにアクセスするには通常、構造化クエリ言語(SQL)を使用します。この言語により、複数のテーブルに分散したデータを取得するための複雑な結合が可能になります。
関係型ERDの強み
関係型図は、データの一貫性が最も重要な状況で優れた性能を発揮します。金融取引、在庫管理、またはルールへの厳格な準拠が求められるあらゆるアプリケーションに適しています。
- データ整合性:厳格なスキーマが、無効なデータがシステムに入ることを防ぐルールを強制します。これはコンプライアンスや監査トレースにとって不可欠です。
- 成熟度:技術は広く理解されています。可視化、デバッグ、保守のためのツールが豊富で、標準化されています。
- ACID準拠:関係型システムは通常、原子性、整合性、分離性、耐久性(ACID)をサポートしています。これにより、システム障害が発生した場合でも、トランザクションが信頼性を持って処理されることを保証します。
- 結合の効率性:関係のレベルが少なく、深く正規化されたデータでは、テーブルの結合が効率的で予測可能になります。
考慮すべき制限事項
強みがある一方で、関係型モデルは、非常に相互に接続されたデータを扱う際に課題に直面します。関係の数が増えるにつれて、結合の複雑さも増大します。
- 複雑な結合:多数のテーブルにまたがるデータを照会すると、パフォーマンスの低下が生じる可能性があります。各結合は計算上のオーバーヘッドを追加します。
- スキーマの硬さ:関係型データベースの構造を変更するには、通常、マイグレーションスクリプトが必要です。これは本番環境ではリスクが高く、時間もかかる場合があります。
- モデリングの深さ:多数対多数の関係や再帰構造(組織の階層構造など)を表現するには、中間テーブルや自己参照キーが必要であり、これは図やクエリを複雑にする可能性がある。
🕸️ グラフベースのアプローチ:接続を第一級の要素として
グラフベースのモデリングは、データそのものではなく、データポイント間の接続に注目する。このアプローチでは、関係性が外部キーによって推論されるのではなく、明示的に定義されたリンクとして保存される。これにより、グラフモデルはネットワーク、社会構造、レコメンデーションエンジンに特に適している。
グラフモデリングの基本原則
- ノードとエッジ:エンティティはノードとして表現され、関係はエッジとして表現される。各ノードとエッジはプロパティを保持でき、追加のテーブルなしに豊富なメタデータを扱える。
- トラバーサル:クエリは、ノードから別のノードへパスをたどることを中心に設計される。データベースエンジンは、テーブルのスキャンよりもリンクの追跡を最適化する。
- スキーマの柔軟性:スキーマを強制することは可能だが、グラフモデルはしばしばスキーマレスまたは読み取り時のスキーマアプローチを許容する。新しい関係タイプを追加する際、全体の構造を変更する必要はない。
- パターンマッチング:クエリは特定の接続パターンの検出に焦点を当てる。友達の友達、最短経路、共有された特徴などを効率的に見つけるのに適している。
グラフERDの強み
システムの価値がエンティティ間の接続にある場合、グラフ図は特に優れた表現を提供する。複雑なネットワークに対して自然な表現を可能にする。
- ナビゲーション効率:複数の分離度を通じてデータを取得する際、著しく高速になる。データベースは、全体のデータセットをスキャンすることなく、リンクを直接たどる。
- 動的関係:新しい種類の接続を追加しても、スキーマの移行は不要である。これにより、迅速な反復開発と変化するビジネス要件の対応が可能になる。
- 視覚的明確さ:グラフERDはしばしばデータのメンタルモデルを反映する。ステークホルダーは、複雑な結合条件を理解しなくても、エンティティがどのように関係しているかを簡単に把握できる。
- 深い階層構造の扱い:カテゴリの中にカテゴリがあるといった再帰的関係は、ノードとエッジの連鎖として自然に表現される。
考慮すべき制限
グラフモデルは万能の解決策ではない。特定の課題を引き起こすため、適切に管理する必要がある。
- 書き込みパフォーマンス:読み取りは高速だが、大量の書き込み中に関係性を維持することは、単純な挿入よりも複雑になることがある。
- トランザクションのスコープ:分散グラフ全体でのトランザクション管理は、単一テーブルの行更新と比べて困難である。
- クエリの複雑さ: 効果的なトラバーサルクエリを書くには、SQLの結合を書くのとは異なる思考が必要です。これは経路探索アルゴリズムの理解を伴います。
- ツールエコシステム: グラフデータ管理のエコシステムは成長しているものの、リレーショナルシステムと比べて依然として小さいため、人材採用やサポートの可用性に影響を与える可能性があります。
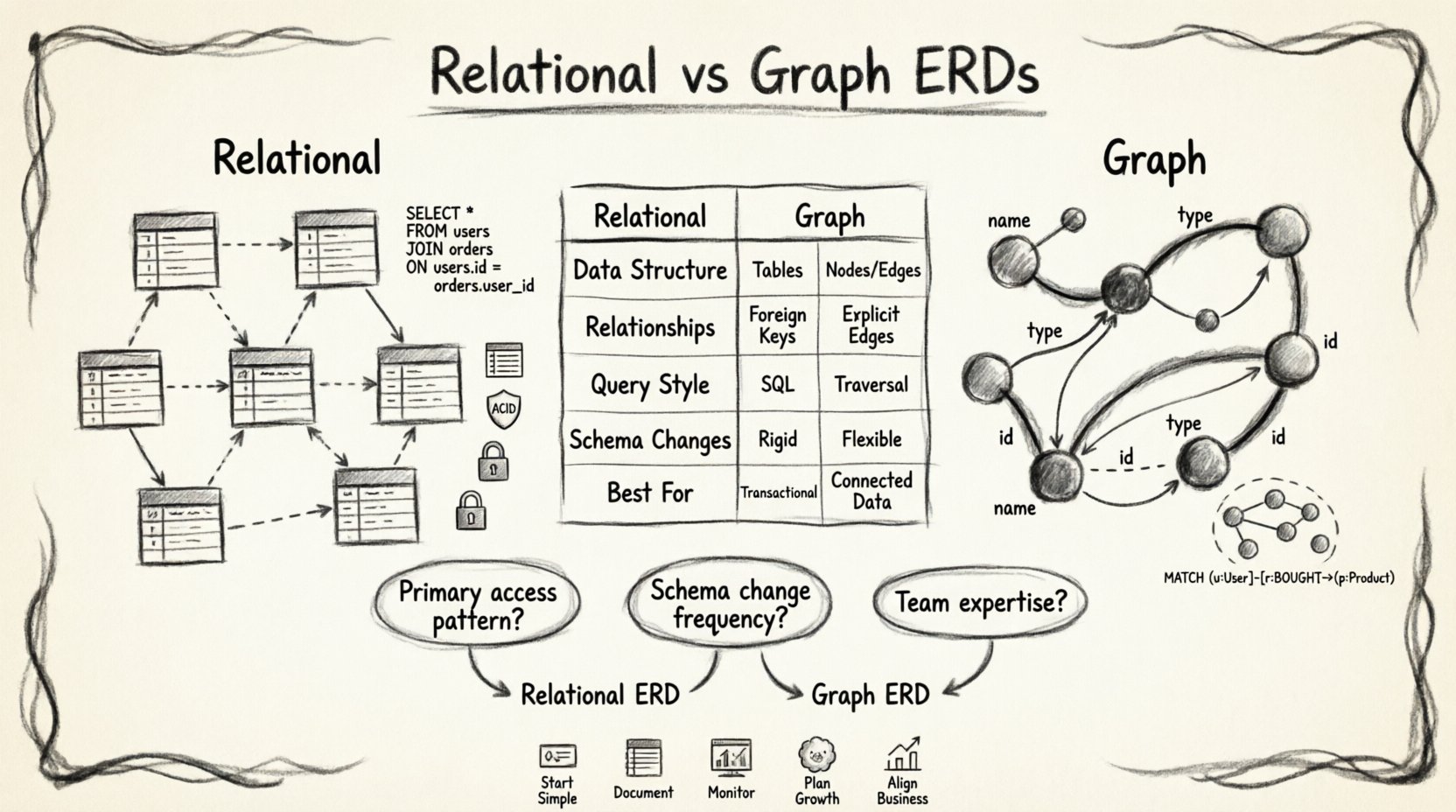
⚖️ 比較分析:主な違い
利点と欠点を明確に理解するためには、2つのアプローチを並べて見ることが役立ちます。以下の表は、一般的なアーキテクチャ的次元における主な違いを概説しています。
| 次元 | リレーショナルERDアプローチ | グラフベースのERDアプローチ |
|---|---|---|
| データ構造 | テーブル、行、列 | ノード、エッジ、プロパティ |
| 関係の格納方法 | 外部キー(暗黙的) | 明示的なエッジ(第一級) |
| クエリスタイル | 宣言型(SQL) | トラバーサル/パターンマッチング |
| スキーマの変更 | 高コスト(マイグレーション) | 柔軟性がある(スキーマレスな選択肢) |
| 最適な使用ケース | トランザクション型、構造化データ | ネットワーク化、接続されたデータ |
| 整合性の強制 | 厳格な制約 | アプリケーションレベルまたは設定可能 |
| スケーラビリティ | 垂直スケーリング | 水平スケーリング |
| クエリの複雑さ | 高頻度の結合 = ゆっくり | 深い階層 = 効率的 |
🛠️ 実装上の考慮事項
これらのアプローチのどちらを選ぶかは、技術的な好み以上のことを含みます。アプリケーションのライフサイクル、チームの専門知識、長期的な保守目標を評価する必要があります。
スキーマの進化と移行
リレーショナル環境では、スキーマの進化は意図的なプロセスです。列の追加やデータ型の変更は、テーブルのロックやマイグレーションスクリプトの実行を要することが多く、可用性に影響を与えることがあります。一方、グラフモデルでは、既存のノードに影響を与えずに新しい関係タイプを導入できます。この柔軟性は、要件が頻繁に変化するアジャイル開発サイクルをサポートします。
しかし、この柔軟性にはコストが伴います。厳格なスキーマの強制がなければ、データの品質は時間とともに低下する可能性があります。チームは、グラフが使いやすくクエリ可能であることを保証するために、ガバナンス戦略を導入する必要があります。
クエリのパフォーマンスとインデックス
両モデル間でのパフォーマンス最適化は大きく異なります。リレーショナルシステムは、検索を高速化するために列にインデックスを依存しています。複数のテーブルを結合する際、最適化ツールが最も効率的な実行計画を決定します。
グラフシステムは、ノードとエッジにインデックスを依存しています。トレイバーサルエンジンはポインタを直接たどります。深いネストを必要とするクエリ、たとえば「地域Xの顧客に配送される製品に部品を供給するすべてのサプライヤーを検索する」というような場合、グラフモデルは複数の結合による指数関数的なコストを回避できます。
データの一貫性要件
お金、医療記録、法的契約を取り扱うアプリケーションは、強い一貫性を必要とします。リレーショナルモデルは、トランザクションをコミットする前にすべてが有効であることを保証する組み込みメカニズムを提供します。グラフモデルも一貫性をサポートできますが、分散ノード間で同じレベルの保証を得るには、多くの設定が必要になることがよくあります。
既存システムとの統合
多くの組織はすでにリレーショナルインフラを備えています。グラフモデルを導入すると、ポリグロット永続化を必要とすることがよくあります。これは、2つの異なるデータストアを維持し、両者が同期されていることを保証する必要があることを意味します。統合レイヤーはアーキテクチャに複雑性をもたらします。
🌐 モダンなアプリケーションのためのハイブリッド戦略
多くのモダンなアプリケーションは、一つのカテゴリに neatly には当てはまりません。ハイブリッドアプローチがしばしば最適なバランスを提供します。この戦略では、コアのトランザクションデータにはリレーショナルデータベースを使用し、関係性が重いクエリにはグラフストアを使用します。
マイクロサービスとデータ所有権
マイクロサービスアーキテクチャでは、異なるサービスが異なるデータモデルを所有できます。ユーザーサービスはアカウントを安全に管理するためにリレーショナルモデルを使用するかもしれません。おすすめサービスは、ユーザーの好みや関係性を分析するためにグラフモデルを使用するかもしれません。この分離により、各サービスが固有のワークロードに最適化できるようになります。
同期パターン
2つのストアを同期させることは、慎重な設計を必要とします。イベント駆動型アーキテクチャを使用して変更を伝播できます。リレーショナルストアでレコードが更新されると、対応するノードをグラフストアで更新するためのイベントが発生します。
- 変更データキャプチャ:リレーショナルデータベースのトランザクションログを監視して変更を検出する。
- イベントソーシング:状態の変更を、グラフ状態を再構築するために再実行可能なイベントのシーケンスとして保存する。
- バッチ処理:リレーショナルソースからグラフインデックスを再構築する定期的なジョブ。
📊 決定フレームワーク
どのERDアプローチを採用するかを検討する際は、以下の質問を検討してください。
- 主なアクセスパターンは何ですか?多くのテーブルにわたってデータを集約する必要がある場合、リレーショナルモデルがしばしば優れています。関係をたどる必要がある場合、グラフモデルが優れています。
- スキーマの変更頻度はどのくらいですか?頻繁な変更は、グラフまたはドキュメントベースのアプローチを示唆します。安定したスキーマは、リレーショナルモデルに適しています。
- データの重複に対する許容度はどのくらいですか?リレーショナルモデルは重複を最小限に抑えます。グラフモデルは、読み取りを高速化するために重複をしばしば受け入れます。
- チームの専門知識はどの程度ですか?リレーショナルSQLは広く教えられています。グラフクエリ言語は、チームが効果的に機能するためには特定のトレーニングが必要です。
- コンプライアンス要件は何ですか?厳格に規制されている業界では、リレーショナルシステムの監査可能性を好む傾向があります。
🔮 データモデリングの将来のトレンド
データモデリングの分野は引き続き進化しています。アプリケーションがより複雑になるにつれ、リレーショナルアプローチとグラフアプローチの境界がさらに曖昧になる可能性があります。
グラフ-リレーショナルハイブリッド
一部の新興データベースプラットフォームは、両者の長所を組み合わせようとしています。これらは、ネイティブなグラフ走査機能を備えたリレーショナルテーブルを提供します。これにより、開発者はトランザクションの整合性とネットワーク分析の両方を、1つのエンジンで扱うことができます。
AI駆動のスキーマ設計
人工知能は、データモデリングの支援を始めています。ツールは使用パターンを分析し、最適なスキーマ設計を提案できます。データの非正規化すべきタイミングや、関係インデックスを導入すべきタイミングを推奨することもできます。
クラウドネイティブなスケーリング
クラウドインフラは、両方のモデルを水平スケーリングへと促しています。分散型リレーショナルデータベースと分散型グラフクラスタは、標準になりつつあります。これにより、スケーリングの障壁が低下し、データのグローバル配布が可能になります。
📝 ベストプラクティスの要約
選択されたアプローチに関わらず、すべての成功したデータモデリングの取り組みに共通する原則があります。
- シンプルから始める:初期モデルを過剰に設計しないでください。コアとなるエンティティから始め、要件に応じて複雑性を段階的に追加してください。
- 関係を文書化する:関係の基数と方向を明確に文書化してください。これはチームの整合性にとって不可欠です。
- パフォーマンスを監視する:継続的にクエリのパフォーマンスを監視してください。紙面上では良いように見えるモデルでも、実際の運用環境では性能が劣る可能性があります。
- 成長を見据えて設計する:スケーリングを意識して設計してください。モデルが現在のデータ量の10倍または100倍を処理する場合を想定してください。
- ビジネスと一致させる:データモデルがビジネスドメインを反映していることを確認してください。図はビジネスロジックの物語を語るべきです。
リレーショナルモデルとグラフベースのERDのどちらを選ぶかは、完璧な解決策を見つけることではありません。特定の問題に適したツールを選ぶことが重要です。それぞれのアプローチの長所と限界を理解することで、アーキテクトは耐障害性があり、パフォーマンスが高く、将来のニーズに適応可能なシステムを構築できます。最終的な判断は、データの性質とアプリケーションの運用要件に依存します。