











डेटा मॉडलिंग किसी भी विश्वसनीय डेटाबेस आर्किटेक्चर की रीढ़ है। जबकि सिद्धांत अक्सर विश्वविद्यालय के कोर्स में पढ़ाया जाता है, लेकिन उत्पादन वातावरण में व्यावहारिक अनुप्रयोग धाराप्रवाह, प्रदर्शन बॉटलनेक, और तार्किक अस्पष्टताओं से भरे माहौल को उजागर करता है। एंटिटी रिलेशनशिप डायग्राम (ERD) इन प्रणालियों के लिए नींव के रूप में कार्य करते हैं, लेकिन जब वास्तविक दुनिया बॉक्स और रेखाओं में आराम से फिट नहीं होती है, तो वे अक्सर विवाद के कारण बन जाते हैं।
हमने मुख्य डेटाबेस प्रशासकों और डेटा वार्किटेक्ट्स के एक पैनल के साथ बैठकर उन परिदृश्यों का विश्लेषण किया जो डिज़ाइन चरण के दौरान टीमों को लगातार भ्रमित करते हैं। ये सिद्धांतवादी अभ्यास नहीं हैं; ये वे समस्याएं हैं जो व्यावसायिक आवश्यकताओं और भौतिक भंडारण सीमाओं के टकराव के कारण उत्पन्न होती हैं। यहाँ लक्ष्य एक त्वरित समाधान प्रदान करने का नहीं है, बल्कि शामिल व्यापारिक विकल्पों को गहराई से समझने में मदद करना है।
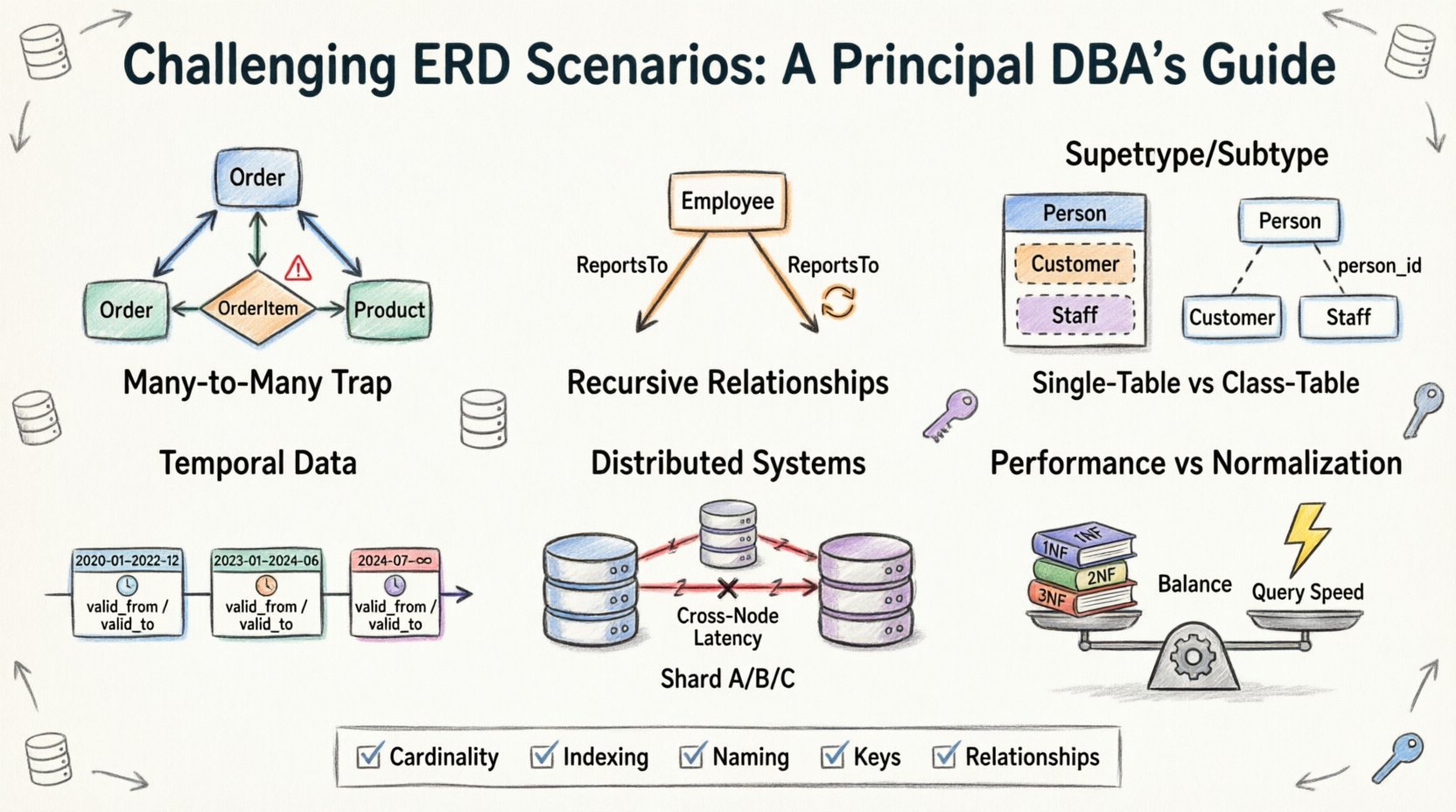
1. बहु-से-बहु जाल: सरल जॉइन टेबलों से परे 🕸️
ERD डिज़ाइन में सबसे आम शुरुआत बहु-से-बहु संबंध है। यह तार्किक लगता है: एक छात्र बहुत से कोर्स में दाखिला ले सकता है, और एक कोर्स में बहुत से छात्र हो सकते हैं। मानक समाधान एक ब्रिज या संबंधात्मक टेबल के उपयोग को शामिल करता है। हालांकि, जब संबंध में विशेषताएं शामिल की जाती हैं, तो जटिलता उत्पन्न होती है।
- समस्या:अक्सर, टीमें दाखिला डेटा (जैसे ग्रेड या पंजीकरण तिथियां) को मुख्य छात्र या कोर्स टेबल में संग्रहीत करने की कोशिश करती हैं, जिससे विशाल पुनरावृत्ति या खाली मान उत्पन्न होते हैं।
- वास्तविकता:संबंध स्वयं एक एंटिटी है। इसे अपना प्राथमिक कुंजी और माता-पिता की ओर इशारा करने वाली विदेशी कुंजी होनी चाहिए।
- चुनौती:कैस्केडिंग डिलीट का प्रबंधन। यदि कोई कोर्स हटा दिया जाता है, तो दाखिला रिकॉर्ड क्या होते हैं? यदि एक दाखिला हटा दिया जाता है, तो छात्र गायब हो जाता है? इन निर्णयों से डेटा अखंडता निर्धारित होती है।
हमारी चर्चा के दौरान, एक मुख्य डेटाबेस प्रशासक ने ध्यान दिलाया कि संबंधात्मक टेबल अक्सर प्रदर्शन की बाधा बन जाती है। इस जंक्शन के माध्यम से डेटा के प्रश्न के दौरान, डेटाबेस इंजन को जॉइन ऑपरेशन करना होता है, जो लाखों तक पहुंचने वाली पंक्ति संख्या के साथ खराब तरीके से पैमाने पर बढ़ सकता है। समाधान हमेशा आर्किटेक्चरल नहीं होता है; कभी-कभी इसके लिए डेनॉर्मलाइजेशन की आवश्यकता होती है, लेकिन इससे अपडेट असंगतियां उत्पन्न होती हैं।
बहु-से-बहु के लिए मुख्य विचार:
- क्या संबंध में ऐसी विशेषताएं हैं जिनके लिए इंडेक्सिंग की आवश्यकता है?
- क्या संबंध सक्रिय है या ऐतिहासिक है? (उदाहरण के लिए, क्या वर्तमान दाखिला पिछले दाखिले से अलग है?)
- यदि किसी माता-पिता को हटा दिया जाता है, तो प्रणाली अनाथ रिकॉर्ड को कैसे संभालेगी?
2. पुनरावृत्त संबंध: स्व-संदर्भित पदानुक्रम 🌳
पदानुक्रमित डेटा हर जगह है। एक संगठनात्मक चार्ट, एक सामग्री सूची, या एक फोरम पर टिप्पणी प्रवाह के बारे में सोचें। इसके मॉडलिंग के लिए एक टेबल को स्वयं के संदर्भ में रखना आवश्यक होता है। जबकि इसकी अवधारणा सरल है, एक संबंधात्मक स्कीमा में इसके कार्यान्वयन में गहराई और यात्रा से संबंधित विशिष्ट चुनौतियां उत्पन्न होती हैं।
संरचनात्मक समस्या:
आप एक टेबल बनाते हैं जिसमें प्राथमिक कुंजी और एक विदेशी कुंजी कॉलम होता है जो उसी टेबल की प्राथमिक कुंजी की ओर इशारा करता है। इसे अक्सर ‘माता-पिता_आईडी’ कॉलम कहा जाता है। रूट नोड का माता-पिता खाली होता है।
प्रदर्शन की समस्या:
मानक SQL प्रश्न गहन पदानुक्रमों के साथ कठिनाई में पड़ते हैं। यदि आप एक प्रबंधक और उनके सीधे और असीधे अधीनस्थों को प्राप्त करना चाहते हैं, तो एक सरल जॉइन पर्याप्त नहीं है। आपको पुनरावृत्ति वाले सामान्य टेबल एक्सप्रेशन (CTE) या स्टोर्ड प्रोसीजर्स की आवश्यकता होती है जो स्तरों के माध्यम से लूप करते हैं। इसका गणनात्मक खर्च अधिक हो सकता है।
अखंडता की समस्या:
चक्रीय संदर्भ एक चुप्पी नाशक हैं। यदि कर्मचारी A कर्मचारी B के प्रबंधन करता है, और कर्मचारी B कर्मचारी A के प्रबंधन करता है, तो आपके पास एक चक्र है। डेटाबेस को इसे रोकना चाहिए, या एप्लिकेशन लॉजिक को इसे पता लगाना चाहिए। बड़ी प्रणालियों में, एक चक्र रिपोर्टिंग टूल्स में अनंत लूप का कारण बन सकता है।
- गहराई सीमाएं:अधिकांश प्रणालियां पदानुक्रम की गहराई को सीमित करती हैं (उदाहरण के लिए, 32 स्तर) ताकि यात्रा के दौरान स्टैक ओवरफ्लो त्रुटियों से बचा जा सके।
- पथ संग्रहण:एक उप-पेड के कुल लागत या गिनती की गणना करने के लिए पुनरावृत्ति तर्क की आवश्यकता होती है, जिसे मानक प्रश्न योजनाओं में अनुकूलित करना कठिन होता है।
3. सुपरटाइप और सबटाइप मॉडलिंग: विरासत की दुविधा 🧬
ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंग में विरासत मानक है। संबंधात्मक डेटाबेस में, यह भंडारण और प्राप्ति पर प्रभाव डालने वाला डिज़ाइन चयन है। प्रश्न यह है: क्या आप वाहन को एक टेबल के रूप में मॉडल करेंगे, या इसे वाहन, कार और ट्रक में विभाजित करेंगे?
विकल्प A: एकल तालिका विरासत
सभी उपप्रकारों के लिए सभी विशेषताएं एक ही तालिका में होती हैं। अप्रयुक्त विशेषताओं के लिए नॉल का उपयोग किया जाता है।
- लाभ:सरल प्रश्न, किसी भी वाहन को खोजने के लिए जॉइन की आवश्यकता नहीं है।
- नुकसान:तालिका बढ़ना, उपप्रकार-विशिष्ट प्रतिबंधों को लागू करना मुश्किल, बहुत सारे नॉल वाले कॉलम।
विकल्प B: वर्ग तालिका विरासत
एक तालिका सुपरटाइप (वाहन) के लिए, और उपप्रकारों (कार, ट्रक) के लिए अलग-अलग तालिकाएं, जो प्राथमिक कुंजी द्वारा जुड़ी हैं।
- लाभ:स्पष्ट अलगाव, कोई नॉल नहीं, प्रत्येक उपप्रकार के लिए कठोर प्रतिबंध।
- नुकसान:प्रश्न पूछने के लिए एक से अधिक तालिकाओं को जोड़ने की आवश्यकता होती है, जिससे पढ़ने के प्रदर्शन पर प्रभाव पड़ सकता है।
हमारे मुख्य DBAs ने इंगित किया कि चयन अक्सर प्रश्न पैटर्न पर निर्भर करता है। यदि आप नियमित रूप से विशिष्ट उपप्रकारों को प्रश्न पूछते हैं, तो वर्ग तालिका दृष्टिकोण बेहतर है। यदि आप नियमित रूप से सभी उपप्रकारों को एकत्र करते हैं, तो एकल तालिका दृष्टिकोण जीतता है। ERD को इस निर्णय को स्पष्ट रूप से दर्शाना चाहिए ताकि भविष्य के विकासकर्ताओं को भ्रम न हो।
4. समय संबंधी डेटा: समय के साथ बदलावों को ट्रैक करना ⏳
व्यावसायिक नियम बदलते हैं। एक ग्राहक स्थानांतरित होता है, मूल्य अद्यतन होता है, एक अनुबंध समाप्त होता है। केवल “वर्तमान” स्थिति को संग्रहीत करना आमतौर पर लेखापरीक्षण या रिपोर्टिंग के लिए पर्याप्त नहीं होता है। इससे समय संबंधी तालिकाओं या धीमी बदलाव वाले आयामों (SCD) के डिज़ाइन की ओर जाया जाता है।
जटिलता:
एक पंक्ति के अपडेट के बजाय, आप एक प्रभावी शुरुआत और समाप्ति तिथि के साथ एक नई पंक्ति डालते हैं। पुरानी पंक्ति को अक्रिय चिह्नित कर दिया जाता है। इससे ऐतिहासिक डेटा के लिए स्टोरेज की आवश्यकता दोगुनी हो जाती है और “वर्तमान दृश्य” प्रश्न को जटिल बना देता है।
प्रश्न चुनौती:
किसी विशिष्ट समय बिंदु “के अनुसार” डेटा चुनने के लिए तिथि सीमा पर फ़िल्टर करने की आवश्यकता होती है। यदि आप तिथि सीमा तर्क को छोड़ देते हैं, तो आप एक रिकॉर्ड का गलत संस्करण लौटा सकते हैं। यह आमतौर पर वित्तीय एप्लिकेशनों में डेटा अखंडता की समस्याएं उभरने वाली जगह होती है।
- स्नैपशॉट डिज़ाइन:किसी समय बिंदु पर स्थिति संग्रहीत करें। स्नैपशॉट लिखने के लिए नियमित बैच कार्यक्रमों की आवश्यकता होती है।
- लेनदेन लॉग डिज़ाइन:हर बदलाव को कैप्चर करें। उच्च लेखन आयतन, जटिल प्राप्ति तर्क।
- आवधिक डिज़ाइन:वैध अंतराल संग्रहीत करें। समय में अंतराल को अच्छी तरह से संभालता है, लेकिन सीमा प्रबंधन की ध्यान से आवश्यकता होती है।
5. वितरित प्रणालियां: शार्डिंग और संबंध 🔗
जब एकल डेटाबेस डेटा को धारण नहीं कर सकता है, तो शार्डिंग आवश्यक हो जाती है। यहीं एरडी डिज़ाइन को उन सबसे गंभीर भौतिक सीमाओं का सामना करना पड़ता है। शार्डिंग सीमाओं को पार करने वाले संबंध महंगे होते हैं।
जॉइन समस्या:
यदि तालिका A को उपयोगकर्ता ID द्वारा शार्ड किया गया है, और तालिका B तालिका A से जुड़ी है, तो तालिका B को उसी उपयोगकर्ता ID द्वारा शार्ड किया जाना चाहिए ताकि वितरित जॉइन से बचा जा सके। यदि तालिका B को किसी अन्य चीज़ द्वारा शार्ड किया गया है, तो आपको प्रश्न को एकाधिक शार्ड में रूट करना होगा, परिणामों को एकत्र करना होगा, और स्थानीय रूप से जोड़ना होगा।
संदर्भात्मक अखंडता:
वितरित नोड्स के बीच विदेशी कुंजी प्रतिबंधों को लागू करना मुश्किल होता है। बहुत से सिस्टम उपलब्धता बनाए रखने के लिए शेडेड वातावरण में विदेशी कुंजियों को अक्षम कर देते हैं। इससे अखंडता का बोझ एप्लिकेशन लेयर पर स्थानांतरित हो जाता है, जो रेस कंडीशन के लिए अधिक झुकाव रखता है।
वितरित ERD के लिए मुख्य बिंदु:
- कई-से-कई संबंधों से बचें जो बहुत से शेड्स को छूते हैं।
- क्रॉस-नोड जॉइन की आवश्यकता को कम करने के लिए डेटा को अनियमित बनाएं।
- पार्टीशन कुंजी (शेडिंग कुंजी) को सिर्फ प्राथमिक कुंजी के बजाय सबसे अधिक आवृत्ति वाले प्रश्न पैटर्न के आधार पर डिज़ाइन करें।
6. प्रदर्शन बनाम सामान्यीकरण: व्यापार बैलेंस ⚖️
सामान्यीकरण (1NF, 2NF, 3NF) को डेटा अखंडता के स्वर्ण मानक के रूप में पढ़ाया जाता है। हालांकि, उच्च थ्रूपुट सिस्टम में सख्त सामान्यीकरण प्रदर्शन को मार सकता है। ERD को दोनों के बीच संतुलन बनाए रखना चाहिए।
जब डेटा को अनियमित बनाना चाहिए:
- पढ़ने पर अधिक आधारित कार्यभार: यदि आप डेटा को लिखने की तुलना में बहुत अधिक पढ़ते हैं, तो अतिरिक्त कॉलम जोड़ने से जॉइन ऑपरेशन बचते हैं।
- रिपोर्टिंग की आवश्यकताएं:सामान्यीकृत डेटा पर एग्रीगेशन के लिए जटिल जॉइन की आवश्यकता होती है जो डैशबोर्ड को धीमा कर देती है।
- लेखन पर अधिक आधारित कार्यभार: कभी-कभी, डेटा को अलग रखने से अपडेट के दौरान लॉकिंग प्रतिस्पर्धा कम हो जाती है।
हमारी पैनल ने जोर देकर कहा कि कोई भी ‘आदर्श’ स्कीमा नहीं है। यह एक समझौता है। ERD में यह दर्ज करना चाहिए कि डेनॉर्मलाइजेशन कहाँ और क्यों होता है, ताकि भविष्य के रखरखाव कर्मचारी समझ सकें कि अतिरिक्तता जानबूझकर है, गलती नहीं।
मॉडलिंग पैटर्न की तुलना 📊
निर्णय लेने में सहायता करने के लिए, यहाँ चर्चा किए गए मॉडलिंग पैटर्न और उनके सामान्य उपयोग के मुख्य बिंदु दिए गए हैं।
| पैटर्न | सर्वोत्तम उपयोग केस | मुख्य जोखिम | जटिलता |
|---|---|---|---|
| एकल तालिका | सरल हायरार्की, कम विविधता | नॉल फील्ड, स्कीमा ब्लाट | कम |
| वर्ग तालिका | कठोर उपप्रकार, अलग-अलग लक्षण | जॉइन ओवरहेड | मध्यम |
| पुनरावृत्त | संगठन आरेख, श्रेणियाँ | पारगमन गहराई, चक्र | उच्च |
| सहयोगी संस्था | गुणों के साथ बहु-से-बहु | जॉइन प्रदर्शन | मध्यम |
| कालिक | लेखापरीक्षण, इतिहास ट्रैकिंग | प्रश्न कठिनाई | उच्च |
| वितरित शर्डिंग | विशाल पैमाना, क्षैतिज वृद्धि | संदर्भात्मक अखंडता | अत्यधिक उच्च |
ईआरडी समीक्षा के लिए चेकलिस्ट ✅
एक संघ के संबंध आरेख को अंतिम रूप देने से पहले, आम त्रुटियों को पकड़ने के लिए इस चेकलिस्ट का उपयोग करें। डिजाइन चरण के दौरान इन समस्याओं को पकड़ना उत्पादन में बेहतर है।
- कार्डिनैलिटी:क्या आपने स्पष्ट रूप से एक-से-एक, एक-से-बहु और बहु-से-बहु संबंध परिभाषित किए हैं? क्या न्यूनतम/अधिकतम सीमाएँ (0..1, 1..*) स्पष्ट हैं?
- डेटा प्रकार:क्या कॉलम प्रकार प्रत्याशित डेटा आकार के लिए उपयुक्त हैं? (उदाहरण के लिए, आईडी के लिए Integer बनाम Varchar का उपयोग करना)।
- नलता:क्या विदेशी कुंजियाँ नल हो सकती हैं? यदि हाँ, तो क्या तर्क अनाथ संदर्भों को चुपचाप संभालता है?
- इंडेक्सिंग रणनीति:क्या ईआरडी प्रदर्शन के लिए किन कॉलम के इंडेक्सिंग की आवश्यकता है, इसका उल्लेख करता है? विदेशी कुंजियों को अक्सर जॉइन को तेज करने के लिए इंडेक्स किया जाता है।
- नामकरण प्रथाएँ:क्या तालिका और कॉलम के नाम संगत हैं? बाद में अस्पष्ट हो सकने वाले संक्षिप्त रूपों से बचें।
- व्यापार नियम:क्या सीमाएँ (उदाहरण के लिए, “एक उपयोगकर्ता के पास दो सक्रिय सदस्यताएँ नहीं हो सकती हैं”) तार्किक जाँच या डेटाबेस सीमाओं के रूप में प्रस्तुत की गई हैं?
- विस्तार्यता: क्या स्कीमा किसी भी पूर्ण माइग्रेशन के बिना नए लक्षणों को समायोजित कर सकता है? (उदाहरण के लिए, उपयुक्त स्थितियों में EAV पैटर्न या JSON कॉलम का उपयोग करके)।
डेटा मॉडलिंग पर अंतिम विचार 🧠
एक एंटिटी रिलेशनशिप डायग्राम डिज़ाइन करना केवल बॉक्स और लाइनें बनाने के बारे में नहीं है। यह डेटा के प्रवाह, हार्डवेयर की सीमाओं और व्यापार की आवश्यकताओं को समझने के बारे में है। यहाँ चर्चा किए गए परिदृश्य सिद्धांत और व्यवहार के मिलने के स्थानों को दर्शाते हैं।
इन चुनौतियों—पुनरावृत्ति गहराई, वितरित जॉइन, समय संबंधी इतिहास और विरासत के लाभ-हानि—की पूर्व संभावना रखकर आप लचीले स्कीमा बना सकते हैं। अच्छी तरह से डिज़ाइन किए गए एरडी तकनीकी दायित्व को कम करता है और बाद में महंगे रीफैक्टरिंग की आवश्यकता को रोकता है। यह पूरी प्रणाली की स्थिरता में निवेश है।
याद रखें कि सबसे अच्छा स्कीमा वह है जो डेटा के साथ विकसित होता है। दस्तावेज़ीकरण महत्वपूर्ण है। सुनिश्चित करें कि मानक सामान्यीकरण से हर विचलन के लिए तर्क दिया गया हो और दर्ज किया गया हो। यह पारदर्शिता ही एक मजबूत डेटाबेस आर्किटेक्चर को एक नाजुक वाले से अलग करती है।