











💡 Points clés
-
Clarté visuelle : L’ingénierie inverse transforme le code source dense en diagrammes UML lisibles, révélant l’architecture cachée.
-
Cartographie des dépendances : L’analyse automatisée identifie les relations entre les modules, facilitant le restructurage et la compréhension du couplage.
-
Modernisation des systèmes hérités : La création de diagrammes à partir de bases de code existantes comble le fossé entre la dette technique et la documentation future.
Dans le paysage du développement logiciel, la maintenance de la documentation est souvent en retard par rapport au rythme de mise en œuvre. Les bases de code s’agrandissent, des fonctionnalités sont ajoutées, et les décisions architecturales initiales deviennent floues. C’est là que l’ingénierie inverse devient une discipline essentielle. Elle consiste à analyser le code source existant afin de reconstruire une représentation visuelle, généralement à l’aide de diagrammes UML. Ce processus ne se contente pas de documenter ce qui existe ; il clarifie comment les composants interagissent, où se trouvent les dépendances et comment le système est structuré.
Comprendre l’ingénierie inverse dans le contexte de l’UML 🧩
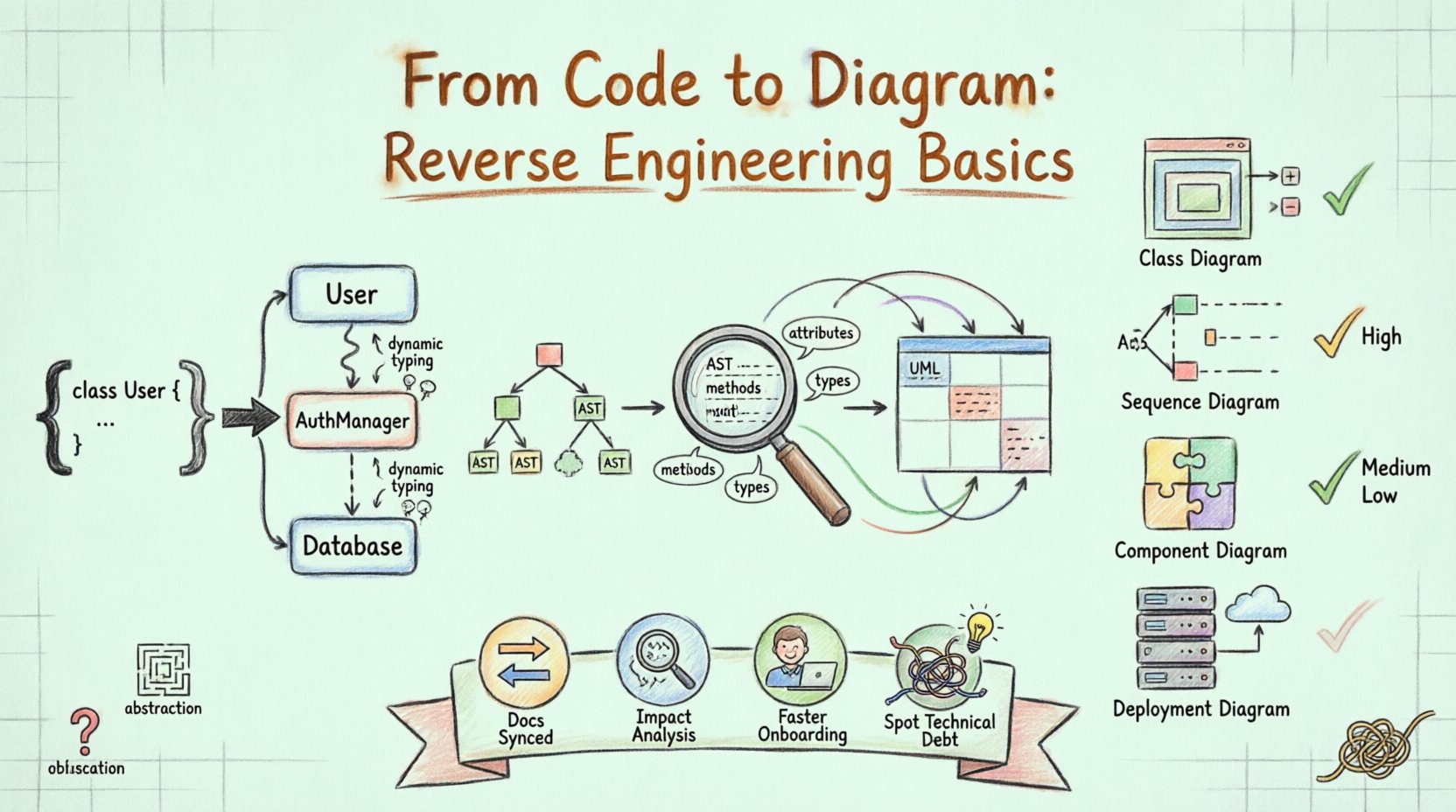
L’ingénierie inverse en développement logiciel est le processus d’analyse d’un système afin d’identifier ses composants et leurs interrelations. Lorsqu’elle est appliquée à l’UML, l’objectif est de dériver une représentation diagrammatique à partir de l’implémentation réelle. Contrairement à l’ingénierie ascendante, où les diagrammes guident l’écriture du code, l’ingénierie inverse commence par le code et en déduit les diagrammes.
Cette approche est particulièrement précieuse pour les systèmes hérités où la documentation peut être obsolète ou inexistante. En analysant le code source, les outils peuvent extraire les noms de classes, les signatures de méthodes, les hiérarchies d’héritage et les liens d’association. Ces éléments constituent les briques de base des diagrammes de classes, des diagrammes de séquence et des diagrammes de composants.
L’objectif fondamental
L’objectif principal est d’atteindre un état de compréhension. Les développeurs rencontrent souvent du code hérité qui semble être une boîte noire. L’ingénierie inverse ouvre cette boîte, permettant aux équipes de visualiser le flux de données et la logique structurelle sans avoir à lire chaque ligne d’implémentation. Elle agit comme un pont entre la réalité concrète du code et la conceptualisation abstraite du design.
Pourquoi générer des diagrammes à partir du code ? 📊
Il existe plusieurs raisons stratégiques à entreprendre ce processus. Ce n’est pas simplement une question de créer de jolies images ; il s’agit de réduction des risques et de clarté.
-
Synchronisation de la documentation : Le code change fréquemment. Les diagrammes générés à partir du code sont toujours à jour, reflétant l’état actuel du système.
-
Analyse d’impact : Avant de restructurer un module, les développeurs doivent savoir ce qui en dépend. Les diagrammes mettent clairement en évidence ces dépendances.
-
Intégration : Les nouveaux membres de l’équipe peuvent mieux comprendre l’architecture du système plus rapidement en consultant des diagrammes qu’en naviguant dans un dépôt de fichiers.
-
Identification de la dette technique : Les structures complexes se révèlent souvent sous forme de toiles emmêlées dans les diagrammes, mettant en évidence les zones nécessitant une simplification.
Le processus de l’ingénierie inverse 🔄
Transformer le code en diagrammes implique un flux de travail systématique. Bien que les implémentations spécifiques varient, les étapes logiques restent constantes d’un environnement à l’autre.
1. Analyse et parsing
La première étape consiste à lire les fichiers de code source. Le système analyse la syntaxe pour comprendre la structure. Il identifie les classes, les interfaces, les fonctions et les variables. Cette phase convertit le texte brut en un format de données structuré, souvent un arbre syntaxique abstrait (AST). Le parseur doit être conscient du langage pour interpréter correctement la syntaxe spécifique au langage de programmation utilisé.
2. Extraction des métadonnées
Une fois le code analysé, le système extrait des métadonnées spécifiques. Cela inclut :
-
Attributs : Champs de données au sein des classes.
-
Méthodes : Fonctions et leurs modificateurs d’accès (public, privé, protégé).
-
Types : Les types de données associés aux attributs et aux valeurs de retour.
-
Relations : Héritage (extends/implements), association (utilisation) et agrégation (composition).
3. Mappage vers les sémantiques UML
Les métadonnées extraites doivent être mappées vers la notation UML. Par exemple, une définition de classe se traduit par une boîte dans un diagramme de classes. Un appel de méthode au sein d’une fonction se traduit par une interaction dans un diagramme de séquence. Ce mappage nécessite une inférence logique. Si la classe A crée une instance de la classe B, le système infère une association ou une dépendance.
4. Visualisation et rendu
La dernière étape consiste à rendre les données sous une forme visuelle. Cela implique de placer les éléments sur une toile et de dessiner des lignes pour représenter les relations. Les algorithmes de disposition tentent d’organiser le diagramme afin qu’il soit lisible, en minimisant les croisements de lignes et en regroupant les composants connexes.
Diagrams couramment générés 📝
Tous les diagrammes ne sont pas également adaptés à l’ingénierie inverse. Certains capturent la structure statique, tandis que d’autres capturent le comportement dynamique.
|
Type de diagramme |
Objectif |
Utilité dans l’ingénierie inverse |
|---|---|---|
|
Diagramme de classes |
Structure statique |
Élevée. Montre l’héritage, les attributs et les méthodes directement à partir du code. |
|
Diagramme de séquence |
Comportement dynamique |
Moyenne. Nécessite le suivi des appels de méthodes pour comprendre le flux d’interaction. |
|
Diagramme de composants |
Modules du système |
Élevée. Regroupe les classes en unités logiques ou bibliothèques. |
|
Diagramme de déploiement |
Infrastructure |
Faible. Nécessite des connaissances en configuration de serveur, et non seulement du code. |
Défis du processus ⚠️
Bien que puissant, l’ingénierie inverse n’est pas sans difficultés. Plusieurs facteurs peuvent compliquer la génération de diagrammes précis.
Abstraction et masquage
Les bases de code modernes reposent fortement sur l’abstraction. Les interfaces et la polymorphisme peuvent masquer l’implémentation réelle. Une méthode peut être définie dans une interface mais implémentée dans plusieurs classes. Visualiser cela nécessite de montrer à la fois le contrat et la réalisation, ce qui peut encombrer un diagramme.
Typage dynamique
Les langages qui supportent le typage dynamique (où les types des variables sont déterminés à l’exécution) posent un défi pour l’analyse statique. L’outil d’ingénierie inverse peut éprouver des difficultés à déterminer le type exact d’un objet sans exécuter le code ou analyser des flux de contrôle complexes.
Obfuscation du code
Dans certains contextes, le code est obfusqué pour protéger le droit de propriété intellectuelle. La minification et le renommage des variables rendent le code source difficile à lire pour les humains et les machines. L’ingénierie inverse d’un code obfusqué nécessite des techniques d’analyse nettement plus sophistiquées.
Dépendances complexes
Les grands systèmes ont souvent des dépendances circulaires ou des modules fortement couplés. Lorsqu’un diagramme est généré, ces dépendances peuvent créer un effet « spaghetti », où les lignes se croisent de manière chaotique. Une intervention manuelle est souvent nécessaire pour nettoyer le layout et regrouper logiquement les éléments connexes.
Meilleures pratiques pour la précision ✅
Pour garantir que les diagrammes générés soient utiles, certaines pratiques doivent être suivies pendant le processus d’ingénierie inverse.
-
Filtrer le bruit : Exclure les bibliothèques standard ou le code boilerplate qui ajoutent du bruit visuel sans valeur architecturale. Se concentrer sur la logique métier personnalisée.
-
Regrouper les modules : Utiliser des paquets ou des espaces de noms pour regrouper les classes. Cela empêche le diagramme de devenir un seul nœud massif.
-
Valider les relations : Les outils automatisés peuvent parfois mal interpréter les relations. Vérifiez les liens générés pour vous assurer qu’ils reflètent fidèlement la logique du code.
-
Itérer : L’ingénierie inverse est rarement une tâche ponctuelle. Au fur et à mesure que la base de code évolue, les diagrammes doivent être régénérés et revus périodiquement.
Le rôle de l’automatisation 🤖
L’ingénierie inverse manuelle est impraticable pour les grands projets. L’automatisation est essentielle. Les parseurs automatisés analysent les dépôts, construisent des graphes de dépendances et exportent vers des formats standards comme XMI ou PlantUML. Cela permet aux équipes d’intégrer la génération de diagrammes dans leurs pipelines CI/CD.
L’automatisation garantit que la documentation n’est jamais obsolète. Si un développeur effectue un changement qui rompt une dépendance, le processus de génération de diagrammes peut signaler cette incohérence. Cette validation continue aide à maintenir l’intégrité du système au fil du temps.
Intégrer les diagrammes à la maintenance 🛠️
Une fois les diagrammes générés, ils doivent être activement utilisés. Ils ne servent pas seulement à la présentation. Les équipes peuvent les utiliser pour planifier des efforts de refactoring. Par exemple, si un diagramme de classes montre une classe avec des dépendances excessives, elle est candidate à une décomposition.
En outre, les diagrammes aident aux revues de code. Les validateurs peuvent examiner l’impact structurel d’un changement proposé avant de lire le diff. Cela déplace l’attention du syntaxe vers l’architecture, améliorant ainsi la qualité de la base de code.
Conclusion sur l’analyse structurelle 🏁
L’ingénierie inverse du code vers des diagrammes UML est une pratique fondamentale pour maintenir les systèmes logiciels complexes. Elle transforme un code opaque en architecture transparente, permettant une meilleure prise de décision et une communication plus claire. Bien que des défis existent concernant le typage dynamique et les dépendances complexes, les bénéfices d’une documentation synchronisée dépassent les coûts. En privilégiant la clarté structurelle, les équipes peuvent naviguer avec confiance dans les systèmes hérités et moderniser leurs applications avec précision.