











À mesure que les systèmes gagnent en complexité, la stabilité des structures de données sous-jacentes devient le fondement de la fiabilité opérationnelle. L’un des défis les plus persistants auxquels les équipes d’ingénierie sont confrontées est le décalage de schéma. Ce phénomène survient lorsque le schéma de base de données diverge de la conception attendue, entraînant des incohérences, des requêtes cassées et un comportement d’application imprévisible. Bien qu’il soit souvent traité comme une question de gestion de base de données, la cause fondamentale réside fréquemment dans la manière dont le diagramme d’entités et de relations (ERD) est conçu et gouverné dès le départ.
Un ERD bien structuré fait bien plus que visualiser les relations ; il agit comme un contrat entre la logique de l’application et la couche de stockage des données. Dans les environnements évolutifs où plusieurs services interagissent avec des données partagées, ce contrat doit être rigide tout en restant suffisamment souple pour s’adapter à la croissance. Ce guide explore les modèles architecturaux et les méthodologies qui stabilisent les modèles de données et préviennent le décalage de schéma avant qu’il n’impacte la production.
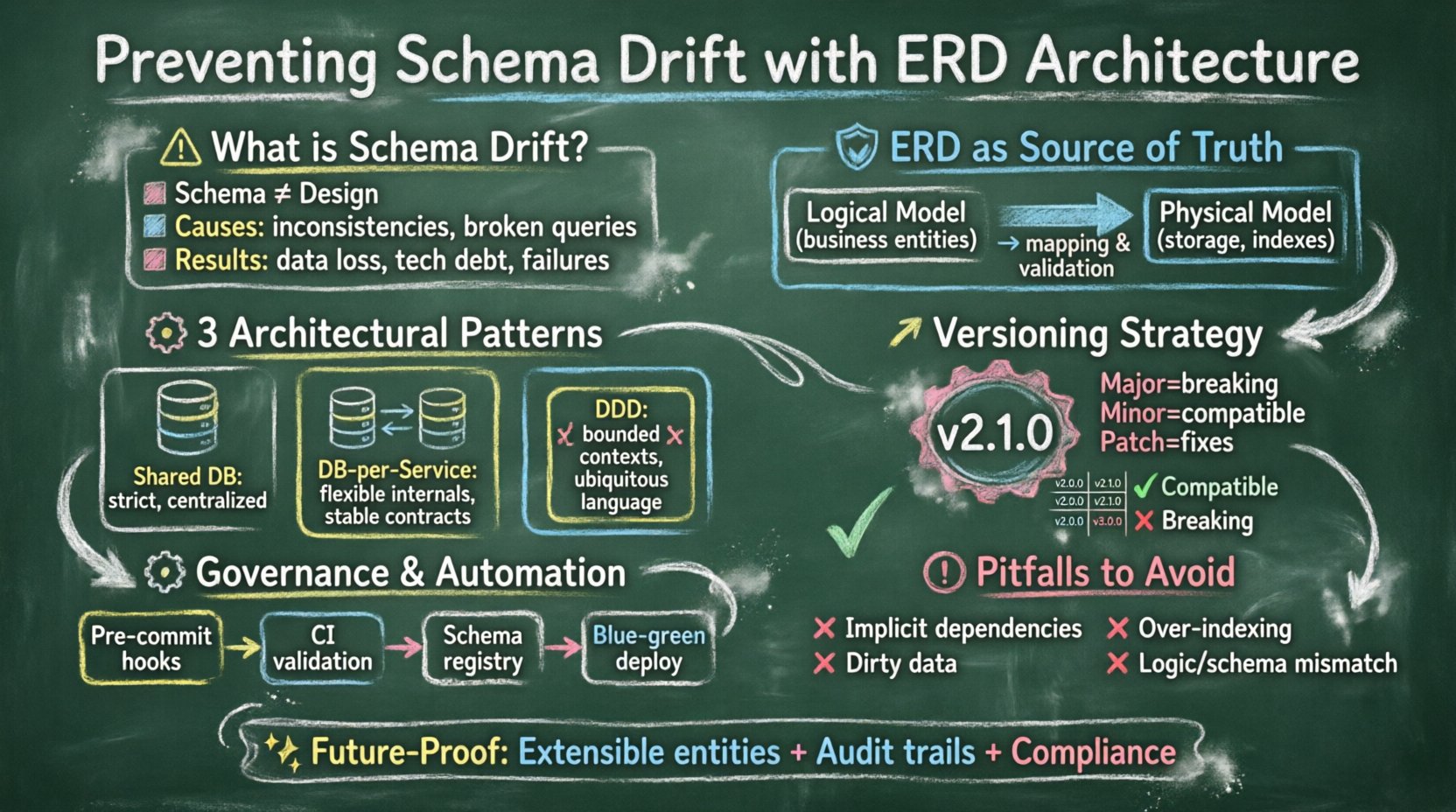
📉 Comprendre le décalage de schéma dans les environnements distribués
Le décalage de schéma n’est pas simplement une question d’oubli de mise à jour d’une table. Il s’agit d’un problème systémique où l’implémentation physique du modèle de données diverge de sa définition logique au fil du temps. Dans les systèmes monolithiques, cela peut se manifester par quelques colonnes oubliées. Dans les architectures distribuées et à microservices, cela peut entraîner des conditions de course où le Service A écrit des données dans un format que le Service B ne peut pas lire.
Les conséquences du décalage non contrôlé incluent :
- Perte d’intégrité des données :Les contraintes sont contournées, permettant des états non valides.
- Augmentation de la dette technique :Les développeurs passent plus de temps à déboguer des problèmes de données qu’à développer de nouvelles fonctionnalités.
- Pannes de service :Les API échouent lorsque des types de champs ou leur existence sont attendus.
- Complexité de migration :Rattraper le retard devient plus difficile à mesure que l’écart s’agrandit.
Prévenir cela exige une approche architecturale de l’ERD qui impose la cohérence sans entraver l’agilité. Cela implique de définir des règles de changement, de versionner le modèle de données et d’établir une gouvernance autour du diagramme lui-même.
🛡️ La fondation : l’ERD comme source de vérité
La première étape pour prévenir le décalage est de transformer le diagramme d’entités et de relations d’un dessin statique en un document vivant qui pilote l’implémentation. Lorsque l’ERD est traité comme un artefact secondaire, le décalage devient inévitable. Lorsqu’il est traité comme la source de vérité principale, l’architecture soutient la stabilité.
1. Séparation logique vs physique
Pour maintenir la flexibilité tout en assurant la stabilité, séparez le modèle de données logique de son implémentation physique. L’ERD logique doit décrire les entités métier et leurs relations sans contraintes techniques. L’ERD physique gère l’indexation, le partitionnement et les types de stockage spécifiques.
Cette séparation permet à la logique métier d’évoluer sans imposer de modifications physiques immédiates. Elle crée une zone tampon où les changements peuvent être validés par rapport aux exigences métiers avant d’impacter la couche de stockage.
2. Modèles de données canoniques
Dans les systèmes évolutifs, plusieurs services ont souvent besoin de comprendre les mêmes données. Établir un modèle de données canonique garantit que tous les services font référence aux mêmes définitions. L’ERD définit ces entités canoniques.
- Source unique de vérité : L’ERD définit le schéma exact pour des entités critiques telles que l’Utilisateur, la Commande ou l’Inventaire.
- Contrats de service : Les services consomment des données selon la définition de l’ERD, et non des requêtes ad hoc.
- Nomenclature standardisée : Les conventions de nommage définies dans l’ERD évitent toute ambiguïté entre les différentes instances de base de données.
🧩 Modèles architecturaux pour la stabilité de l’ERD
Les différentes architectures de système exigent des stratégies ERD différentes. Les modèles suivants aident à maintenir la cohérence au fur et à mesure que le système évolue.
1. Le modèle de base de données partagée
Dans certains systèmes monolithiques ou fortement couplés, une base de données partagée est utilisée. Ici, le MCD doit être extrêmement rigoureux. Les modifications du MCD nécessitent une coordination entre tous les modules accédant à cette base de données.
- Gestion centralisée du schéma : Une seule équipe est responsable des mises à jour du MCD.
- Contrôle d’accès strict : Seuls les scripts autorisés peuvent modifier le schéma.
- Suivi des dépendances : Le MCD doit représenter clairement les dépendances entre les tables afin d’identifier l’impact avant toute modification.
2. Le modèle base de données par service
Dans les architectures de microservices, chaque service possède ses propres données. Cela réduit le couplage direct, mais introduit le risque de définitions de données incohérentes entre les services. L’architecture du MCD se concentre ici sur l’interface entre les services plutôt que sur le stockage interne de chacun.
- Flexibilité interne : Chaque service peut évoluer son schéma interne tant que l’interface externe reste stable.
- Contrats externes : Le MCD définit les contrats partagés. Si le service A a besoin de données du service B, le MCD définit la structure attendue.
- Sourcing d’événements : Le MCD peut définir les événements qui transportent les données, garantissant l’immuabilité et la traçabilité.
3. L’approche Conception axée sur le domaine (DDD)
La conception axée sur le domaine aligne le schéma de la base de données sur les domaines métiers. Le MCD est divisé selon des contextes limités. Cela évite le problème de la « table Dieu » où des entités sans lien sont contraintes dans un même schéma.
- Cartographie des contextes : Le MCD cartographie les relations entre les contextes limités.
- Langue omniprésente : Les noms d’entités dans le MCD correspondent à la terminologie métier.
- Encapsulation : Les entités internes sont masquées ; seule la frontière du domaine est exposée.
🔄 Stratégies de versioning pour l’évolution du schéma
Le changement est inévitable. L’objectif est de le gérer sans briser les consommateurs existants. La versionning du schéma au sein de l’architecture du MCD est essentiel.
1. Versioning sémantique pour les schémas
Tout comme le code logiciel utilise le versioning sémantique, les schémas de données devraient également le faire. Une version de schéma peut être notée Major.Minor.Patch.
- Majeure :Changements disruptifs (par exemple, suppression d’une colonne, changement de type).
- Mineur : Ajouts compatibles à l’envers (par exemple, ajout d’une colonne pouvant être nulle).
- Correctif : Corrections internes ou optimisations qui n’affectent pas l’API.
2. Règles de compatibilité descendante
Pour éviter le décalage, respectez des règles strictes concernant l’évolution du schéma. Le tableau suivant décrit les modifications sûres contre les modifications non sûres.
| Action | Compatibilité | Exigence |
|---|---|---|
| Ajouter une nouvelle colonne | Compatibilité descendante | Doit autoriser les valeurs NULL initialement |
| Ajouter une nouvelle table | Compatibilité descendante | Assurez-vous qu’il n’y ait pas de dépendances de clés étrangères initialement |
| Supprimer une colonne | Changement cassant | Déprécier d’abord, puis supprimer ultérieurement |
| Changer le type de données | Changement cassant | Exige un plan complet de migration |
| Ajouter une clé étrangère | Conditionnel | Assurez-vous que les données existantes respectent la contrainte |
3. Modèles d’écriture double
Lorsqu’une modification du schéma est nécessaire, évitez le passage immédiat. Mettez en œuvre une stratégie d’écriture double où les données sont écrites dans les deux structures, ancienne et nouvelle. Au fil du temps, le trafic est redirigé vers la nouvelle structure. Le schéma entité-relation doit documenter les deux versions pendant cette transition.
- Chemin de lecture : Continuer à lire à partir du schéma stable.
- Chemin d’écriture : Écrire simultanément dans les deux schémas.
- Validation : Surveiller la cohérence des données entre les deux schémas.
- Passage à la nouvelle version : Une fois vérifié, cesser d’écrire dans l’ancien schéma.
⚙️ Gestion et gouvernance des migrations
Même avec le versioning, les migrations sont nécessaires. L’architecture doit supporter des migrations sûres, réversibles et automatisées.
1. Scripts de migration comme du code
Les migrations doivent être versionnées conjointement avec le code de l’application. Le modèle conceptuel des données (ERD) sert d’état cible pour ces scripts. Chaque fichier de migration doit faire référence à la version spécifique de l’ERD qu’il implémente.
- Idempotence :Les scripts doivent être sûrs à exécuter plusieurs fois.
- Capacité de retour en arrière : Chaque mise à jour doit avoir un script de désinstallation correspondant.
- Atomicité : Les modifications doivent être transactionnelles lorsque cela est possible pour éviter les mises à jour partielles.
2. Registre de schéma
Mettre en place un registre de schéma pour suivre l’état du modèle conceptuel des données (ERD) à travers les environnements. Cela garantit que les environnements de développement, de préproduction et de production sont alignés.
- Parité des environnements : Empêche les écarts entre dev et prod.
- Flux d’approbation : Les modifications de schéma nécessitent une revue avant promotion.
- Validation : Des vérifications automatisées garantissent que le schéma déployé correspond à l’ERD enregistré.
3. Documentation comme du code
La documentation doit être générée directement à partir de l’ERD. Cela garantit que les diagrammes et les descriptions textuelles restent synchronisés. La documentation manuelle devient souvent obsolète rapidement.
- Génération automatisée : Les outils peuvent générer de la documentation à partir du fichier ERD.
- Documents vivants : Les mises à jour de documentation font partie du processus de revue de code.
- Notes contextuelles : Inclure les notes de logique métier directement dans les métadonnées de l’ERD.
📝 Automatisation et intégration CI/CD
Les erreurs humaines sont une cause principale du décalage de schéma. L’automatisation réduit ce risque en imposant des règles pendant le pipeline de déploiement.
1. Hooks pré-commit
Implémentez des hooks qui valident les modifications de schéma avant leur validation dans le dépôt. Ces hooks vérifient les modifications critiques par rapport à la définition actuelle du modèle ERD.
- Analyse de code (linting) : Appliquez des conventions de nommage et des règles de structure.
- Validation : Assurez-vous que les nouvelles contraintes ne sont pas en conflit avec les données existantes.
- Revue : Exigez une approbation manuelle pour les modifications à haut risque.
2. Vérifications d’intégration continue
Pendant le processus CI, exécutez une validation de schéma contre une base de données de test. Cela permet de détecter les problèmes avant le déploiement.
- Environnements de sandbox : Déployez dans un environnement temporaire pour tester les migrations.
- Tests d’intégration : Exécutez des requêtes qui dépendent du schéma pour garantir la fonctionnalité.
- Vérifications de performance : Assurez-vous que les nouveaux index n’entraînent pas de dégradation des performances d’écriture.
3. Déploiements bleu-vert pour les données
De manière similaire aux déploiements d’applications, utilisez des stratégies bleu-vert pour les données. Maintenez deux versions du schéma en parallèle jusqu’à ce que la nouvelle version soit stable.
- Temps d’arrêt nul : Les utilisateurs ne sont pas affectés par les modifications de schéma.
- Retour instantané : Si des problèmes surviennent, revenez à la version précédente du schéma.
- Synchronisation des données : Assurez-vous que les données restent cohérentes entre les deux versions pendant la transition.
🚨 Pièges courants à éviter
Même avec une architecture solide, les équipes tombent souvent dans des pièges qui réintroduisent le décalage. La prise de conscience de ces pièges est essentielle pour une stabilité à long terme.
1. Dépendances implicites
Le code dépend souvent de structures de données qui ne sont pas explicitement définies dans le modèle ERD. Les noms de colonnes codés en dur ou les hypothèses sur la présence des données entraînent des échecs silencieux.
- Typage explicite : Utilisez un typage fort dans toutes les couches d’accès aux données.
- Contrats d’interface : Définissez des interfaces claires pour l’accès aux données.
- Refactoring : Auditez régulièrement le code pour repérer les hypothèses implicites.
2. Ignorer la qualité des données
Un schéma peut être parfait, mais si les données qui y entrent sont sales, le système échoue. Le MCD doit inclure des contraintes qui garantissent la qualité des données.
- Contraintes de vérification : Validez les valeurs au niveau de la base de données.
- Contraintes d’unicité : Empêchez les entrées en double.
- Contraintes NOT NULL : Assurez-vous que les champs obligatoires sont toujours remplis.
3. Sur-indexation
Ajouter des index pour améliorer les performances de lecture ralentit souvent les écritures. Cela peut entraîner des modifications du schéma qui perturbent le chemin d’écriture.
- Mesurez d’abord : Surveillez les performances des requêtes avant d’ajouter des index.
- Revoyez régulièrement : Supprimez les index inutilisés pour réduire la charge.
- Équilibre : Trouvez le bon équilibre entre les performances de lecture et d’écriture.
4. Découpler la logique du schéma
Appliquer la logique métier au niveau de la couche application alors qu’elle devrait être dans la base de données entraîne une incohérence. Le MCD doit indiquer où réside la logique.
- Contraintes de base de données : Déplacez la logique vers des déclencheurs ou des procédures stockées lorsque cela est approprié.
- Validation : Assurez-vous que la logique d’application ne contourne pas les règles de la base de données.
- Clarté : Documentez où réside la logique dans les notes du MCD.
🔮 Mise en place pour l’avenir du modèle de données
Les systèmes évolutifs doivent être prêts pour l’avenir. L’architecture du schéma entité-relation doit anticiper la croissance et les changements.
1. Extensibilité
Concevez les entités pour qu’elles soient extensibles. Utilisez des types de données flexibles ou des colonnes JSON pour les attributs qui peuvent varier, tout en maintenant une structure centrale rigide.
- Ensembles d’attributs :Stockez les attributs variables dans une carte structurée.
- Balises et étiquettes :Utilisez des paires clé-valeur pour les métadonnées dynamiques.
- Champs de version :Incluez des numéros de version dans les entités pour suivre les modifications.
2. Traçabilité
Tout changement apporté aux données doit être traçable. Le schéma entité-relation doit inclure des tables d’audit pour enregistrer qui a modifié quoi et quand.
- Tables d’historique :Maintenez un historique des modifications des enregistrements.
- Journaux de changements :Enregistrez les changements de schéma séparément des changements de données.
- Journaux d’accès :Suivez qui interroge les données sensibles.
3. Conformité et sécurité
Les modèles de données doivent respecter les exigences réglementaires. Le schéma entité-relation doit définir où les données sensibles sont stockées et comment elles sont protégées.
- Chiffrement :Marquez les champs qui nécessitent un chiffrement.
- Politiques de rétention :Définissez pendant combien de temps les données sont conservées dans le schéma.
- Contrôle d’accès :Définissez les rôles pouvant accéder à des entités spécifiques.
🏁 Réflexions finales sur l’intégrité architecturale
Empêcher le décalage du schéma ne consiste pas à restreindre les changements ; c’est plutôt à les gérer avec discipline. En traitant le schéma entité-relation comme un élément architectural central, les équipes peuvent construire des systèmes à la fois robustes et adaptables. La clé réside dans la séparation des préoccupations, la versioning rigoureux et la gouvernance automatisée.
Lorsque le schéma entité-relation est respecté, le modèle de données devient une fondation stable sur laquelle des applications évolutives peuvent être construites. Cela réduit la charge cognitive sur les développeurs, minimise les risques opérationnels et garantit que le système reste maintenable au fil de sa croissance. L’architecture du schéma dicte la stabilité des données, et en retour, la stabilité de l’entreprise.
Adopter ces modèles nécessite un investissement initial en processus et outils. Toutefois, le retour à long terme est un système qui évolue avec grâce, sans le fardeau constant de corriger des contrats de données brisés. Priorisez l’intégrité du modèle de données, et le système suivra.