











💡 Puntos clave
-
Claridad visual:La ingeniería inversa transforma el código fuente denso en diagramas UML legibles, revelando la arquitectura oculta.
-
Mapa de dependencias:El análisis automatizado identifica las relaciones entre módulos, facilitando la refactorización y la comprensión del acoplamiento.
-
Modernización de sistemas heredados:Crear diagramas a partir de bases de código existentes cierra la brecha entre la deuda técnica y la documentación futura.
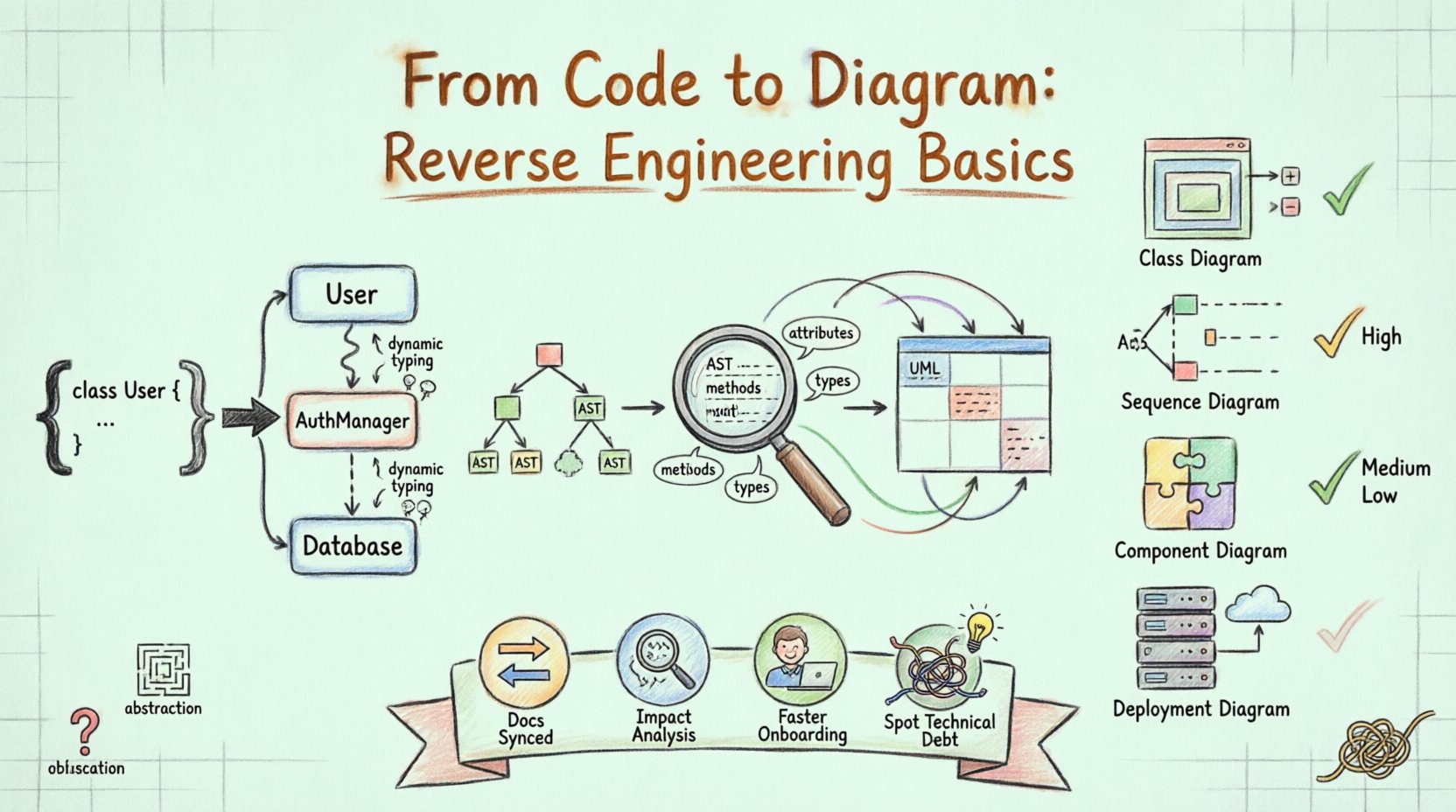
En el panorama del desarrollo de software, mantener la documentación a menudo queda rezagada respecto a la velocidad de implementación. Las bases de código crecen, se añaden características y las decisiones arquitectónicas originales se vuelven borrosas. Es aquí donde la ingeniería inversa se convierte en una disciplina esencial. Implica analizar el código fuente existente para reconstruir una representación visual, típicamente utilizando diagramas de Lenguaje Unificado de Modelado (UML). Este proceso no se limita a documentar lo que existe; clarifica cómo interactúan los componentes, dónde se encuentran las dependencias y cómo está estructurado el sistema.
Comprender la ingeniería inversa en el contexto de UML 🧩
La ingeniería inversa en el desarrollo de software es el proceso de analizar un sistema para identificar sus componentes y sus interrelaciones. Cuando se aplica a UML, el objetivo es derivar una representación diagramática a partir de la implementación real. A diferencia de la ingeniería hacia adelante, donde los diagramas guían la escritura del código, la ingeniería inversa comienza con el código y deriva los diagramas.
Este enfoque es especialmente valioso para sistemas heredados donde la documentación puede estar desactualizada o no existir. Al analizar el código fuente, las herramientas pueden extraer nombres de clases, firmas de métodos, jerarquías de herencia y enlaces de asociación. Estos elementos forman los bloques fundamentales de diagramas de clases, diagramas de secuencia y diagramas de componentes.
El objetivo principal
El objetivo principal es alcanzar un estado de comprensión. Los desarrolladores a menudo se enfrentan a código heredado que parece una caja negra. La ingeniería inversa abre esta caja, permitiendo a los equipos visualizar el flujo de datos y la lógica estructural sin necesidad de leer cada línea de la implementación. Sirve como puente entre la realidad concreta del código y la conceptualización abstracta del diseño.
¿Por qué generar diagramas a partir de código? 📊
Existen varias razones estratégicas para emprender este proceso. No se trata simplemente de crear imágenes atractivas; se trata de reducir riesgos y ganar claridad.
-
Sincronización de documentación:El código cambia con frecuencia. Los diagramas generados a partir del código siempre están actualizados, reflejando el estado actual del sistema.
-
Análisis de impacto:Antes de refactorizar un módulo, los desarrolladores necesitan saber qué depende de él. Los diagramas destacan claramente estas dependencias.
-
Integración:Los nuevos miembros del equipo pueden comprender la arquitectura del sistema mucho más rápido revisando diagramas que navegando por un repositorio de archivos.
-
Identificación de la deuda técnica:Las estructuras complejas a menudo se revelan como redes enredadas en los diagramas, destacando áreas que necesitan simplificación.
El proceso de ingeniería inversa 🔄
Transformar código en diagramas implica un flujo de trabajo sistemático. Aunque las implementaciones específicas varían, los pasos lógicos permanecen consistentes en todos los entornos.
1. Análisis y análisis sintáctico
El primer paso implica leer los archivos de código fuente. El sistema analiza la sintaxis para comprender la estructura. Identifica clases, interfaces, funciones y variables. Esta fase convierte el texto sin procesar en un formato de datos estructurado, a menudo una Árbol Sintáctico Abstracto (AST). El analizador sintáctico debe ser consciente del lenguaje para interpretar correctamente la sintaxis específica del lenguaje de programación en uso.
2. Extracción de metadatos
Una vez que el código se ha analizado, el sistema extrae metadatos específicos. Esto incluye:
-
Atributos:Campos de datos dentro de las clases.
-
Métodos:Funciones y sus modificadores de acceso (público, privado, protegido).
-
Tipos:Los tipos de datos asociados con los atributos y los valores devueltos.
-
Relaciones:Herencia (extends/implements), asociación (uso) y agregación (composición).
3. Mapeo a la semántica de UML
Los metadatos extraídos deben mapearse a la notación de UML. Por ejemplo, una definición de clase se mapea a un cuadro de Diagrama de Clases. Una llamada a un método dentro de una función se mapea a una interacción en un Diagrama de Secuencia. Este mapeo requiere inferencia lógica. Si la clase A crea una instancia de la clase B, el sistema infiere una asociación o dependencia.
4. Visualización y representación
El paso final consiste en representar los datos en un formato visual. Esto implica colocar elementos en una superficie de dibujo y trazar líneas para representar relaciones. Los algoritmos de disposición intentan organizar el diagrama para que sea legible, minimizando las líneas que se cruzan y agrupando los componentes relacionados.
Diagramas comunes generados 📝
No todos los diagramas son igualmente adecuados para la ingeniería inversa. Algunos capturan la estructura estática, mientras que otros capturan el comportamiento dinámico.
|
Tipo de diagrama |
Enfoque |
Utilidad en la ingeniería inversa |
|---|---|---|
|
Diagrama de clases |
Estructura estática |
Alta. Muestra la herencia, atributos y métodos directamente desde el código. |
|
Diagrama de secuencia |
Comportamiento dinámico |
Media. Requiere rastrear llamadas a métodos para entender el flujo de interacción. |
|
Diagrama de componentes |
Módulos del sistema |
Alta. Agrupa clases en unidades lógicas o bibliotecas. |
|
Diagrama de despliegue |
Infraestructura |
Baja. Requiere conocimiento de la configuración del servidor, no solo del código. |
Desafíos en el proceso ⚠️
Aunque es poderoso, la ingeniería inversa no está exento de dificultades. Varios factores pueden complicar la generación de diagramas precisos.
Abstracción y ocultamiento
Las bases de código modernas dependen en gran medida de la abstracción. Las interfaces y la polimorfía pueden ocultar la implementación real. Un método podría definirse en una interfaz pero implementarse en múltiples clases. Visualizar esto requiere mostrar tanto el contrato como la realización, lo cual puede emborronar un diagrama.
Tipado dinámico
Los lenguajes que admiten tipado dinámico (donde los tipos de variables se determinan en tiempo de ejecución) presentan un desafío para el análisis estático. La herramienta de ingeniería inversa puede tener dificultades para determinar el tipo exacto de un objeto sin ejecutar el código o analizar flujos de control complejos.
Obfuscación de código
En algunos contextos, el código se obfusca para proteger la propiedad intelectual. La minificación y el cambio de nombres de variables hacen que el código fuente sea difícil de leer para humanos y máquinas. La ingeniería inversa de código obfuscado requiere técnicas de análisis significativamente más sofisticadas.
Dependencias complejas
Los sistemas grandes a menudo tienen dependencias circulares o módulos fuertemente acoplados. Cuando se genera un diagrama, estas dependencias pueden crear un efecto de ‘espagueti’, donde las líneas se cruzan de forma caótica. A menudo se requiere intervención manual para limpiar el diseño y agrupar los elementos relacionados de forma lógica.
Mejores prácticas para la precisión ✅
Para asegurar que los diagramas generados sean útiles, se deben seguir ciertas prácticas durante el proceso de ingeniería inversa.
-
Filtrar ruido: Excluya las bibliotecas estándar o el código repetitivo que añade confusión visual sin valor arquitectónico. Enfóquese en la lógica de negocio personalizada.
-
Agrupar módulos: Utilice paquetes o espacios de nombres para agrupar clases. Esto evita que el diagrama se convierta en un único nodo masivo.
-
Validar relaciones: Las herramientas automatizadas a veces pueden malinterpretar las relaciones. Revise los enlaces generados para asegurarse de que reflejen con precisión la lógica del código.
-
Iterar: La ingeniería inversa rara vez es una tarea única. A medida que evoluciona la base de código, los diagramas deben regenerarse y revisarse periódicamente.
El papel de la automatización 🤖
La ingeniería inversa manual es impracticable para proyectos grandes. La automatización es clave. Los analizadores automatizados escanean repositorios, construyen gráficos de dependencias y exportan a formatos estándar como XMI o PlantUML. Esto permite a los equipos integrar la generación de diagramas en sus pipelines de CI/CD.
La automatización garantiza que la documentación nunca esté desactualizada. Si un desarrollador realiza un cambio que rompe una dependencia, el proceso de generación de diagramas puede detectar la inconsistencia. Esta validación continua ayuda a mantener la integridad del sistema con el paso del tiempo.
Integrar diagramas en el mantenimiento 🛠️
Una vez generados los diagramas, deben usarse activamente. No son solo para presentación. Los equipos pueden usarlos para planificar esfuerzos de refactorización. Por ejemplo, si un diagrama de clases muestra una clase con dependencias excesivas, es candidata a descomposición.
Además, los diagramas ayudan en las revisiones de código. Los revisores pueden analizar el impacto estructural de un cambio propuesto antes de leer el diff. Esto desplaza el enfoque desde la sintaxis hacia la arquitectura, mejorando la calidad de la base de código.
Conclusión sobre la visión estructural 🏁
La ingeniería inversa de código para diagramas UML es una práctica fundamental para mantener sistemas de software complejos. Transforma el código opaco en una arquitectura transparente, permitiendo una toma de decisiones mejor y una comunicación más clara. Aunque existen desafíos relacionados con el tipado dinámico y las dependencias complejas, los beneficios de una documentación sincronizada superan los costos. Priorizando la claridad estructural, los equipos pueden navegar con confianza sistemas heredados y modernizar sus aplicaciones con precisión.