











Diseñar una arquitectura de datos sólida requiere equilibrar prioridades contradictorias. La integridad, el rendimiento y la mantenibilidad a menudo tiran en direcciones diferentes. Cuando el sistema cambia su enfoque hacia operaciones intensivas en lectura, las reglas tradicionales de diseño de esquemas enfrentan una tensión significativa. El diagrama de relaciones de entidades (ERD) se convierte en algo más que un plano estático; actúa como el contrato entre la lógica de la aplicación y el motor de almacenamiento. Esta guía explora la divergencia estratégica entre los enfoques normalizados y denormalizados específicamente en el contexto de cargas de trabajo intensivas en lectura con alto volumen.
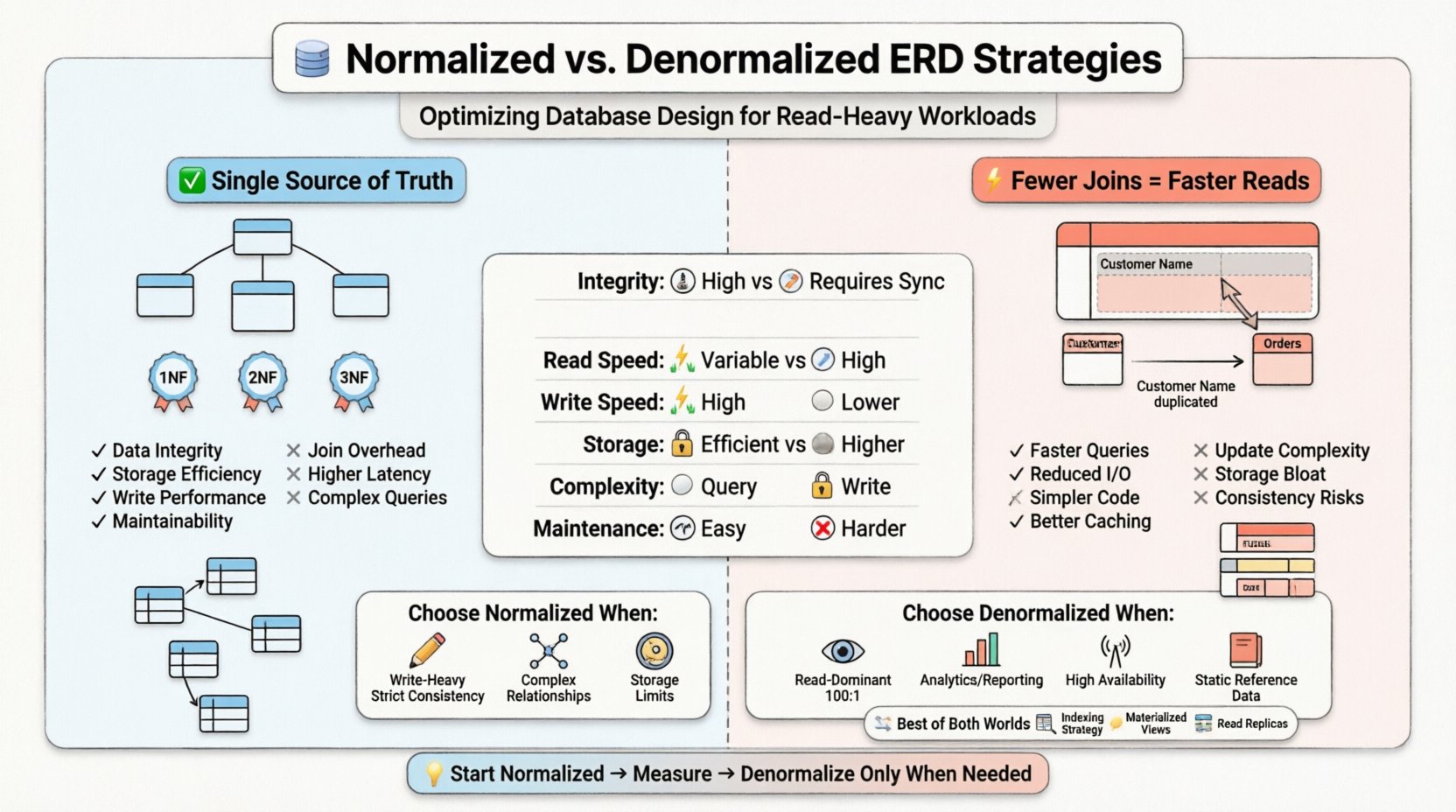
La decisión de normalizar o denormalizar no es binaria. Implica comprender el costo de la duplicación de datos frente al costo de recuperación de datos. En entornos donde las operaciones de lectura dominan los registros de transacciones, minimizar la complejidad de las uniones suele convertirse en el objetivo principal de optimización. Sin embargo, introducir redundancia plantea nuevos desafíos para la consistencia de los datos y las operaciones de escritura. Debemos analizar las compensaciones para seleccionar la estrategia estructural adecuada.
🏗️ Comprender la normalización en el diseño de ERD
La normalización es un proceso sistemático utilizado para reducir la redundancia de datos y mejorar la integridad de los datos. Organiza atributos y tablas en una base de datos relacional para minimizar las anomalías durante las operaciones de inserción, actualización y eliminación. El objetivo es garantizar que cada pieza de datos se almacene en exactamente un lugar.
Principios fundamentales de la normalización
Al construir un diagrama de relaciones de entidades, los arquitectos suelen seguir una jerarquía de reglas conocidas como Formas Normales. Cada forma aborda tipos específicos de redundancia.
- Primera Forma Normal (1FN):Garantiza que cada columna contenga valores atómicos y que no existan grupos repetidos. Esto establece una estructura plana para las filas.
- Segunda Forma Normal (2FN):Se basa en la 1FN al eliminar las dependencias parciales. Los atributos deben depender de toda la clave primaria, no solo de una parte de ella.
- Tercera Forma Normal (3FN):Elimina las dependencias transitivas. Los atributos no clave deben depender únicamente de la clave primaria, no de otros atributos no clave.
En un ERD altamente normalizado, las tablas son granulares. Una tabla de clientes podría existir por separado de su tabla de direcciones, vinculada mediante una clave foránea. Una tabla de pedidos referencia al cliente, y una tabla de artículos de pedido referencia al pedido. Esta estructura garantiza que si un cliente se muda, la actualización ocurre en un solo lugar y se propaga automáticamente.
Ventajas de un esquema normalizado
- Integridad de datos:Fuentes únicas de verdad reducen el riesgo de información contradictoria.
- Eficiencia de almacenamiento:Menos datos redundantes significa que la huella de la base de datos es más pequeña.
- Rendimiento de escritura:Las operaciones de inserción, actualización y eliminación suelen ser más rápidas porque se necesitan tocar menos filas a través de múltiples tablas.
- Mantenibilidad:Los cambios en las estructuras de datos son locales. Añadir un nuevo atributo a una entidad específica no requiere cambios en cascada en tablas no relacionadas.
Desventajas para sistemas intensivos en lectura
Mientras que la normalización destaca en entornos intensivos en escritura o mixtos, introduce fricción para las operaciones de lectura. Cada unión necesaria para ensamblar un registro completo representa una operación física en el disco o en la caché de memoria. En una carga de trabajo intensiva en lectura, el sistema podría necesitar recuperar datos de cinco o seis tablas diferentes para mostrar una sola vista de panel de control.
- Sobrecarga de unión:El procesador de consultas debe coincidir claves entre tablas. Esto consume ciclos de CPU y ancho de banda de memoria.
- Operaciones de E/S:Si las tablas son grandes, el motor de almacenamiento debe realizar múltiples búsquedas para recuperar datos relacionados.
- Latencia: El tiempo acumulado de múltiples búsquedas aumenta el tiempo de respuesta para el usuario final.
🔗 El enfoque de denormalización
La denormalización es la introducción deliberada de redundancia en un diseño de base de datos. El objetivo es optimizar el sistema para el rendimiento de lectura reduciendo el número de uniones necesarias. En el diagrama de relaciones de entidades, esto se manifiesta como columnas que duplican datos de otras tablas o tablas más amplias que consolidan información relacionada.
Cómo funciona la denormalización
En lugar de almacenar una clave foránea para buscar el nombre de un cliente, una tabla de pedidos denormalizada podría almacenar directamente el nombre del cliente. Si el cliente cambia su nombre, el registro del pedido debe actualizarse o marcarse, o el sistema acepta que el pedido refleje el nombre en el momento de la compra.
Esta estrategia desplaza la complejidad desde la ruta de lectura hasta la ruta de escritura. El sistema debe ahora manejar la lógica de actualizar copias redundantes de datos.
Beneficios para cargas de trabajo intensivas en lectura
- Ejecución de consultas más rápida:Menos uniones significan menor sobrecarga computacional.
- I/O reducido:Se recuperan más datos en una sola escaneo de tabla en lugar de múltiples búsquedas.
- Consultas simplificadas:El código de la aplicación requiere menos lógica para ensamblar los resultados.
- Eficiencia de caché:Las estructuras más planas suelen ser más fáciles de cachear de forma eficaz en memoria.
Riesgos y desventajas
El costo principal de la denormalización es la consistencia de los datos. Si los datos de origen cambian, todas las copias redundantes deben actualizarse simultáneamente. El fracaso en hacerlo resulta en datos obsoletos.
- Anomalías de actualización:Actualizar el nombre de un cliente requiere encontrar y cambiar cada registro de pedido que hace referencia a ese cliente.
- Aumento del almacenamiento:La replicación de datos aumenta el tamaño total de la base de datos.
- Complejidad en las escrituras:Las transacciones de escritura se vuelven más complejas, a menudo requiriendo más bloqueos o tiempos de transacción más largos.
- Rigidez del esquema:Agregar un nuevo campo puede requerir actualizar múltiples tablas, no solo una.
📈 Análisis de las características de cargas de trabajo intensivas en lectura
Para elegir la estrategia correcta, uno debe comprender la naturaleza específica de la carga de trabajo. Los sistemas intensivos en lectura difieren significativamente de los sistemas transaccionales donde las escrituras son frecuentes y críticas.
Patrones de consulta
¿La aplicación realiza consultas analíticas complejas o búsquedas simples? Las consultas complejas que implican agregaciones a través de muchas tablas se benefician de la denormalización. Las búsquedas simples por ID podrían funcionar adecuadamente con normalización si los índices están bien ajustados.
- Consultas de punto: Recuperando un solo registro por ID.
- Consultas de rango: Recuperando un conjunto de registros dentro de un rango de fechas.
- Agregaciones: Calculando totales, promedios o conteos en conjuntos de datos grandes.
Requisitos de latencia
Las plataformas de trading de alta frecuencia o los paneles en tiempo real no pueden permitirse la latencia introducida por joins complejos. En estos escenarios, la denormalización suele ser una necesidad en lugar de una opción. Por el contrario, si la aplicación puede tolerar unos cientos de milisegundos de retraso, la normalización podría ser suficiente con un índice adecuado.
Tolerancia a la consistencia de datos
¿Se requiere consistencia inmediata? Si el sistema puede tolerar la consistencia eventual, la denormalización se vuelve mucho más segura. Las réplicas de lectura o los mecanismos de actualización asíncrona pueden manejar la sincronización de datos redundantes sin bloquear las operaciones de escritura.
📋 Tabla de comparación estratégica
La siguiente tabla resume las diferencias clave entre los dos enfoques en el contexto del diseño de bases de datos.
| Característica | Esquema normalizado | Esquema denormalizado |
|---|---|---|
| Integridad de datos | Alta (fuente única de verdad) | Más baja (requiere lógica de sincronización) |
| Rendimiento de lectura | Variable (depende de los joins) | Alto (menos joins) |
| Rendimiento de escritura | Alto (mínima redundancia) | Más bajo (actualizar múltiples filas) |
| Uso de almacenamiento | Eficiente | Más alto (datos redundantes) |
| Complejidad | Alta complejidad de consulta | Alta complejidad de escritura |
| Mantenibilidad | Fácil para cambios en el esquema | Más difícil para cambios en el esquema |
🧭 Marco de decisión para arquitectos
Elegir la ruta adecuada requiere evaluar los requisitos del negocio frente a las limitaciones técnicas. El siguiente marco ayuda a guiar el proceso de toma de decisiones.
Cuándo elegir la normalización
- Intensidad de escritura: Si las operaciones de escritura ocurren con frecuencia en comparación con las lecturas, la normalización evita anomalías de actualización.
- Consistencia estricta: Los sistemas financieros o los registros médicos a menudo requieren cumplimiento estricto de ACID, donde la redundancia es inaceptable.
- Relaciones complejas: Cuando las entidades tienen relaciones muchos a muchos que cambian con frecuencia, la normalización maneja el mapeo de forma limpia.
- Limitaciones de almacenamiento: Si el espacio en disco es escaso, minimizar la redundancia es beneficioso.
Cuándo elegir la denormalización
- Dominio de lectura: Si las lecturas superan con amplio margen a las escrituras (por ejemplo, 100:1), las ganancias de rendimiento derivadas de menos combinaciones superan los costos de escritura.
- Informes y análisis: Los almacenes de datos y los motores de informes a menudo denormalizan para acelerar las consultas de agregación.
- Alta disponibilidad: Los sistemas distribuidos pueden denormalizar datos para permitir lecturas en nodos locales sin saltos de red hacia otras particiones.
- Datos de referencia estáticos: Los datos que rara vez cambian (por ejemplo, códigos de país, tasas de cambio) son candidatos ideales para la duplicación.
🛠️ Enfoques híbridos y optimización
Rara vez es necesario elegir un extremo sobre el otro. Los sistemas modernos suelen emplear estrategias híbridas para equilibrar los beneficios de ambos modelos.
Estrategias de indexación
Antes de denormalizar, asegúrese de que el esquema normalizado esté completamente indexado. Los índices cubiertos pueden permitir al motor de almacenamiento recuperar todos los datos necesarios directamente del índice, evitando búsquedas en tablas. Esto a veces puede lograr velocidades de lectura cercanas a las de la denormalización sin la redundancia de datos.
- Índices compuestos: Ordene las columnas por los campos más selectivos para acelerar las búsquedas por rango.
- Índices parciales: Indexe solo subconjuntos específicos de datos para reducir el tamaño del índice y el costo de mantenimiento.
Vistas materializadas
Una vista materializada es un objeto de base de datos que almacena físicamente el resultado de una consulta. Permite al sistema mantener una vista desnormalizada de los datos sin alterar las tablas base. Cuando cambia la data subyacente, la vista materializada puede actualizarse.
- Precomputación:Las agregaciones complejas se calculan de antemano.
- Ciclos de actualización:Puede configurarse para ejecutarse según un horario o desencadenarse ante cambios en los datos.
- Separación de lectura:Las consultas acceden a la vista materializada, mientras que las escrituras van a las tablas base.
Réplicas de lectura
En arquitecturas distribuidas, las réplicas de lectura pueden configurarse para alojar copias desnormalizadas de los datos. El nodo principal maneja las escrituras y mantiene el esquema normalizado. La réplica recibe actualizaciones de forma asíncrona y atiende el tráfico de lectura con el esquema optimizado.
- Escalabilidad de lecturas:Distribuye la carga entre múltiples nodos.
- Proximidad geográfica:Coloca los datos más cerca del usuario.
- Consistencia eventual:Acepta un ligero retraso en la propagación de los datos.
⚠️ Peligros comunes en el diseño de esquemas
Incluso con una estrategia clara, los errores de implementación pueden afectar el rendimiento. Los arquitectos deben permanecer alerta ante errores comunes.
Sobrenormalización
Crear demasiadas tablas para un solo concepto puede provocar un número excesivo de combinaciones. Aunque la 3FN es un estándar, adherirse a ella ciegamente en sistemas con muchas lecturas puede degradar el rendimiento. A veces, es necesario una violación controlada de la 3FN.
Desnormalización inconsistente
Desnormalizar solo algunas partes de la aplicación mientras se deja el resto normalizado crea un sistema fragmentado. La inconsistencia dificulta que los desarrolladores predigan las características de rendimiento.
Ignorar el volumen de datos
Un esquema que funciona para un conjunto de datos pequeño puede fallar cuando el volumen aumenta. La desnormalización aumenta los requisitos de almacenamiento de forma lineal con el número de registros. Si los datos crecen exponencialmente, el costo de almacenamiento y la sobrecarga de mantenimiento de la redundancia pueden volverse inmanejables.
Complejidad de la lógica de actualización
Implementar la lógica para mantener los datos redundantes sincronizados no es trivial. A menudo requiere desencadenantes, transacciones a nivel de aplicación o colas de mensajes. Si esta lógica falla, se produce una corrupción de datos de forma silenciosa.
🔍 Consideraciones de implementación
Al pasar del diseño a la implementación, deben abordarse detalles técnicos específicos para garantizar el éxito.
Gestión de transacciones
Las actualizaciones desnormalizadas a menudo abarcan múltiples filas. Deben envolverse en una sola transacción para garantizar la atomicidad. Si el sistema falla a mitad de camino, los datos deben deshacerse para evitar inconsistencias.
Capas de almacenamiento en caché
Incluso con desnormalización, almacenar en caché datos frecuentemente accedidos en memoria puede reducir aún más la carga de la base de datos. La caché debe invalidarse o actualizarse cuando cambie los datos subyacentes.
Monitoreo y métricas
El monitoreo continuo es esencial. Supervisa los tiempos de ejecución de las consultas, la contención de bloqueos y el crecimiento del almacenamiento. Si hay un pico en la latencia de escritura, podría indicar que la lógica de actualización de desnormalización es demasiado pesada.
📝 Consideraciones finales para arquitectos
La elección entre estrategias de ERD normalizadas y desnormalizadas es una decisión arquitectónica fundamental. Determina cómo fluyen los datos a través del sistema y cómo interactúa el motor de almacenamiento con la aplicación. No existe una única respuesta correcta que se aplique a todos los escenarios.
- Mide primero:No optimices sobre la base de suposiciones. Analiza la carga de trabajo actual para identificar cuellos de botella.
- Empieza simple:Comienza con un diseño normalizado. Desnormaliza solo cuando las métricas de rendimiento indiquen la necesidad.
- Documenta las decisiones:Registra claramente por qué se introdujo la redundancia. Los futuros mantenimientos necesitan comprender las compensaciones.
- Planifica la evolución:Los diseños de esquema deben evolucionar. Una estrategia que funciona hoy puede necesitar ajustes a medida que cambien los patrones de datos.
Al comprender la mecánica de las uniones, el costo de la redundancia y las demandas específicas de cargas de trabajo intensivas en lectura, los arquitectos pueden diseñar sistemas que sean tanto robustos como eficientes. El objetivo no es seguir una regla rígida, sino aplicar la herramienta más adecuada para el entorno de datos específico.